文章目录
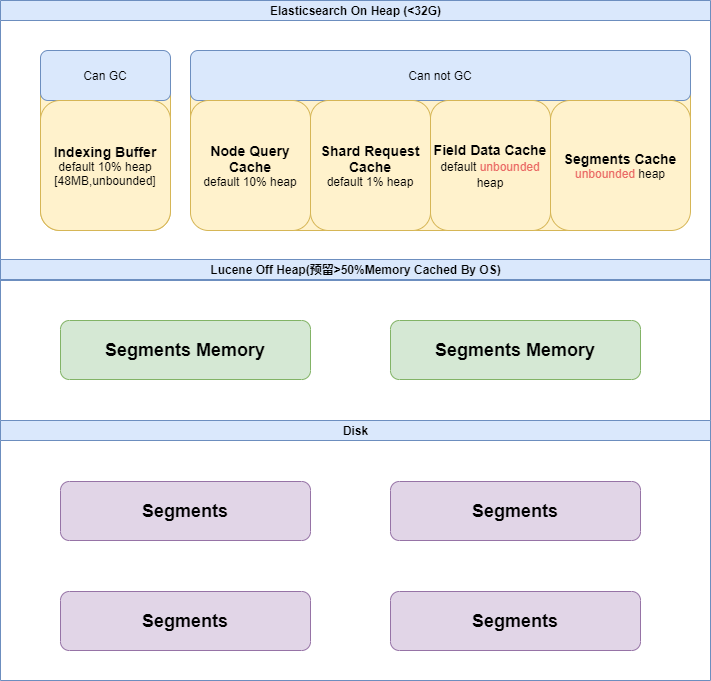
- Elasticsearch JVM内存由哪些部分组成
- Indexing Buffer
- Node Query Cache
- Shard Request Cache
- Field Data Cache
- Segments Cache
- 查询
- 非堆内存
- 内存压力
- mat分析es的jvm
- 缓存监控
Elasticsearch JVM内存由哪些部分组成
官方建议Elasticsearch设置堆内存为32G,因为Elasticsearch是Java语言实现的程序,所以:
1)这部分堆内存,首先得包括Elasticsearch从字节码加载验证解析到内存的部分,如局部变量存储虚拟机栈,实例对象存储堆空间等;
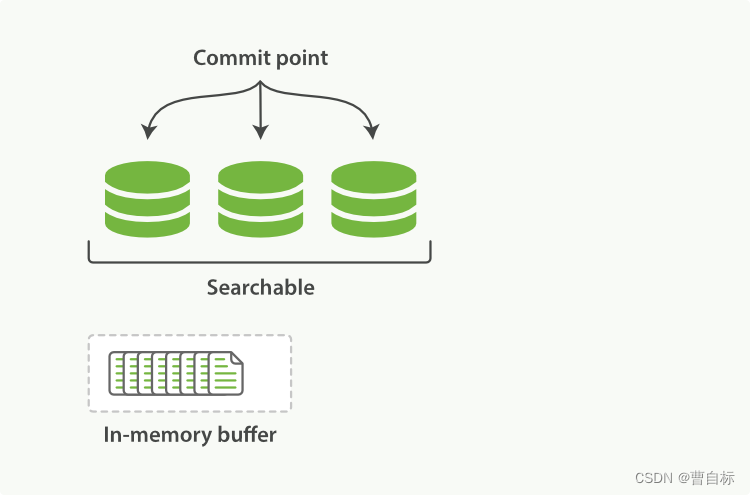
2)新的文档写入原理是,首先被添加到内存索引缓存中,然后写入到一个基于磁盘的段;
3)查询时,如果用到filter过滤查询,会有查询结果缓存;
4)当针对一个索引或多个索引运行搜索请求时,每个涉及的分片都会在本地执行搜索并将其本地结果返回到协调节点,协调节点将这些分片级结果组合成“全局”结果集。分片级请求缓存模块将本地结果缓存在每个分片上;
5)当对一个字段进行排序、聚合,或某些过滤,比如地理位置过滤、某些与字段相关的脚本计算等操作,就会需要Field Data Cache
6)ES 底层存储采用 Lucene,Lucene 引入排索引的二级索引 FST,原理上可以理解为前缀树,加速查询
Indexing Buffer
新的文档写入原理是,首先被添加到内存索引缓存中,然后写入到一个基于磁盘的段,这部分内存为Indexing Buffer
- 说明:分配给节点上的所有分片
- 配置参数:
indices.memory.index_buffer_size:接受百分比或字节大小值。它默认为10%
indices.memory.min_index_buffer_size:如果index_buffer_size指定为百分比,则此设置可用于指定绝对最小值。默认为48mb.
indices.memory.max_index_buffer_size:如果index_buffer_size指定为百分比,则此设置可用于指定绝对最大值。默认为无界。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/dynamic-indices.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/indexing-buffer.html
Node Query Cache
- 说明:每个节点有一个查询缓存,由所有分片共享
- 失效策略:LRU算法
- 生效条件:1)index.queries.cache.enabled配置开启(默认true)2)filter过滤查询,注意Term查询和在filter过滤器之外的不会产生Node Query Cache 3)当缓存是按段进行时,合并段可能会使缓存的查询无效
- 配置参数:indices.queries.cache.size,接受百分比值(如5%)或精确值(如 )512mb。默认为10%
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/query-cache.html
Shard Request Cache
- 说明:对满足条件的查询,整个查询 JSON 主体的哈希值用作缓存键,对分片级请求缓存搜索size=0的结果
- 失效策略:LRU算法
- 生效条件:1)默认情况下,请求缓存只会缓存搜索请求所在的结果size=0,因此不会缓存hits,但会缓存hits.total, aggregations和 suggestions 2)大多数使用的查询now无法缓存 3)使用不确定性 API 调用的脚本化查询,例如 Math.random()或new Date()不能缓存
- 配置参数:indices.requests.cache.size,缓存在节点级别进行管理,并且具有默认的最大堆大小1%
查看缓存使用情况:
GET /_stats /request_cache
{
"index": {
"uuid": "X8PM2Eq_Tk2ZVpzjYcJ0CQ",
"primaries": {
"request_cache": {
"memory_size_in_bytes": 97792,
"evictions": 0,
"hit_count": 171814,
"miss_count": 20344
}
},
"total": {
"request_cache": {
"memory_size_in_bytes": 186416,
"evictions": 0,
"hit_count": 241527,
"miss_count": 26841
}
}
}
}
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/shard-request-cache.html
Field Data Cache
- 说明:包含field data和global ordinals。1)Field Data包括一个字段中所有唯一值的列表以及每个唯一值的文档ID列表。它用于支持排序、聚合和搜索等操作。当你执行排序或聚合操作时,Elasticsearch可能会在Field Data Cache中存储该字段的数据,以便快速访问2)Global Ordinals(全局顺序号):全局顺序号是Field Data的一种改进,它使用更紧凑的数据结构来提高性能和减少内存占用。Global Ordinals通过将字段中的每个唯一值映射到一个整数,从而更有效地支持排序和聚合操作。这有助于减少内存开销并提高性能3)Field Data通常用于text字段,而Global Ordinals更常用于keyword字段,因为keyword字段通常包含更少的唯一值
- 失效策略:LRU算法
- 生效条件:1)默认text字段类型不支持 2)keyword, ip, and flattened 等字段上聚合操作 3)从join字段对父文档和子文档进行操作,包括 has_child查询和parent聚合
- 配置参数:indices.fielddata.cache.size,默认无限制,但应小于请求熔断器(indices.breaker.request.limit默认JVM堆60%)
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/modules-fielddata.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/text.html#fielddata-mapping-param
https://www.elastic.co/guide/en/elasticsearch/reference/8.10/eager-global-ordinals.html
Segments Cache
Segments Cache(segments FST数据的缓存),为了加速查询,FST 永驻堆内内存,无法被 GC 回收。该部分内存无法设置大小,减少data node上的segment memory占用,有三种方法:
- 删除不用的索引。
- 关闭索引(文件仍然存在于磁盘,只是释放掉内存),需要的时候可重新打开。
- 定期对不再更新的索引做force merge
解释下FST:ES 底层存储采用 Lucene(搜索引擎),写入时会根据原始数据的内容,分词,然后生成倒排索引。查询时先通过查询倒排索引找到数据地址(DocID),再读取原始数据(行存数据、列存数据)。但由于 Lucene 会为原始数据中的每个词都生成倒排索引,数据量较大。所以倒排索引对应的倒排表被存放在磁盘上。这样如果每次查询都直接读取磁盘上的倒排表,再查询目标关键词,会有很多次磁盘 IO,严重影响查询性能。为了解磁盘 IO 问题,Lucene 引入排索引的二级索引 FST [Finite State Transducer] 。原理上可以理解为前缀树,加速查询
https://armsword.com/2021/03/26/es-memory-management/
查询
/_cat/nodes?v&h=name,node*,heap*,ram*,fielddataMemory,queryCacheMemory,requestCacheMemory,segmentsMemory
name id node.role heap.current heap.percent heap.max ram.current ram.percent ram.max fielddataMemory queryCacheMemory requestCacheMemory segmentsMemory
name id node.role heap.current heap.percent heap.max ram.current ram.percent ram.max fielddataMemory queryCacheMemory requestCacheMemory segmentsMemory
es-7-master-1 7Doz dim 6.1gb 38 16gb 20.4gb 64 32gb 0b 3mb 205.9kb 484.2kb
es-7-master-0 mxrv dim 8.2gb 51 16gb 20gb 63 32gb 0b 2.9mb 208.9kb 476.3kb
es-7-master-2 uiZk dim 9.5gb 59 16gb 20gb 63 32gb 0b 2.6mb 209.5kb 516.2kb
https://armsword.com/2021/03/26/es-memory-management/
非堆内存
上面的提到的内存都是JVM管理的,ES能控制,即On-heap内存,ES还有Off-heap内存,由Lucene管理,负责缓存倒排索引(Segment Memory)。Lucene 中的倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到内存中,从而提高 Lucene 性能。
https://armsword.com/2021/03/26/es-memory-management/
内存压力
GET /cn/_nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
{
"nodes": {
"7DozU2vhRc2xg2RGrdTFWA": {
"jvm": {
"mem": {
"pools": {
"old": {
"used_in_bytes": 2199187968,
"max_in_bytes": 17179869184,
"peak_used_in_bytes": 3432122880,
"peak_max_in_bytes": 17179869184
}
}
}
}
}
}
}
JVM Memory Pressure = used_in_bytes / max_in_bytes
https://www.elastic.co/cn/blog/managing-and-troubleshooting-elasticsearch-memory
mat分析es的jvm
熟悉的话,通过直方图看谁占用内存最大

否则通过dominator_tree查看,可以看到调用链

但不熟悉源码,这种分析感觉作用不大
缓存监控
感觉作用亦不大,安心使用es提供的接口吧
https://elasticsearch.cn/article/14432