一般来说,大数据平台包括以下4类数据生产域——生产生态环境(正式生产环境)、开发和测试环境、培训和演示环境、灾备环境。各生产域在由平台提供资源、安全、监控、故障恢复等保障的同时,不同的生产域之间还需要严格隔离,以确保数据生产的可靠性、可用性和安全性。具体到真实的企业环境,生产域的规划则更为复杂。
本文聚焦独立生产域的规划与新建,分享标准流程和注意事项。

为什么应该关注新建数据生产域?
企业在发展过程中,出于业务扩张、安全合规、组织调整等要求,常需要对现有的大数据平台进行独立的生产域规划,来匹配新涌现的数据需求。
举几个例子:
1. 业务快速扩张,数据生产域能否同步快速复制?
业务的快速复制是企业规模化扩张的常见做法。相对应的,大数据平台也要提供出足够的数据空间,以便这些业务投入使用。譬如,制造企业在某地建厂有成熟实践后,随后新建的各地工厂同样需要新建的数据生产域,工厂之间的数据作业互不影响。
2. 安全合规要求,能否确保独立的数据隔离和管理?
企业在开展跨境业务时,需遵守业务所在地的数据安全相关法律法规,且各地数据不允许无原则地传输交换。因此企业需创建多个物理隔离、数据独立的生产域,确保在当地的数据业务安全合规。在国内,对上市公司的财务数据往往也有数据独立管理的合规要求,也就意味着财务应有独立的数据生产域。
3. 匹配组织架构,各业态能否互不干扰、独立运营?
旗下有多个子公司、子品牌及业态的大型集团企业,必须在大数据平台分别设立多个独立的数据生产域,同时,也便于集团层面对每个子公司完成独立的数据成本核算。
在上述场景中必须注意的是,一个又一个的数据生产域代表着安全、隔离、稳定,但并不意味着重新建起了数据孤岛。
以“既隔离又统一”的集团数据云服务为例,集团大数据平台统一为各子公司、子品牌(独立数据生产域)提供存算资源、运维服务及安全保障,并保留对全集团数据资产分析洞察的能力。技术更为成熟的大数据平台,还应支持在合规前提下的“复用”,例如,支持复制标准空间的数据业务逻辑到新的空间中,以跟上业务快速扩张的节奏,避免一次又一次从头重建。
5步走,搞定新建数据生产域的规划
奇点云数据云平台DataSimba具备跨云多域多租户能力。依托DataSimba,企业可以统一建设并管理全域数据资产,也可以创建多个Workspace(工作空间,即独立的数据生产域),来完成多云、多品牌、多业态等管理需求。
DataSimba的权限管控体系有序、灵活、精细化,租户可以在一个Workspace下建立自己的Project(项目)并进行权限划分,也可以在不同Workspace建立不同的项目。一个Workspace中可以有多个租户建立项目,也可以被一个租户独占。
在数据云平台DataSimba中,规划并创建一个新的Workspace可归纳为以下5个环节:
1. 大数据集群评估
1.1 整体调研:调研企业业务和数据现状
确认业务整体目标以及业务范围;探查数据现状,明确数据分布及数据流向;IT系统调研,调研企业IT基础设施的现状;组织架构调研,了解企业整体组织架构。
1.2 资源评估:评估出需要的资源总量
通过调研的数据情况,估算未来数年整体的数据量;基于整体业务未来发展情况,估算整体任务数量。
1.3 组件评估:基于调研的业务场景,进行组件选型,满足业务的需求。
2. Account规划
Account(账号)指租户账号,此账号会绑定若干User(用户子账号),每个子账号可以被分配不同的Role(角色),每个角色可以控制能访问的功能权限。同时,每个子账号可以进行数据权限的绑定。
具体步骤包括:基于组织架构调研,明确需要建立子账号的用户;基于用户的职位职责,规划出不同的角色和所需要的功能权限;根据企业的数据安全要求,规划数据权限的设定;最后,Account与资源节点对应绑定。
3. Project规划
Project(项目)是一种对任务、作业、数据逻辑上的管理单位。
首先根据企业业务情况,选择适合的划分维度进行Project规划。划分完毕后,将上述Account相关的用户分配到对应的Project中。
规划Project的常见维度如下:
· 环境用途维度:例如开发环境、测试环境、预发环境、正式环境等。从经济性角度出发,通常分为开发环境、正式环境。
· 业务领域维度:例如订单域,财务域等。
· 组织架构维度:例如生产部门、市场运营部门、电商部门等。
· 地理位置维度:根据业务所在的地理位置划分,例如欧洲、北美洲等。
4. Quota规划
Quota(配额)指对不同用户或部门使用资源(如CPU、内存、GPU等)的分配及限制。
结合上述规划的资源和项目,可以开始进行Quota规划,通常遵循以下原则:
· 业务优先原则:重要的业务空间具有更高的配额,以确保任务能有效执行完毕。
· 资源利用率原则:在不影响业务使用的前提下,可以尽可能使用Quota共享的方式来提升资源利用率。
结合上述原则和业务场景,判断高优先级的业务。在确保高优先级业务有效执行的前提下,配置Quota。随后判断中优先级的业务,可以根据实际业务要求选择和低优先级的业务共同使用一个Quota。规划好Quota后,分配给对应的Project使用。
5. 任务和数据迁移
上述环节规划完毕后,开始正式迁移相关的任务以及数据。
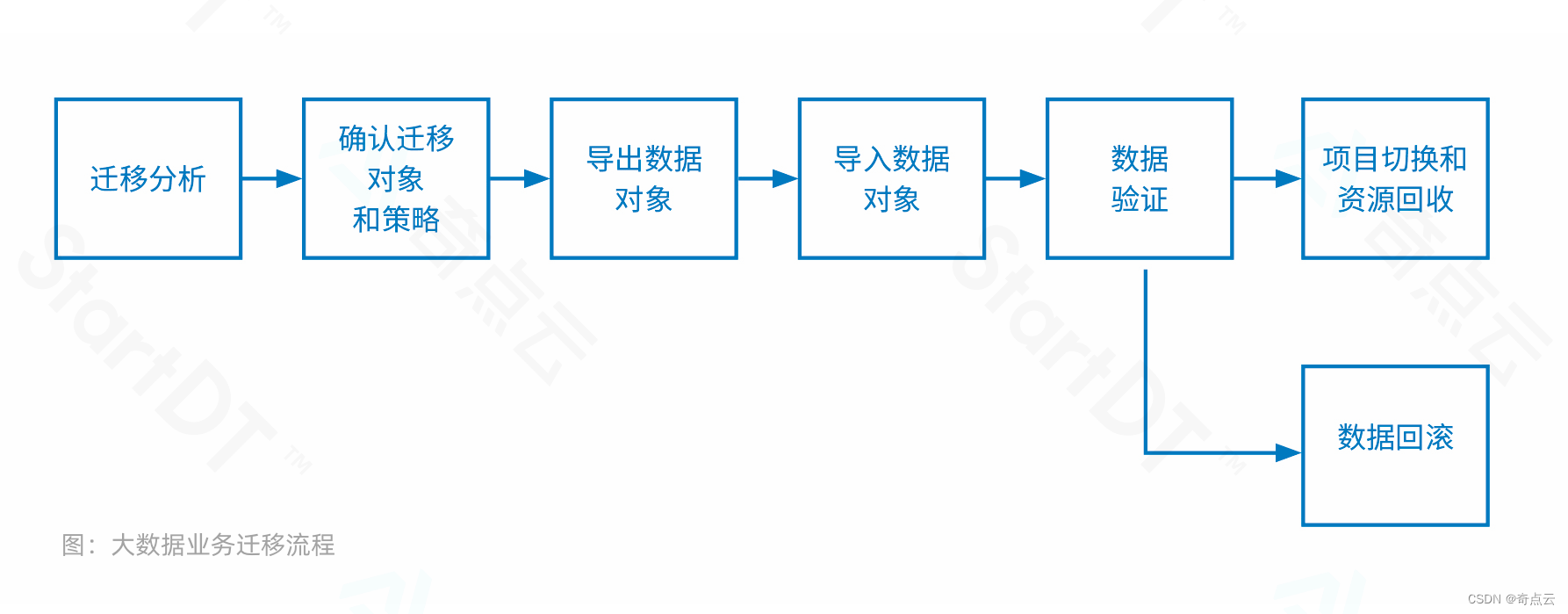
DataSimba内置迁移客户端,支持将现有大数据系统的数据源、作业、任务、服务等对象自动化迁移至DataSimba。
此外,DataSimba提供完备工具,将现有Workspace的数据业务逻辑完整复制到新的Workspace中,以满足快速新建、复制独立生产域的需求。
写在最后:创建数据生产域,就是创建对象体系的实例
数据云平台DataSimba底层为数据云操作系统内核(SimbaOS Kernel)。内核将大数据领域的存储、计算、服务、调度、安全、租户等常用功能,抽象为一组标准对象模块。这组标准对象加上对象之间的关联关系,能几乎满足所有业务场景的需要。
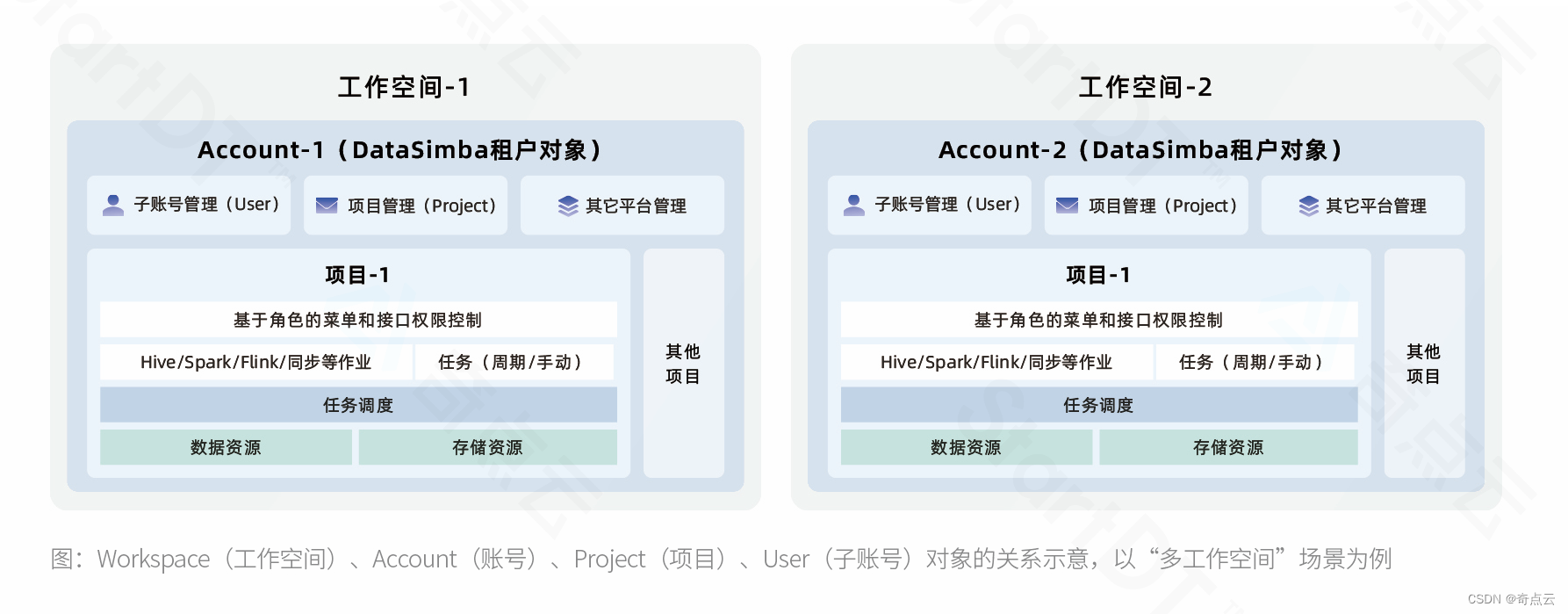
如上图所示,Workspace(工作空间)、Account(账号)、Project(项目)、User(子账号)等均为“对象”,在DataSimba创建数据生产域,也就是创建对象体系的实例:
- 创建Account实例,并关联Workspace;
- 选择并创建Project实例;
- 创建对应Quota实例;
- 最后进行数据迁移,并创建Task(任务)、Job(作业)等实例。
通过创建对象体系(的实例)的方式来构建数据生产域,更有利于:
· 封装底层技术,提高易用性:以Project(项目)为例,数据云平台用户(工程师)只需通过该对象创建项目,完成对项目的各种修改,无需关注底层技术细节;
· 提高系统的可维护性:单个对象调整对整体影响小,例如Workspace(工作空间)这一对象需要支持新的特性,只需要对该对象改动,不会影响其他对象及关系。