文章目录
- 0 项目简介
- 任务 1数据导入与预处理
- 任务 1.1 探查数据质量并进行缺失值和异常值处理
- 1.1.2检查重复值
- 1.1.3数据内容总览
- 1.1.4数据分布总览
- 1.1.5消费金额和消费次数观察消费金额和消费次数的散点图
- 1.1.6观察 CardCount 特征的分布情况
- 任务2 食堂就餐行为分析
- 任务 2.2 食堂刷卡记录
- 任务 2.3 根据上述分析的结果,为食堂的运营提供建议。
- 任务 3学生消费行为分析
- 任务 3.1 分析不同专业间不同性别学生群体的消费特点。
- 3.3.1 本月人均刷卡频次和人均消费额
- 3.3.2 选择 3 个专业,分析不同专业间不同性别学生群体的消费特点
- 任务 3.2 分析每一类学生群体的消费特点。
- 3.2.1 概述
- 3.2.4 聚类结果分析
- 任务 3.3 助学金评定
- 4 关键代码
- 最后
0 项目简介
今天学长向大家介绍一个数据分析项目
基于大数据的高校校园学生一卡通数据分析
基于国内某高校校园一卡通系统一个月的运行数据,使用数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为
任务 1数据导入与预处理
任务 1.1 探查数据质量并进行缺失值和异常值处理
1.1.1数据结构总览查看数据集项数,发现数据集data1.csv,有4341项,5列;数据集data2.csv,有519367 项,14列;数据集data3.csv,有43156项,6列
1.1.2检查重复值
通过去重操作发现三个数据集均无重复项
1.1.3数据内容总览
查看数据信息info(),发现data1和data3中均无缺失值 ,data2中termSerNo、conOperNo 存在较大量的缺失值,因为这两项数据对后续分析无影响故直接过滤
1.1.4数据分布总览
通过对数据Describe,查看数据的均值,最大值,最小值以及方差等数据特征,观察到data1
和data3中的特征值均较为合理,data2中的Money、FundMoney、Surplus以及 CardCount,均存在和样本群体偏离程度较大的数据,会影响后序模型的性能
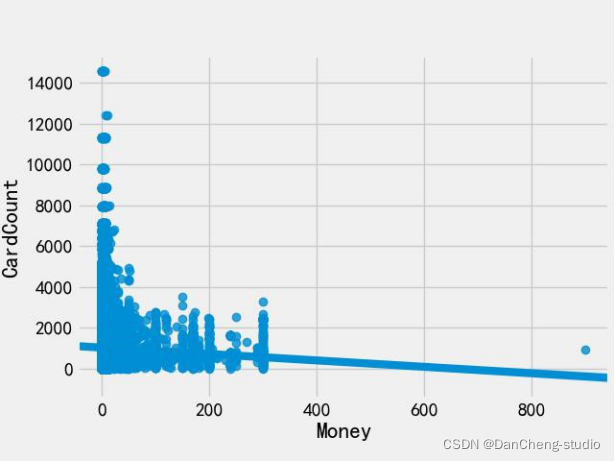
1.1.5消费金额和消费次数观察消费金额和消费次数的散点图
发现数据中具有一定数量的离群点,将其过滤
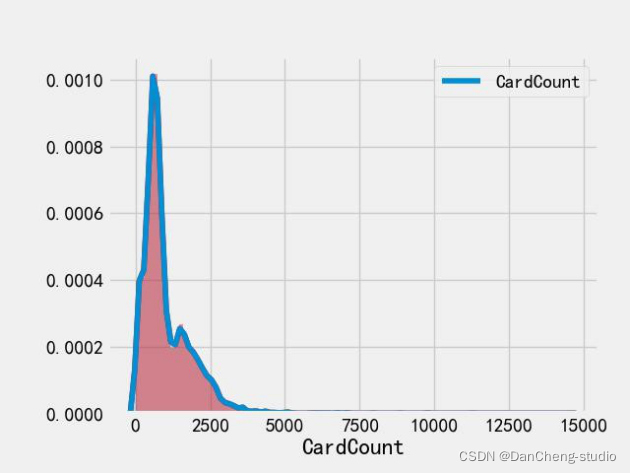
1.1.6观察 CardCount 特征的分布情况
通过 distplot 和 kdeplot 绘制柱状图观察 CardCount 特征的分布情况,属于长尾类型的分布,这说明了有很多消费次数过多且超出正常范围。
任务2 食堂就餐行为分析
任务 2.1 绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点,是否有显著差别
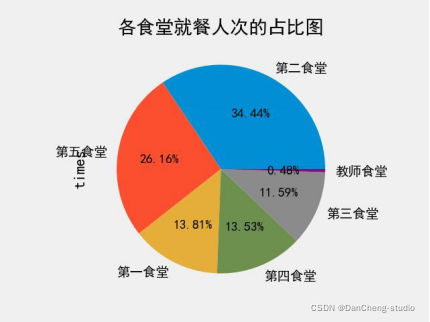
根据图 1,综合早、午、晚三餐学生的就餐地点来看,34.44%的学生更偏爱去第二食堂,
26.16%的学生偏爱去第五食堂,第一、三、四食堂在学生的偏爱程度中属于一般水平,而只有 0.46%的学生在教师食堂就餐。
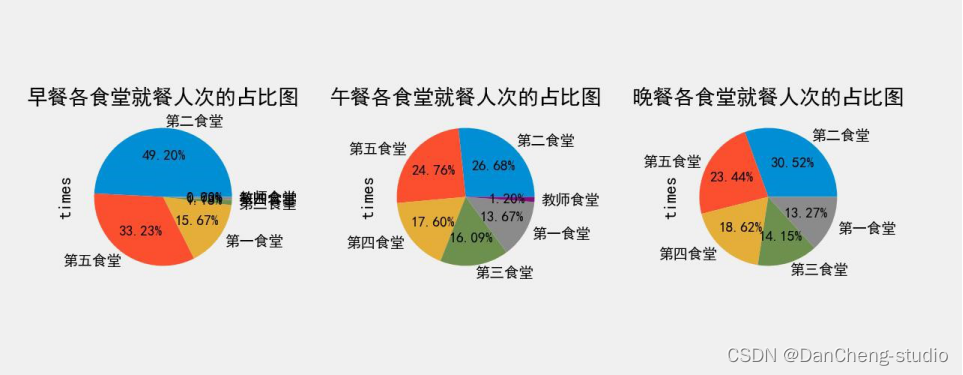
根据图 2,图 3,图 4 三图分析,学生对食堂的偏爱程度前三的食堂是:早餐:第二食堂 > 第五食堂 > 第一食堂午餐:第二食堂 > 第五食堂 > 第四食堂晚餐:第二食堂 > 第五食堂 > 第四食堂而学生用餐次数少的食堂(以用餐次数是否超过 10%为分界点)分别有:早餐:第四食堂、第三食堂、教师食堂午餐:教师食堂晚餐:教师食堂
综上,学生午晚两餐的用餐地点与综合三餐用餐地点分析比较,不存在显著差别;而学生的早餐用餐地点,选择第三、四食堂的占极少数,与综合三餐用餐地点有较为显著的差别。
任务 2.2 食堂刷卡记录
分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值
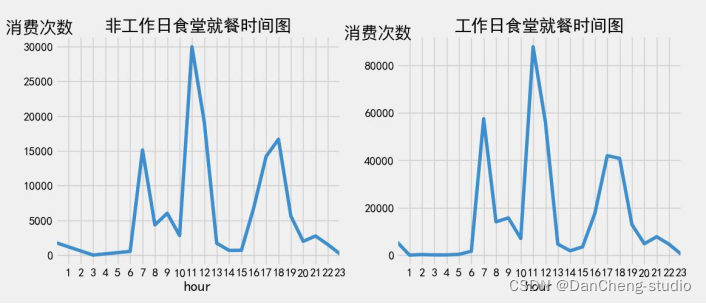
从上图可以看出,工作日的就餐峰值均高于非工作日。工作日食堂早餐的就餐峰值为 60000次,非工作日为15000次;工作日食堂午餐的就餐峰值为90000次,非工作日为30000 次;工作日食堂晚餐的就餐峰值为17000次,非工作日为41000次。
出现该现象的主要原因在于工作日学生需要外出上课,直接前往食堂就餐的可能性更高,而非工作日学生由于直接在宿舍点外卖或者外出游玩就餐等原因导致前往食堂就餐的人数大幅减少。因此工作日食堂就餐峰值高于非工作日就餐峰值。
任务 2.3 根据上述分析的结果,为食堂的运营提供建议。
学校方面,应该根据学生的喜好程度合理安排食堂的场地、资金分配等资源,由2.1 可知,大部分学生偏爱去第二食堂和第五食堂,因此学校应给予第二食堂和第五食堂资源倾斜。
食堂方面,受偏爱的第二食堂和第五食堂应该进行菜品创新,形成顾客粘性。并且因为就餐学生多,食堂更应该合理安排食堂内的排队位置,提高排队效率。而就餐学生数偏少的第一、三、四食堂应该找出自身原因,采取例如提高食堂环境质量、增加菜品种类或提出促销活动等方法吸引学生群体。
此外,每个食堂在就餐峰值(分别为7点、11点、17点左右)应加大食堂人手,合理安排排队场所,提高排队效率,避免打饭效率低下,并且应在这三个高峰时间段内增加菜品供应量,避免供不应求。而在非高峰期,食堂可以适当减少菜品供应和食堂工作人员数量,从而减少食堂无用的运营成本。
任务 3学生消费行为分析
任务 3.1 分析不同专业间不同性别学生群体的消费特点。
3.3.1 本月人均刷卡频次和人均消费额
根据程序计算结果得出:本月人均消费频次为:72.74118014361537次本月人均消费额为:288.7773899469248元
考虑数据合理性,得出:本月人均消费频次越为:73次;本月人均消费额288.8元
3.3.2 选择 3 个专业,分析不同专业间不同性别学生群体的消费特点
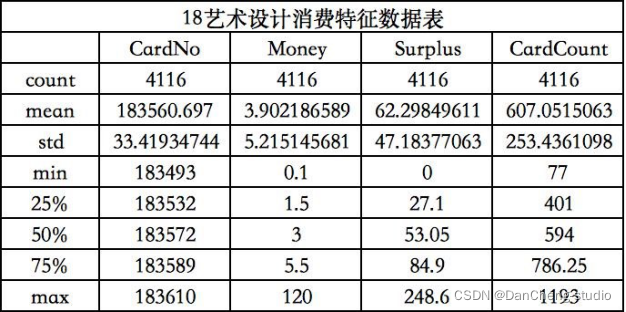
3.3.2.1根据程序运行结果得出学生消费总额、消费次数总数、校园卡中余额的数据特征图
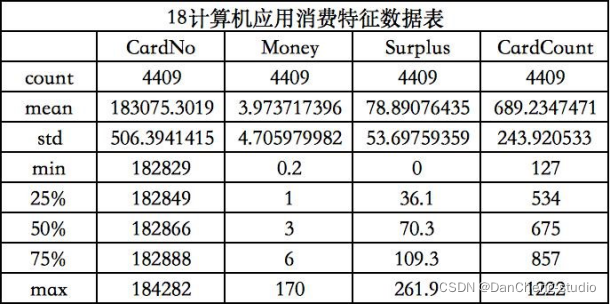
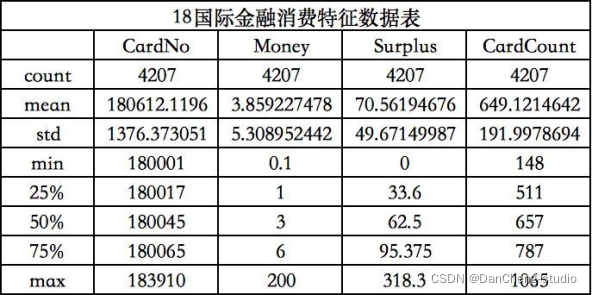
3.3.2.2根据程序运行结果得出学生消费总额、消费次数总数、校园卡中余额的柱状图
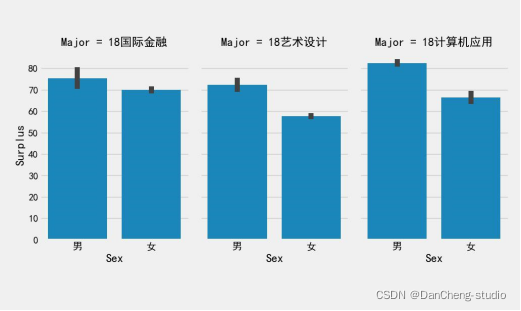
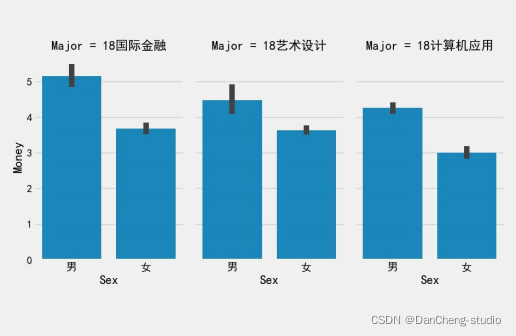
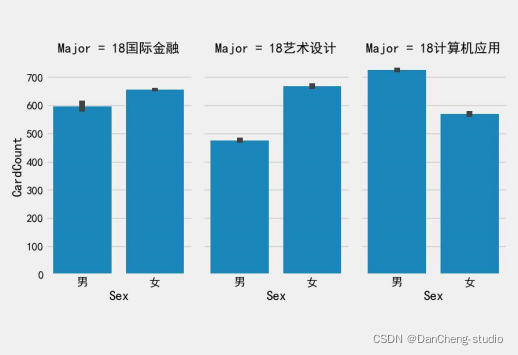
从上图和上表可以得到不同专业的学生,计算机应用专业学生消费最频繁,国际金融专业学生单次消费金额最高,艺术设计专业学生卡内盈余最低。而不同专业的学生卡内盈余相差不大。出现该差异的可能原因在于计算机应用专业需要运用到电脑等电子设备,导致购买频繁。国际金融专业消费金额高可能是其运用专业知识赚钱所需。艺术设计专业学生卡内盈余最低可能是由于其日常在服装等上面的开销较大。
此外,我们可以得到不同专业间不同性别学生群体的消费特点。
首先是国际金融专业的学生。该专业女生消费频繁,男生单次消费金额高,卡内盈余金额近似。其次是艺术设计专业的学生。该专业女生消费频繁,男生单次消费金额高。男生卡内盈余金额高于女生。最后是计算机应用专业的学生。该专业男生消费频繁、单次消费金额高,并且男生盈余金额高于女生。
通过分析,出现性别上消费特点差异主要是由于男女性格原因。女生更偏好高频低费用的购买,享受消费的过程,因此消费次数多,每次都只是购买小额商品。而男生更偏好于低频高费用的购买,消费目的性强,虽不经常消费,但每次总是会消费较大额度。
任务 3.2 分析每一类学生群体的消费特点。
3.2.1 概述
为了将学生的整体校园消费行为进行分类,选择了当月消费总金额,消费次数,卡内存款作为特征进行聚类,采用的聚类算法为 k-means 算法(k-均值聚类算法)
3.2.2 k-means 算法简介
k-means 算法(k-均值聚类算法)是一种基本的已知聚类类别数的划分算法。它是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。它可以处理大数据集,且高效。它的输入自然是数据集和类别数。聚类结果是划分为 k 类的 k 个数据集。
3.2.3 过程
将学生的整体校园消费行为分为 4 类,因此将 k-means 算法中的 k 值取为 4,运用公式 data = 1.0*(data - data.mean())/data.std() 进行数据标准化,采用欧式距离作为度量,并画出每一项特征对应的数据直方图如下
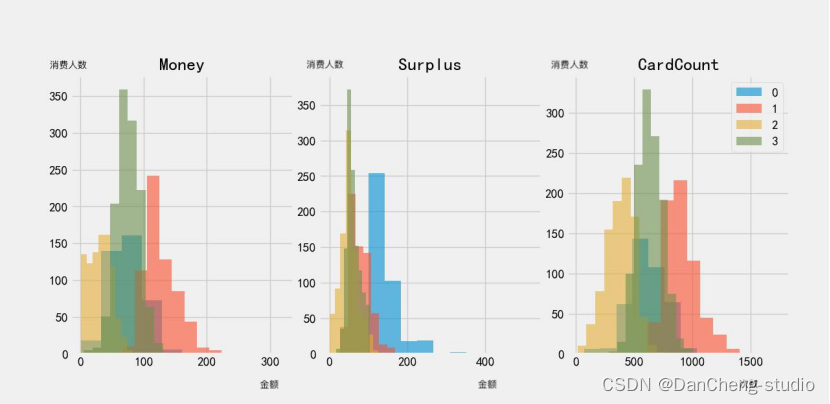
3.2.4 聚类结果分析
根据学生在 4 月份的消费金额、卡内盈余与消费次数,我们将学生分成了四类群体,分别命名为 0,1,2,3.
学生群体 0 的消费特点为:该群体属于中等消费水平,有较高的消费潜力,这类学生群体应有较为良好的储蓄意识,属于滞后消费。
学生群体 1 的消费特点为:该群体属于高消费水平,但消费潜力较弱,这类学生群体的消费能力较高。
学生群体 2 的消费特点为:该群体属于低消费水平,且消费潜力较弱,这类学生群体的消费能力较弱。
学生群体 3 的消费特点为:该群体属于中等消费水平,消费潜力较弱,这类学生群体的储蓄意识较于学生群体 0 更弱。
任务 3.3 助学金评定
通过对低消费学生群体的行为进行分析,探讨是否存在某些特征,能为学校助学金评定提供参考。
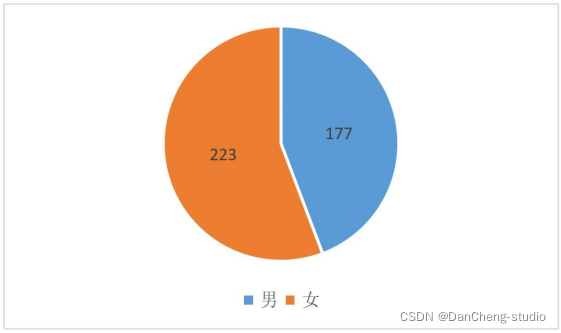
根据分类所得的贫困生情况,我们首先针对贫困生的性别进行分析。由上图可看出,在已知的贫困生人数之中,超过半数的贫困生为女性。
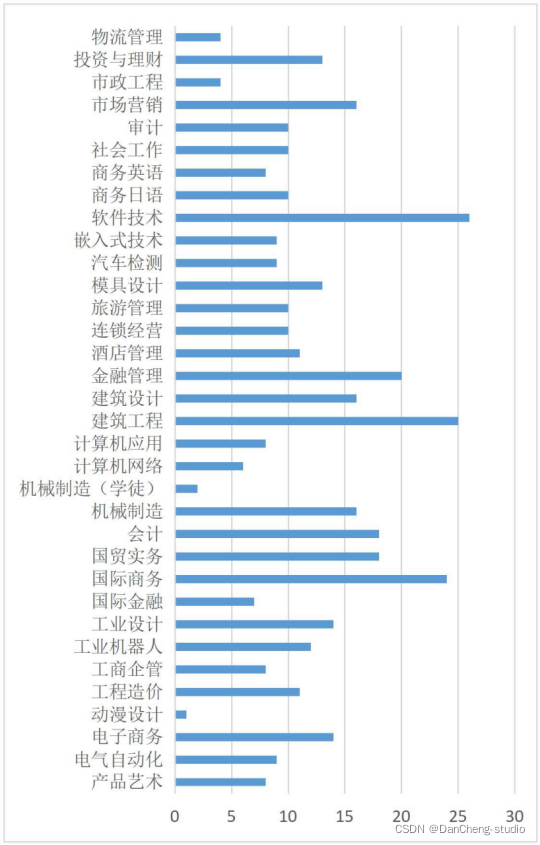
根据分类所得的贫困生情况,对贫困生所在专业类别进行分析归纳。可发现,专业为理工科的学生中,贫困人口占比大;经管商科的学生中,贫困人口的占比数相较于理工科的会更少。而专业为艺术设计类的学生,贫困人口数量最少。

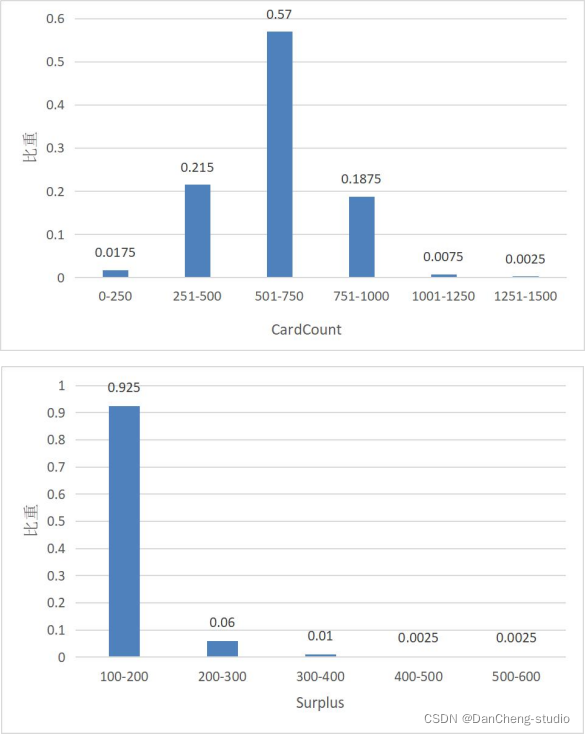
从上图可以看出贫困生的单次消费金额主要在 51-100 元之间,消费次数主要在 501-750 元之间,卡内盈余主要在 100-200 元之间。和其他类别学生相比,我们可以看出贫困生的消费次数、消费金额和卡内盈余均较低。
从上述分析我们可以看出,贫困人口有较大概率集中在性别为女,专业为理工科,日常消费次数、消费金额以及卡内盈余都较低的学生当中。因此,学校在评定奖助学金的过程中,可以根据学生的性别、专业和日常消费情况对学生的贫困背景进行一个初步的估计,为后面对学生群体贫困背景的详细调查,提供一个简单的基础。
4 关键代码
task1.py
import pandas as pd
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
plt.style.use("fivethirtyeight")
sns.set_style({'font.sans-serif':['simhei','Arial']})
'''
任务 1.1 理解字段含义。探查数据质量并进行缺失值和异常值等
方面的必要处理。
'''
# 导入数据
df1 = pd.read_csv('data1.csv', encoding='gbk')
df2 = pd.read_csv('data2.csv', encoding='gbk')
df3 = pd.read_csv('data3.csv', encoding='gbk')
# 数据信息总览
print('**************************************************')
print(df1.shape)
print('**************************************************')
print(df2.shape)
print('**************************************************')
print(df3.shape)
print('**************************************************')
print('未去重: ', df1.shape)
print('去重: ', df1.drop_duplicates().shape)
print('未去重: ', df2.shape)
print('去重: ', df2.drop_duplicates().shape)
print('未去重: ', df3.shape)
print('去重: ', df3.drop_duplicates().shape)
print('**************************************************')
print(df1.info())
print('**************************************************')
print(df2.info())
print('**************************************************')
print(df3.info())
print('**************************************************')
print('**************************************************')
print(df1.describe())
print('**************************************************')
print(df2.describe())
print('**************************************************')
print(df3.describe())
print('**************************************************')
'''
**************************************************
(4341, 5)
**************************************************
(519367, 14)
**************************************************
(43156, 6)
**************************************************
# 检查重复值
均无重复值
df1.describe().to_csv('data1_describe.csv')
df2.describe().to_csv('data2_describe.csv')
df3.describe().to_csv('data3_describe.csv')
'''
# 重新摆放列位置
columns = ['CardNo', 'Date', 'Money', 'FundMoney', 'Surplus', 'CardCount', 'Type', 'TermNo', 'OperNo',
'Dept']
df2 = pd.DataFrame(df2, columns=columns)
#print(df2.head())
# 观察消费总额和消费次数之间的关系
#df2.to_csv('task1_1.csv')
#df_money_amount=df2.groupby('CardNo')['Money'].sum().sort_values(ascending=False).to_frame().reset_index()
#df_money_times=df2.groupby('CardNo')['CardCount'].max().sort_values(ascending=False).to_frame().reset_index()
#sns.regplot(x='Money',y='CardCount',data=df2)
#plt.show()
sns.distplot(df2['CardCount'],bins=100,color='r')
sns.kdeplot(df2['CardCount'],shade=True)
'''
通过 distplot 和 kdeplot 绘制柱状图观察 CardCount 特征的分布情况,属于长尾类型的分布,
这说明了有很多消费次数过多且超出正常范围。
也可能是年级较为高的学生
'''
plt.show()
task2.py
import pandas as pd
'''
任务 1.2 将 data1.csv 中的学生个人信息与 data2.csv 中的消费记录建立
关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与
data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
'''
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
# 导入数据
df1 = pd.read_csv('data1.csv', encoding='gbk')
df2 = pd.read_csv('data2.csv', encoding='gbk')
df3 = pd.read_csv('data3.csv', encoding='gbk')
data1_2=df1.merge(df2,left_on='CardNo',right_on='CardNo')
data1_2.rename(columns={"Index_x": "Stu_Index"}, inplace=True)
data1_2.rename(columns={"Index_y": "Con_Index"}, inplace=True)
#print(data1_2.head())
data1_3=df1.merge(df3,left_on='AccessCardNo',right_on='AccessCardNo')
data1_3.rename(columns={"Index_x": "Stu_Index"}, inplace=True)
data1_3.rename(columns={"Index_y": "Acc_Index"}, inplace=True)
#print(data1_3.head())
data1_2.to_csv('task1_2_1.csv')
data1_3.to_csv('task1_2_2.csv')
其他代码,文章篇幅有限,略