1.8. 数据 存储 ( CommitLog、MemTable、SSTable )
写请求分别到 CommitLog 和 MemTable, 并且 MemTable 的数据会刷写到磁盘 SSTable 上. 除
了写数据,还有索引也会保存到磁盘上.
先将数据写到磁盘中的 commitlog,同时追加到中内存中的数据结构 memtable 。这个时候就会
返 回 客 户 端 状 态 , memtable 内 容 超 出 指 定 容 量 后 会 被 放 进 将 被 刷 入 磁 盘 的 队 列
(memtable_flush_queue_size 配置队列长度)。若将被刷入磁盘的数据超出了队列长度,将内存
数据刷进磁盘中的 SSTable,之后 commit log 被清空。
SSTable 文件构成(BloomFilter 、index 、data 、static )
SSTable 文件有fileer(判断数据key是否存在,这里使用了BloomFilter提高效率),index(寻
找对应 column 值所在 data 文件位置)文件,data(存储真实数据)文件,static(存储和统计
column 和 row 大小)文件。
1.9. 二级索引(对要索引的 (对要索引的 value 摘要,生成 RowKey )
在 Cassandra 中,数据都是以 Key-value 的形式保存的。
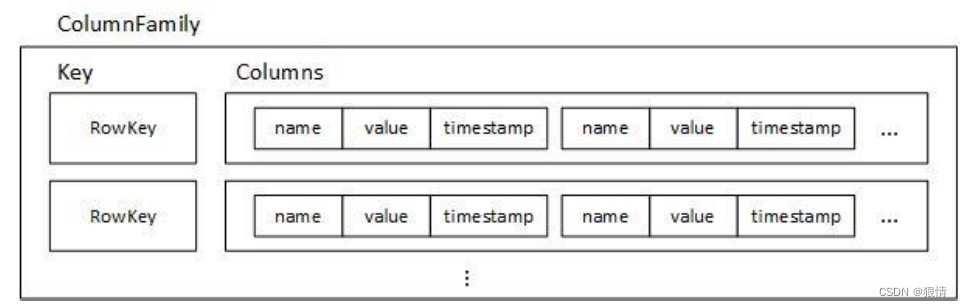
KeysIndex 所创建的二级索引也被保存在一张 ColumnFamily 中。在插入数据时,对需要进行索
引的value进行摘要,生成独一无二的key,将其作为RowKey保存在索引的ColumnFamily中;
同时在 RowKey 上添加一个 Column,将插入数据的 RowKey 作为 name 域的值,value 域则赋
空值,timestamp 域则赋为插入数据的时间戳。
如果有相同的 value 被索引了,则会在索引 ColumnFamily 中相同的 RowKey 后再添加新的
Column。如果有新的 value 被索引,则会在索引 ColumnFamily 中添加新的 RowKey 以及对应
新的 Column。
当对 value 进行查询时,只需计算该 value 的 RowKey,在索引 ColumnFamily 中的查找该
RowKey,对其 Columns 进行遍历就能得到该 value 所有数据的 RowKey。
1.10. 数据读写
数据写入和更新(数据追加) (数据追加)
Cassandra 的设计思路与这些系统不同,无论是 insert 还是 remove 操作,都是在已有的数据后面进行追加,而不修改已有的数据。这种设计称为 Log structured 存储,顾名思义就是系统中的数据是以日志的形式存在的,所以只会将新的数据追加到已有数据的后面。Log structured 存储
系统有两个主要优点:
数据的写和删除效率极高
传统的存储系统需要更新元信息和数据,因此磁盘的磁头需要反复移动,这是一个比较耗时
的操作,而 Log structured 的系统则是顺序写,可以充分利用文件系统的 cache,所以效率
很高。
错误恢复简单
由于数据本身就是以日志形式保存,老的数据不会被覆盖,所以在设计 journal 的时候不需
要考虑 undo,简化了错误恢复。
读的复杂度高
但是,Log structured 的存储系统也引入了一个重要的问题:读的复杂度和性能。理论上
说,读操作需要从后往前扫描数据,以找到某个记录的最新版本。相比传统的存储系统,这
是比较耗时的。
参考:https://blog.csdn.net/fs1360472174/article/details/55005335
数据删除( (column 的墓碑 的墓碑) )
如果一次删除操作在一个节点上失败了(总共 3 个节点,副本为 3, RF=3).整个删除操作仍然被
认为成功的(因为有两个节点应答成功,使用 CL.QUORUM 一致性)。接下来如果读发生在该节
点上就会变的不明确,因为结果返回是空,还是返回数据,没有办法确定哪一种是正确的。
Cassandra 总是认为返回数据是对的,那就会发生删除的数据又出现了的事情,这些数据可以叫”
僵尸”,并且他们的表现是不可预见的。
墓碑
删除一个 column 其实只是插入一个关于这个 column 的墓碑(tombstone),并不直接删除原
有的 column。该墓碑被作为对该 CF 的一次修改记录在 Memtable 和 SSTable 中。墓碑的内容
是删除请求被执行的时间,该时间是接受客户端请求的存储节点在执行该请求时的本地时间
(local delete time),称为本地删除时间。需要注意区分本地删除时间和时间戳,每个 CF 修改
记录都有一个时间戳,这个时间戳可以理解为该 column 的修改时间,是由客户端给定的。
垃圾回收 compaction
由于被删除的 column 并不会立即被从磁盘中删除,所以系统占用的磁盘空间会越来越大,这就
需要有一种垃圾回收的机制,定期删除被标记了墓碑的 column。垃圾回收是在 compaction 的过
程中完成的。
数据读取 ( memtable+SStables )
为了满足读 cassandra 读取的数据是 memtable 中的数据和 SStables 中数据的合并结果。读取
SSTables 中的数据就是查找到具体的哪些的 SSTables 以及数据在这些 SSTables 中的偏移量
(SSTables 是按主键排序后的数据块)。首先如果 row cache enable 了话,会检测缓存。缓存命中
直接返回数据,没有则查找 Bloom filter,查找可能的 SSTable。然后有一层 Partition key cache,
找 partition key 的位置。如果有根据找到的 partition 去压缩偏移量映射表找具体的数据块。如果
缓存没有,则要经过 Partition summary,Partition index 去找 partition key。然后经过压缩偏移
量映射表找具体的数据块。
1. 检查 memtable
2. 如果 enabled 了,检查 row cache
3. 检查 Bloom filter
4. 如果 enable 了,检查 partition key 缓存
5. 如果在 partition key 缓存中找到了 partition key,直接去 compression offset 命中,如果没
有,检查 partition summary
6. 根据 compression offset map 找到数据位置
7. 从磁盘的 SSTable 中取出数据
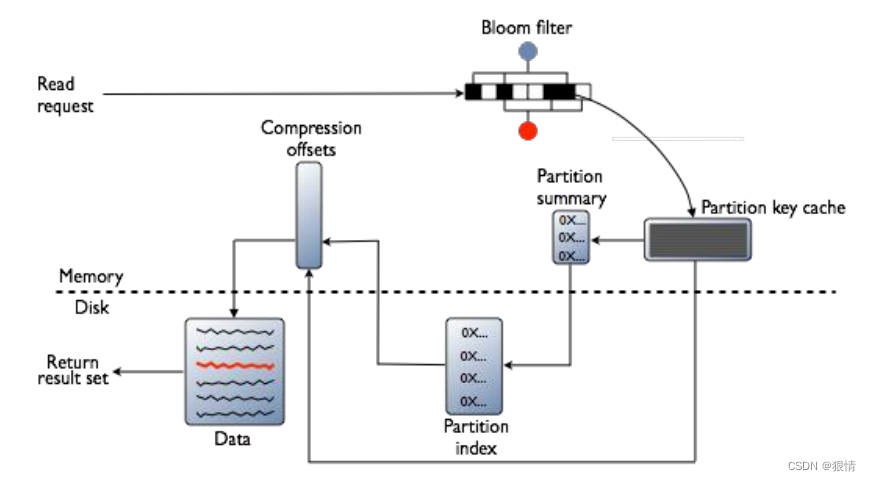
行缓存和键缓存请求流程图
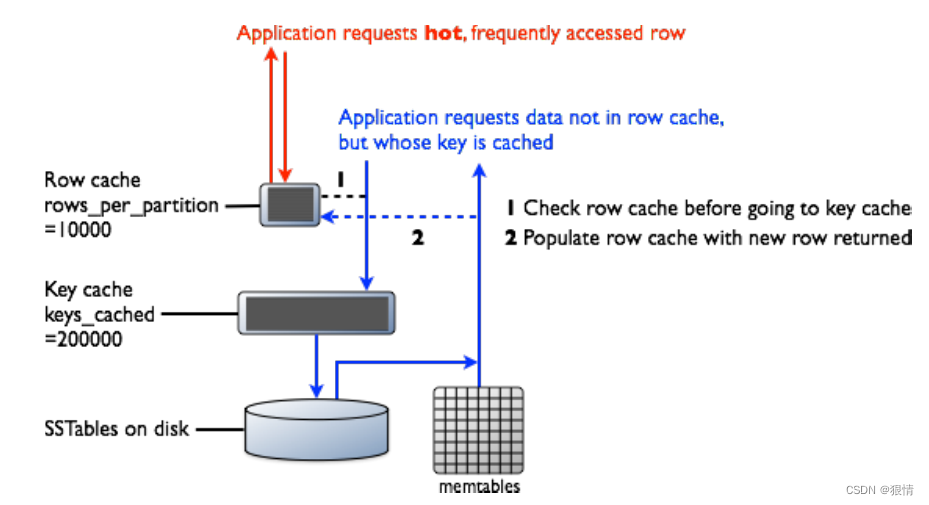
MemTable:如果 memtable 有目标分区数据,这个数据会被读出来并且和从 SSTables 中读出
来的数据进行合并。SSTable 的数据访问如下面所示的步骤。
Row Cache ( SSTables 中频繁被访问的数据 )
在 Cassandra2.2+,它们被存储在堆外内存,使用全新的实现避免造成垃圾回收对 JVM 造成压力。
存在在 row cache 的子集数据可以在特定的一段时间内配置一定大小的内存。row cache 使用
LRU(least-recently-userd)进行回收在申请内存。存储在 row cache 中的数据是 SSTables 中频繁
被访问的数据。存储到row cache中后,数据就可以被后续的查询访问。row cache不是写更新。
如果写某行了,这行的缓存就会失效,并且不会被继续缓存,直到这行被读到。类似的,如果一
个partition更新了,整个partition的cache都会被移除,但目标的数据在row cache中找不到,
就会去检查 Bloom filter。
Bloom Filter ( 查找数据可能对应的 SSTable )
首先,Cassandra 检查 Bloom filter 去发现哪个 SSTables 中有可能有请求的分区数据。Bloom
filter 是存储在堆外内存。每个 SSTable 都有一个关联的 Bloom filter。一个 Bloom filter 可以建
立一个 SSTable 没有包含的特定的分区数据。同样也可以找到分区数据存在 SSTable 中的可能性。
它可以加速查找 partition key 的查找过程。然而,因为 Bloom filter 是一个概率函数,所以可能
会得到错误的结果,并不是所有的 SSTables 都可以被 Bloom filter 识别出是否有数据。如果
Bloom filter 不能够查找到 SSTable,Cassandra 会检查 partition key cache。Bloom filter 大小
增长很适宜,每 10 亿数据 1~2GB。在极端情况下,可以一个分区一行。都可以很轻松的将数十
亿的 entries 存储在单个机器上。Bloom filter 是可以调节的,如果你愿意用内存来换取性能。
Partition Key Cache ( 查找数据可能对应的 Partition key )
partition key 缓存如果开启了,将 partition index 存储在堆外内存。key cache 使用一小块可配
置大小的内存。在读的过程中,每个”hit”保存一个检索。如果在 key cache 中找到了 partition
key。就直接到 compression offset map 中招对应的块。partition key cache 热启动后工作的更
好,相比较冷启动,有很大的性能提升。如果一个节点上的内存非常受限制,可能的话,需要限
制保存在 key cache 中的 partition key 数目。如果一个在 key cache 中没有找到 partition key。
就会去partition summary中去找。partition key cache 大小是可以配置的,意义就是存储在key
cache 中的 partition keys 数目。
Partition Summary ( 内存中 存储一些 partition index 的样本 )
partition summary 是存储在堆外内存的结构,存储一些 partition index 的样本。如果一个
partition index 包含所有的 partition keys。鉴于一个 partition summary 从每 X 个 keys 中取
样,然后将每X个key map到index 文件中。例如,如果一个partition summary设置了20keys
进行取样。它就会存储 SSTable file 开始的一个 key,20th 个 key,以此类推。尽管并不知道
partition key 的具体位置,partition summary 可以缩短找到 partition 数据位置。当找到了
partition key 值可能的范围后,就会去找 partition index。通过配置取样频率,你可以用内存来
换取性能,当 partition summary 包含的数据越多,使用的内存越多。可以通过表定义的 index
interval 属性来改变样本频率。固定大小的内存可以通过 index_summary_capacity_in_mb 属性
来设置,默认是堆大小的 5%。
Partition Index (磁盘中)
partition index 驻扎在磁盘中,索引所有 partition keys 和偏移量的映射。如果 partition
summary 已经查到 partition keys 的范围,现在的检索就是根据这个范围值来检索目标 partition
key。需要进行单次检索和顺序读。根据找到的信息。然后去 compression offset map 中去找磁
盘中有这个数据的块。如果 partition index 必须要被检索,则需要检索两次磁盘去找到目标数据。
Compression offset map (磁盘中)
compression offset map 存储磁盘数据准确位置的指针。存储在堆外内存,可以被 partition key
cache 或者 partition index 访问。一旦 compression offset map 识别出来磁盘中的数据位置,
就会从正确的 SStable(s)中取出数据。查询就会收到结果集。