欢迎来到魔法宝库,传递AIGC的前沿知识,做有格调的分享❗
喜欢的话记得点个关注吧!
今天,我们将共同探索OpenAI的GPT-2,跟随论文深入理解其技术细节。
论文:Language Models are Unsupervised Multitask Learners
模型参数:15亿
公司/机构:OpenAI
摘要
GPT-2是自然语言处理领域的重要里程碑作品,采用了Transformer模型,展现出强大的语言生成能力。作为OpenAI开发的杰出之作,GPT-2令人惊叹。它的模型规模达到了15亿,并通过在大规模语料库WebText 上进行自监督学习进行了训练。
GPT-2的设计思想是通过大量网络文本数据的学习,以无监督的方式掌握语言的模式和结构。在没有具体任务指导的情况下,GPT-2能够生成与人类书写风格相似且连贯的文本,并回答输入文本中提出的问题。
它在语言建模任务上表现出色,在多个自然语言处理任务中都取得了优秀的效果,例如文本生成、机器翻译、问答系统和生成摘要等。GPT-2的卓越之处在于其能够进行零样本迁移学习,即在未经过训练的任务上也能表现出良好的性能。
何为语言模型
GPT-2是一款经典的语言模型,关于什么是语言模型,我们来聊聊。
语言模型是针对语言序列进行建模和预测的统计模型或神经网络模型。它通过学习大量的文本数据,深化对语言规律和结构的理解,并以概率分布的形式表达字符序列的生成概率。 语言模型通常被定义为对一组样本(x1, x2, ..., xn) 进行无监督估计的分布模型,其中每个样本由可变长度的符号序列(s1, s2, ..., sn) 组成。由于语言具有内在的顺序性,通常将联合概率表示为符号的条件概率乘积:
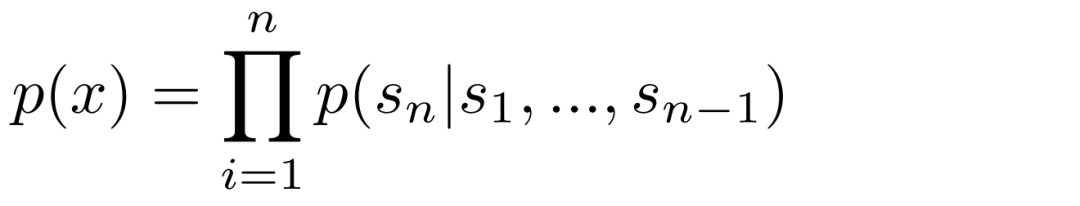
这种方法可以方便地从概率分布p(x)中进行抽样,同时也能够对形如下式的条件概率进行估计:
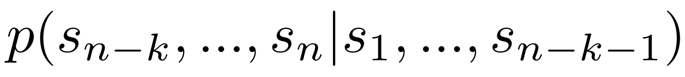
其中,sn−k,...,sn表示当前待预估的符号序列,s1,...,sn-k-1表示给定的上下文序列,通过学习这些条件概率,模型可以更好地理解语言的上下文关系并生成合适的文本。
语言模型可以用于评估句子的合理性,也可以生成新的句子。它能够预测在给定上下文的情况下下一个词或字是什么,或者在给定一段文本的情况下预测接下来的文本是什么。语言模型可以捕捉到词语之间的依赖关系和句子的上下文信息,从而使生成的文本更加连贯和准确。
输入法中的联想功能是语言模型的一个典型应用,例如,当我们输入"你好"时,输入法会为我们提供下一个字或词的候选项供选择。
GPT-2基本原理
语言建模是一项无监督学习任务,其目标是从一组包含可变长度符号的样本中学习符号出现的概率分布。
GPT-2旨在基于已观察到的输入序列来预测下一个符号。此外,GPT-2引入了多任务学习的概念,通过在语言建模过程中引入任务条件,使得模型能够执行多个不同的任务。具体而言,使用符号序列来表示任务、输入和输出,并利用条件概率p(output|input, task)进行建模。通过共享模型的参数,GPT-2能够推断和执行多样的任务。其中,output表示预测的输出符号,input表示模型的输入符号序列,task表示任务标识。
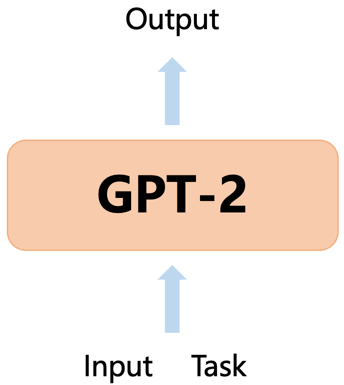
GPT-2主要基于Transformer Decoder构建,利用Transformer架构中的自注意力机制来捕捉输入序列中的依赖关系,从而学习输入和输出之间的联系。
GPT-2在很大程度上继承了OpenAI GPT-1模型的细节,并进行了一些改进。GPT-2的模型结构图如下所示:
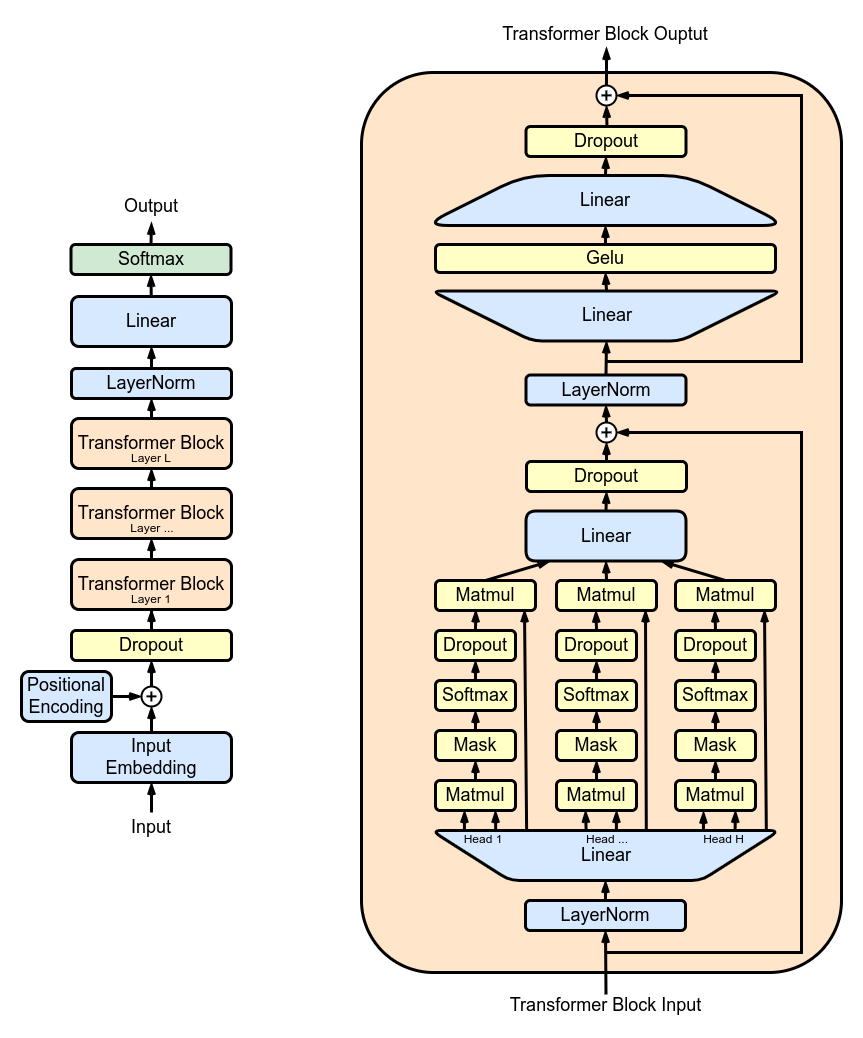
为了更好地处理信息,GPT-2对每个子块的输入进行了Layer Normalization,即在处理之前对数据进行归一化,以便更好地进行处理。这类似于使用预激活残差网络的方法,可以提升模型性能。此外,GPT-2 在最后的自注意力块之后也添加了Layer Normalization。
为了更好地初始化模型参数,GPT-2采用了一种改进的初始化方法,即将残差层的权重缩放因子设置为1/√N,其中N代表残差层的数量。这种初始化方法考虑了模型深度对残差路径上累积效应的影响。
为了增强模型的表达能力, GPT-2扩展了词汇表,使其包含50257个词汇,从而使模型能够更准确地理解和生成多样化的文本。此外,GPT-2还增加了上下文的大小,从原先的512个tokens扩大到1024 个tokens,这使得模型能够更好地理解更长的文本片段。批大小设置为512。
总结
GPT-2的显著特点是它的零样本迁移学习能力,这使得它能够在处理新任务时不需要对其进行显式的训练。这是GPT-2模型的一个最为突出的特点,也是它在自然语言处理领域具有重要意义的原因之一。
如果对AIGC感兴趣,请关注我们的微信公众号“我有魔法WYMF”,我们会定期分享AIGC最新咨询和经典论文精读分享,让我们一起交流学习!!