Explain详细说明:
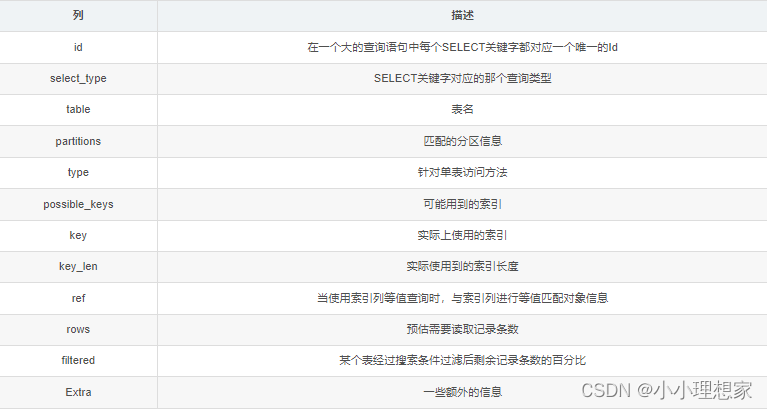
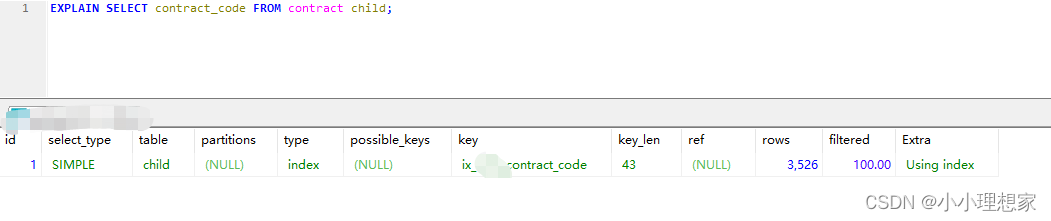
id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。MySQL将 select 查询分为简单查询(SIMPLE)和复杂查询(PRIMARY)。
复杂查询分为三类:简单子查询、派生表(from语句中的子查询)、union 查询
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行
** table列**
表示 explain 的一行正在访问哪个表
type列
这一列表示关联类型或访问类型,即Mysql决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system >const -> eq_ref > ref > range > index > ALL
index:扫描全表索引,这通常比ALL快一些。(index是从索引中读取的,而all是从硬盘中读取)
possible_keys列
这一列显示查询可能使用哪些索引来查找
key列
这一列显示mysql实际采用哪个索引来优化对该表的访问
key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
字符串
char(n):n字节长度
varchar(n):2字节存储字符串长度,如果是utf-8,则长度3n+2
数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为NULL,需要1字节记录是否为NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前部部分的字符提取出来做索引。
一般情况下key_len值越小越好,索引越短,既节约空间,速度又比较快
ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名
rows列
这一列是mysql估计要读取并检测的行数
filtered
某个表经过搜索条件过滤后剩余记录条数的百分比
Extra列
Using index:查询的列被索引覆盖,并且where筛选条件是索引的前导列(最左侧索引),是性能高的表现。一般是使用了覆盖索引(索引包含了所有查询的字段)。对于innodb来说,如果是辅助索引性能会有不少提高
Using where:查询的列未被索引覆盖,where筛选条件非索引的前导列
Using where Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一但不是索引的前导列,意味着无法直接通过索引查找来查询到符合条件的数据,Using index代表select用到了覆盖索引
NULL:查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是纯粹地用到了索引,也不是完全没用到索引
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
actor.name没有索引,此时创建了张临时表来distinct
film.name建立了idx_name索引,此时查询时extra是using index,没有用临时表