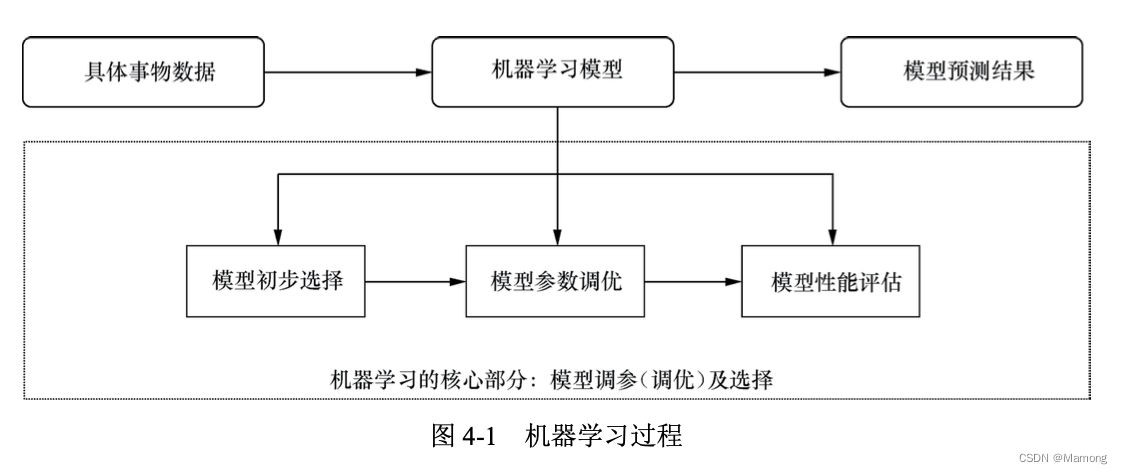
4.1 通俗讲解机器学习是什么
4.1.1 究竟什么是机器学习
卡内基梅隆大学机器学习领域的著名学者汤姆·米切尔曾经在 1997 年对机器学习做出过更为严谨和经典的定义:
A program can be said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
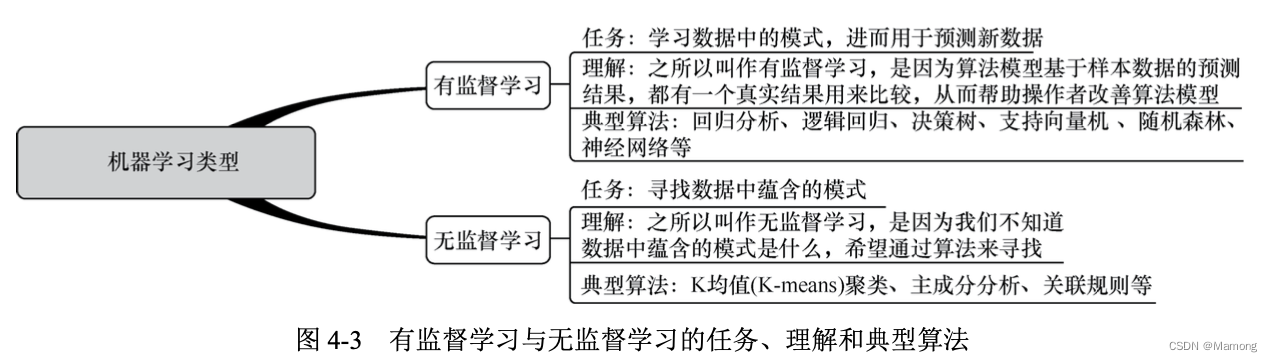
翻译过来就是,假设用 P 来评估计算机程序在某一项任务 T 上的性能表现,如果程序能够利用经验 E 提升在任务 T 上的性能表现,那么我们就说对于任务 T 的性能 P,这个程序对经验 E 进行了学习。从米切尔的定义中,我们也可以发现机器学习的 3 个重要概念:任务(Task)、 经验(Experience)和性能(Performance)。
机器学习有时候又被称为统计学习,它是计算机基于数据来构建概率统计模型并运用模型对 数据进行分析和预测的学科。机器学习基于统计方法,以计算机为工具对数据进行分析和预测。 之所以将其称为“统计学习”或者“机器学习”,是因为统计学习具有“自我改进”的特征。
器学习已经开始在各种场景之中广泛使用。
(1)营销场景:商品推荐、用户画像系统、广告精准投放。
(2)文本挖掘场景:新闻分类、关键词提取、文本情感分析。
(3)社交关系挖掘场景:微博用户领袖分析、社交关系链分析。
(4)金融反欺诈场景:贷款发放、金融风控。
(5)非结构化数据场景:人脸识别、图片分类、光学字符识别(OCR)等。
4.1.2 机器学习的分类
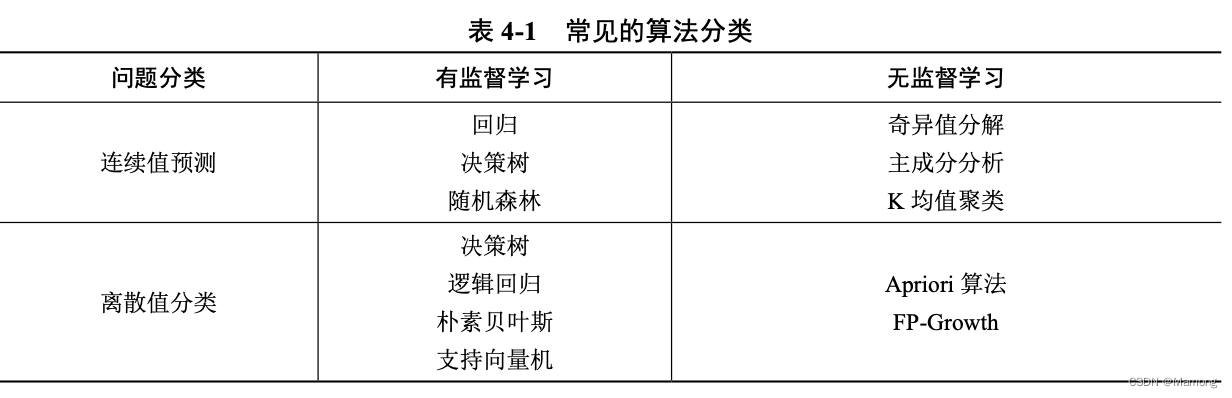
(1)按照是否有监督,机器学习可以分为有监督学习和无监督学习。
(2)按照预测值是连续还是离散,机器学习可以分为分类和回归。
4.2 机器学习所需环境介绍
4.2.1 Python的优势
4.2.2 Python下载、安装及使用
4.3 跟着例子熟悉机器学习全过程
4.4 准备数据包括什么
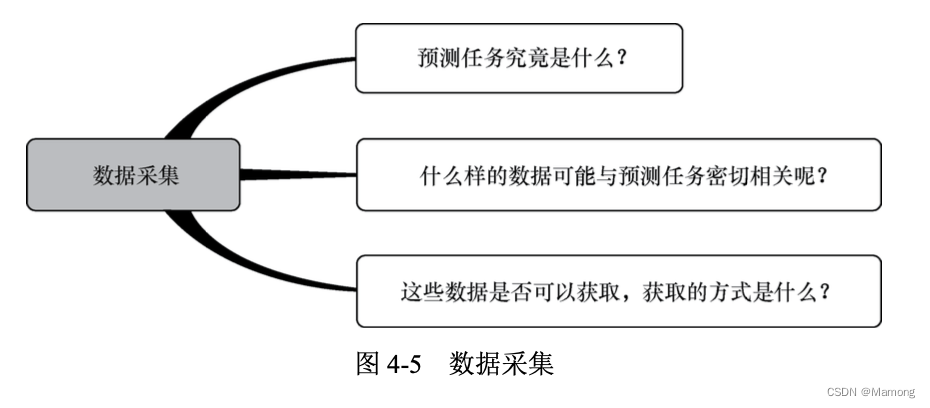
准备数据包含多个环节, 例如数据采集、数据清洗、不均衡样本处理、数据类型转换、数据标准化、特征工程等。
4.4.1 数据采集
4.4.2 数据清洗
数据清洗,顾名思义就是把“脏”数据“清洗”干净,使数据能够使用的过程,常包括数 据一致性检查,数据缺失值、错误值或无效值的纠正等。
4.4.3 不均衡样本处理
很多情况下,数据 的正负样本是不均衡的,而大多数算法模型又对正负样本比较敏感,所以还需要进行样本均衡 处理。
(1)如果正负样本数量较多,且正样本远多于负样本,则采用下采样方法来处理。
(2)如果正样本远多于负样本,且负样本数量较少,则可以采取上采样方法来处理。
4.4.4 数据类型转换
(1)连续数据离散化
连续数据离散化是一种常见的数值型数据预处理方法。在某些情况下,特征离散化会大大增 加模型的稳定性。某些算法模型本身也对数据有着离散化的要求。
模型究竟采用离散特征还是连续特征,是一个 “海量离散特征 + 简单模型”与“少量连续特征 + 复杂模型”的权衡问题。处理同一个问题,你可以采用线性模型处理离散化特征的方式,也可以采用深度学习处理连续特征的方式,各有利弊。不过从实践角度来讲,采用离散特征往往更加容易和成熟。
(2)类别数据数值化
计算机能够处理的是数值型数据,但是原始数据集中却常常有类别型数据,例如性别有男 和女,类别型数据需要通过一定的方法转换成数值型数据,才能够被计算机所处理。常见的 转换方法有 one-hot 编码。one-hot 编码也叫“独热码”,简单地讲就是有多少个状态就有多少比 特,其中只有一比特为 1,其他全为 0 的一种编码机制。由于性别特征总共有两个不同的分类值,采用 one-hot 编码,男性可以 表示为 {10},女性可以表示为 {01}。假如多个特征需要 one-hot 编码,则可以依次将每个特征的 one-hot 编码拼接起来。除了 one-hot 编码外,类别型数据也可以采用散列方法来处理。
4.4.5 数据标准化
数据标准化是特征处理环节中非常重要的一步,主要是为了消除不同指标量纲带来的影响, 提高不同数据指标之间的可比性。数据标准化方法如下。
(1)最大值-最小值(max-min)标准化:最大值-最小值标准化也称为离差标准化,主要是将原始指标缩放到 0 ~ 1,相当于对原变量做了一次线性变化。
(2)z-score 标准化:这是一种较为常见的数据标准化方法,几乎所有线性模型进行拟合时 都会考虑使用 z-score 标准化。主要是将数据转换为均值为 0、标准 差为 1 的正态分布。
4.4.6 特征工程
(1)特征工程概述。
通过特征工程对数据进行预处理,能够降低算法模型受噪声干扰的程度,能够更好地找出 发展趋势。特征工程的目的是筛选出更好的特征,获取更好的训练数据。因为更好的特征意味 着特征具有更强的灵活性,可以使用更简单的算法模型同时得到更优秀的训练结果。一般来说, 特征工程可以分为特征构建、特征提取、特征选择 3 种方式。

(2)特征选择。
特征选择是使用最为广泛的特征工程技术,一方面是因为部分特征之间相关度较高导致特征冗余,从而容易造成计算资源浪费,需要进行特征选择来降低计算资源的浪费;另一方面是因为部分特征是噪声,会对预测结果产生负面影响,需要进行特征选择。
特征选择的技巧和方法:
第一,过滤法。过滤法主要是评估某个特征与预测结果之间的相关度,对相关度进行排序, 保留排序靠前的特征维度。实践中经常使用 pearson 相关系数、距离相关度等指标来进行相关度度量。
第二,包装法。首先使用全量特征进行算法模型构建,得到基础模型;然后根据线性模型系数,删除部分弱特征后观察模型预测能力的变化情况,当模型预测能力大幅下降时停止删除弱特征。最常用的包装法是递归消除特征法。
第三,嵌入法。使用正则化方法来对特征进 行处理,正则化惩罚项越大,模型的系数就会越小,而当正则化 惩罚项大到一定的程度时,部分特征系数会趋于 0。这部分特征就可以先剔除,只保留 特征系数较大的特征。
4.5 如何选择算法
4.5.1 单一算法模型
4.5.2 集成学习模型
集成学习通过构 建多个学习器并将其结合,从而更好地完成预测任务,也常被称为模型融合或者基于委员会的 学习。
融合模型根据个体学习器生成方式的不同,可以分为两大类:个体学习器之间存在 强依赖关系、必须串行生成的序列化算法,代表算法是 Boosting ;个体学习器之间不存在强依 赖关系、可同时生成的并行化算法,代表算法是 Bagging 和随机森林。
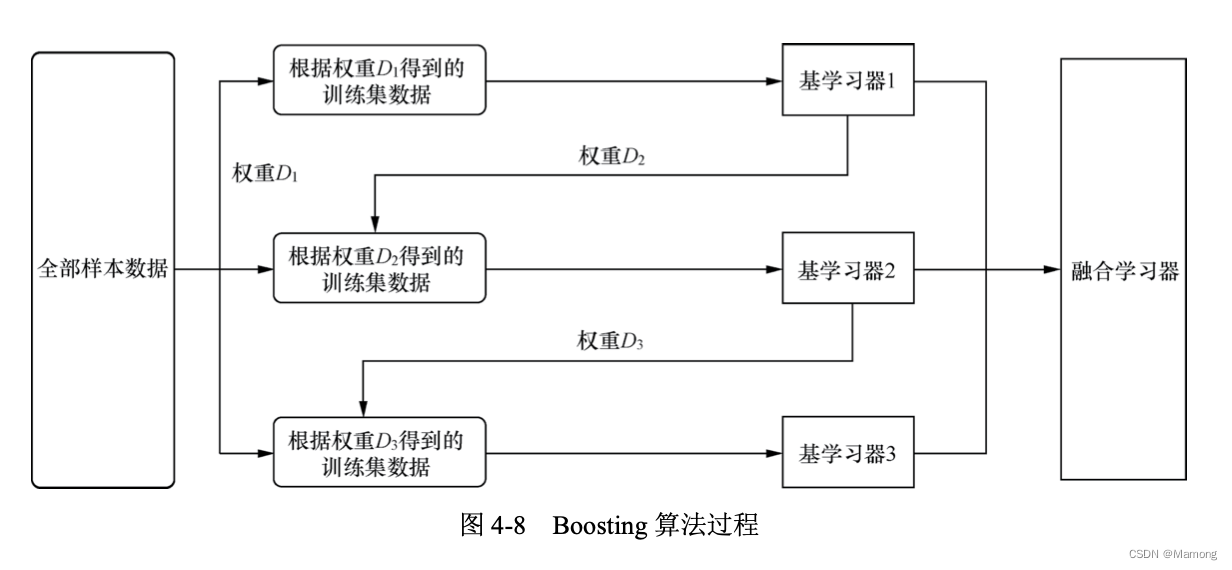
1.Boosting
Boosting 算法的思想是,首先从初始训练集中训练一个基学习器,基学习器对不同的样本 数据有着不同的预测结果,有些样本基学习器能够很好地预测,有些则不能;对于预测错误的 样本,增加其权重后,再次训练下一个基学习器;如此反复进行,直到基学习器数目达到事先指定的数值 T,然后将 T 个基学习器进行加权结合。Boosting 算法实际上是算法族,表示一系 列将基学习器提升为强学习器的算法。典型的 Boosting 算法有 AdaBoost。
2.Bagging 和随机森林
Bagging 算法的思想是通过尽可能增加每个学习器训练集的差异来使得学习器之间产生较大差异,从而避免各个学习器雷同。具体做法:第一,从原始样 本集中抽取训练集,每次随机抽取 n 个训练样本抽取 T 次得到 T 个训练集;第二,每次使用一个训练集得到 一个模型,T 个训练集共得到 T 个模型;第三,对上述 T 个学习器采取某种策略进行结合。一 般来说,Bagging 对分类问题通常采用简单投票法,对回归问题通常采用简单平均法。
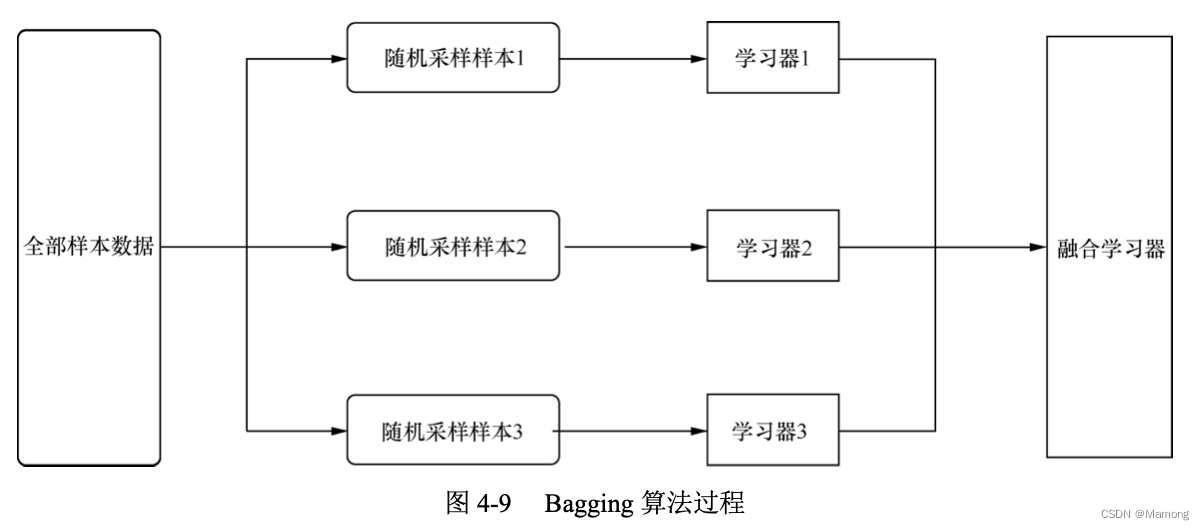
随机森林使用了分类与回归树作为弱学习器,并对决策树的建立做了改进,通过随机选择节点上的一部分样本特征进 一步增强了模型的泛化能力。随机森林的“随机”主要体现在两方面:数据的随机 选择、待选特征的随机选择。
4.5.3 算法选择路径
(1)观察数据量大小。如果数据量太小(例如样本数小于 50),那么首先要做的应该是获 取更多的数据。
(2)问题类型。究竟是连续值预测还是离散值分类。
(3)分类问题解决。分类问题根据数据是否存在标签数据,可以分为有监督分类问题和无 监督分类问题。如果数据存在标签数据,那么我们可以采用有监督分类算法来予以解决,例 如可以采取 LR、支持向量机(Support Vector Machine,SVM)或者梯度提升决策树(Gradient Boosting Decision Tree,GBDT)等算法;如果数据不存在标签数据,那么我们可以采用一些无 监督算法来予以解决,例如聚类算法。
(4)连续值预测问题解决。如果特征维度不是特别多,我们可以直接采用回归算法来处理;如果特征维度很多则需要先进行降维处理。
4.6 调参优化怎么处理
4.6.1 关于调参的几个常识
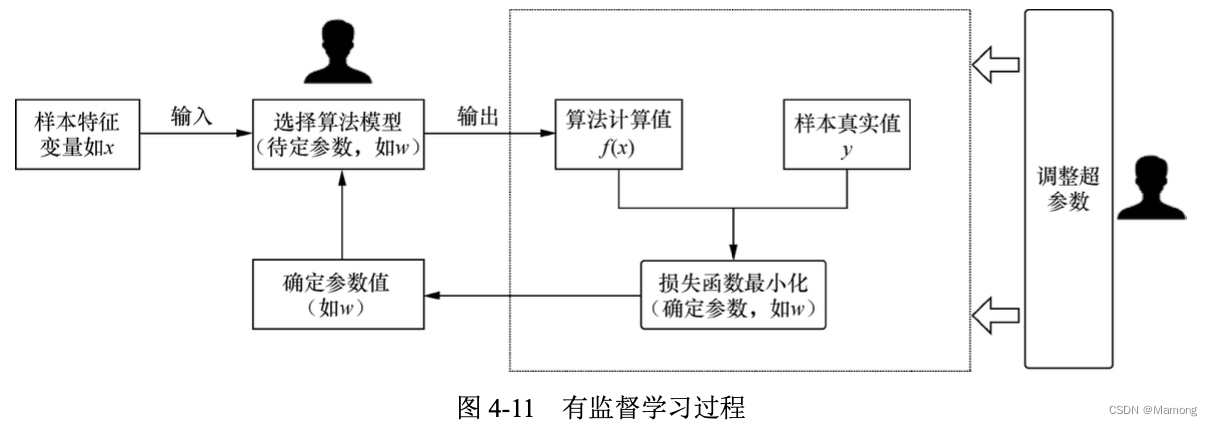
(1)机器学习通过训练数据得到一个具体算法模型的过程,就是确定这个算法模型参数的 过程。
(2)超参数是在模型训练前我们手动设定的。超参数设定的目的是更快、更好地得到算法 模型的参数。而我们一般谈论的调参指的实际上是调整超参数。
(3)如果以线性回归算法为例,回归模型一般表达式里面的系数 ω 和 b 是参数,而正则项 的惩罚系数就是超参数。神经网络算法中,节点的权重是参数,而神经网络的层数和每层节点 个数就是超参数。
有监督学习的核心环节就是选择合适的算法模型和调整超参数,通过损失函数最小化来 为算法模型找到合适的参数值,确定一个泛化性能良好的算法模型。
4.6.2 模型欠拟合与过拟合
欠拟合和过拟合是导致模型泛化能力不高的两种常见原因。“欠拟合”是指模型学习能力较弱,无法学习到样本数据中的“一般规律”,因此导致模型泛化能力较弱。而“过拟合”则恰好 相反,是指模型学习能力太强,以至于将样本数据中的“个别特点”也当成了“一般规律”,因 此导致模型泛化能力同样较弱。
欠拟合的解决解决办法是,提高学习器的学习能力,例如在决策树中扩展分支数量或者在神经网络算法中增加训练轮数等。
过拟合产生的原因是模型“过度用力”去学习训练样本的分布情况,甚至把噪声特征也学习到了,从而导致模型的普适性不 够。常见的解决方法包括增大样本量和正则化。
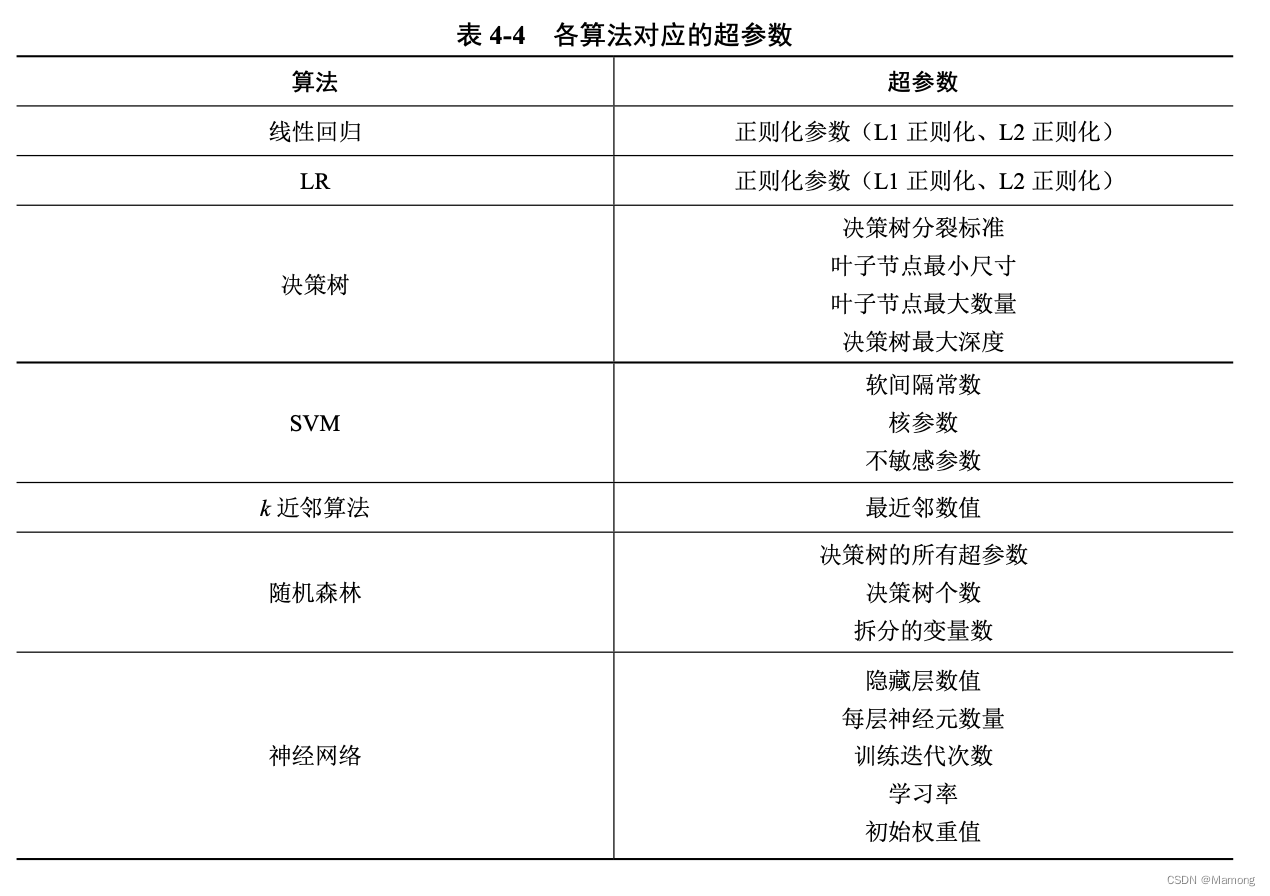
4.6.3 常见算法调参的内容
线性算法需要调 整的超参数主要是正则化系数,而决策树算法需要调整的超参数主要是决策树最大深度、决策 树分裂标准等。
4.6.4 算法调参的实践方法
通常情况下,算法模型的超参数可以手动设定(如 k 近邻算法中的 k 值)。但由于超参数组 合空间巨大,手动设定超参数的过程过于繁杂,这个时候我们就可以考虑使用网格搜索(Grid Search)方法来寻找合适的超参数。网格搜索本质上是穷举所有的超参数组合。
4.7 如何进行性能评估
根据机器学习问题类型的不同,算法模型有着不同的性能度量标准。回归预测问题通常采用平均绝对误差、均方误差等指标来度量算法模型的预测能力。分类问题则通过采用精度与错误率、查全率(Recall)与查准率(Precision)等指标来度量算法模型的预测能力。
4.7.1 回归预测性能度量
(1)平均绝对误差。各预测值偏离真实值的绝对值之和的平均数。
(2)均方误差。误差平方和的平均数。
4.7.2 分类任务性能度量
(1)精度与错误率。精度是分类正确的样本数占样本总数的比例,错误率是分类错误的样本数占样本总数的比例。
(2)查全率与查准率。查全率也被称为“召回率”,查准率也被称为“准确率”。大家可以这样记忆:查全率表示有多少癌症患 者被医院真正检测出来了(比例),查准率表示医院检测出来的癌症患者有多少真的是癌症患者(比例)。一般来说,如果要求查准率比较高,那么查全率就会比较 低;而如果要求查全率比较高,那么查准率就会比较低。
![[C/C++]数据结构 链表OJ题 : 链表中倒数第k个结点](https://img-blog.csdnimg.cn/aa67e8afba5c4036891a0dc39cbd2090.png)






![CNVD-2023-08743:宏景HCM SQL注入漏洞复现 [附POC]](https://img-blog.csdnimg.cn/8b95f8617da244c28eaf7e2dd8f92369.png)