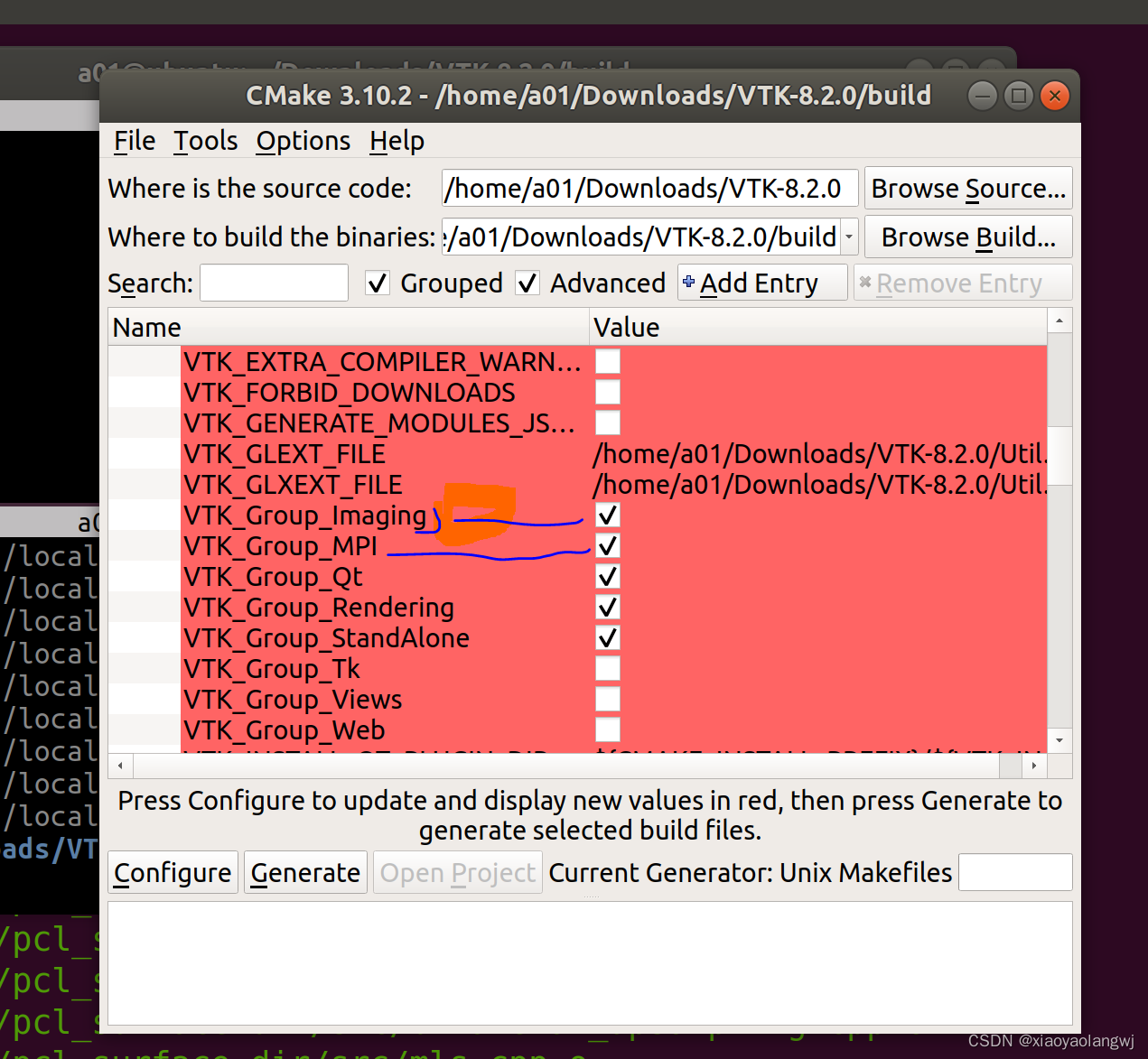
这是一个使用 Perl 和爬虫ip服务器来爬取图书网站信息采集的示例代码。以下每行代码的中文解释:

use LWP::UserAgent;
use HTTP::Proxy;
use HTML::TreeBuilder;
# 创建爬虫ip服务器
my $proxy = HTTP::Proxy->new(
host => "www.duoip.cn",
port => 8000,
);
# 创建用户爬虫ip
my $ua = LWP::UserAgent->new(proxies => $proxy);
# 设置要爬取的网站的 URL
my $url = '目标网址';
# 使用用户爬虫ip访问网站
my $response = $ua->get($url);
# 检查请求是否成功
if ($response->is_success) {
# 解析 HTML 页面
my $tree = HTML::TreeBuilder->new();
$tree->parse($response->decoded_content);
# 找到需要的信息
my $title = $tree->look_down(_tag => 'title')->as_text;
my $author = $tree->look_down(_tag => 'span', att => { class => 'author' })->as_text;
my $price = $tree->look_down(_tag => 'span', att => { class => 'price' })->as_text;
print "Title: $title\n";
print "Author: $author\n";
print "Price: $price\n";
}
else {
print "Failed to get $url\n";
}
步骤如下:
1、导入所需的 Perl 模块:LWP::UserAgent、HTTP::Proxy 和 HTML::TreeBuilder。
2、创建一个 HTTP::Proxy 对象,指定爬虫ip服务器的主机名和端口号。
3、创建一个 LWP::UserAgent 对象,并指定爬虫ip服务器。
4、设置要爬取的网站的 URL。
5、使用用户爬虫ip访问网站。
6、检查请求是否成功。
7、如果请求成功,解析 HTML 页面。
8、找到需要的信息,并打印出来。
9、如果请求失败,打印错误信息。

![CNVD-2023-08743:宏景HCM SQL注入漏洞复现 [附POC]](https://img-blog.csdnimg.cn/8b95f8617da244c28eaf7e2dd8f92369.png)