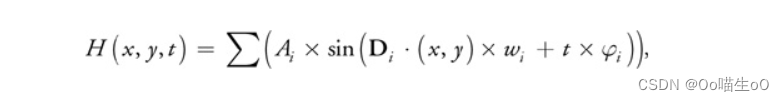目录
EfficientDet
0、摘要
1、整体架构
1.1 BackBone:EfficientNet-B0
1.2 Neck:BiFPN特征加强提取网络
1.3 Head检测头
1.4 compound scaling
2、anchors先验框
3、loss组成
4、论文理解
5、参考资料
EfficientDet
影响网络的性能(或者说规模)的三大因素:depth(layer的重复次数), width(特征图channels), resolution(特征图宽高)。
EfficientDet是以EfficientNet作为BackBone提取特征,以BiFPN作为加强特征提取网络。依据复杂度不同分为8个版本,其中网络EfficientNetB0-B6,BiFPN重复次数不同,共同组成成EfficientNetD0-D7。


下面结合原文,和一些博客资料,展开详细描述。
0、摘要
为了提高map值,以往的模型都在堆参数(eg:ResNXt),map是提上去了,但是计算量产目忍睹;针对这个问题,本文提出efficientdet,确保牛逼性能(coco 上最高55.1%)的同时,参数量低得一批(模型参数量缩小4-9倍,参数量缩小13-42倍,原因是:借鉴mobileNet,到处使用deep wise conv,BiFPN删除了冗余节点)。创新之处在于:
- 提出简洁、快速的多尺度特征融合Neck:BiFPN;
- 提出了一种模型缩放方案:即:通过适当地修改:BackBone中特征图分辨率、channels、深度,Neck:BiFPN重复次数,Head(框、类别预测层)中的特征图的channels等多个参数,达到模型最优。(以上参数不是瞎J8乱设置的,也不是和NAS搜索架构那样自动搜索的,而是本文创造的一个公式,参考:1.4 compound scaling
,有章可循!) (注:D0-D7不同版本对应不同的EfficientNetB0-B6,图像输入分辨率也不一样!)
1、整体架构

(注:上图中,变量后缀_U、_D分别表示上采样、下采样)
EfficientDet是以EfficientNet为backBone提取特征,依据网络复杂度不同都有8个版本,如上图,网络主要包含:
- BackBone(EfficientNet ):输出5个特征层到BiFPN
- Neck(BiFPN Layer加强特征提取):处理BackBone输出的5个特征图,之后再输出5个特征层给Head。
- Head(class&box prediction net):box预测 + class预测
1.1 BackBone:EfficientNet-B0
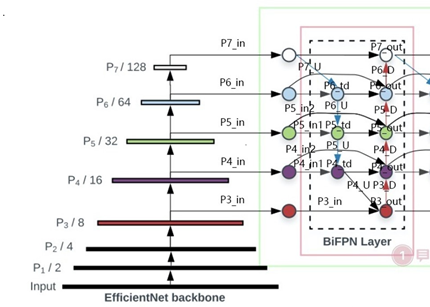
对于主干网络,主要依赖MBConvBlock重复提取、压缩特征,如下图,然后将中高低特征层(P3、4、5;P6和P7都是由P5下采样得到的)拿出来,输入到BiFPN层。
EfficientNet分为B0-B6等7个版本,每个本版中,特征图的分辨率、channels和卷积层的重复次数不同,具体EfficientDet如何使用的,待更新!
1.2 Neck:BiFPN特征加强提取网络
BiFPN(加权的双向特征金字塔网络,权重矩阵可理解为注意力机制),这里拿FPN、PANet、NAS-FPN作为对比,以下是四种多尺度特征融合结构图:
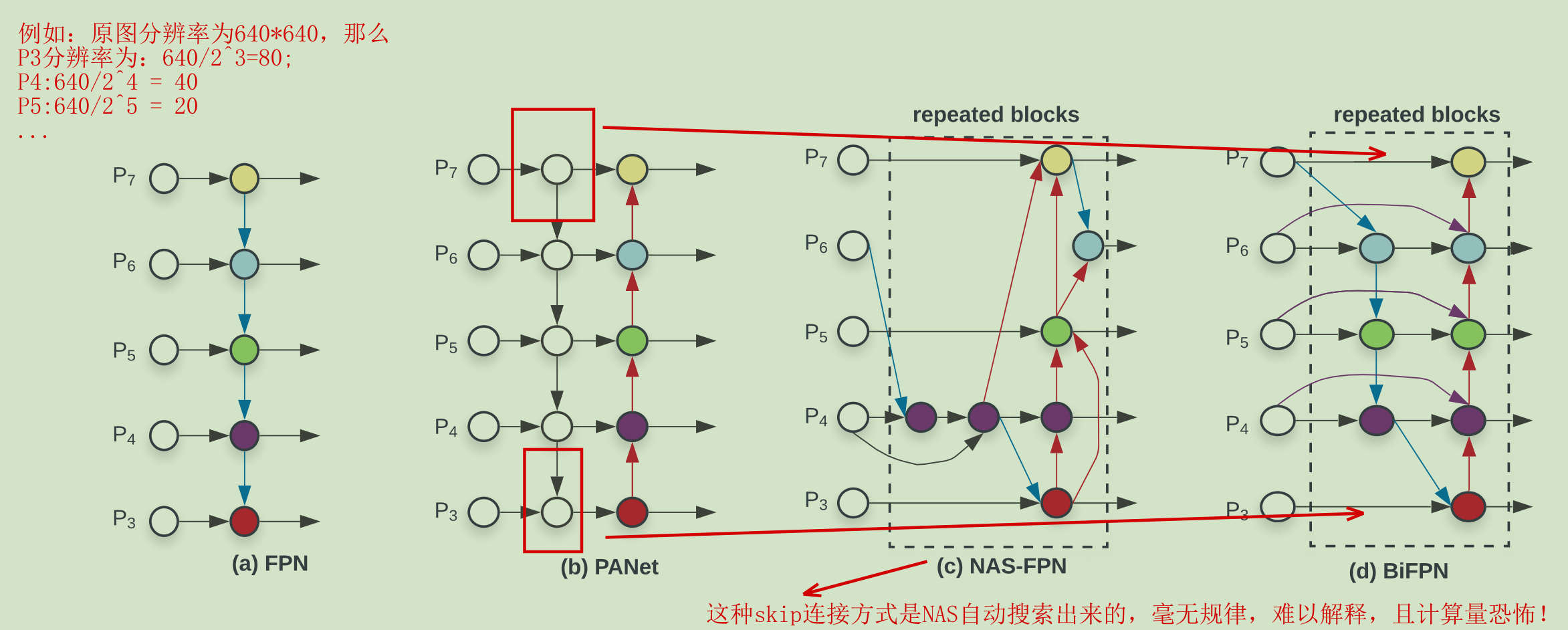
四种多尺度特征融合网络
如下图,PANet精度最好,但是计算量最多(时间开销是BiFPN的1.31倍),所以选择基于PANet改进,得到BiFPN(改进如上图?(d)BiFPN),修改内容如下:
- 删除只有一个输入的节点(因为删除的节点只有一个输入,删了之后几乎不改变性能,并且能够降低计算量),如图(b)PANet;
- 增加额外的skip连接,加强特征提取;
- 重复BiFPN加强特征提取
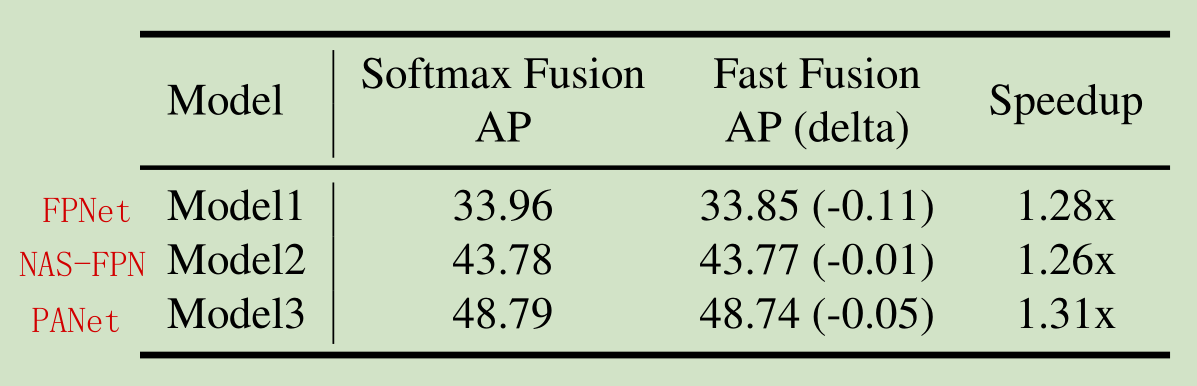
三种经典多尺度特征融合网络
另外,在多尺度特征图融合的时候,我们知道,特征图融合之前,由于分辨率不一样,传统步骤:先将所有两组待融合(下文成为A、B)的特征图进行resize到一样的尺寸,然后直接作加法。
但是,本文认为A、B的重要程度是一样的,所有给A、B都设定了权重tensor,加上权重后能提升效果。然而新的问题来了,直接加权重tensor可能导致特征值范围不受限制,进而导致训练不稳定,基于此,本文又利用softmax将权重tensor进行了归一化(使得所有权值取值为:[0, 1]),解决了训练不稳定问题。然而(尼玛的),实验表明,利用softmax归一化会导致网络慢得一批,于是,本文又提出了一种快速归一化方法,公式如下:
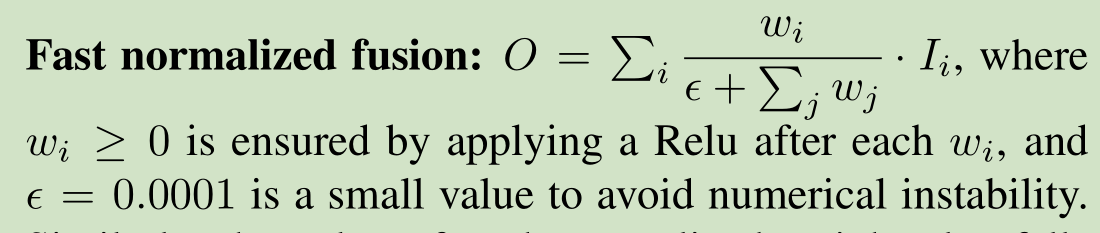
相对于softmax,能够提速30%,相当残忍。如下图,给出BiFPN中第六层的计算公式和示意图:

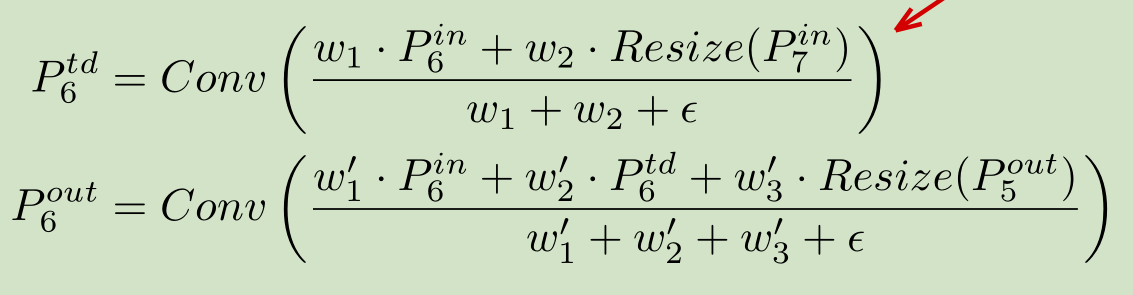
小结:BiFPN是基于PANet进行改进的,主要有以下几点:
- 删除只有一个输入的节点,提升速度;
- 引入权重tensor,提升精度
- 改进softmax提升速度
- 增加skip连接、重复BiFPN次数,进一步加强特征提取
下面补充下网络解读:
P6 P7是由P5下采样得到,在将特征输入到BiFPN之前,P3、P4、P5需要调整通道数一致。
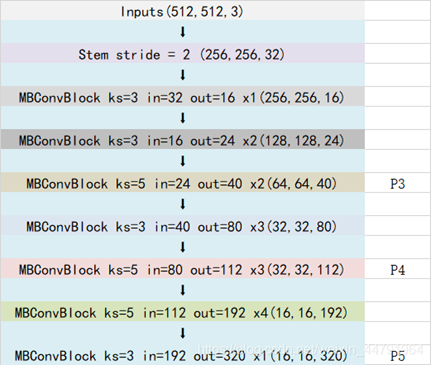
其中,每个MbconvBlock的结构如下图;Block的通用结构如下,其总体的设计思路是Inverted residuals结构和残差结构,在3x3或者5x5网络结构前利用1x1卷积升维,在3x3或者5x5网络结构后增加了一个关于通道的注意力机制,最后利用1x1卷积降维后增加一个大残差边(和MobileNetV2&3类似,都是google一家的东西)。

在获得P3_out、P4_td、P4_in_2、P5_td、P5_in_2、P6_in、P6_td、P7_in之后,之后需要对P3_out进行下采样,下采样后与P4_td、P4_in_2堆叠获得P4_out;之后对P4_out进行下采样,下采样后与P5_td、P5_in_2进行堆叠获得P5_out;之后对P5_out进行下采样,下采样后与P6_in、P6_td进行堆叠获得P6_out;之后对P6_out进行下采样,下采样后与P7_in进行堆叠获得P7_out。
将获得的P3_out、P4_out、P5_out、P6_out、P7_out作为P3_in、P4_in、P5_in、P6_in、P7_in,重复2、3步骤进行堆叠即可,对于Effiicientdet B0来讲,还需要重复2次,需要注意P4_in_1和P4_in_2此时不需要分开了,P5也是。

1.3 Head检测头
通过第二部的重复运算,我们获得了P3_out, P4_out, P5_out, P6_out, P7_out。为了和普通特征层区分,我们称之为有效特征层,将这五个有效的特征层传输过ClassNet+BoxNet就可以获得预测结果了。对于Efficientdet-B0来讲,如下图:
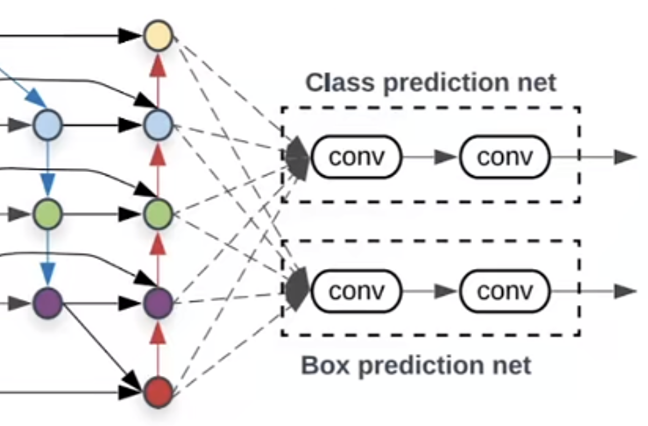
ClassNet采用:
① :3次64通道的卷积(深度可分离卷积,D0版本是3数)
② :1次num_anchors x num_classes的卷积(调整通道数,获得最终预测结果;注:num_anchors x num_classes表示channel维度,这里num_anchors一般取值为9)
注:num_anchors指的是该特征层所拥有的先验框数量,num_classes指的是网络一共对多少类的目标进行检测。
BoxNet采用:
① :3次64通道的卷积
② :和1次num_anchors x 4的卷积,num_anchors指的是该特征层所拥有的先验框数量,4指的是先验框的调整情况。需要注意的是,每个特征层所用的ClassNet是同一个ClassNet;每个特征层所用的BoxNet是同一个BoxNet。其中:num_anchors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
注:num_anchors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
1.4 compound scaling
由上文可知,依据不同的复杂度,网络可分为D0-D7等8个版本,这8个版本对应输入图像分辨率、BackBone、Neck、Head都不同,如下表,可以看到其对应搭配关系:
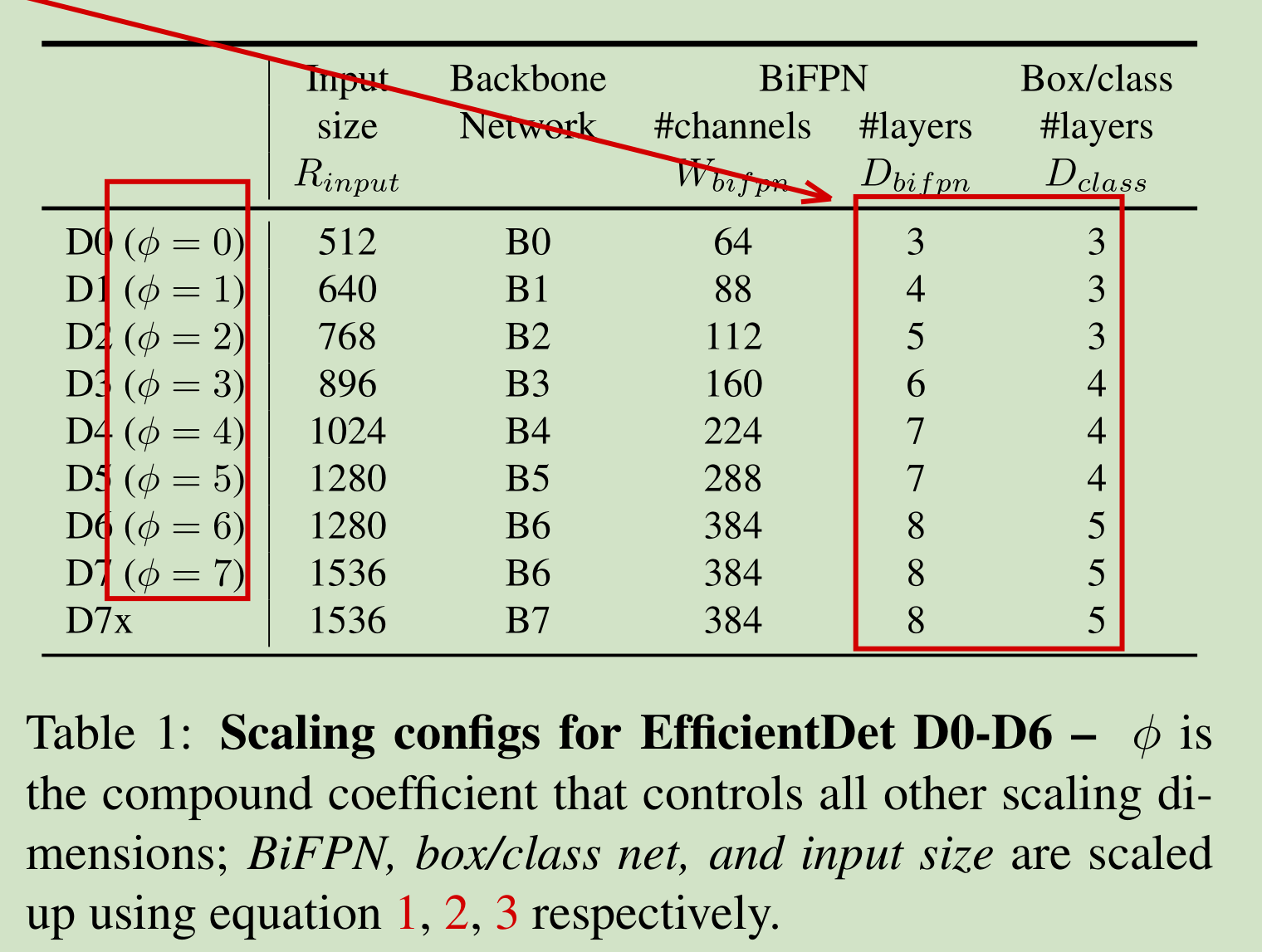
在上述表格第一列,有一个超参数φ,第二列的输入图像分辨率与其关系式为:
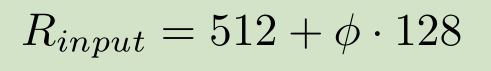
第三列为BackBone,这里不赘述。
第四列为Neck中BiFPN的对应卷积核的channels、和BiFPN的重复次数:

第五列为Head层重复次数,和φ关系为:
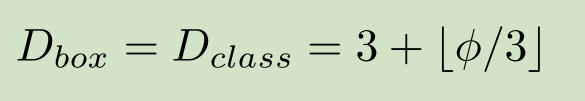
2、anchors先验框
每个点9个先验框,三个近似正方形,三个近似横着的矩形,三个近似竖着的矩形。其余的先验框的计算和YOLOV5没啥区别,唯一不同:这里用左上角、右下角两个点表示框的位置。
3、loss组成
loss的计算分为两个部分:
1、Smooth Loss:获取所有正标签的框的预测结果的回归loss。
2、Focal Loss:获取所有未被忽略的种类的预测结果的交叉熵loss。
4、论文理解
EfficientDet-D7,在coco上map达到55.1%,77M参数量,410BFloPs计算量。
5、参考资料
原论文:
链接:https://pan.baidu.com/s/1bm772PGnnRQhFKY7LV6rJQ
提取码:6nl4