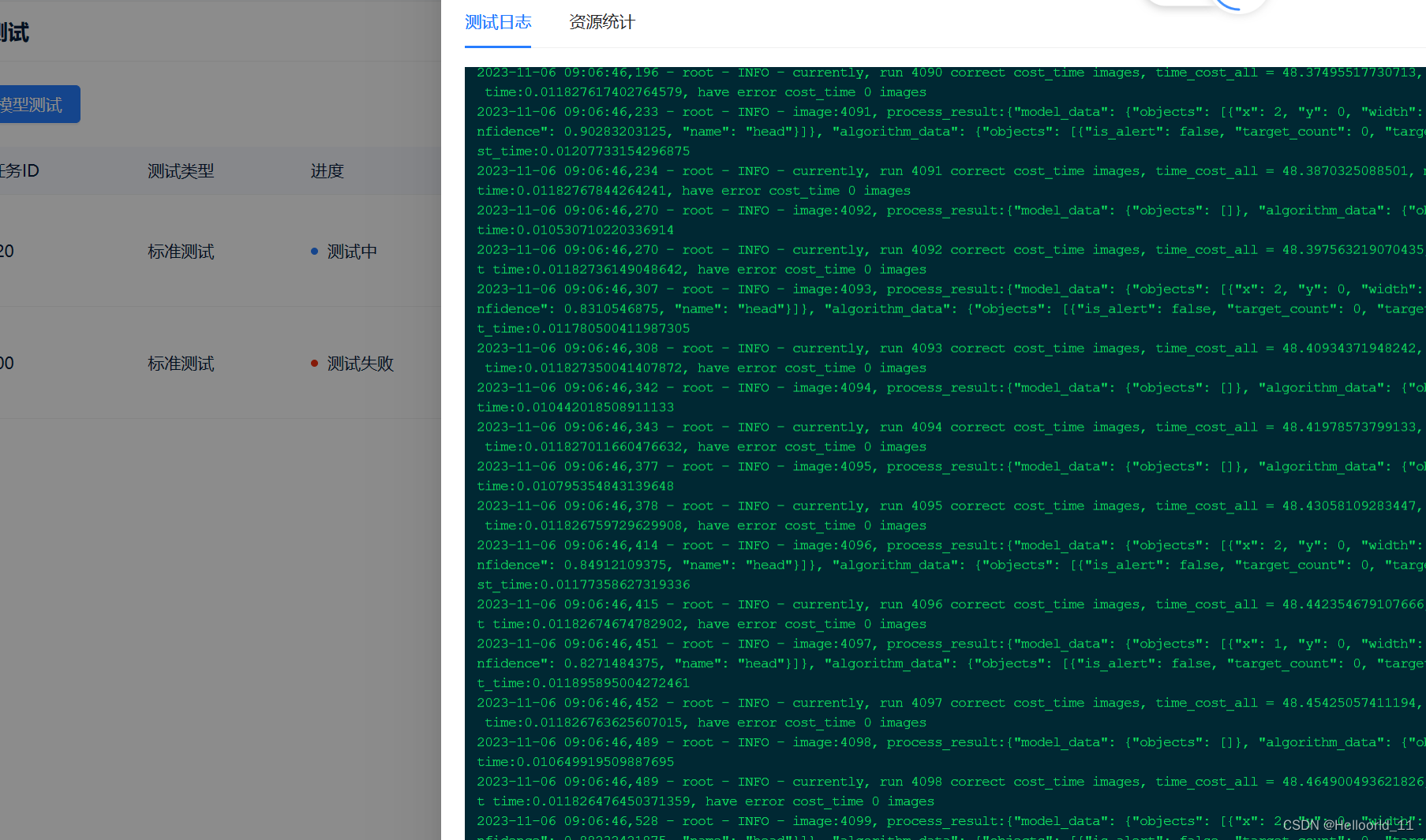
1、切换当前文件目录位置:
%cd /project/train/2、删除目标文件夹和文件夹下面的内容,注意这个r是不能少的:
!rm -r /project/train/src_repo/dataset3、创建数据集相关文件夹
!mkdir /project/train/src_repo/dataset4、复制指定后缀名的文件到,指定的文件夹下面
!cp /home/data/2711/*.xml /project/train/src_repo/dataset/Annotations5、执行.py文件,前面加上!python即可
!python /project/train/src_repo/dataset/voc_label.py6、使用bash命令执行指定的.sh文件
!bash /project/train/src_repo/run.sh7、对xml文件进行标签处理转变为coco数据标签格式常用的python代码如下:
先对数据集进行分类(训练集,测试集,验证集)
import os
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', type=str, help='input xml label path')
parser.add_argument('--txt_path', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num=len(total_xml)
list=range(num)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
ftrainval.write(name)
if i%7 == 0:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
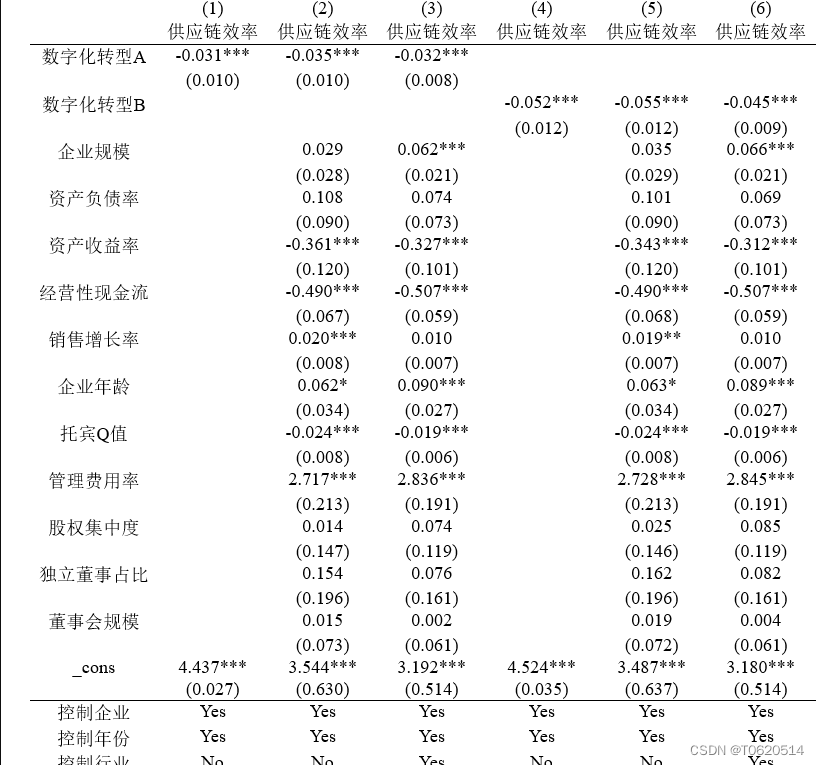
ftest.close() 这段代码主要做的是将一些XML标签文件进行划分,分成训练集、验证集、测试集三部分。
首先,代码导入了三个模块:os、random、argparse。
然后,使用argparse模块创建了一个命令行参数解析器,并添加了两个命令行参数:--xml_path 和 --txt_path。这两个参数分别用于指定输入的XML标签路径和输出的TXT标签路径。
之后,代码定义了两个变量:trainval_percent 和 train_percent,分别设置为1.0和0.9。这两个变量可能是用于设置训练集和总数据集的比例,但在这个代码段中并未使用。
然后,代码获取了用户通过命令行参数指定的XML文件路径和TXT文件保存路径,并列出了指定路径下的所有XML文件。
如果指定的TXT文件保存路径不存在,代码会创建这个路径。
接着,代码定义了四个文件对象:ftrainval、ftest、ftrain、fval,用于写入四个不同的TXT文件。
最后,代码遍历了所有的XML文件,将每个文件的名称(去掉后缀)写入到ftrainval文件中。每写入7个文件名,就将下一个文件名写入到fval文件中,其他的都写入到ftrain文件中。
在完成所有写入操作后,代码关闭了所有文件对象。
这样,就完成了将XML标签文件划分成训练集、验证集和测试集的操作。需要注意的是,这个代码段并没有使用随机打乱数据,也没有按照实际的比例划分数据集,可能还需要进一步的处理才能满足实际需求。
下面这个是读取xml文件的内容,并且写入到指定的txt文件下面
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=['train', 'val', 'test']
classes = ['head']
abs_path = os.getcwd()
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('/home/data/2718/%s.xml'%( image_id))
out_file = open('/project/train/src_repo/dataset/labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
#difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes :
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists('/project/train/src_repo/dataset/labels/'):
os.makedirs('/project/train/src_repo/dataset/labels/')
image_ids = open('/project/train/src_repo/dataset/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('/project/train/src_repo/dataset/%s.txt'%(image_set), 'w')
for image_id in image_ids:
list_file.write('/project/train/src_repo/dataset/images/%s.jpg\n'%(image_id))
convert_annotation(image_id)
list_file.close() 首先,导入了一些需要的模块,包括xml.etree.ElementTree用于解析XML文件,pickle用于序列化和反序列化Python对象,os用于操作系统相关的操作,getcwd获取当前工作目录,listdir列出一个目录中的文件名,join连接路径的元素。
然后,定义了一些变量,包括三个数据集名称sets和一个类别名称classes。
接下来,定义了一个函数convert,它接收两个参数:size和box。这个函数将一个矩形框(box)转换为标准化的形式。标准化的过程是将矩形框的左上角坐标(x,y)和宽度高度(w,h)进行变换,变换的公式是:x = (box[0] + box[1])/2.0 - 1 和 y = (box[2] + box[3])/2.0 - 1,并且 w = box[1] - box[0] 和 h = box[3] - box[2]。然后这个函数返回转换后的坐标和尺寸。
再下面,定义了一个函数convert_annotation,这个函数用于处理单个图片的XML标注文件。它首先打开图片的XML文件,解析XML树,获取到图片的大小以及所有的对象(在这里是目标)。然后对于每一个目标,如果它在类别列表中,就获取其边界框并使用上述的转换函数进行转换,然后将类别ID和转换后的边界框写入到一个新的文本文件中。
最后,对于每个数据集,首先检查输出文件夹是否存在,如果不存在就创建。然后读取该数据集的所有图片ID,对于每个图片ID,调用上述函数处理其对应的XML文件,然后将图片的路径写入到一个新的文本文件中。
需要注意的是,这段代码假设所有的图片和标注文件都在指定的路径下,如果不在这个路径下需要进行相应的修改。另外,这段代码处理的是VOC格式的XML标注文件,如果你使用的是其他格式的标注文件可能需要进行一些修改。
最后注意 CoCo数据集的格式是每一行作为一个label(包含分类序号,中心点的坐标,宽度,高度,都需要进行归一化)