RAG是一个考验技术的工作
基于大模型的企业应用中很大一部分需求就是RAG——检索增强生成。
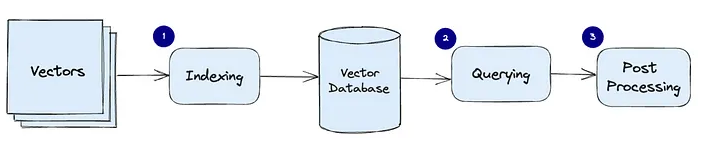
这个流程依然无法描述RAG的复杂性
RAG涉及的内容其实广泛,包括Embedding、分词分块、检索召回(相似度匹配)、chat系统、ReAct和Prompt优化等,最后还有与LLM的交互,整个过程技术复杂度很高。如果你用的LLM非常好,反而大模型这一块是你最不需要关心的。而这些环节里面我们每个都没达到1(比如0.9、0.7…),那么最终的结果可能是这些小数点的乘积。如果我们每个环节都可以做到>1.0,那么最终的结果会比上一个结果高出很多。
今天我们来聊聊分块,很重要的一个环节(没有哪个环节不重要),但它也许是我们容易做到高质量的一个环节。
什么是分块?
在构建RAG这类基于LLM的应用程序中,分块(chunking)是将大块文本分解成小段的过程。当我们使用LLM embedding内容时,这是一项必要的技术,可以帮助我们优化从向量数据库被召回的内容的准确性。在本文中,我们将探讨它是否以及如何帮助提高RAG应用程序的效率和准确性。
Pinecone是领先的向量数据库供应商
在向量数据库(如:Pinecone)中索引的任何内容都需要首先Embedding。分块的主要原因是尽量减少我们Embedding内容的噪音。
例如,在语义搜索中,我们索引一个文档语料库,每个文档包含一个特定主题的有价值的信息。通过使用有效的分块策略,我们可以确保搜索结果准确地捕获用户查询的需求本质。如果我们的块太小或太大,可能会导致不精确的搜索结果或错过展示相关内容的机会。根据经验,如果文本块尽量是语义独立的,也就是没有对上下文很强的依赖,这样子对语言模型来说是最易于理解的。因此,为语料库中的文档找到最佳块大小对于确保搜索结果的准确性和相关性至关重要。
另一个例子是会话Agent。我们使用embedding的块为基于知识库的会话agent构建上下文,该知识库将代理置于可信信息中。在这种情况下,对分块策略做出正确的选择很重要,原因有两个:
- 首先,它将决定上下文是否与我们的prompt相关。
- 其次,考虑到我们可以为每个请求发送的tokens数量的限制,它将决定我们是否能够在将检索到的文本合并到prompt中发送到大模型(如OpenAI)。
在某些情况下,比如使用具有32k上下文窗口的GPT-4时,拟合块可能不是问题。尽管如此,当我们使用非常大的块时,我们需要注意,因为这可能会对我们从向量数据库获得的结果的相关性产生不利影响。
在这篇文章中,我们将探讨几种分块方法,并讨论在选择分块大小和方法时应该考虑的权衡。最后,我们将给出一些建议,以确定适合您的应用程序的最佳块大小和方法。
Embedding长短内容
当我们在嵌入内容(也就是embedding)时,我们可以根据内容是短(如句子)还是长(如段落或整个文档)来预测不同的行为。
当嵌入一个句子时,生成的向量集中在句子的特定含义上。当与其他句子Embedding进行比较时,自然会在这个层次上进行比较。这也意味着Embedding可能会错过在段落或文档中找到的更广泛的上下文信息。
当嵌入一个完整的段落或文档时,Embedding过程既要考虑整个上下文,也要考虑文本中句子和短语之间的关系。这可以产生更全面的向量表示,从而捕获文本的更广泛的含义和主题。另一方面,较大的输入文本大小可能会引入噪声或淡化单个句子或短语的重要性,从而在查询索引时更难以找到精确的匹配。
查询的长度也会影响Embeddings之间的关系。较短的查询,如单个句子或短语,将专注于细节,可能更适合与句子级Embedding进行匹配。跨越多个句子或段落的较长的查询可能更适合段落或文档级别的Embedding,因为它可能会寻找更广泛的上下文或主题。
索引也可能是非同质的,并且包含“不同”大小的块的Embedding。这可能会在查询结果相关性方面带来挑战,但也可能产生一些积极的后果。一方面,由于长内容和短内容的语义表示不一致,查询结果的相关性可能会波动。另一方面,非同构索引可能捕获更大范围的上下文和信息,因为不同的块大小表示文本中的不同粒度级别。这可以更灵活地容纳不同类型的查询。
分块需要考虑的因素
在确定最佳分块策略时,有几个因素会对我们的选择起到至关重要的影响。以下是一些事实我们需要首先记在心里:
-
被索引内容的性质是什么? 这可能差别会很大,是处理较长的文档(如文章或书籍),还是处理较短的内容(如微博或即时消息)?答案将决定哪种模型更适合您的目标,从而决定应用哪种分块策略。
-
您使用的是哪种Embedding模型,它在多大的块大小上表现最佳?例如,sentence-transformer[1]模型在单个句子上工作得很好,但像text- embedt-ada -002[2]这样的模型在包含256或512个tokens的块上表现得更好。
-
你对用户查询的长度和复杂性有什么期望?用户输入的问题文本是简短而具体的还是冗长而复杂的?这也直接影响到我们选择分组内容的方式,以便在嵌入查询和嵌入文本块之间有更紧密的相关性。
-
如何在您的特定应用程序中使用检索结果? 例如,它们是否用于语义搜索、问答、摘要或其他目的?例如,和你底层连接的LLM是有直接关系的,LLM的tokens限制会让你不得不考虑分块的大小。
没有最好的分块策略,只有适合的分块策略,为了确保查询结果更加准确,有时候我们甚至需要选择性的使用几种不同的策略。
分块的方法
分块有不同的方法,每种方法都可能适用于不同的情况。通过检查每种方法的优点和缺点,我们的目标是确定应用它们的正确场景。
固定大小分块
这是最常见、最直接的分块方法:
我们只需决定块中的tokens的数量,以及它们之间是否应该有任何重叠。一般来说,我们会在块之间保持一些重叠,以确保语义上下文不会在块之间丢失。在大多数情况下,固定大小的分块将是最佳方式。与其他形式的分块相比,固定大小的分块在计算上更加经济且易于使用,因为它在分块过程中不需要使用任何NLP库。
下面是一个使用LangChain执行固定大小块处理的示例:
1 2 3 4 5 6 7 8 | text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
|
Content-Aware:基于内容意图分块
这是一系列方法的组合,利用我们正在分块的内容的性质,并对其应用更复杂的分块。下面是一些例子:
句分割——Sentence splitting
正如我们之前提到的,许多模型都针对Embedding句子级内容进行了优化。当然,我们会使用句子分块,有几种方法和工具可以做到这一点,包括:
- Naive splitting: 最幼稚的方法是用句号(。)和“换行”来分割句子。虽然这可能是快速和简单的,但这种方法不会考虑到所有可能的边缘情况。这里有一个非常简单的例子:
1 2 | text = "..." # 你的文本
docs = text.split(".")
|
- NLTK[3]: 自然语言工具包(NLTK)是一个流行的Python库,用于处理自然语言数据。它提供了一个句子标记器,可以将文本分成句子,帮助创建更有意义的分块。例如,要将NLTK与LangChain一起使用,您可以这样做:
1 2 3 4 | text = "..." # 你的文本 from langchain.text_splitter import NLTKTextSplitter text_splitter = NLTKTextSplitter() docs = text_splitter.split_text(text) |
- spaCy[4]: spaCy是另一个用于NLP任务的强大Python库。它提供了一个复杂的句子分割功能,可以有效地将文本分成单独的句子,从而在生成的块中更好地保存上下文。例如,要将space与LangChain一起使用,您可以这样做:
1 2 3 4 | text = "..." # 你的文本 from langchain.text_splitter import SpacyTextSplitter text_splitter = SpaCyTextSplitter() docs = text_splitter.split_text(text) |

spacy-llm package
递归分割
递归分块使用一组分隔符以分层和迭代的方式将输入文本分成更小的块。如果分割文本开始的时候没有产生所需大小或结构的块,那么这个方法会使用不同的分隔符或标准对生成的块递归调用,直到获得所需的块大小或结构。这意味着虽然这些块的大小并不完全相同,但它们仍然会逼近差不多的大小。
这里有一个例子,如何配合LangChain使用递归分块:
1 2 3 4 5 6 7 8 9 | text = "..." # 你的文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# 设置一个非常小的块大小。
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
|
专门的分块
Markdown和LaTeX是您可能遇到的结构化和格式化内容的两个例子。在这些情况下,可以使用专门的分块方法在分块过程中保留内容的原始结构。

本文就是用markdown写作的
- Markdown: Markdown是一种轻量级的标记语言,通常用于格式化文本。通过识别Markdown语法(例如,标题、列表和代码块),您可以根据其结构和层次结构智能地划分内容,从而生成语义更连贯的块。例如:
1 2 3 4 5 | from langchain.text_splitter import MarkdownTextSplitter markdown_text = "..." markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0) docs = markdown_splitter.create_documents([markdown_text]) |
- LaTex: LaTeX是一种文档准备系统和标记语言,通常用于学术论文和技术文档。通过解析LaTeX命令和环境,您可以创建尊重内容逻辑组织的块(例如,节、子节和方程),从而产生更准确和上下文相关的结果。例如:
1 2 3 4 | from langchain.text_splitter import LatexTextSplitter latex_text = "..." latex_splitter = LatexTextSplitter(chunk_size=100, chunk_overlap=0) docs = latex_splitter.create_documents([latex_text]) |
确定应用程序的最佳块大小
如果常见的分块方法(如固定分块)不容易适用于您的用例,这里有一些指针可以帮助您找到最佳的块大小。
- 清洗数据 :在确定应用程序的最佳块大小之前,您需要首先预处理清洗数据以确保质量。例如,如果您的数据是从web爬取的,您可能需要删除HTML标记或特定的元素,保证文本的“纯洁”,减少文本的噪音。
- 选择一个范围的块大小 :一旦你的数据被预处理,下一步是选择一个范围的潜在块大小进行测试。如前所述,选择时应考虑内容的性质(例如短文本还是长文档)、将要使用的Embedding模型及其功能(如token限制)。目标是在保留上下文和保持准确性之间找到平衡。从探索各种块大小开始,包括较小的块(例如,128或256个tokens)用于捕获更细粒度的语义信息,较大的块(例如,512或1024个tokens)用于保留更多上下文。
- 评估每个块大小的性能 :很傻,但是很稳重的一种方式。为了测试不同大小的块,您可以把不同大小的块进行标记。使用可以覆盖你的业务场景效果的数据集,为要测试的各个大小的块创建Embedding,并将它们保存下来。然后,你可以运行一系列查询来评估质量,并比较不同块大小的性能。这是一个反复测试的过程,在这个过程中,针对不同的查询测试不同的块大小,直到找到最佳的块大小。
结论
好了,说了这么多,最后我要说的结论你可能会失望,那就是我们自己也还没有找到最佳的分块方式,哈哈。但是对于不同的业务场景,我们现在比刚开始做RAG应用的时候会有经验很多了。
引用:
1.sentence-transformer:https://huggingface.co/sentence-transformers
2.text- embedt-ada -002:New and improved embedding model
3.NLTK:NLTK :: Natural Language Toolkit
4.spaCy:spaCy · Industrial-strength Natural Language Processing in Python
5.Chunking Strategies for LLM Applications:Chunking Strategies for LLM Applications | Pinecone





![贰[2],QT异常处理](https://img-blog.csdnimg.cn/10e421e3221945c59388cb76515cfc17.png)