原文地址
为了保证概念的严谨性,翻译时保留了英文原文。
This post explains how to implement heap allocators from scratch. It presents and discusses different allocator designs, including bump allocation, linked list allocation, and fixed-size block allocation. For each of the three designs, we will create a basic implementation that can be used for our kernel.
这篇文章解释了如何从头开始实现堆内存分配器。它介绍并讨论了不同的分配器设计,包括 bump分配、链表分配和固定大小块分配。对于这三种设计中的每一种,我们都将创建一个可用于我们的内核的基本实现。
This blog is openly developed on GitHub. If you have any problems or questions, please open an issue there. You can also leave comments at the bottom. The complete source code for this post can be found in the post-11 branch.
该博客是在 GitHub 上公开开发的。如果您有任何问题或疑问,请在那里提出问题。也可以在底部留言评论。这篇文章的完整源代码可以在 post-11 分支中找到。
1. Introduction 介绍
In the previous post, we added basic support for heap allocations to our kernel. For that, we created a new memory region in the page tables and used the linked_list_allocator crate to manage that memory. While we have a working heap now, we left most of the work to the allocator crate without trying to understand how it works.
在上一篇文章中,我们向内核添加了对堆内存分配的基本支持。为此,我们在页表中创建了一个新的内存区域,并使用 linked_list_allocator crate 来管理该内存。虽然现在有了一个可以工作的堆,但我们将大部分工作留给了外部分配器 crate,而没有尝试了解它是如何工作的。
In this post, we will show how to create our own heap allocator from scratch instead of relying on an existing allocator crate. We will discuss different allocator designs, including a simplistic bump allocator and a basic fixed-size block allocator, and use this knowledge to implement an allocator with improved performance (compared to the linked_list_allocator crate).
在这篇文章中,我们将展示如何从头开始创建我们自己的堆分配器,而不是依赖于外部的 分配器crate。我们将讨论不同的分配器设计,包括简单的 bump 分配器和基本的固定大小块分配器,并使用这些知识来实现性能改进的分配器(与 linked_list_allocator crate 相比)。
1.1 Design Goals 设计目标
The responsibility of an allocator is to manage the available heap memory. It needs to return unused memory on alloc calls and keep track of memory freed by dealloc so that it can be reused again. Most importantly, it must never hand out memory that is already in use somewhere else because this would cause undefined behavior.
分配器的职责是管理可用的堆内存。它需要在 alloc 调用上返回未使用的内存,并跟踪 dealloc 释放的内存,以便可以再次重用。最重要的是,它绝不能重复分配已经在其他地方使用的内存,因为这会导致未定义的行为。
Apart from correctness, there are many secondary design goals. For example, the allocator should effectively utilize the available memory and keep fragmentation low. Furthermore, it should work well for concurrent applications and scale to any number of processors. For maximal performance, it could even optimize the memory layout with respect to the CPU caches to improve cache locality and avoid false sharing.
除了正确性之外,还有许多次要的设计目标。例如,分配器应该有效地利用可用内存并保持低碎片。此外,它应该适用于并发应用程序,并可扩展到任意数量的处理器。为了获得最佳性能,它甚至可以优化 CPU 缓存的内存布局,以提高缓存局部性并避免错误共享。
These requirements can make good allocators very complex. For example, jemalloc has over 30.000 lines of code. This complexity is often undesired in kernel code, where a single bug can lead to severe security vulnerabilities. Fortunately, the allocation patterns of kernel code are often much simpler compared to userspace code, so that relatively simple allocator designs often suffice.
这些要求会使好的分配器变得非常复杂。例如,jemalloc 有超过 30,000 行代码。这种复杂性在内核代码中通常是不受欢迎的,因为单个错误可能会导致严重的安全漏洞。幸运的是,与用户空间代码相比,内核代码的分配模式通常要简单得多,因此相对简单的分配器设计通常就足够了。
In the following, we present three possible kernel allocator designs and explain their advantages and drawbacks.
下面,我们提出三种可能的内核分配器设计并解释它们的优点和缺点。
2. Bump Allocator 线性分配器
The most simple allocator design is a bump allocator (also known as stack allocator). It allocates memory linearly and only keeps track of the number of allocated bytes and the number of allocations. It is only useful in very specific use cases because it has a severe limitation: it can only free all memory at once.
最简单的分配器设计是 bump分配器(也称为栈分配器,线性分配器)。它线性分配内存,并且只跟踪已分配的字节数和分配的数量。它仅在非常特定的用例中有用,因为它有一个严重的限制:它只能一次释放所有内存。
2.1 Idea 思想
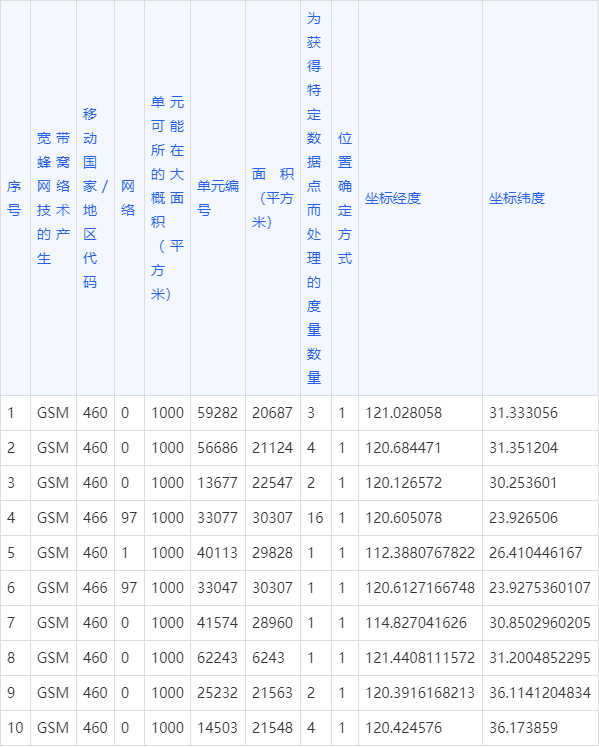
The idea behind a bump allocator is to linearly allocate memory by increasing (“bumping”) a next variable, which points to the start of the unused memory. At the beginning, next is equal to the start address of the heap. On each allocation, next is increased by the allocation size so that it always points to the boundary between used and unused memory:
bump 分配器背后的想法是通过增加(“ bumping”)一个 next 变量来线性分配内存,该变量指向未使用内存的开头。一开始, next 等于堆的起始地址。每次分配时, next 都会增加分配大小,以便它始终指向已用内存和未用内存之间的边界:
The next pointer only moves in a single direction and thus never hands out the same memory region twice. When it reaches the end of the heap, no more memory can be allocated, resulting in an out-of-memory error on the next allocation.
next 指针仅在一个方向上移动,因此永远不会两次分配相同的内存区域。当它到达堆末尾时,无法再分配更多内存,从而导致下次分配时出现内存不足错误。
A bump allocator is often implemented with an allocation counter, which is increased by 1 on each alloc call and decreased by 1 on each dealloc call. When the allocation counter reaches zero, it means that all allocations on the heap have been deallocated. In this case, the next pointer can be reset to the start address of the heap, so that the complete heap memory is available for allocations again.
bump 分配器通常使用分配计数器来实现,每次 alloc 调用时分配计数器加 1,每次 dealloc 调用时减 1。当分配计数器达到零时,意味着堆上的所有分配都已被释放。在这种情况下,可以将 next 指针重置为堆的起始地址,以便完整的堆内存再次可供分配。
2.2 Implementation 实现
We start our implementation by declaring a new allocator::bump submodule:
我们通过声明一个新的 allocator::bump 子模块来开始我们的实现:
// in src/allocator.rs
pub mod bump;
The content of the submodule lives in a new src/allocator/bump.rs file, which we create with the following content:
子模块的内容位于一个新的 src/allocator/bump.rs 文件中,我们使用以下内容创建该文件:
// in src/allocator/bump.rs
pub struct BumpAllocator {
heap_start: usize,
heap_end: usize,
next: usize,
allocations: usize,
}
impl BumpAllocator {
/// Creates a new empty bump allocator.
pub const fn new() -> Self {
BumpAllocator {
heap_start: 0,
heap_end: 0,
next: 0,
allocations: 0,
}
}
/// Initializes the bump allocator with the given heap bounds.
///
/// This method is unsafe because the caller must ensure that the given
/// memory range is unused. Also, this method must be called only once.
pub unsafe fn init(&mut self, heap_start: usize, heap_size: usize) {
self.heap_start = heap_start;
self.heap_end = heap_start + heap_size;
self.next = heap_start;
}
}
The heap_start and heap_end fields keep track of the lower and upper bounds of the heap memory region. The caller needs to ensure that these addresses are valid, otherwise the allocator would return invalid memory. For this reason, the init function needs to be unsafe to call.
heap_start 和 heap_end 字段跟踪堆内存区域的下限和上限。调用者需要确保这些地址有效,否则分配器将返回无效内存。因此, init 函数需要通过 unsafe 来调用。
The purpose of the next field is to always point to the first unused byte of the heap, i.e., the start address of the next allocation. It is set to heap_start in the init function because at the beginning, the entire heap is unused. On each allocation, this field will be increased by the allocation size (“bumped”) to ensure that we don’t return the same memory region twice.
next 字段的目的是始终指向堆的第一个未使用的字节,即下一次分配的起始地址。在 init 函数中将其设置为 heap_start ,因为一开始,整个堆都未使用。每次分配时,该字段都会增加分配大小(“增加”),以确保我们不会两次返回相同的内存区域。
The allocations field is a simple counter for the active allocations with the goal of resetting the allocator after the last allocation has been freed. It is initialized with 0.
allocations 字段是活动分配的简单计数器,目的是在释放最后一个分配后重置分配器。它被初始化为0。
We chose to create a separate init function instead of performing the initialization directly in new in order to keep the interface identical to the allocator provided by the linked_list_allocator crate. This way, the allocators can be switched without additional code changes.
我们选择创建一个单独的 init 函数,而不是直接在 new 中执行初始化,以便保持接口与 linked_list_allocator crate提供的分配器相同。这样,无需更改额外的代码即可切换分配器。
2.3 Implementing GlobalAlloc 实现 GlobalAlloc
As explained in the previous post, all heap allocators need to implement the GlobalAlloc trait, which is defined like this:
正如上一篇文章中所解释的,所有堆分配器都需要实现 GlobalAlloc 特征,其定义如下:
pub unsafe trait GlobalAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8;
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
unsafe fn alloc_zeroed(&self, layout: Layout) -> *mut u8 { ... }
unsafe fn realloc(
&self,
ptr: *mut u8,
layout: Layout,
new_size: usize
) -> *mut u8 { ... }
}
Only the alloc and dealloc methods are required; the other two methods have default implementations and can be omitted.
仅需要 alloc 和 dealloc 方法;另外两个方法有默认实现,可以省略。
2.3.1 First Implementation Attempt
第一次实现尝试
Let’s try to implement the alloc method for our BumpAllocator:
让我们尝试为 BumpAllocator 实现 alloc 方法:
// in src/allocator/bump.rs
use alloc::alloc::{GlobalAlloc, Layout};
unsafe impl GlobalAlloc for BumpAllocator {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
// TODO alignment and bounds check
let alloc_start = self.next;
self.next = alloc_start + layout.size();
self.allocations += 1;
alloc_start as *mut u8
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
todo!();
}
}
First, we use the next field as the start address for our allocation. Then we update the next field to point to the end address of the allocation, which is the next unused address on the heap. Before returning the start address of the allocation as a *mut u8 pointer, we increase the allocations counter by 1.
首先,我们使用 next 字段作为分配的起始地址。然后我们更新 next 字段以指向分配的结束地址,这是堆上 下一个未使用的地址。在将分配的起始地址作为 *mut u8 指针返回之前,我们将 allocations 计数器加 1。
Note that we don’t perform any bounds checks or alignment adjustments, so this implementation is not safe yet. This does not matter much because it fails to compile anyway with the following error:
请注意,我们不执行任何边界检查或对齐调整,因此此实现尚不安全。这并不重要,因为无论如何它都无法编译并出现以下错误:
error[E0594]: cannot assign to `self.next` which is behind a `&` reference
--> src/allocator/bump.rs:29:9
|
29 | self.next = alloc_start + layout.size();
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be written
(The same error also occurs for the self.allocations += 1 line. We omitted it here for brevity.)
( self.allocations += 1 行也会出现同样的错误。为了简洁起见,我们在此处省略了它。)
The error occurs because the alloc and dealloc methods of the GlobalAlloc trait only operate on an immutable &self reference, so updating the next and allocations fields is not possible. This is problematic because updating next on every allocation is the essential principle of a bump allocator.
发生错误的原因是 GlobalAlloc 特征的 alloc 和 dealloc 方法仅对不可变的 &self 引用进行操作,因此更新 next 和 allocations 字段是不可能的。这是有问题的,因为每次分配时更新 next 是 bump 分配器的基本原则。
2.3.2 GlobalAlloc and Mutability GlobalAlloc 和可变性
Before we look at a possible solution to this mutability problem, let’s try to understand why the GlobalAlloc trait methods are defined with &self arguments: As we saw in the previous post, the global heap allocator is defined by adding the #[global_allocator] attribute to a static that implements the GlobalAlloc trait. Static variables are immutable in Rust, so there is no way to call a method that takes &mut self on the static allocator. For this reason, all the methods of GlobalAlloc only take an immutable &self reference.
在我们研究这个可变性问题的可能解决方案之前,让我们尝试理解为什么 GlobalAlloc 特征方法是用 &self 参数定义的:正如我们在上一篇文章中看到的,全局堆分配器是通过将 #[global_allocator] 属性添加到实现 GlobalAlloc 特征的 static 来定义的。静态变量在 Rust 中是不可变的,因此无法调用静态分配器上采用 &mut self 的方法。因此, GlobalAlloc 的所有方法仅采用不可变的 &self 引用。
Fortunately, there is a way to get a &mut self reference from a &self reference: We can use synchronized interior mutability by wrapping the allocator in a spin::Mutex spinlock. This type provides a lock method that performs mutual exclusion and thus safely turns a &self reference to a &mut self reference. We’ve already used the wrapper type multiple times in our kernel, for example for the VGA text buffer.
幸运的是,有一种方法可以从 &self 引用获取 &mut self 引用:我们可以通过将分配器包装在 spin::Mutex 自旋锁中来使用同步内部可变性。此类型提供了执行互斥的 lock 方法,从而安全地将 &self 引用转换为 &mut self 引用。我们已经在内核中多次使用了包装类型,例如 VGA 文本缓冲区。
2.3.3 A Locked Wrapper Type Locked 包装类型
With the help of the spin::Mutex wrapper type, we can implement the GlobalAlloc trait for our bump allocator. The trick is to implement the trait not for the BumpAllocator directly, but for the wrapped spin::Mutex<BumpAllocator> type:
在 spin::Mutex 包装类型的帮助下,我们可以为 bump分配器实现 GlobalAlloc 特征。诀窍是不直接为 BumpAllocator 实现特征,而是为包装的 spin::Mutex<BumpAllocator> 类型实现特征:
unsafe impl GlobalAlloc for spin::Mutex<BumpAllocator> {…}
Unfortunately, this still doesn’t work because the Rust compiler does not permit trait implementations for types defined in other crates:
不幸的是,这仍然不起作用,因为 Rust 编译器不允许对其他包中定义的类型进行特征实现:
error[E0117]: only traits defined in the current crate can be implemented for arbitrary types
--> src/allocator/bump.rs:28:1
|
28 | unsafe impl GlobalAlloc for spin::Mutex<BumpAllocator> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^--------------------------
| | |
| | `spin::mutex::Mutex` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
To fix this, we need to create our own wrapper type around spin::Mutex:
为了解决这个问题,我们需要围绕 spin::Mutex 创建我们自己的包装类型:
// in src/allocator.rs
/// A wrapper around spin::Mutex to permit trait implementations.
pub struct Locked<A> {
inner: spin::Mutex<A>,
}
impl<A> Locked<A> {
pub const fn new(inner: A) -> Self {
Locked {
inner: spin::Mutex::new(inner),
}
}
pub fn lock(&self) -> spin::MutexGuard<A> {
self.inner.lock()
}
}
The type is a generic wrapper around a spin::Mutex<A>. It imposes no restrictions on the wrapped type A, so it can be used to wrap all kinds of types, not just allocators. It provides a simple new constructor function that wraps a given value. For convenience, it also provides a lock function that calls lock on the wrapped Mutex. Since the Locked type is general enough to be useful for other allocator implementations too, we put it in the parent allocator module.
该类型是 spin::Mutex<A> 的通用包装器。它对包装类型 A 没有任何限制,因此它可以用于包装所有类型,而不仅仅是分配器。它提供了一个简单的 new 构造函数来包装给定值。为了方便起见,它还提供了一个 lock 函数,可以在包装的 Mutex 上调用 lock 。由于 Locked 类型足够通用,对于其他分配器实现也很有用,因此我们将其放在父 allocator 模块中。
2.3.4 Implementation for Locked<BumpAllocator>
Locked<BumpAllocator> 的实现
The Locked type is defined in our own crate (in contrast to spin::Mutex), so we can use it to implement GlobalAlloc for our bump allocator. The full implementation looks like this:
Locked 类型是在我们自己的 crate 中定义的(与 spin::Mutex 相比),因此我们可以使用它来为 bump分配器实现 GlobalAlloc 。完整的实现如下所示:
// in src/allocator/bump.rs
use super::{align_up, Locked};
use alloc::alloc::{GlobalAlloc, Layout};
use core::ptr;
unsafe impl GlobalAlloc for Locked<BumpAllocator> {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
let mut bump = self.lock(); // get a mutable reference
let alloc_start = align_up(bump.next, layout.align());
let alloc_end = match alloc_start.checked_add(layout.size()) {
Some(end) => end,
None => return ptr::null_mut(),
};
if alloc_end > bump.heap_end {
ptr::null_mut() // out of memory
} else {
bump.next = alloc_end;
bump.allocations += 1;
alloc_start as *mut u8
}
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {
let mut bump = self.lock(); // get a mutable reference
bump.allocations -= 1;
if bump.allocations == 0 {
bump.next = bump.heap_start;
}
}
}
The first step for both alloc and dealloc is to call the Mutex::lock method through the inner field to get a mutable reference to the wrapped allocator type. The instance remains locked until the end of the method, so that no data race can occur in multithreaded contexts (we will add threading support soon).
alloc 和 dealloc 的第一步是通过 inner 字段调用 Mutex::lock 方法,以获取对包装的可变引用分配器类型。该实例将保持锁定状态,直到方法结束,以便在多线程上下文中不会发生数据争用(我们将很快添加线程支持)。
Compared to the previous prototype, the alloc implementation now respects alignment requirements and performs a bounds check to ensure that the allocations stay inside the heap memory region. The first step is to round up the next address to the alignment specified by the Layout argument. The code for the align_up function is shown in a moment. We then add the requested allocation size to alloc_start to get the end address of the allocation. To prevent integer overflow on large allocations, we use the checked_add method. If an overflow occurs or if the resulting end address of the allocation is larger than the end address of the heap, we return a null pointer to signal an out-of-memory situation. Otherwise, we update the next address and increase the allocations counter by 1 like before. Finally, we return the alloc_start address converted to a *mut u8 pointer.
与之前的原型相比, alloc 实现现在遵循对齐要求并执行边界检查以确保分配保留在堆内存区域内。第一步是将 next 地址向上舍入到 Layout 参数指定的对齐方式。稍后将显示 align_up 函数的代码。然后,我们将请求的分配大小添加到 alloc_start 中以获得分配的结束地址。为了防止大量分配时的整数溢出,我们使用 checked_add 方法。如果发生溢出或者分配的结果结束地址大于堆的结束地址,我们将返回一个空指针以表示内存不足的情况。否则,我们会像以前一样更新 next 地址并将 allocations 计数器加 1。最后,我们返回转换为 *mut u8 指针的 alloc_start 地址。
The dealloc function ignores the given pointer and Layout arguments. Instead, it just decreases the allocations counter. If the counter reaches 0 again, it means that all allocations were freed again. In this case, it resets the next address to the heap_start address to make the complete heap memory available again.
dealloc 函数忽略给定的指针和 Layout 参数。相反,它只是减少 allocations 计数器。如果计数器再次达到 0 ,则意味着所有分配再次被释放。在这种情况下,它将 next 地址重置为 heap_start 地址,以使整个堆内存再次可用。
2.3.5 Address Alignment 地址对齐
The align_up function is general enough that we can put it into the parent allocator module. A basic implementation looks like this:
align_up 函数足够通用,我们可以将其放入父 allocator 模块中。基本实现如下所示:
// in src/allocator.rs
/// Align the given address `addr` upwards to alignment `align`.
fn align_up(addr: usize, align: usize) -> usize {
let remainder = addr % align;
if remainder == 0 {
addr // addr already aligned
} else {
addr - remainder + align
}
}
The function first computes the remainder of the division of addr by align. If the remainder is 0, the address is already aligned with the given alignment. Otherwise, we align the address by subtracting the remainder (so that the new remainder is 0) and then adding the alignment (so that the address does not become smaller than the original address).
该函数首先计算 addr 除以 align 的余数。如果余数为 0 ,则该地址已经与给定的对齐方式对齐。否则,我们通过减去余数(使得新的余数为0)然后加上对齐(使得地址不会变得小于原始地址)来对齐地址。
Note that this isn’t the most efficient way to implement this function. A much faster implementation looks like this:
请注意,这不是实现此功能的最有效方法。更快的实现如下所示:
/// Align the given address `addr` upwards to alignment `align`.
///
/// Requires that `align` is a power of two.
fn align_up(addr: usize, align: usize) -> usize {
(addr + align - 1) & !(align - 1)
}
This method requires align to be a power of two, which can be guaranteed by utilizing the GlobalAlloc trait (and its Layout parameter). This makes it possible to create a bitmask to align the address in a very efficient way. To understand how it works, let’s go through it step by step, starting on the right side:
此方法要求 align 是 2 的幂,这可以通过利用 GlobalAlloc 特征(及其 Layout 参数)来保证。这使得创建位掩码以非常有效的方式对齐地址成为可能。为了理解它是如何工作的,让我们从右侧开始一步步进行:
-
Since
alignis a power of two, its binary representation has only a single bit set (e.g.0b000100000). This means thatalign - 1has all the lower bits set (e.g.0b00011111).由于
align是 2 的幂,因此其二进制表示只有一个位集(例如0b000100000)。这意味着align - 1已设置所有较低位(例如0b00011111)。 -
By creating the bitwise
NOTthrough the!operator, we get a number that has all the bits set except for the bits lower thanalign(e.g.0b…111111111100000).通过通过
!运算符创建按位NOT,我们得到一个数字,其中设置了除低于align的位之外的所有位(例如0b…111111111100000)。 -
By performing a bitwise
ANDon an address and!(align - 1), we align the address downwards. This works by clearing all the bits that are lower thanalign.通过对地址和
!(align - 1)执行按位AND,我们将地址向下对齐。这是通过清除所有低于align的位来实现的。 -
Since we want to align upwards instead of downwards, we increase the
addrbyalign - 1before performing the bitwiseAND. This way, already aligned addresses remain the same while non-aligned addresses are rounded to the next alignment boundary. -
由于我们想要向上而不是向下对齐,因此在执行按位
AND之前,我们将addr增加align - 1。这样,已对齐的地址保持不变,而未对齐的地址则舍入到下一个对齐边界。
Which variant you choose is up to you. Both compute the same result, only using different methods.
您选择哪种方法取决于您。两者计算相同的结果,只是使用不同的方法。
2.4 Using It 使用它
To use the bump allocator instead of the linked_list_allocator crate, we need to update the ALLOCATOR static in allocator.rs:
要使用bump 分配器而不是 linked_list_allocator crate,我们需要更新 allocator.rs 中的 静态 ALLOCATOR :
// in src/allocator.rs
use bump::BumpAllocator;
#[global_allocator]
static ALLOCATOR: Locked<BumpAllocator> = Locked::new(BumpAllocator::new());
Here it becomes important that we declared BumpAllocator::new and Locked::new as const functions. If they were normal functions, a compilation error would occur because the initialization expression of a static must be evaluable at compile time.
在这里,我们将 BumpAllocator::new 和 Locked::new 声明为 const 函数变得很重要。如果它们是普通函数,则会发生编译错误,因为 static 的初始化表达式必须在编译时可计算。
We don’t need to change the ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE) call in our init_heap function because the bump allocator provides the same interface as the allocator provided by the linked_list_allocator.
我们不需要更改 init_heap 函数中的 ALLOCATOR.lock().init(HEAP_START, HEAP_SIZE) 调用,因bump分配器提供与 linked_list_allocator 提供的分配器相同的接口。
Now our kernel uses our bump allocator! Everything should still work, including the heap_allocation tests that we created in the previous post:
现在我们的内核使用我们的bump分配器!一切都应该仍然有效,包括我们在上一篇文章中创建的 heap_allocation 测试:
> cargo test --test heap_allocation
[…]
Running 3 tests
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
2.5 Discussion 讨论
The big advantage of bump allocation is that it’s very fast. Compared to other allocator designs (see below) that need to actively look for a fitting memory block and perform various bookkeeping tasks on alloc and dealloc, a bump allocator can be optimized to just a few assembly instructions. This makes bump allocators useful for optimizing the allocation performance, for example when creating a virtual DOM library.
bump分配的一大优点是速度非常快。与需要主动寻找合适的内存块并在 alloc 和 dealloc 上执行各种簿记任务的其他分配器设计(见下文)相比,bump分配器可以优化为仅一些组装说明。这使得bump分配器对于优化分配性能非常有用,例如在创建虚拟 DOM 库时。
While a bump allocator is seldom used as the global allocator, the principle of bump allocation is often applied in the form of arena allocation, which basically batches individual allocations together to improve performance. An example of an arena allocator for Rust is contained in the toolshed crate.
虽然bump分配器很少用作全局分配器,但bump分配的原理通常以[竞技场分配]的形式应用,它基本上将各个分配批处理在一起以提高性能。 Rust 的 arena 分配器示例包含在 toolshed 箱中。
2.5.1 The Drawback of a Bump Allocator
Bump 分配器的缺点
The main limitation of a bump allocator is that it can only reuse deallocated memory after all allocations have been freed. This means that a single long-lived allocation suffices to prevent memory reuse. We can see this when we add a variation of the many_boxes test:
Bump 分配器的主要限制是它只能在释放所有分配后重用已释放的内存。这意味着单个长期分配足以防止内存重用。当我们添加 many_boxes 测试的用例时,我们可以看到这一点:
// in tests/heap_allocation.rs
#[test_case]
fn many_boxes_long_lived() {
let long_lived = Box::new(1); // new
for i in 0..HEAP_SIZE {
let x = Box::new(i);
assert_eq!(*x, i);
}
assert_eq!(*long_lived, 1); // new
}
Like the many_boxes test, this test creates a large number of allocations to provoke an out-of-memory failure if the allocator does not reuse freed memory. Additionally, the test creates a long_lived allocation, which lives for the whole loop execution.
与 many_boxes 测试类似,此测试会创建大量分配,如果分配器不重用已释放的内存,则会引发内存不足故障。此外,该测试还创建一个 long_lived 分配,该分配在整个循环执行期间都有效。
When we try to run our new test, we see that it indeed fails:
当我们尝试运行新测试时,我们发现它确实失败了:
> cargo test --test heap_allocation
Running 4 tests
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
many_boxes_long_lived... [failed]
Error: panicked at 'allocation error: Layout { size_: 8, align_: 8 }', src/lib.rs:86:5
Let’s try to understand why this failure occurs in detail: First, the long_lived allocation is created at the start of the heap, thereby increasing the allocations counter by 1. For each iteration of the loop, a short-lived allocation is created and directly freed again before the next iteration starts. This means that the allocations counter is temporarily increased to 2 at the beginning of an iteration and decreased to 1 at the end of it. The problem now is that the bump allocator can only reuse memory after all allocations have been freed, i.e., when the allocations counter falls to 0. Since this doesn’t happen before the end of the loop, each loop iteration allocates a new region of memory, leading to an out-of-memory error after a number of iterations.
让我们尝试详细了解为什么会发生此故障:首先, long_lived 分配是在堆的开头创建的,从而使 allocations 计数器增加 1。对于每次迭代循环中,会创建一个短期分配,并在下一次迭代开始之前再次直接释放。这意味着 allocations 计数器在迭代开始时暂时增加到 2,并在迭代结束时减少到 1。现在的问题是,Bump 分配器只能在所有分配都被释放后(即,当 allocations 计数器降至 0 时)才能重用内存。由于这不会在循环结束之前发生,因此每个循环迭代分配新的内存区域,在多次迭代后导致内存不足错误。
2.5.2 Fixing the Test? 修复测试?
There are two potential tricks that we could utilize to fix the test for our bump allocator:
我们可以利用两个潜在的技巧来修复Bump 分配器的测试:
-
We could update
deallocto check whether the freed allocation was the last allocation returned byallocby comparing its end address with thenextpointer. In case they’re equal, we can safely resetnextback to the start address of the freed allocation. This way, each loop iteration reuses the same memory block.我们可以更新
dealloc,通过将其结束地址与next指针进行比较来检查释放的分配是否是alloc返回的最后一个分配。如果它们相等,我们可以安全地将next重置回已释放分配的起始地址。这样,每次循环迭代都会重用相同的内存块。 -
We could add an
alloc_backmethod that allocates memory from the end of the heap using an additionalnext_backfield. Then we could manually use this allocation method for all long-lived allocations, thereby separating short-lived and long-lived allocations on the heap. Note that this separation only works if it’s clear beforehand how long each allocation will live. Another drawback of this approach is that manually performing allocations is cumbersome and potentially unsafe.我们可以添加一个
alloc_back方法,该方法使用附加的next_back字段从堆末尾分配内存。然后我们可以手动对所有长期分配使用这种分配方法,从而将堆上的短期分配和长期分配分开。请注意,只有事先明确每个分配的生存时间,这种分离才有效。这种方法的另一个缺点是手动执行分配很麻烦并且可能不安全。
While both of these approaches work to fix the test, they are not a general solution since they are only able to reuse memory in very specific cases. The question is: Is there a general solution that reuses all freed memory?
虽然这两种方法都可以修复测试,但它们不是通用解决方案,因为它们只能在非常特定的情况下重用内存。问题是:是否有一个通用的解决方案可以重用所有已释放的内存?
2.5.3 Reusing All Freed Memory?
重用所有释放的内存?
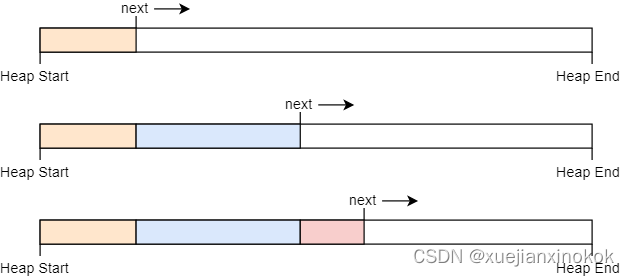
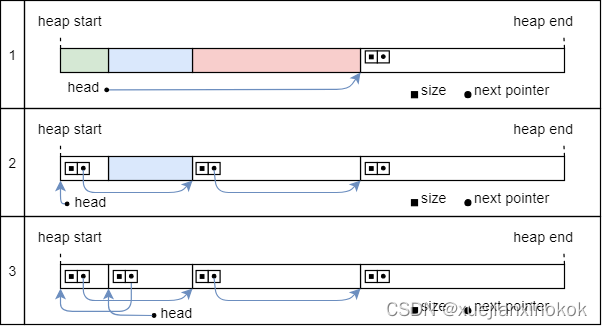
As we learned in the previous post, allocations can live arbitrarily long and can be freed in an arbitrary order. This means that we need to keep track of a potentially unbounded number of non-continuous, unused memory regions, as illustrated by the following example:
正如我们在上一篇文章中了解到的,分配可以存在任意长的时间,并且可以按任意顺序释放。这意味着我们需要跟踪可能无限数量的非连续、未使用的内存区域,如下例所示:
The graphic shows the heap over the course of time. At the beginning, the complete heap is unused, and the next address is equal to heap_start (line 1). Then the first allocation occurs (line 2). In line 3, a second memory block is allocated and the first allocation is freed. Many more allocations are added in line 4. Half of them are very short-lived and already get freed in line 5, where another new allocation is also added.
该图显示了随时间变化的堆。一开始,完整的堆未被使用, next 地址等于 heap_start (第1行)。然后发生第一次分配(第 2 行)。在第 3 行中,分配了第二个内存块,并释放了第一个分配的内存块。第 4 行中添加了更多分配。其中一半的分配非常短暂,并且已在第 5 行中释放,其中还添加了另一个新分配。
Line 5 shows the fundamental problem: We have five unused memory regions with different sizes, but the next pointer can only point to the beginning of the last region. While we could store the start addresses and sizes of the other unused memory regions in an array of size 4 for this example, this isn’t a general solution since we could easily create an example with 8, 16, or 1000 unused memory regions.
第 5 行显示了根本问题:我们有五个不同大小的未使用内存区域,但 next 指针只能指向最后一个区域的开头。虽然在此示例中我们可以将其他未使用内存区域的起始地址和大小存储在大小为 4 的数组中,但这不是通用解决方案,因为我们可以轻松创建具有 8、16 或 1000 个未使用内存区域的示例。
Normally, when we have a potentially unbounded number of items, we can just use a heap-allocated collection. This isn’t really possible in our case, since the heap allocator can’t depend on itself (it would cause endless recursion or deadlocks). So we need to find a different solution.
通常,当我们有可能无限数量的项目时,我们可以只使用堆分配的集合。在我们的例子中,这实际上是不可能的,因为堆分配器不能依赖于自身(这会导致无休止的递归或死锁)。所以我们需要找到不同的解决方案。
3. Linked List Allocator 链表分配器
A common trick to keep track of an arbitrary number of free memory areas when implementing allocators is to use these areas themselves as backing storage. This utilizes the fact that the regions are still mapped to a virtual address and backed by a physical frame, but the stored information is not needed anymore. By storing the information about the freed region in the region itself, we can keep track of an unbounded number of freed regions without needing additional memory.
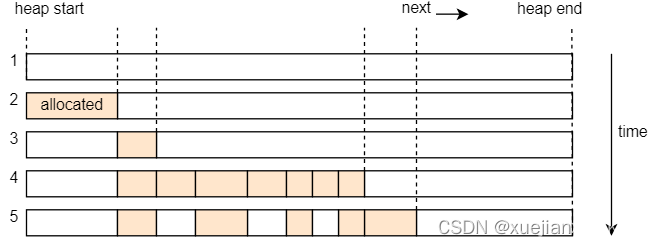
在实现分配器时跟踪任意数量的空闲内存区域的常见技巧是使用这些区域本身作为后备存储。这利用了以下事实:区域仍然映射到虚拟地址并由物理页支持,但不再需要存储的信息。通过将有关已释放区域的信息存储在区域本身中,我们可以跟踪无限数量的已释放区域,而无需额外的内存。
The most common implementation approach is to construct a single linked list in the freed memory, with each node being a freed memory region:
最常见的实现方法是在释放的内存中构造一个单链表,每个节点都是一个释放的内存区域:
Each list node contains two fields: the size of the memory region and a pointer to the next unused memory region. With this approach, we only need a pointer to the first unused region (called head) to keep track of all unused regions, regardless of their number. The resulting data structure is often called a free list.
每个列表节点包含两个字段:内存区域的大小和指向下一个未使用的内存区域的指针。通过这种方法,我们只需要一个指向第一个未使用区域(称为 head )的指针来跟踪所有未使用区域,无论其数量如何。生成的数据结构通常称为空闲列表。
As you might guess from the name, this is the technique that the linked_list_allocator crate uses. Allocators that use this technique are also often called pool allocators.
正如您可能从名称中猜到的,这是 linked_list_allocator crate 使用的技术。使用这种技术的分配器通常也称为池分配器。
3.1 Implementation
In the following, we will create our own simple LinkedListAllocator type that uses the above approach for keeping track of freed memory regions. This part of the post isn’t required for future posts, so you can skip the implementation details if you like.
接下来,我们将创建自己的简单 LinkedListAllocator 类型,该类型使用上述方法来跟踪已释放的内存区域。以后的帖子不需要这部分内容,因此如果您愿意,可以跳过实现细节。
3.1.1 The Allocator Type 分配器类型
We start by creating a private ListNode struct in a new allocator::linked_list submodule:
我们首先在新的 allocator::linked_list 子模块中创建一个私有 ListNode 结构:
// in src/allocator.rs
pub mod linked_list;
// in src/allocator/linked_list.rs
struct ListNode {
size: usize,
next: Option<&'static mut ListNode>,
}
Like in the graphic, a list node has a size field and an optional pointer to the next node, represented by the Option<&'static mut ListNode> type. The &'static mut type semantically describes an owned object behind a pointer. Basically, it’s a Box without a destructor that frees the object at the end of the scope.
如图所示,列表节点有一个 size 字段和一个指向下一个节点的可选指针,由 Option<&'static mut ListNode> 类型表示。 &'static mut 类型在语义上描述了指针背后的拥有对象。基本上,它是一个没有析构函数的 Box ,可以在作用域末尾释放对象。
We implement the following set of methods for ListNode:
我们为 ListNode 实现以下一组方法:
// in src/allocator/linked_list.rs
impl ListNode {
const fn new(size: usize) -> Self {
ListNode { size, next: None }
}
fn start_addr(&self) -> usize {
self as *const Self as usize
}
fn end_addr(&self) -> usize {
self.start_addr() + self.size
}
}
The type has a simple constructor function named new and methods to calculate the start and end addresses of the represented region. We make the new function a const function, which will be required later when constructing a static linked list allocator. Note that any use of mutable references in const functions (including setting the next field to None) is still unstable. In order to get it to compile, we need to add #![feature(const_mut_refs)] to the beginning of our lib.rs.
该类型有一个名为 new 的简单构造函数以及计算所表示区域的起始和结束地址的方法。我们将 new 函数设为 const 函数,稍后在构造静态链表分配器时将需要它。请注意,在 const 函数中使用可变引用(包括将 next 字段设置为 None )仍然不稳定。为了让它编译,我们需要将 #![feature(const_mut_refs)] 添加到 lib.rs 的开头。
With the ListNode struct as a building block, we can now create the LinkedListAllocator struct:
使用 ListNode 结构作为构建块,我们现在可以创建 LinkedListAllocator 结构:
// in src/allocator/linked_list.rs
pub struct LinkedListAllocator {
head: ListNode,
}
impl LinkedListAllocator {
/// Creates an empty LinkedListAllocator.
pub const fn new() -> Self {
Self {
head: ListNode::new(0),
}
}
/// Initialize the allocator with the given heap bounds.
///
/// This function is unsafe because the caller must guarantee that the given
/// heap bounds are valid and that the heap is unused. This method must be
/// called only once.
pub unsafe fn init(&mut self, heap_start: usize, heap_size: usize) {
self.add_free_region(heap_start, heap_size);
}
/// Adds the given memory region to the front of the list.
unsafe fn add_free_region(&mut self, addr: usize, size: usize) {
todo!();
}
}
The struct contains a head node that points to the first heap region. We are only interested in the value of the next pointer, so we set the size to 0 in the ListNode::new function. Making head a ListNode instead of just a &'static mut ListNode has the advantage that the implementation of the alloc method will be simpler.
该结构包含一个指向第一个堆区域的 head 节点。我们只对 next 指针的值感兴趣,因此我们在 ListNode::new 函数中将 size 设置为 0。将 head 设为 ListNode 而不仅仅是 &'static mut ListNode 的优点是 alloc 方法的实现会更简单。
Like for the bump allocator, the new function doesn’t initialize the allocator with the heap bounds. In addition to maintaining API compatibility, the reason is that the initialization routine requires writing a node to the heap memory, which can only happen at runtime. The new function, however, needs to be a const function that can be evaluated at compile time because it will be used for initializing the ALLOCATOR static. For this reason, we again provide a separate, non-constant init method.
与bump 分配器一样, new 函数不会使用堆边界初始化分配器。除了保持 API 兼容性之外,原因还在于初始化例程需要将节点写入堆内存,而这只能在运行时发生。但是, new 函数需要是可以在编译时计算的 const 函数,因为它将用于初始化 ALLOCATOR 静态。为此,我们再次提供一个单独的非常量 init 方法。
The init method uses an add_free_region method, whose implementation will be shown in a moment. For now, we use the todo! macro to provide a placeholder implementation that always panics.
init 方法使用 add_free_region 方法,稍后将显示其实现。目前,我们使用 todo! 宏来提供一个始终会发生恐慌的占位符实现。
The add_free_region Method add_free_region 方法
The add_free_region method provides the fundamental push operation on the linked list. We currently only call this method from init, but it will also be the central method in our dealloc implementation. Remember, the dealloc method is called when an allocated memory region is freed again. To keep track of this freed memory region, we want to push it to the linked list.
add_free_region 方法提供了链表上基本的推送操作。我们目前仅从 init 调用此方法,但它也将是我们 dealloc 实现中的核心方法。请记住,当再次释放已分配的内存区域时,将调用 dealloc 方法。为了跟踪这个已释放的内存区域,我们希望将其推送到链表中。
The implementation of the add_free_region method looks like this:
add_free_region 方法的实现如下所示:
// in src/allocator/linked_list.rs
use super::align_up;
use core::mem;
impl LinkedListAllocator {
/// Adds the given memory region to the front of the list.
unsafe fn add_free_region(&mut self, addr: usize, size: usize) {
// ensure that the freed region is capable of holding ListNode
assert_eq!(align_up(addr, mem::align_of::<ListNode>()), addr);
assert!(size >= mem::size_of::<ListNode>());
// create a new list node and append it at the start of the list
let mut node = ListNode::new(size);
node.next = self.head.next.take();
let node_ptr = addr as *mut ListNode;
node_ptr.write(node);
self.head.next = Some(&mut *node_ptr)
}
}
The method takes the address and size of a memory region as an argument and adds it to the front of the list. First, it ensures that the given region has the necessary size and alignment for storing a ListNode. Then it creates the node and inserts it into the list through the following steps:
该方法将内存区域的地址和大小作为参数,并将其添加到列表的前面。首先,它确保给定区域具有存储 ListNode 所需的大小和对齐方式。然后它创建节点并将其插入到列表中,步骤如下:
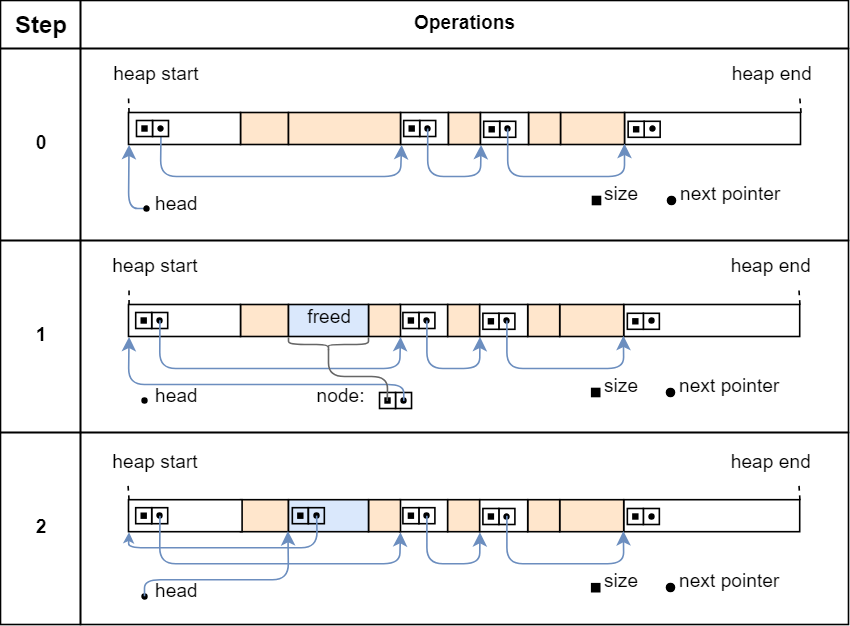
Step 0 shows the state of the heap before add_free_region is called. In step 1, the method is called with the memory region marked as freed in the graphic. After the initial checks, the method creates a new node on its stack with the size of the freed region. It then uses the Option::take method to set the next pointer of the node to the current head pointer, thereby resetting the head pointer to None.
步骤 0 显示调用 add_free_region 之前堆的状态。在步骤 1 中,调用该方法时,内存区域在图形中标记为 freed 。初始检查后,该方法在其堆栈上创建一个新的 node ,其大小与已释放区域的大小相同。然后它使用 Option::take 方法将节点的 next 指针设置为当前的 head 指针,从而将 head 指针重置为 None 。
In step 2, the method writes the newly created node to the beginning of the freed memory region through the write method. It then points the head pointer to the new node. The resulting pointer structure looks a bit chaotic because the freed region is always inserted at the beginning of the list, but if we follow the pointers, we see that each free region is still reachable from the head pointer.
在步骤2中,该方法通过 write 方法将新创建的 node 写入到已释放的内存区域的开头。然后它将 head 指针指向新节点。生成的指针结构看起来有点混乱,因为释放的区域总是插入到列表的开头,但如果我们跟踪指针,我们会看到每个空闲区域仍然可以从 head 指针到达。
The find_region Method find_region 方法
The second fundamental operation on a linked list is finding an entry and removing it from the list. This is the central operation needed for implementing the alloc method. We implement the operation as a find_region method in the following way:
链表上的第二个基本操作是查找条目并将其从链表中删除。这是实现 alloc 方法所需的核心操作。我们通过以下方式将操作实现为 find_region 方法:
// in src/allocator/linked_list.rs
impl LinkedListAllocator {
/// Looks for a free region with the given size and alignment and removes
/// it from the list.
///
/// Returns a tuple of the list node and the start address of the allocation.
fn find_region(&mut self, size: usize, align: usize)
-> Option<(&'static mut ListNode, usize)>
{
// reference to current list node, updated for each iteration
let mut current = &mut self.head;
// look for a large enough memory region in linked list
while let Some(ref mut region) = current.next {
if let Ok(alloc_start) = Self::alloc_from_region(®ion, size, align) {
// region suitable for allocation -> remove node from list
let next = region.next.take();
let ret = Some((current.next.take().unwrap(), alloc_start));
current.next = next;
return ret;
} else {
// region not suitable -> continue with next region
current = current.next.as_mut().unwrap();
}
}
// no suitable region found
None
}
}
The method uses a current variable and a while let loop to iterate over the list elements. At the beginning, current is set to the (dummy) head node. On each iteration, it is then updated to the next field of the current node (in the else block). If the region is suitable for an allocation with the given size and alignment, the region is removed from the list and returned together with the alloc_start address.
该方法使用 current 变量和 while let 循环来迭代列表元素。一开始, current 设置为(虚拟) head 节点。在每次迭代中,它都会更新为当前节点的 next 字段(在 else 块中)。如果该区域适合具有给定大小和对齐方式的分配,则该区域将从列表中删除并与 alloc_start 地址一起返回。
When the current.next pointer becomes None, the loop exits. This means we iterated over the whole list but found no region suitable for an allocation. In that case, we return None. Whether a region is suitable is checked by the alloc_from_region function, whose implementation will be shown in a moment.
当 current.next 指针变为 None 时,循环退出。这意味着我们迭代了整个列表,但没有发现适合分配的区域。在这种情况下,我们返回 None 。区域是否合适由 alloc_from_region 函数检查,其实现稍后将显示。
Let’s take a more detailed look at how a suitable region is removed from the list:
让我们更详细地看看如何从列表中删除合适的区域:
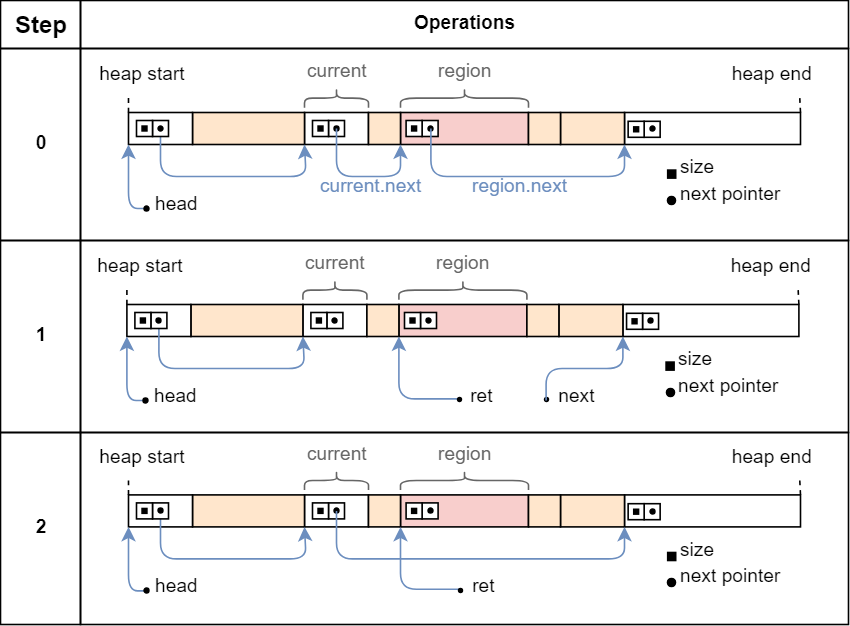
Step 0 shows the situation before any pointer adjustments. The region and current regions and the region.next and current.next pointers are marked in the graphic. In step 1, both the region.next and current.next pointers are reset to None by using the Option::take method. The original pointers are stored in local variables called next and ret.
步骤 0 显示任何指针调整之前的情况。 region 和 current 区域以及 region.next 和 current.next 指针已在图形中标记。在步骤1中,使用 Option::take 方法将 region.next 和 current.next 指针重置为 None 。原始指针存储在名为 next 和 ret 的局部变量中。
In step 2, the current.next pointer is set to the local next pointer, which is the original region.next pointer. The effect is that current now directly points to the region after region, so that region is no longer an element of the linked list. The function then returns the pointer to region stored in the local ret variable.
在步骤2中, current.next 指针被设置为本地 next 指针,即原始的 region.next 指针。效果是 current 现在直接指向 region 之后的区域,因此 region 不再是链表的元素。然后,该函数返回指向存储在本地 ret 变量中的 region 的指针。
The alloc_from_region Function alloc_from_region 函数
The alloc_from_region function returns whether a region is suitable for an allocation with a given size and alignment. It is defined like this:
alloc_from_region 函数返回区域是否适合具有给定大小和对齐方式的分配。它的定义如下:
// in src/allocator/linked_list.rs
impl LinkedListAllocator {
/// Try to use the given region for an allocation with given size and
/// alignment.
///
/// Returns the allocation start address on success.
fn alloc_from_region(region: &ListNode, size: usize, align: usize)
-> Result<usize, ()>
{
let alloc_start = align_up(region.start_addr(), align);
let alloc_end = alloc_start.checked_add(size).ok_or(())?;
if alloc_end > region.end_addr() {
// region too small
return Err(());
}
let excess_size = region.end_addr() - alloc_end;
if excess_size > 0 && excess_size < mem::size_of::<ListNode>() {
// rest of region too small to hold a ListNode (required because the
// allocation splits the region in a used and a free part)
return Err(());
}
// region suitable for allocation
Ok(alloc_start)
}
}
First, the function calculates the start and end address of a potential allocation, using the align_up function we defined earlier and the checked_add method. If an overflow occurs or if the end address is behind the end address of the region, the allocation doesn’t fit in the region and we return an error.
首先,该函数使用我们之前定义的 align_up 函数和 checked_add 方法计算潜在分配的起始和结束地址。如果发生溢出或者结束地址位于区域的结束地址之后,则分配不适合该区域,我们将返回错误。
The function performs a less obvious check after that. This check is necessary because most of the time an allocation does not fit a suitable region perfectly, so that a part of the region remains usable after the allocation. This part of the region must store its own ListNode after the allocation, so it must be large enough to do so. The check verifies exactly that: either the allocation fits perfectly (excess_size == 0) or the excess size is large enough to store a ListNode.
此后该函数执行不太明显的检查。此检查是必要的,因为大多数时候分配并不完全适合合适的区域,因此分配后该区域的一部分仍然可用。这部分区域在分配后必须存储自己的 ListNode ,因此它必须足够大才能这样做。检查准确地验证了:要么分配完全适合( excess_size == 0 ),要么多余的大小足以存储 ListNode 。
Implementing GlobalAlloc
With the fundamental operations provided by the add_free_region and find_region methods, we can now finally implement the GlobalAlloc trait. As with the bump allocator, we don’t implement the trait directly for the LinkedListAllocator but only for a wrapped Locked<LinkedListAllocator>. The Locked wrapper adds interior mutability through a spinlock, which allows us to modify the allocator instance even though the alloc and dealloc methods only take &self references.
通过 add_free_region 和 find_region 方法提供的基本操作,我们现在终于可以实现 GlobalAlloc 特征了。与Bump分配器一样,我们不直接为 LinkedListAllocator 实现该特征,而仅为包装的 Locked<LinkedListAllocator> 实现该特征。 Locked 包装器通过自旋锁添加内部可变性,这允许我们修改分配器实例,即使 alloc 和 dealloc 方法仅采用 &self
The implementation looks like this:
实现如下所示:
// in src/allocator/linked_list.rs
use super::Locked;
use alloc::alloc::{GlobalAlloc, Layout};
use core::ptr;
unsafe impl GlobalAlloc for Locked<LinkedListAllocator> {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
// perform layout adjustments
let (size, align) = LinkedListAllocator::size_align(layout);
let mut allocator = self.lock();
if let Some((region, alloc_start)) = allocator.find_region(size, align) {
let alloc_end = alloc_start.checked_add(size).expect("overflow");
let excess_size = region.end_addr() - alloc_end;
if excess_size > 0 {
allocator.add_free_region(alloc_end, excess_size);
}
alloc_start as *mut u8
} else {
ptr::null_mut()
}
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
// perform layout adjustments
let (size, _) = LinkedListAllocator::size_align(layout);
self.lock().add_free_region(ptr as usize, size)
}
}
Let’s start with the dealloc method because it is simpler: First, it performs some layout adjustments, which we will explain in a moment. Then, it retrieves a &mut LinkedListAllocator reference by calling the Mutex::lock function on the Locked wrapper. Lastly, it calls the add_free_region function to add the deallocated region to the free list.
让我们从 dealloc 方法开始,因为它更简单:首先,它执行一些布局调整,我们稍后将对此进行解释。然后,它通过调用 Locked 包装器上的 Mutex::lock 函数来检索 &mut LinkedListAllocator 引用。最后,它调用 add_free_region 函数将释放的区域添加到空闲列表中。
The alloc method is a bit more complex. It starts with the same layout adjustments and also calls the Mutex::lock function to receive a mutable allocator reference. Then it uses the find_region method to find a suitable memory region for the allocation and remove it from the list. If this doesn’t succeed and None is returned, it returns null_mut to signal an error as there is no suitable memory region.
alloc 方法有点复杂。它以相同的布局调整开始,并且还调用 Mutex::lock 函数来接收可变分配器引用。然后它使用 find_region 方法找到适合分配的内存区域并将其从列表中删除。如果此操作不成功并且返回 None ,则会返回 null_mut 以发出错误信号,因为没有合适的内存区域。
In the success case, the find_region method returns a tuple of the suitable region (no longer in the list) and the start address of the allocation. Using alloc_start, the allocation size, and the end address of the region, it calculates the end address of the allocation and the excess size again. If the excess size is not null, it calls add_free_region to add the excess size of the memory region back to the free list. Finally, it returns the alloc_start address casted as a *mut u8 pointer.
在成功的情况下, find_region 方法返回合适区域(不再在列表中)和分配的起始地址的元组。使用 alloc_start 、分配大小和区域的结束地址,它再次计算分配的结束地址和超出的大小。如果超出的大小不为空,则调用 add_free_region 将内存区域的超出的大小添加回空闲列表。最后,它返回转换为 *mut u8 指针的 alloc_start 地址。
Layout Adjustments
So what are these layout adjustments that we make at the beginning of both alloc and dealloc? They ensure that each allocated block is capable of storing a ListNode. This is important because the memory block is going to be deallocated at some point, where we want to write a ListNode to it. If the block is smaller than a ListNode or does not have the correct alignment, undefined behavior can occur.
那么我们在 alloc 和 dealloc 开头进行的布局调整是什么呢?它们确保每个分配的块都能够存储 ListNode 。这很重要,因为内存块将在某个时刻被释放,此时我们要向其写入 ListNode 。如果块小于 ListNode 或没有正确对齐,则可能会发生未定义的行为。
The layout adjustments are performed by the size_align function, which is defined like this:
布局调整由 size_align 函数执行,其定义如下:
// in src/allocator/linked_list.rs
impl LinkedListAllocator {
/// Adjust the given layout so that the resulting allocated memory
/// region is also capable of storing a `ListNode`.
///
/// Returns the adjusted size and alignment as a (size, align) tuple.
fn size_align(layout: Layout) -> (usize, usize) {
let layout = layout
.align_to(mem::align_of::<ListNode>())
.expect("adjusting alignment failed")
.pad_to_align();
let size = layout.size().max(mem::size_of::<ListNode>());
(size, layout.align())
}
}
First, the function uses the align_to method on the passed Layout to increase the alignment to the alignment of a ListNode if necessary. It then uses the pad_to_align method to round up the size to a multiple of the alignment to ensure that the start address of the next memory block will have the correct alignment for storing a ListNode too. In the second step, it uses the max method to enforce a minimum allocation size of mem::size_of::<ListNode>. This way, the dealloc function can safely write a ListNode to the freed memory block.
首先,如果需要,该函数会在传递的 Layout 上使用 align_to 方法将对齐方式增加到 ListNode 的对齐方式。然后,它使用 pad_to_align 方法将大小四舍五入为对齐方式的倍数,以确保下一个内存块的起始地址也将具有正确的对齐方式来存储 ListNode 。在第二步中,它使用 max 方法强制执行最小分配大小 mem::size_of::<ListNode> 。这样, dealloc 函数就可以安全地将 ListNode 写入已释放的内存块中。
3.2 Using it 使用它
We can now update the ALLOCATOR static in the allocator module to use our new LinkedListAllocator:
我们现在可以更新 allocator 模块中的 ALLOCATOR 静态以使用新的 LinkedListAllocator :
// in src/allocator.rs
use linked_list::LinkedListAllocator;
#[global_allocator]
static ALLOCATOR: Locked<LinkedListAllocator> =
Locked::new(LinkedListAllocator::new());
Since the init function behaves the same for the bump and linked list allocators, we don’t need to modify the init call in init_heap.
由于 init 函数对于Bump分配器和链表分配器的行为相同,因此我们不需要修改 init_heap 中的 init 调用。
When we now run our heap_allocation tests again, we see that all tests pass now, including the many_boxes_long_lived test that failed with the bump allocator:
当我们现在再次运行 heap_allocation 测试时,我们看到所有测试现在都通过了,包括因Bump分配器而失败的 many_boxes_long_lived 测试:
> cargo test --test heap_allocation
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
many_boxes_long_lived... [ok]
This shows that our linked list allocator is able to reuse freed memory for subsequent allocations.
这表明我们的链表分配器能够重用释放的内存进行后续分配。
3.3 Discussion 讨论
In contrast to the bump allocator, the linked list allocator is much more suitable as a general-purpose allocator, mainly because it is able to directly reuse freed memory. However, it also has some drawbacks. Some of them are only caused by our basic implementation, but there are also fundamental drawbacks of the allocator design itself.
与Bump分配器相比,链表分配器更适合作为通用分配器,主要是因为它能够直接重用释放的内存。然而,它也有一些缺点。其中一些只是由我们的基本实现引起的,但分配器设计本身也存在根本缺陷。
Merging Freed Blocks 合并释放的块
The main problem with our implementation is that it only splits the heap into smaller blocks but never merges them back together. Consider this example:
我们的实现的主要问题是它只将堆分割成更小的块,但从不将它们合并在一起。考虑这个例子:
In the first line, three allocations are created on the heap. Two of them are freed again in line 2 and the third is freed in line 3. Now the complete heap is unused again, but it is still split into four individual blocks. At this point, a large allocation might not be possible anymore because none of the four blocks is large enough. Over time, the process continues, and the heap is split into smaller and smaller blocks. At some point, the heap is so fragmented that even normal sized allocations will fail.
在第一行中,在堆上创建了三个分配。其中两个在第 2 行中再次释放,第三个在第 3 行中释放。现在完整的堆再次未使用,但它仍然分为四个单独的块。此时,可能不再可能进行大的分配,因为四个块都不够大。随着时间的推移,该过程继续进行,堆被分成越来越小的块。在某些时候,堆碎片如此之多,甚至正常大小的分配也会失败。
To fix this problem, we need to merge adjacent freed blocks back together. For the above example, this would mean the following:
为了解决这个问题,我们需要将相邻的释放块重新合并在一起。对于上面的例子,这意味着:
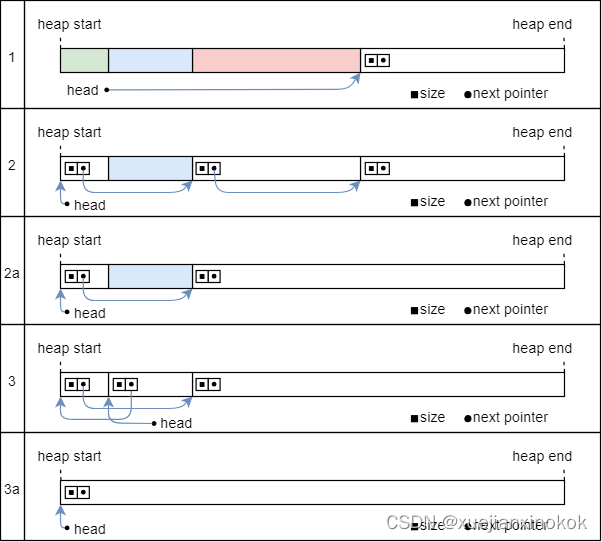
Like before, two of the three allocations are freed in line 2. Instead of keeping the fragmented heap, we now perform an additional step in line 2a to merge the two rightmost blocks back together. In line 3, the third allocation is freed (like before), resulting in a completely unused heap represented by three distinct blocks. In an additional merging step in line 3a, we then merge the three adjacent blocks back together.
与之前一样,三个分配中的两个在 2 行中被释放。现在,我们不再保留碎片堆,而是在 2a 行中执行一个附加步骤,将两个最右边的块重新合并在一起。在 3 行中,第三个分配被释放(像以前一样),导致完全未使用的堆由三个不同的块表示。在 3a 行的附加合并步骤中,我们将三个相邻的块重新合并在一起。
The linked_list_allocator crate implements this merging strategy in the following way: Instead of inserting freed memory blocks at the beginning of the linked list on deallocate, it always keeps the list sorted by start address. This way, merging can be performed directly on the deallocate call by examining the addresses and sizes of the two neighboring blocks in the list. Of course, the deallocation operation is slower this way, but it prevents the heap fragmentation we saw above.
linked_list_allocator 箱通过以下方式实现此合并策略:它始终保持列表按起始地址排序,而不是在 deallocate 上的链接列表的开头插入已释放的内存块。这样,通过检查列表中两个相邻块的地址和大小,可以直接在 deallocate 调用上执行合并。当然,这种方式的释放操作会比较慢,但它可以防止我们上面看到的堆碎片。
Performance 表现
As we learned above, the bump allocator is extremely fast and can be optimized to just a few assembly operations. The linked list allocator performs much worse in this category. The problem is that an allocation request might need to traverse the complete linked list until it finds a suitable block.
正如我们在上面了解到的,Bump分配器速度非常快,并且可以针对少量装配操作进行优化。链表分配器在这一类别中的表现要差得多。问题是分配请求可能需要遍历完整的链表,直到找到合适的块。
Since the list length depends on the number of unused memory blocks, the performance can vary extremely for different programs. A program that only creates a couple of allocations will experience relatively fast allocation performance. For a program that fragments the heap with many allocations, however, the allocation performance will be very bad because the linked list will be very long and mostly contain very small blocks.
由于列表长度取决于未使用的内存块的数量,因此不同程序的性能可能会有很大差异。仅创建几个分配的程序将体验相对较快的分配性能。然而,对于通过多次分配对堆进行碎片化的程序,分配性能将非常糟糕,因为链表将非常长并且大部分包含非常小的块。
It’s worth noting that this performance issue isn’t a problem caused by our basic implementation but a fundamental problem of the linked list approach. Since allocation performance can be very important for kernel-level code, we explore a third allocator design in the following that trades improved performance for reduced memory utilization.
值得注意的是,这个性能问题不是我们的基本实现引起的问题,而是链表方法的根本问题。由于分配性能对于内核级代码非常重要,因此我们在下面探讨了第三种分配器设计,该设计以提高性能来降低内存利用率。
4. Fixed-Size Block Allocator
固定大小块分配器
In the following, we present an allocator design that uses fixed-size memory blocks for fulfilling allocation requests. This way, the allocator often returns blocks that are larger than needed for allocations, which results in wasted memory due to internal fragmentation. On the other hand, it drastically reduces the time required to find a suitable block (compared to the linked list allocator), resulting in much better allocation performance.
下面,我们提出一种分配器设计,它使用固定大小的内存块来满足分配请求。这样,分配器通常会返回大于分配所需的块,从而导致由于内部碎片而浪费内存。另一方面,它大大减少了找到合适块所需的时间(与链表分配器相比),从而带来更好的分配性能。
4.1 Introduction 介绍
The idea behind a fixed-size block allocator is the following: Instead of allocating exactly as much memory as requested, we define a small number of block sizes and round up each allocation to the next block size. For example, with block sizes of 16, 64, and 512 bytes, an allocation of 4 bytes would return a 16-byte block, an allocation of 48 bytes a 64-byte block, and an allocation of 128 bytes a 512-byte block.
固定大小块分配器背后的想法如下:我们定义少量的块大小并将每个分配向上舍入到下一个块大小,而不是完全按照请求分配尽可能多的内存。例如,对于 16、64 和 512 字节的块大小,分配 4 字节将返回 16 字节块,分配 48 字节将返回 64 字节块,分配 128 字节将返回 512 字节块。 。
Like the linked list allocator, we keep track of the unused memory by creating a linked list in the unused memory. However, instead of using a single list with different block sizes, we create a separate list for each size class. Each list then only stores blocks of a single size. For example, with block sizes of 16, 64, and 512, there would be three separate linked lists in memory:
与链表分配器一样,我们通过在未使用的内存中创建链表来跟踪未使用的内存。但是,我们不是使用具有不同块大小的单个列表,而是为每个大小类别创建一个单独的列表。每个列表仅存储单一大小的块。例如,块大小为 16、64 和 512 时,内存中将存在三个独立的链表:
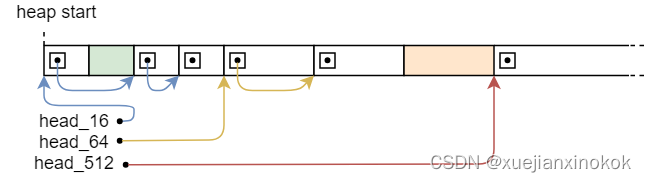
.
Instead of a single head pointer, we have the three head pointers head_16, head_64, and head_512 that each point to the first unused block of the corresponding size. All nodes in a single list have the same size. For example, the list started by the head_16 pointer only contains 16-byte blocks. This means that we no longer need to store the size in each list node since it is already specified by the name of the head pointer.
我们有三个头指针 head_16 、 head_64 和 head_512 ,而不是单个 head 指针,每个指针都指向第一个未使用的头指针相应大小的块。单个列表中的所有节点都具有相同的大小。例如,由 head_16 指针开始的列表仅包含16字节块。这意味着我们不再需要在每个列表节点中存储大小,因为它已经由头指针的名称指定。
Since each element in a list has the same size, each list element is equally suitable for an allocation request. This means that we can very efficiently perform an allocation using the following steps:
由于列表中的每个元素具有相同的大小,因此每个列表元素同样适合分配请求。这意味着我们可以使用以下步骤非常有效地执行分配:
-
Round up the requested allocation size to the next block size. For example, when an allocation of 12 bytes is requested, we would choose the block size of 16 in the above example.
将请求的分配大小向上舍入到下一个块大小。例如,当请求分配 12 字节时,我们将在上例中选择块大小 16。
-
Retrieve the head pointer for the list, e.g., for block size 16, we need to use
head_16.检索列表的头指针,例如,对于块大小 16,我们需要使用
head_16。 -
Remove the first block from the list and return it.
从列表中删除第一个块并将其返回。
Most notably, we can always return the first element of the list and no longer need to traverse the full list. Thus, allocations are much faster than with the linked list allocator.
最值得注意的是,我们始终可以返回列表的第一个元素,而不再需要遍历整个列表。因此,分配比链表分配器快得多。
Block Sizes and Wasted Memory
块大小和浪费的内存
Depending on the block sizes, we lose a lot of memory by rounding up. For example, when a 512-byte block is returned for a 128-byte allocation, three-quarters of the allocated memory is unused. By defining reasonable block sizes, it is possible to limit the amount of wasted memory to some degree. For example, when using the powers of 2 (4, 8, 16, 32, 64, 128, …) as block sizes, we can limit the memory waste to half of the allocation size in the worst case and a quarter of the allocation size in the average case.
根据块大小,我们通过舍入会丢失大量内存。例如,当为 128 字节分配返回 512 字节块时,四分之三的已分配内存未使用。通过定义合理的块大小,可以在一定程度上限制浪费的内存量。例如,当使用 2 的幂(4、8、16、32、64、128…)作为块大小时,我们可以将内存浪费限制在最坏情况下分配大小的一半和分配大小的四分之一平均情况下的大小。
It is also common to optimize block sizes based on common allocation sizes in a program. For example, we could additionally add block size 24 to improve memory usage for programs that often perform allocations of 24 bytes. This way, the amount of wasted memory can often be reduced without losing the performance benefits.
根据程序中常见的分配大小来优化块大小也很常见。例如,我们可以另外添加块大小 24,以改善经常执行 24 字节分配的程序的内存使用情况。这样,通常可以减少浪费的内存量,而不会损失性能优势。
Deallocation 释放
Much like allocation, deallocation is also very performant. It involves the following steps:
与分配非常相似,释放也非常高效。它涉及以下步骤:
-
Round up the freed allocation size to the next block size. This is required since the compiler only passes the requested allocation size to
dealloc, not the size of the block that was returned byalloc. By using the same size-adjustment function in bothallocanddealloc, we can make sure that we always free the correct amount of memory.将释放的分配大小向上舍入到下一个块大小。这是必需的,因为编译器仅将请求的分配大小传递给
dealloc,而不是alloc返回的块的大小。通过在alloc和dealloc中使用相同的大小调整函数,我们可以确保始终释放正确的内存量。 -
Retrieve the head pointer for the list.
检索列表的头指针。
-
Add the freed block to the front of the list by updating the head pointer.
通过更新头指针将释放的块添加到链表的前面。
Most notably, no traversal of the list is required for deallocation either. This means that the time required for a dealloc call stays the same regardless of the list length.
最值得注意的是,释放也不需要遍历列表。这意味着无论列表长度如何, dealloc 调用所需的时间都保持不变。
Fallback Allocator 后备分配器
Given that large allocations (>2 KB) are often rare, especially in operating system kernels, it might make sense to fall back to a different allocator for these allocations. For example, we could fall back to a linked list allocator for allocations greater than 2048 bytes in order to reduce memory waste. Since only very few allocations of that size are expected, the linked list would stay small and the (de)allocations would still be reasonably fast.
鉴于大型分配 (>2 KB) 通常很少见,尤其是在操作系统内核中,因此为这些分配回退到不同的分配器可能是有意义的。例如,对于大于 2048 字节的分配,我们可以回退到链表分配器,以减少内存浪费。由于预计该大小的分配非常少,因此链表将保持很小,并且分配(取消)分配仍然相当快。
Creating new Blocks 创建新块
Above, we always assumed that there are always enough blocks of a specific size in the list to fulfill all allocation requests. However, at some point, the linked list for a given block size becomes empty. At this point, there are two ways we can create new unused blocks of a specific size to fulfill an allocation request:
上面,我们始终假设列表中始终有足够的特定大小的块来满足所有分配请求。然而,在某些时候,给定块大小的链表会变空。此时,我们可以通过两种方法创建特定大小的新的未使用块来满足分配请求:
-
Allocate a new block from the fallback allocator (if there is one).
从后备分配器(如果有)分配一个新块。
-
Split a larger block from a different list. This best works if block sizes are powers of two. For example, a 32-byte block can be split into two 16-byte blocks.
从不同的列表中分割一个更大的块。如果块大小是 2 的幂,则此方法最有效。例如,一个32字节的块可以被分割成两个16字节的块。
For our implementation, we will allocate new blocks from the fallback allocator since the implementation is much simpler.
对于我们的实现,我们将从后备分配器分配新块,因为实现要简单得多。
4.2 Implementation
Now that we know how a fixed-size block allocator works, we can start our implementation. We won’t depend on the implementation of the linked list allocator created in the previous section, so you can follow this part even if you skipped the linked list allocator implementation.
现在我们知道固定大小的块分配器是如何工作的,我们可以开始实现了。我们不会依赖于上一节中创建的链表分配器的实现,因此即使您跳过了链表分配器的实现,也可以按照这部分进行操作。
List Node 列表节点
We start our implementation by creating a ListNode type in a new allocator::fixed_size_block module:
我们通过在新的 allocator::fixed_size_block 模块中创建 ListNode 类型来开始实现:
// in src/allocator.rs
pub mod fixed_size_block;
// in src/allocator/fixed_size_block.rs
struct ListNode {
next: Option<&'static mut ListNode>,
}
This type is similar to the ListNode type of our linked list allocator implementation, with the difference that we don’t have a size field. It isn’t needed because every block in a list has the same size with the fixed-size block allocator design.
此类型类似于我们的链表分配器实现的 ListNode 类型,区别在于我们没有 size 字段。不需要它,因为在固定大小的块分配器设计中,列表中的每个块都具有相同的大小。
Block Sizes 块尺寸
Next, we define a constant BLOCK_SIZES slice with the block sizes used for our implementation:
接下来,我们定义一个常量 BLOCK_SIZES 切片,其中包含用于实现的块大小:
// in src/allocator/fixed_size_block.rs
/// The block sizes to use.
///
/// The sizes must each be power of 2 because they are also used as
/// the block alignment (alignments must be always powers of 2).
const BLOCK_SIZES: &[usize] = &[8, 16, 32, 64, 128, 256, 512, 1024, 2048];
As block sizes, we use powers of 2, starting from 8 up to 2048. We don’t define any block sizes smaller than 8 because each block must be capable of storing a 64-bit pointer to the next block when freed. For allocations greater than 2048 bytes, we will fall back to a linked list allocator.
对于块大小,我们使用 2 的幂,从 8 到 2048。我们不定义任何小于 8 的块大小,因为每个块在释放时必须能够存储指向下一个块的 64 位指针。对于大于 2048 字节的分配,我们将回退到链表分配器。
To simplify the implementation, we define the size of a block as its required alignment in memory. So a 16-byte block is always aligned on a 16-byte boundary and a 512-byte block is aligned on a 512-byte boundary. Since alignments always need to be powers of 2, this rules out any other block sizes. If we need block sizes that are not powers of 2 in the future, we can still adjust our implementation for this (e.g., by defining a second BLOCK_ALIGNMENTS array).
为了简化实现,我们将块的大小定义为其在内存中所需的对齐方式。因此,16 字节块始终在 16 字节边界上对齐,512 字节块始终在 512 字节边界上对齐。由于对齐始终需要为 2 的幂,因此排除了任何其他块大小。如果我们将来需要的块大小不是 2 的幂,我们仍然可以为此调整我们的实现(例如,通过定义第二个 BLOCK_ALIGNMENTS 数组)。
The Allocator Type 分配器类型
Using the ListNode type and the BLOCK_SIZES slice, we can now define our allocator type:
使用 ListNode 类型和 BLOCK_SIZES 切片,我们现在可以定义分配器类型:
// in src/allocator/fixed_size_block.rs
pub struct FixedSizeBlockAllocator {
list_heads: [Option<&'static mut ListNode>; BLOCK_SIZES.len()],
fallback_allocator: linked_list_allocator::Heap,
}
The list_heads field is an array of head pointers, one for each block size. This is implemented by using the len() of the BLOCK_SIZES slice as the array length. As a fallback allocator for allocations larger than the largest block size, we use the allocator provided by the linked_list_allocator. We could also use the LinkedListAllocator we implemented ourselves instead, but it has the disadvantage that it does not merge freed blocks.
list_heads 字段是一个 head 指针数组,每个指针对应一个块大小。这是通过使用 BLOCK_SIZES 切片的 len() 作为数组长度来实现的。作为大于最大块大小的分配的后备分配器,我们使用 linked_list_allocator 提供的分配器。我们也可以使用我们自己实现的 LinkedListAllocator 来代替,但它的缺点是它不会合并释放的块。
For constructing a FixedSizeBlockAllocator, we provide the same new and init functions that we implemented for the other allocator types too:
为了构造 FixedSizeBlockAllocator ,我们提供了与其他分配器类型相同的 new 和 init 函数:
// in src/allocator/fixed_size_block.rs
impl FixedSizeBlockAllocator {
/// Creates an empty FixedSizeBlockAllocator.
pub const fn new() -> Self {
const EMPTY: Option<&'static mut ListNode> = None;
FixedSizeBlockAllocator {
list_heads: [EMPTY; BLOCK_SIZES.len()],
fallback_allocator: linked_list_allocator::Heap::empty(),
}
}
/// Initialize the allocator with the given heap bounds.
///
/// This function is unsafe because the caller must guarantee that the given
/// heap bounds are valid and that the heap is unused. This method must be
/// called only once.
pub unsafe fn init(&mut self, heap_start: usize, heap_size: usize) {
self.fallback_allocator.init(heap_start, heap_size);
}
}
The new function just initializes the list_heads array with empty nodes and creates an empty linked list allocator as fallback_allocator. The EMPTY constant is needed to tell the Rust compiler that we want to initialize the array with a constant value. Initializing the array directly as [None; BLOCK_SIZES.len()] does not work, because then the compiler requires Option<&'static mut ListNode> to implement the Copy trait, which it does not. This is a current limitation of the Rust compiler, which might go away in the future.
new 函数只是用空节点初始化 list_heads 数组,并创建一个 empty 链表分配器作为 fallback_allocator 。 EMPTY 常量需要告诉 Rust 编译器我们想要用常量值初始化数组。直接将数组初始化为 [None; BLOCK_SIZES.len()] 不起作用,因为编译器需要 Option<&'static mut ListNode> 来实现 Copy 特征,但事实并非如此。这是 Rust 编译器当前的限制,将来可能会消失。
If you haven’t done so already for the LinkedListAllocator implementation, you also need to add #![feature(const_mut_refs)] to the top of your lib.rs. The reason is that any use of mutable reference types in const functions is still unstable, including the Option<&'static mut ListNode> array element type of the list_heads field (even if we set it to None).
如果您尚未对 LinkedListAllocator 实现执行此操作,则还需要将 #![feature(const_mut_refs)] 添加到 lib.rs 的顶部。原因是在 const 函数中使用可变引用类型仍然不稳定,包括 list_heads 字段的 Option<&'static mut ListNode> 数组元素类型(即使我们将其设置为 None
The unsafe init function only calls the init function of the fallback_allocator without doing any additional initialization of the list_heads array. Instead, we will initialize the lists lazily on alloc and dealloc calls.
不安全的 init 函数仅调用 fallback_allocator 的 init 函数,而不对 list_heads 数组进行任何额外的初始化。相反,我们将在 alloc 和 dealloc 调用时延迟初始化列表。
For convenience, we also create a private fallback_alloc method that allocates using the fallback_allocator:
为了方便起见,我们还创建了一个使用 fallback_allocator 进行分配的私有 fallback_alloc 方法:
// in src/allocator/fixed_size_block.rs
use alloc::alloc::Layout;
use core::ptr;
impl FixedSizeBlockAllocator {
/// Allocates using the fallback allocator.
fn fallback_alloc(&mut self, layout: Layout) -> *mut u8 {
match self.fallback_allocator.allocate_first_fit(layout) {
Ok(ptr) => ptr.as_ptr(),
Err(_) => ptr::null_mut(),
}
}
}
The Heap type of the linked_list_allocator crate does not implement GlobalAlloc (as it’s not possible without locking). Instead, it provides an allocate_first_fit method that has a slightly different interface. Instead of returning a *mut u8 and using a null pointer to signal an error, it returns a Result<NonNull<u8>, ()>. The NonNull type is an abstraction for a raw pointer that is guaranteed to not be a null pointer. By mapping the Ok case to the NonNull::as_ptr method and the Err case to a null pointer, we can easily translate this back to a *mut u8 type.
linked_list_allocator crate 的 Heap 类型不实现 GlobalAlloc (因为没有锁定就不可能实现)。相反,它提供了一个接口略有不同的 allocate_first_fit 方法。它不是返回 *mut u8 并使用空指针来表示错误,而是返回 Result<NonNull<u8>, ()> 。 NonNull 类型是原始指针的抽象,保证不是空指针。通过将 Ok 情况映射到 NonNull::as_ptr 方法,并将 Err 情况映射到空指针,我们可以轻松地将其转换回 *mut u8 类型。
Calculating the List Index
计算列表索引
Before we implement the GlobalAlloc trait, we define a list_index helper function that returns the lowest possible block size for a given Layout:
在实现 GlobalAlloc 特征之前,我们定义一个 list_index 辅助函数,它返回给定 Layout 的最小可能块大小:
// in src/allocator/fixed_size_block.rs
/// Choose an appropriate block size for the given layout.
///
/// Returns an index into the `BLOCK_SIZES` array.
fn list_index(layout: &Layout) -> Option<usize> {
let required_block_size = layout.size().max(layout.align());
BLOCK_SIZES.iter().position(|&s| s >= required_block_size)
}
The block must have at least the size and alignment required by the given Layout. Since we defined that the block size is also its alignment, this means that the required_block_size is the maximum of the layout’s size() and align() attributes. To find the next-larger block in the BLOCK_SIZES slice, we first use the iter() method to get an iterator and then the position() method to find the index of the first block that is at least as large as the required_block_size.
该块必须至少具有给定 Layout 所需的大小和对齐方式。由于我们定义块大小也是其对齐方式,这意味着 required_block_size 是布局的 size() 和 align() 属性中的最大值。为了在 BLOCK_SIZES 切片中查找下一个更大的块,我们首先使用 iter() 方法获取迭代器,然后使用 position() 方法查找索引第一个块至少与 required_block_size 一样大。
Note that we don’t return the block size itself, but the index into the BLOCK_SIZES slice. The reason is that we want to use the returned index as an index into the list_heads array.
请注意,我们不返回块大小本身,而是返回 BLOCK_SIZES 切片的索引。原因是我们想使用返回的索引作为 list_heads 数组的索引。
Implementing GlobalAlloc
The last step is to implement the GlobalAlloc trait:
最后一步是实现 GlobalAlloc 特征:
// in src/allocator/fixed_size_block.rs
use super::Locked;
use alloc::alloc::GlobalAlloc;
unsafe impl GlobalAlloc for Locked<FixedSizeBlockAllocator> {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
todo!();
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
todo!();
}
}
Like for the other allocators, we don’t implement the GlobalAlloc trait directly for our allocator type, but use the Locked wrapper to add synchronized interior mutability. Since the alloc and dealloc implementations are relatively large, we introduce them one by one in the following.
与其他分配器一样,我们不直接为分配器类型实现 GlobalAlloc 特征,而是使用 Locked 包装器来添加同步内部可变性。由于 alloc 和 dealloc 的实现比较大,下面我们一一介绍。
实现 alloc
The implementation of the alloc method looks like this:
alloc 方法的实现如下所示:
// in `impl` block in src/allocator/fixed_size_block.rs
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
let mut allocator = self.lock();
match list_index(&layout) {
Some(index) => {
match allocator.list_heads[index].take() {
Some(node) => {
allocator.list_heads[index] = node.next.take();
node as *mut ListNode as *mut u8
}
None => {
// no block exists in list => allocate new block
let block_size = BLOCK_SIZES[index];
// only works if all block sizes are a power of 2
let block_align = block_size;
let layout = Layout::from_size_align(block_size, block_align)
.unwrap();
allocator.fallback_alloc(layout)
}
}
}
None => allocator.fallback_alloc(layout),
}
}
Let’s go through it step by step:
让我们一步步看一下:
First, we use the Locked::lock method to get a mutable reference to the wrapped allocator instance. Next, we call the list_index function we just defined to calculate the appropriate block size for the given layout and get the corresponding index into the list_heads array. If this index is None, no block size fits for the allocation, therefore we use the fallback_allocator using the fallback_alloc function.
首先,我们使用 Locked::lock 方法获取对包装的分配器实例的可变引用。接下来,我们调用刚刚定义的 list_index 函数来计算给定布局的适当块大小,并将相应的索引获取到 list_heads 数组中。如果此索引为 None ,则没有适合分配的块大小,因此我们使用 fallback_allocator 和 fallback_alloc 函数。
If the list index is Some, we try to remove the first node in the corresponding list started by list_heads[index] using the Option::take method. If the list is not empty, we enter the Some(node) branch of the match statement, where we point the head pointer of the list to the successor of the popped node (by using take again). Finally, we return the popped node pointer as a *mut u8.
如果列表索引为 Some ,我们尝试使用 Option::take 方法删除由 list_heads[index] 开头的相应列表中的第一个节点。如果列表不为空,则进入 match 语句的 Some(node) 分支,将列表的头指针指向弹出的 node )。最后,我们将弹出的 node 指针作为 *mut u8 返回。
If the list head is None, it indicates that the list of blocks is empty. This means that we need to construct a new block as described above. For that, we first get the current block size from the BLOCK_SIZES slice and use it as both the size and the alignment for the new block. Then we create a new Layout from it and call the fallback_alloc method to perform the allocation. The reason for adjusting the layout and alignment is that the block will be added to the block list on deallocation.
如果列表头是 None ,则表明块列表为空。这意味着我们需要如上所述构造一个新块。为此,我们首先从 BLOCK_SIZES 切片中获取当前块大小,并将其用作新块的大小和对齐方式。然后我们从中创建一个新的 Layout 并调用 fallback_alloc 方法来执行分配。调整布局和对齐方式的原因是该块将在释放时添加到块列表中。
实现dealloc
The implementation of the dealloc method looks like this:
dealloc 方法的实现如下所示:
// in src/allocator/fixed_size_block.rs
use core::{mem, ptr::NonNull};
// inside the `unsafe impl GlobalAlloc` block
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
let mut allocator = self.lock();
match list_index(&layout) {
Some(index) => {
let new_node = ListNode {
next: allocator.list_heads[index].take(),
};
// verify that block has size and alignment required for storing node
assert!(mem::size_of::<ListNode>() <= BLOCK_SIZES[index]);
assert!(mem::align_of::<ListNode>() <= BLOCK_SIZES[index]);
let new_node_ptr = ptr as *mut ListNode;
new_node_ptr.write(new_node);
allocator.list_heads[index] = Some(&mut *new_node_ptr);
}
None => {
let ptr = NonNull::new(ptr).unwrap();
allocator.fallback_allocator.deallocate(ptr, layout);
}
}
}
Like in alloc, we first use the lock method to get a mutable allocator reference and then the list_index function to get the block list corresponding to the given Layout. If the index is None, no fitting block size exists in BLOCK_SIZES, which indicates that the allocation was created by the fallback allocator. Therefore, we use its deallocate to free the memory again. The method expects a NonNull instead of a *mut u8, so we need to convert the pointer first. (The unwrap call only fails when the pointer is null, which should never happen when the compiler calls dealloc.)
与 alloc 一样,我们首先使用 lock 方法获取可变分配器引用,然后使用 list_index 函数获取与给定 Layout 。如果索引为 None ,则 BLOCK_SIZES 中不存在合适的块大小,这表明分配是由后备分配器创建的。因此,我们再次使用它的 deallocate 来释放内存。该方法需要 NonNull 而不是 *mut u8 ,因此我们需要首先转换指针。 ( unwrap 调用仅在指针为 null 时失败,而当编译器调用 dealloc 时,这种情况永远不会发生。)
If list_index returns a block index, we need to add the freed memory block to the list. For that, we first create a new ListNode that points to the current list head (by using Option::take again). Before we write the new node into the freed memory block, we first assert that the current block size specified by index has the required size and alignment for storing a ListNode. Then we perform the write by converting the given *mut u8 pointer to a *mut ListNode pointer and then calling the unsafe write method on it. The last step is to set the head pointer of the list, which is currently None since we called take on it, to our newly written ListNode. For that, we convert the raw new_node_ptr to a mutable reference.
如果 list_index 返回块索引,我们需要将释放的内存块添加到列表中。为此,我们首先创建一个新的 ListNode 指向当前列表头(再次使用 Option::take )。在将新节点写入已释放的内存块之前,我们首先断言 index 指定的当前块大小具有存储 ListNode 所需的大小和对齐方式。然后,我们通过将给定的 *mut u8 指针转换为 *mut ListNode 指针,然后对其调用不安全的 write 方法来执行写入。最后一步是将列表的头指针(当前为 None 因为我们在其上调用 take )设置为我们新编写的 ListNode 。为此,我们将原始 new_node_ptr 转换为可变引用。
There are a few things worth noting:
有几点值得注意:
-
We don’t differentiate between blocks allocated from a block list and blocks allocated from the fallback allocator. This means that new blocks created in
allocare added to the block list ondealloc, thereby increasing the number of blocks of that size.我们不区分从块列表分配的块和从后备分配器分配的块。这意味着在
alloc中创建的新块将添加到dealloc上的块列表中,从而增加该大小的块的数量。 -
The
allocmethod is the only place where new blocks are created in our implementation. This means that we initially start with empty block lists and only fill these lists lazily when allocations of their block size are performed.alloc方法是我们的实现中创建新块的唯一位置。这意味着我们最初从空块列表开始,并且仅在执行块大小分配时才延迟填充这些列表。 -
We don’t need
unsafeblocks inallocanddealloc, even though we perform someunsafeoperations. The reason is that Rust currently treats the complete body of unsafe functions as one largeunsafeblock. Since using explicitunsafeblocks has the advantage that it’s obvious which operations are unsafe and which are not, there is a proposed RFC to change this behavior.即使我们执行一些
unsafe操作,我们也不需要alloc和dealloc中的unsafe块。原因是 Rust 目前将不安全函数的完整主体视为一个大的unsafe块。由于使用显式unsafe块的优点是哪些操作不安全、哪些操作不安全一目了然,因此有一个提议的 RFC 来改变这种行为。
4.3 Using it 使用它
To use our new FixedSizeBlockAllocator, we need to update the ALLOCATOR static in the allocator module:
要使用新的 FixedSizeBlockAllocator ,我们需要更新 allocator 模块中的静态 ALLOCATOR :
// in src/allocator.rs
use fixed_size_block::FixedSizeBlockAllocator;
#[global_allocator]
static ALLOCATOR: Locked<FixedSizeBlockAllocator> = Locked::new(
FixedSizeBlockAllocator::new());
Since the init function behaves the same for all allocators we implemented, we don’t need to modify the init call in init_heap.
由于 init 函数对于我们实现的所有分配器的行为都是相同的,因此我们不需要修改 init_heap 中的 init 调用。
When we now run our heap_allocation tests again, all tests should still pass:
当我们现在再次运行 heap_allocation 测试时,所有测试仍应通过:
> cargo test --test heap_allocation
simple_allocation... [ok]
large_vec... [ok]
many_boxes... [ok]
many_boxes_long_lived... [ok]
Our new allocator seems to work!
我们的新分配器似乎有效!
4.4 Discussion 讨论
While the fixed-size block approach has much better performance than the linked list approach, it wastes up to half of the memory when using powers of 2 as block sizes. Whether this tradeoff is worth it heavily depends on the application type. For an operating system kernel, where performance is critical, the fixed-size block approach seems to be the better choice.
虽然固定大小的块方法比链表方法具有更好的性能,但当使用 2 的幂作为块大小时,它会浪费多达一半的内存。这种权衡是否值得在很大程度上取决于应用程序类型。对于性能至关重要的操作系统内核来说,固定大小的块方法似乎是更好的选择。
On the implementation side, there are various things that we could improve in our current implementation:
在实施方面,我们当前的实施中有很多可以改进的地方:
-
Instead of only allocating blocks lazily using the fallback allocator, it might be better to pre-fill the lists to improve the performance of initial allocations.
与其仅使用后备分配器延迟分配块,不如预先填充列表以提高初始分配的性能。
-
To simplify the implementation, we only allowed block sizes that are powers of 2 so that we could also use them as the block alignment. By storing (or calculating) the alignment in a different way, we could also allow arbitrary other block sizes. This way, we could add more block sizes, e.g., for common allocation sizes, in order to minimize the wasted memory.
为了简化实现,我们只允许块大小为 2 的幂,这样我们也可以使用它们作为块对齐。通过以不同的方式存储(或计算)对齐方式,我们还可以允许任意其他块大小。这样,我们可以添加更多的块大小,例如,对于常见的分配大小,以最大限度地减少浪费的内存。
-
We currently only create new blocks, but never free them again. This results in fragmentation and might eventually result in allocation failure for large allocations. It might make sense to enforce a maximum list length for each block size. When the maximum length is reached, subsequent deallocations are freed using the fallback allocator instead of being added to the list.
我们目前只创建新块,但不再释放它们。这会导致碎片,并可能最终导致大型分配的分配失败。强制每个块大小的最大列表长度可能是有意义的。当达到最大长度时,后续的释放将使用后备分配器释放,而不是添加到列表中。
-
Instead of falling back to a linked list allocator, we could have a special allocator for allocations greater than 4 KiB. The idea is to utilize paging, which operates on 4 KiB pages, to map a continuous block of virtual memory to non-continuous physical frames. This way, fragmentation of unused memory is no longer a problem for large allocations.
我们可以为大于 4 KiB 的分配提供一个特殊的分配器,而不是退回到链表分配器。这个想法是利用分页(在 4 KiB 页面上运行)将连续的虚拟内存块映射到非连续的物理帧。这样,未使用的内存碎片对于大型分配不再是问题。
-
With such a page allocator, it might make sense to add block sizes up to 4 KiB and drop the linked list allocator completely. The main advantages of this would be reduced fragmentation and improved performance predictability, i.e., better worst-case performance.
使用这样的页面分配器,添加高达 4 KiB 的块大小并完全删除链接列表分配器可能是有意义的。这样做的主要优点是减少碎片并提高性能可预测性,即更好的最坏情况性能。
It’s important to note that the implementation improvements outlined above are only suggestions. Allocators used in operating system kernels are typically highly optimized for the specific workload of the kernel, which is only possible through extensive profiling.
值得注意的是,上述实施改进只是建议。操作系统内核中使用的分配器通常针对内核的特定工作负载进行高度优化,这只有通过广泛的分析才能实现。
4.5 Variations 变体
There are also many variations of the fixed-size block allocator design. Two popular examples are the slab allocator and the buddy allocator, which are also used in popular kernels such as Linux. In the following, we give a short introduction to these two designs.
固定大小的块分配器设计也有许多变体。两个流行的例子是slab分配器和buddy分配器,它们也用在Linux等流行内核中。下面我们对这两种设计进行简单介绍。
4.5.1 Slab Allocator
The idea behind a slab allocator is to use block sizes that directly correspond to selected types in the kernel. This way, allocations of those types fit a block size exactly and no memory is wasted. Sometimes, it might be even possible to preinitialize type instances in unused blocks to further improve performance.
Slab分配器背后的想法是使用直接对应于内核中选定类型的块大小。这样,这些类型的分配完全适合块大小,并且不会浪费内存。有时,甚至可以在未使用的块中预初始化类型实例,以进一步提高性能。
Slab allocation is often combined with other allocators. For example, it can be used together with a fixed-size block allocator to further split an allocated block in order to reduce memory waste. It is also often used to implement an object pool pattern on top of a single large allocation.
Slab分配通常与其他分配器结合使用。例如,它可以与固定大小的块分配器一起使用,以进一步分割分配的块,以减少内存浪费。它还经常用于在单个大型分配之上实现对象池模式。
4.5.2 Buddy Allocator 伙伴分配器
Instead of using a linked list to manage freed blocks, the buddy allocator design uses a binary tree data structure together with power-of-2 block sizes. When a new block of a certain size is required, it splits a larger sized block into two halves, thereby creating two child nodes in the tree. Whenever a block is freed again, its neighbor block in the tree is analyzed. If the neighbor is also free, the two blocks are joined back together to form a block of twice the size.
伙伴分配器设计不使用链表来管理释放的块,而是使用二叉树数据结构和 2 的幂次方块大小。当需要一定大小的新块时,它将较大尺寸的块分成两半,从而在树中创建两个子节点。每当一个块再次被释放时,就会分析树中它的邻居块。如果邻居也空闲,则这两个块将重新连接在一起以形成两倍大小的块。
The advantage of this merge process is that external fragmentation is reduced so that small freed blocks can be reused for a large allocation. It also does not use a fallback allocator, so the performance is more predictable. The biggest drawback is that only power-of-2 block sizes are possible, which might result in a large amount of wasted memory due to internal fragmentation. For this reason, buddy allocators are often combined with a slab allocator to further split an allocated block into multiple smaller blocks.
此合并过程的优点是减少了外部碎片,以便可以将小的释放块重新用于大型分配。它也不使用后备分配器,因此性能更可预测。最大的缺点是只能使用 2 的幂次方块大小,这可能会因内部碎片而导致大量内存浪费。因此,伙伴分配器通常与slab分配器结合使用,以进一步将分配的块分割成多个更小的块。
5. 总结
This post gave an overview of different allocator designs. We learned how to implement a basic bump allocator, which hands out memory linearly by increasing a single next pointer. While bump allocation is very fast, it can only reuse memory after all allocations have been freed. For this reason, it is rarely used as a global allocator.
这篇文章概述了不同的分配器设计。我们学习了如何实现基本的Bump分配器,它通过增加单个 next 指针来线性分配内存。虽然Bump分配非常快,但它只能在所有分配都被释放后才能重用内存。因此,它很少用作全局分配器。
Next, we created a linked list allocator that uses the freed memory blocks itself to create a linked list, the so-called free list. This list makes it possible to store an arbitrary number of freed blocks of different sizes. While no memory waste occurs, the approach suffers from poor performance because an allocation request might require a complete traversal of the list. Our implementation also suffers from external fragmentation because it does not merge adjacent freed blocks back together.
接下来,我们创建了一个链表分配器,它使用释放的内存块本身来创建一个链表,即所谓的空闲列表。该列表使得可以存储任意数量的不同大小的释放块。虽然不会发生内存浪费,但该方法的性能较差,因为分配请求可能需要完整遍历列表。我们的实现还受到外部碎片的影响,因为它不会将相邻的已释放块重新合并在一起。
To fix the performance problems of the linked list approach, we created a fixed-size block allocator that predefines a fixed set of block sizes. For each block size, a separate free list exists so that allocations and deallocations only need to insert/pop at the front of the list and are thus very fast. Since each allocation is rounded up to the next larger block size, some memory is wasted due to internal fragmentation.
为了解决链表方法的性能问题,我们创建了一个固定大小的块分配器,它预定义了一组固定的块大小。对于每个块大小,存在一个单独的空闲列表,因此分配和释放只需要在列表的前面插入/弹出,因此非常快。由于每次分配都会向上舍入到下一个较大的块大小,因此由于内部碎片而浪费了一些内存。
There are many more allocator designs with different tradeoffs. Slab allocation works well to optimize the allocation of common fixed-size structures, but is not applicable in all situations. Buddy allocation uses a binary tree to merge freed blocks back together, but wastes a large amount of memory because it only supports power-of-2 block sizes. It’s also important to remember that each kernel implementation has a unique workload, so there is no “best” allocator design that fits all cases.
还有更多具有不同权衡的分配器设计。Slab分配可以很好地优化常见固定尺寸结构的分配,但并不适用于所有情况。伙伴分配使用二叉树将释放的块合并在一起,但浪费大量内存,因为它只支持 2 的幂的块大小。同样重要的是要记住,每个内核实现都有独特的工作负载,因此不存在适合所有情况的“最佳”分配器设计。
6. What’s next? 下一步是什么?
With this post, we conclude our memory management implementation for now. Next, we will start exploring multitasking, starting with cooperative multitasking in the form of async/await. In subsequent posts, we will then explore threads, multiprocessing, and processes.
通过这篇文章,我们现在结束了内存管理的实现。接下来,我们将开始探索多任务处理,首先从 async/await 形式的协作多任务处理开始。在后续文章中,我们将探讨线程、多处理和进程。