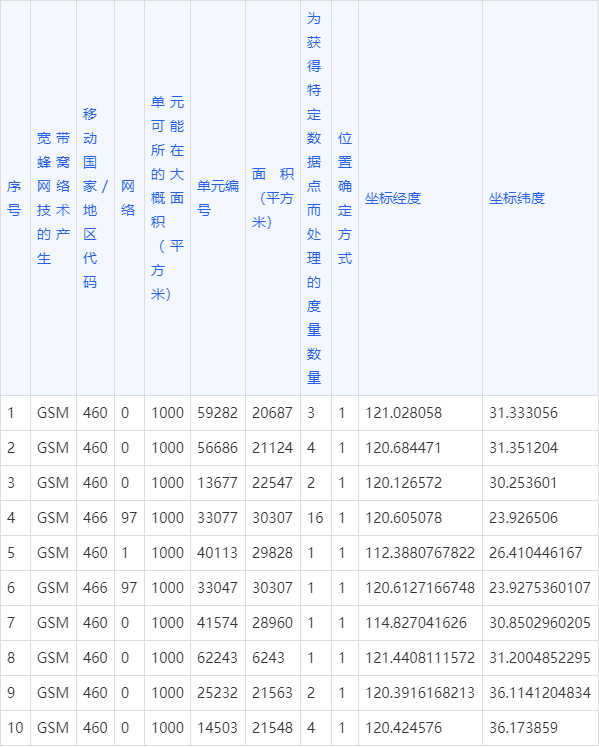
上周末我们服务上线完毕之后发生了一个kafka相关的异常,线上的kafka频繁的rebalance,详细的报错我已经贴到下面,根据字面意思:消费者异常 org.apache.kafka.clients.consumer.CommitFailedException: 无法完成提交,因为消费者组已经重新平衡并将分区分配给另一个成员。这意味着连续调用 poll() 之间的时间超过了配置的 max.poll.interval.ms,通常意味着轮询循环在消息处理上花费了太多时间。您可以通过增加会话超时时间或通过减少 poll() 返回的批次的最大大小(使用 max.poll.records)来解决这个问题。
当然我们的解决方案也是从两个方面展开,分别是“开源” + “截流”。开源就是通过增加处理时间的配置。截流就是通过每一批次的处理数量。上线之后报警消失。通过这次的问题,正好总结一下频繁kafka rebalance 解决方案,希望可以帮助到大家。
consumer ex org.apache.kafka.clients.consumer.CommitFailedException:Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
Kafka是一个高性能、分布式的消息队列系统,但在实际应用中,有时会遇到频繁发生Rebalance的问题。本文将介绍Rebalance的原因、影响以及解决该问题的技术方案。
1. 什么是Kafka的Rebalance
Kafka的Rebalance是指在消费者组中新增或移除消费者时者消费者所订阅的Topic的分区数量发生变化时,Kafka会重新分配分区给消费者,以实现负载均衡。Rebalance的目的是确保每个消费者都能平均地处理分区,提高整体的消费能力,以实现负载均衡和高可用性。
在Rebalance过程中,Kafka会根据配置的Rebalance策略(如Range或RoundRobin)来决定如何分配分区给消费者。具体的分配算法会根据消费者组内的消费者数量、消费者的订阅关系和分区的分配情况来确定。
Rebalance的过程包括以下几个步骤:
- 消费者加入或退出消费者组:当有新的消费者加入或退出消费者组时,Kafka会触发Rebalance操作。
- 分区分配计算:Kafka会根据配置的Rebalance策略和消费者组内的消费者数量,计算出每个消费者应该负责处理的分区。
- 分区分配通知:Kafka会将分区分配结果通知给消费者,告知它们负责处理的分区。
- 消费者重新分配分区:消费者收到分区分配通知后,会重新分配自己负责处理的分区,并开始消费数据。
- 消费者消费数据:消费者根据分配到的分区,从对应的分区中拉取数据并进行消费。
2. Rebalance的原因
Rebalance的发生通常有以下几个原因:
2.1 消费者组中新增或移除消费者
当消费者组中新增或移除消费者时,Kafka会触发Rebalance操作。新增消费者会导致分区重新分配,而移除消费者会导致其所负责的分区重新分配给其他消费者。
2.2 分区的增加或减少
当主题的分区数量发生变化时,Kafka也会触发Rebalance操作。新增分区会导致分区重新分配,而减少分区会导致一些消费者无法分配到分区。
2.3 消费者心跳超时
Kafka通过心跳机制来检测消费者是否存活。如果消费者长时间未发送心跳,Kafka会认为该消费者已经宕机,并将其分区重新分配给其他消费者。
3. Rebalance的影响
Rebalance的频率和耗时取决于多个因素,包括消费者组内的消费者数量、消费者的启停频率、Topic的分区数量和分区的分配情况等。频繁的Rebalance可能会导致消费者在重新分配分区的过程中发生停顿,影响系统的稳定性和性能。因此,合理配置和调优Rebalance相关的参数和策略,对于提高Kafka集群的稳定性和性能非常重要。
3.1 消费延迟增加
Rebalance会导致消费者重新分配分区,消费者需要重新建立与分区的关联关系,这个过程需要一定的时间。频繁的Rebalance会增加消费延迟,影响消息的实时性。
3.2 消费者重复消费
在Rebalance期间,消费者可能会重复消费一些消息。当一个消费者失去分区时,它可能无法及时提交消费位移,导致其他消费者接管该分区时,会重新消费已经消费过的消息。
3.3 消费者失去分区
在Rebalance期间,消费者可能会失去分区,导致消息无法被及时消费。这会导致消息堆积,进一步影响整体的消费能力。
4. 解决频繁Rebalance的技术方案
为了解决频繁发生Rebalance的问题,可以采取以下技术方案:
4.1 增加消费者组的稳定性
消费者组的稳定性对于减少Rebalance非常重要。可以通过以下方式增加消费者组的稳定性:
- 避免频繁地新增或移除消费者,尽量保持消费者组的稳定性。
- 设置合理的心跳超时时间,避免误判消费者宕机。
- 避免消费者长时间阻塞,及时处理消费任务。
4.2 增加分区的稳定性
分区的稳定性也对减少Rebalance非常重要。可以通过以下方式增加分区的稳定性:
- 避免频繁地增加或减少分区,尽量保持分区数量的稳定。
- 合理规划分区的分配策略,避免某些消费者负载过重或无法分配到分区。
4.3 动态调整消费者组和分区的配置
根据实际情况,动态调整消费者组和分区的配置,可以有效减少Rebalance的频率。可以通过以下方式进行配置调整:
- 根据消费者组的负载情况,适时增加或减少消费者的数量。
- 根据主题的负载情况,适时增加或减少分区的数量。
4.4 使用Kafka的自动Rebalance策略
Kafka提供了多种Rebalance策略,可以根据实际需求选择合适的策略。可以通过配置文件或代码来指定Rebalance策略,以减少Rebalance的频率。
5. 相关配置
Kafka提供了一些相关的配置参数,可以用于调整和控制Rebalance的行为。下面是一些常用的Kafka Rebalance相关配置参数的详细说明:
- group.initial.rebalance.delay.ms:
- 类型:long
- 默认值:0
- 描述:设置消费者组初始Rebalance的延迟时间,单位为毫秒。默认值为0,表示立即触发Rebalance。增加延迟时间可以给消费者更多的时间加入消费者组,减少Rebalance的频率。
- group.max.rebalance.delay.ms:
- 类型:long
- 默认值:300000(5分钟)
- 描述:设置消费者组最大Rebalance的延迟时间,单位为毫秒。默认值为300000,表示最多延迟5分钟触发Rebalance。增加延迟时间可以减少Rebalance的频率,但也会增加消费者加入或退出消费者组的等待时间。
- partition.assignment.strategy:
- 类型:String
- 默认值:
org.apache.kafka.clients.consumer.RangeAssignor
- 描述:设置Rebalance的策略。Kafka提供了多种策略可供选择,包括
org.apache.kafka.clients.consumer.RangeAssignor(按照分区范围分配)和
org.apache.kafka.clients.consumer.RoundRobinAssignor(轮询分配)。可以根据实际需求选择合适的策略。
- num.partitions:
- 类型:int
- 默认值:1
- 描述:设置Topic的分区数量。通过增加分区数量可以减少Rebalance的频率,但需要注意分区数的增加可能会导致消费者端的负载增加。在创建Topic时,可以通过指定分区数量来设置。
这些配置参数可以通过在Kafka的配置文件(如server.properties)中进行设置,或者通过编程方式在消费者端进行配置。根据实际需求和场景,可以调整这些参数的值来优化Rebalance的行为,提高Kafka集群的稳定性和性能。
需要注意的是,调整这些配置参数时需要综合考虑系统的负载、消费者组的规模和消费者的启停情况等因素,以避免引入新的问题或影响系统的正常运行。在进行调优时,建议先进行测试和评估,以确保调整后的配置能够满足实际需求。
6. 调优策略
- 监控消费者组的消费情况:通过监控消费者组的消费情况,可以及时发现消费者的启停情况,避免因消费者的频繁启停导致Rebalance的频繁发生。
- 预估消费者组的消费能力:通过预估消费者组的消费能力,可以合理配置消费者的数量和分区的数量,避免因消费者数量和分区数量不匹配导致Rebalance的频繁发生。
- 配置合适的Rebalance超时时间:根据实际情况,调整Rebalance超时时间,避免Rebalance的频繁触发。
7. 结论
频繁发生Rebalance会对Kafka的性能和稳定性产生一定的影响,因此解决该问题非常重要。本文介绍了Rebalance的原因、影响以及解决该问题的技术方案。通过增加消费者组和分区的稳定性,动态调整配置以及使用合适的Rebalance策略,可以有效减少Rebalance的频率,提高Kafka的性能和稳定性。