前言
最近工作比较忙,没怎么记录东西了。Android的Handler重要性不必赘述,之前也写过几篇关于hanlder的文章了:
- Handler有多深?连环二十七问
- Android多线程:深入分析 Handler机制源码(二)
Android单个进程其实就是个死循环,里面接收handler发来的事件处理,所谓的事件驱动系统。本篇文章我们将深入 Native 层,一起来探究 Looper#loop() 为什么不会卡死主线程背后的原因。
从 Android 2.3 开始,Google 把 Handler 的阻塞/唤醒方案从 Object#wait() / notify(),改成了用 Linux epoll 来实现。
原因是 Native 层也引入了一套消息管理机制,用于提供给 C/C++ 开发者使用,而现有的阻塞/唤醒方案是为 Java 层准备的,只支持 Java。
Native 希望能够像 Java 一样:main 线程在没有消息时进入阻塞状态,有到期消息需要执行时,main 线程能及时醒过来处理。怎么办?有两种选择:
- 要么,继续使用 Object#wait() / notify( ),Native 向消息队列添加新消息时,通知 Java 层自己需要什么时候被唤醒
- 要么,在 Native 层重新实现一套阻塞/唤醒方案,弃用 Object#wait() / notify() ,Java 通过 jni 调用 Native 进入阻塞态
结局我们都知道了,Google 选择了后者。
其实如果只是将 Java 层的阻塞/唤醒移植到 Native 层,倒也不用祭出 epoll 这个大杀器 ,Native 调用 pthread_cond_wait 也能达到相同的效果。
选择 epoll 的另一个原因是, Native 层支持监听 自定义 Fd (比如 Input 事件就是通过 epoll 监听 socketfd 来实现将事件转发到 APP 进程的),而一旦有监听多个流事件的需求,那就只能使用 Linux I/O 多路复用技术。
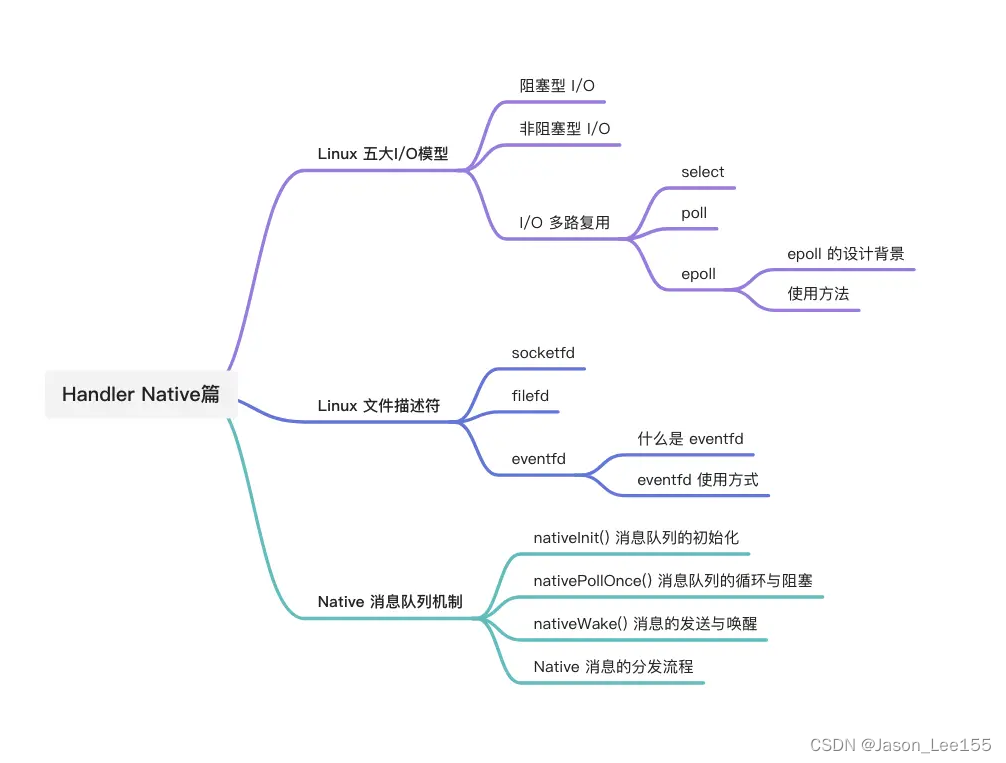
理解 I/O多路复用之epoll
说了这么多,那到底什么是 epoll ?
epoll 全称 eventpoll,是 Linux I/O 多路复用的其中一个实现,除了 epoll 外,还有 select 和 poll ,我们这只讨论 epoll。
要理解 epoll ,我们首先需要理解什么是 "流"?
在 Linux 中,任何可以进行 I/O 操作的对象都可以看做是流,一个 文件, socket, pipe,我们都可以把他们看作流。
接着我们来讨论流的 I/O 操作,通过调用 read() ,我们可以从流中读出数据;通过 write() ,我们可以往流 写入数据。
现在假定一个情形,我们需要从流中读数据,但是流中还没有数据:
int socketfd = socket();
connect(socketfd,serverAddr);
int n = send(socketfd,'在吗');
n = recv(socketfd); //等待接受服务器端 发过来的信息
...//处理服务器返回的数据
一个典型的例子为,客户端要从 socket 中读数据,但是服务器还没有把数据传回来,这时候该怎么办?
- 阻塞: 线程阻塞到 recv() 方法,直到读到数据后再继续向下执行;
- 非阻塞: recv() 方法没读到数据立刻返回 -1 ,用户线程按照固定间隔轮询 recv() 方法,直到有数据返回;
好,现在我们有了阻塞和非阻塞两种解决方案,接着我们同时发起100个网络请求,看看这两种方案各自会怎么处理:
先说阻塞模式,在阻塞模式下,一个线程一次只能处理一个流的 I/O 事件,想要同时处理多个流,只能使用 多线程 + 阻塞 I/O 的方案。但是,每个 socket 对应一个线程会造成很大的资源占用,尤其是对于长连接来说,线程资源一直不会释放,如果后面陆续有很多连接的话,很快就会把机器的内存跑完。
在非阻塞模式下,我们发现 单线程可以同时处理多个流了。只要不停的把所有流从头到尾的访问一遍,就可以得知哪些流有数据(返回值大于-1),但这样的做法效率也不高,因为如果所有的流都没有数据,那么只会白白浪费 CPU。
发现问题了吗?只有阻塞和非阻塞这两种方案时,一旦有监听多个流事件的需求,用户程序只能选择,要么浪费线程资源(阻塞型 I/O),要么浪费 CPU 资源(非阻塞型 I/O),没有其他更高效的方案。
并且,这个问题在用户程序端是无解的,必须让内核创建某种机制,把这些流的监听事件接管过去,因为任何事件都必须通过内核读取转发,内核总是能在第一时间知晓事件发生。
这种能够让用户程序拥有 “同时监听多个流读写事件” 的机制,就被称为 I/O 多路复用!
然后我们来看 epoll 提供的三个函数:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
- epoll_create() 用于创建一个 epoll 池;
- epoll_ctl() 用来执行 fd 的 “增删改” 操作,最后一个参数 event 是告诉内核 需要监听什么事件。还是以网络请求举例, socketfd 监听的就是 可读事件,一旦接收到服务器返回的数据,监听 socketfd 的对象将会收到 回调通知,表示 socket 中有数据可以读了;
- epoll_wait() 是 使用户线程阻塞 的方法,它的第二个参数 events 接受的是一个 集合对象,如果有多个事件同时发生,events 对象可以从内核得到发生的事件的集合;
理解 Linux eventfd
理解了 epoll 我们再来看 Linux eventfd ,eventfd 是专门用来传递事件的 fd ,它提供的功能也非常简单:累计计数。
int efd = eventfd();
write(efd, 1);//写入数字1
write(efd, 2);//再写入数字2
int res = read(efd);
printf(res);//输出值为 3
通过 write() 函数,我们可以向 eventfd 中写入一个 int 类型的值,并且,只要没有发生 读 操作,eventfd 中保存的值将会一直累加。
通过 read() 函数可以将 eventfd 保存的值读了出来,并且,在没有新的值加入之前,再次调用 read() 方法会发生阻塞,直到有人重新向 eventfd 写入值。
eventfd 实现的是计数的功能,只要 eventfd 计数不为 0 ,那么表示 fd 是可读的。再结合 epoll 的特性,我们可以非常轻松的创建出 生产者/消费者模型。
epoll + eventfd 作为消费者大部分时候处于阻塞休眠状态,而一旦有请求入队(eventfd 被写入值),消费者就立刻唤醒处理,Handler 机制的底层逻辑就是利用 epoll + eventfd。
好,有了 epoll 、 eventfd 基础,接下来我们开始正式进入 Handler 机制的 Native 世界。
进入Native Handler
绝大多数 Android 工程师都或多或少的了解过 Handler 机制,所以关于 Handler 的基本使用和实现的原理我们就不过多赘述了,直奔主题。
我们来重点关注 MessageQueue 类中的几个 jni 方法:nativeInit()、nativePollOnce() 和 nativeWake();
它们分别对应了 Native 消息队列中的 初始化消息队列、 消息的循环与阻塞 以及 消息的分送与唤醒 这三大环节。
/frameworks/base/core/java/android/os/MessageQueue.java
class MessageQueue {
private native static long nativeInit();
private native void nativePollOnce(long ptr, int timeoutMillis); /*non-static for callbacks*/
private native static void nativeWake(long ptr);
}
消息队列的初始化
先来看第一步,消息队列的初始化流程:
Java MessageQueue 构造函数中会调用 nativeInit() 方法,同步在 Native 层也会创建一个消息队列 NativeMessageQueue 对象,用于保存 Native 开发者发送的消息。
/frameworks/base/core/java/android/os/MessageQueue.java
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit();
}
看代码,在 NativeMessageQueue 的构造函数中,触发创建 Looper 对象(Native 层的)
/frameworks/base/core/jni/android_os_MessageQueue.cpp
class android_os_MessageQueue {
void android_os_MessageQueue_nativeInit() {
NativeMessageQueue* nativeMessageQueue = new NativeMessageQueue();
}
NativeMessageQueue() {
mLooper = Looper::getForThread();
if (mLooper == NULL) {
mLooper = new Looper(false);
Looper::setForThread(mLooper);
}
}
}
Native 创建 Looper 对象的处理逻辑和 Java 一样:先去 线程局部存储区 获取 Looper 对象,如果为空,创建一个新的 Looper 对象并保存到 线程局部存储区。
我们继续,接着来看 Native Looper 初始化流程:
/system/core/libutils/Looper.cpp
class looper {
Looper::Looper() {
int mWakeEventFd = eventfd();
rebuildEpollLocked();
}
void rebuildEpollLocked(){
int mEpollFd = epoll_create();//哎,这儿非常重要,在 Looper 初始化时创建了 epoll 对象
epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeEventFd, & eventItem);//把用于唤醒消息队列的eventfd 添加到 epoll 池
}
}
关键的地方来了!!!
Looper 的构造函数首先创建了 eventfd 对象 :mWakeEventFd,它的作用就是用来监听 MessageQueue 是否有新消息加入,这个对象非常重要,一定要记住它!
随后调用的 rebuildEpollLocked() 方法中,又创建了 epoll 对象:mEpollFd,并将刚刚申请的 mWakeEventFd 注册到 epoll 池;
到这一步,Handler 机制最依赖的两大核心对象 mEpollFd 和 mWakeEventFd ,全部都初始化成功!
我们来梳理一下 消息队列的初始化 步骤:
- Java 层初始化消息队列时,同步调用 nativeInit() 方法,在 native 层创建了一个 NativeMessageQueue 对象;
- Native 层的消息队列被创建的同时,也会创建一个 Native Looper 对象;
- 在 Native Looper 构造函数中,调用 eventfd() 生成 mWakeEventFd,它是后续用于唤醒消息队列的核心;
- 最后调用 rebuildEpollLocked() 方法,初始化了一个 epoll 实例 mEpollFd ,然后将 mWakeEventFd 注册到 epoll 池;
至此,Native 层的消息队列初始化完成,Looper 对象持有 mEpollFd 和 mWakeEventFd 两大金刚。
消息的循环与阻塞
Java 和 Native 的消息队列都创建完以后,整个线程就会阻塞到 Looper#loop() 方法中,在 Java 层的的调用链大致是这样的:
Looper#loop()
-> MessageQueue#next()
-> MessageQueue#nativePollOnce()
}
MessageQueue 最后一步调用的 nativePollOnce() 是一个 jni 方法,具体实现在 Native 层。
我们接着往下跟,看看 Native 中做了些什么:
/frameworks/base/core/jni/android_os_MessageQueue.cpp
class android_os_MessageQueue {
//jni方法,转到 NativeMessageQueue#pollOnce()
void android_os_MessageQueue_nativePollOnce(){
nativeMessageQueue->pollOnce(env, obj, timeoutMillis);
}
class NativeMessageQueue : MessageQueue {
/转到 Looper#pollOnce() 方法
void pollOnce(){
mLooper->pollOnce(timeoutMillis);
}
}
}
nativePollOnce() 接受到请求后,随手转发到 NativeMessageQueue 的 pollOnce() 方法。
而 NativeMessageQueue#pollOnce() 中什么都没做,只是又把请求转发给了 Looper#pollOnce()。
看来主要的逻辑都在 Looper 中,我们接着往下看:
//system/core/libutils/Looper.cpp
class looper {
int pollOnce(int timeoutMillis){
int result = 0;
for (;;) {
if (result != 0) {
return result;
}
result = pollInner(timeoutMillis);//超时
}
}
int pollInner(int timeoutMillis){
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);//调用 epoll_wait() 等待事件的产生
}
}
看到了吗?线程阻塞和唤醒的执行逻辑都在这!
pollOnce() 会不停的轮询 pollInner() 方法,检查它的的返回值 result
这里的 result 类型是在 Looper.h 文件中声明的枚举类,一共有4种结果:
- -1 表示在 “超时时间到期” 之前使用 wake() 唤醒了轮询,通常是有需要立刻执行的新消息加入了队列;
- -2 表示多个事件同时发生,有可能是新消息加入,也有可能是监听的 自定义 fd 发生了 I/O 事件;
- -3 表示设定的超时时间到期了;
- -4 表示错误,不知道哪里会用到;
消息队列中没消息,或者 设定的超时时间没到期,再或者 自定义 fd 没有事件发生,都会导致线程阻塞到 pollInner() 方法调用。
pollInner() 中,则是使用了 epoll_wait() 系统调用等待事件的产生。
本小节标题是 消息的循环与阻塞 ,现在线程已经阻塞到 pollInner() ,我们可以来梳理下发生阻塞的前后逻辑:
消息队列在初始化成功以后,Java 层的 Looper#loop() 会开始无限轮询,不停的获取下一条消息。如果消息队列为空,调用 epoll_wait 使线程进入到阻塞态,让出 CPU 调度。
从 Java 到 Native 整个调用流程大致是这样的:
Looper#loop()
-> MessageQueue#next()
-> MessageQueue#nativePollOnce()
-> NativeMessageQueue#pollOnce() //注意,进入 Native 层
-> Looper#pollOnce()
-> Looper#pollInner()
-> epoll_wait()
消息的发送/唤醒机制
好,现在的消息队列里面是空的,并且经过上一小节的分析后,我们发现用户线程阻塞到了 native 层的 Looper#pollInner() 方法,我们来向消息队列发送一条消息唤醒它。
前面我们说了,Java 和 Native 都各自维护了一套消息队列,所以他们发送消息的入口也不一样
Java 开发使用 Handler#sendMessage() / post(),C/C++ 开发使用 Looper#sendMessage()。
我们先来看 Java:
/frameworks/base/core/java/android/os/Handler.java
class Handler {
boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
return queue.enqueueMessage(msg, uptimeMillis);
}
}
/frameworks/base/core/java/android/os/MessageQueue.java
class MessageQueue {
boolean enqueueMessage(Message msg, long when) {
//...按照到期时间将消息插入消息队列
if (needWake) {
nativeWake(mPtr);
}
}
}
在使用 Handler 发送消息时,不管调用的是 sendMessage 还是 post,最后都是调用到 MessageQueue#enqueueMessage() 方法将消息入列,入列的顺序是按照执行时间先后排序。
如果我们发送的消息需要马上被执行,那么将 needWake 变量置为 true,接着使用 nativeWake() 唤醒线程。
注:nativeWake() 方法也是 jni 调用,经过层层转发最终调用到 Native Looper 中的 wake() 方法,整个转发过程的调用链清晰而且非常简单,这里就不展开分析了。
Java 发送消息的方式聊完了,然后我们看 Native 层如何发送消息:
/system/core/libutils/Looper.cpp
class looper {
void Looper::sendMessageAtTime(uptime, handler,message) {
int i = 0;
int messageCount = mMessageEnvelopes.size();
while (i < messageCount && uptime >= mMessageEnvelopes.itemAt(i).uptime) {
i += 1;
}
mMessageEnvelopes.insertAt(messageEnvelope(uptime, handler, message), i, 1);
// Wake the poll loop only when we enqueue a new message at the head.
if (i == 0) {
wake();
}
}
}
看上面的代码,Native 层通过 sendMessageAtTime() 方法向消息队列发送消息,添加消息的处理逻辑和 Java 处理逻辑类似:
按照时间的先后顺序添加到 mMessageEnvelopes 集合中,执行时间离得最近的消息被放在前面,如果发现需要唤醒线程,则调用 wake() 方法。
好,Java 和 Native 发送消息的方式都介绍完了。
我们发现,虽然它俩 发消息的方式 、消息类型 、 送达的消息队列 都不相同,但是,当需要唤醒线程时,Java 和 Native 都会执行到 Looper#wake() 方法。
之前我们说 “Handler 机制的底层是 epoll + eventfd”,读者朋友不妨大胆猜一下,这里的线程是怎么被唤醒的?
/system/core/libutils/Looper.cpp
class looper {
void Looper::wake() {
int inc = 1;
write(mWakeEventFd, &inc);
}
}
答案非常简单,write() 一行方法调用,向 mWakeEventFd 写入了一个 1(小提示:mWakeEventFd 的类型是 eventfd )。
为什么 mWakeEventFd 写入了一个 1,线程就可以被唤醒呢???
mWakeEventFd 被写入值后,状态会从 不可读 变成 可读,内核监听到 fd 的可读写状态发生变化,会将事件从内核返回给 epoll_wait() 方法调用;
而 epoll_wait() 方法一旦返回,阻塞态将会被取消,线程继续向下执行。
好,我们来总结一下 消息的发送与唤醒 中几个关键的步骤:
- Java 层发送消息,调用 MessageQueue#enqueueMessage() 方法,如果消息需要马上执行,那么调用 nativeWake() 执行唤醒;
- Native 层发送消息,调用 Looper#sentMessageAtTime() 方法,处理逻辑与 Java 类似,如果需要唤醒线程,调用 Looper#wake();
- Looper#wake() 唤醒方法很简单,向 mWakeEventFd 写入 1;
- 初始化队列 时为 mWakeEventFd 注册了 epoll 监听,所以一旦有来自于 mWakeEventFd 的新内容, epoll_wait() 阻塞调用就会返回,这里就已经起到了唤醒队列的作用;
呼~ 到这里 消息的发送与唤醒 的流程基本上结束了,接下来是 Handler 的重头戏:线程唤醒后的消息分发处理:
唤醒后消息的分发处理
线程在没有消息需要处理时会阻塞在 Looper 中的 pollInner() 方法调用,线程唤醒以后同样也是在 pollInner() 方法中继续执行。
线程醒来以后,先判断自己为什么醒过来,再根据唤醒类型执行不同的逻辑。
pollInner() 方法稍微有点长,大致可以分为5步来看,我们一点点来捋:
/system/core/libutils/Looper.cpp
class looper {
int pollInner(int timeoutMillis){
int result = POLL_WAKE;
// step 1,epoll_wait 方法返回
int eventCount = epoll_wait(mEpollFd, eventItems, timeoutMillis);
if (eventCount == 0) { // 事件数量为0表示,达到设定的超时时间
result = POLL_TIMEOUT;
}
for (int i = 0; i < eventCount; i++) {
if (eventItems[i] == mWakeEventFd) {
// step 2 ,清空 eventfd,使之重新变为可读监听的 fd
awoken();
} else {
// step 3 ,保存自定义fd触发的事件集合
mResponses.push(eventItems[i]);
}
}
// step 4 ,执行 native 消息分发
while (mMessageEnvelopes.size() != 0) {
if (messageEnvelope.uptime <= now) { // 检查消息是否到期
messageEnvelope.handler->handleMessage(message);
}
}
// step 5 ,执行 自定义 fd 回调
for (size_t i = 0; i < mResponses.size(); i++) {
response.request.callback->handleEvent(fd, events, data);
}
return result;
}
void awoken() {
read(mWakeEventFd) ;// 重新变成可读事件
}
}
step 1 : epoll_wait 方法返回说明有事件发生,返回值 eventCount 是发生事件的数量。如果为0,表示达到设定的超时时间,下面的判断逻辑都不会走,不为0,那么我们开始遍历内核返回的事件集合 eventItems,根据类型执行不同的逻辑。
step 2 : 如果事件类型是消息队列的 eventfd ,说明有人向消息队列提交了需要马上执行的消息,我们只需把消息队列的 eventfd 数据读出来,使他重新变成可以触发 可读事件 的 fd,然后等待方法结束就行了。
step 3 : 事件不是消息队列的 eventfd ,说明有其他地方注册了监听 fd,那么,我们将发生的事件保存到 mResponses 集合中,待会需要对这个事件做出响应,通知注册对象。
step 4 : 遍历 Native 的消息集合 mMessageEnvelopes,检查每个消息的到期时间,如果消息到期了,交给 handler 执行分发,分发逻辑参考 Java Handler。
step 5 : 遍历 mResponses 集合,把其他地方注册的 自定义 fd 消费掉,响应它们的回调方法。
唤醒后执行的逻辑还是非常复杂的,我们总结一下:
用户线程被唤醒后,优先分发 Native 层的消息,紧接着,通知 自定义 fd 发生的事件(如果有的话),最后 pollInner() 方法结束,返回到 Java 层 Looper#loop() 方法执行到 Java 层的消息分发。只有当 Java Handler 执行完消息分发,一次 loop() 循环才算是完成。
再之后,因为 Looper#loop() 是死循环,所以会马上再一次进入循环,继续调用 next() 方法获取消息、阻塞到 pollInner() 、从 pollInner() 唤醒执行分发,执行结束接着进入下一次循环,无尽的轮回。
main 线程的一生都将重复这一流程,直到 APP 进程结束运行...
总结
以上就是 Handler Native 篇的全部内容,主要介绍了 Java MessageQueue 中几个关键的 jni 方法在底层是如何实现的。
将全部的代码逻辑分析完以后,我们会发现 Native Handler 的实现不算复杂,关键的阻塞与唤醒部分是借助了 Linux 系统 epoll 机制来实现的。
所以,我们只要理解了 epoll 机制,再对照源码看看 Looper#pollInner() 中的内部逻辑,就能明白整个 Handler 机制是怎么一回事了。
希望对大家有帮助。