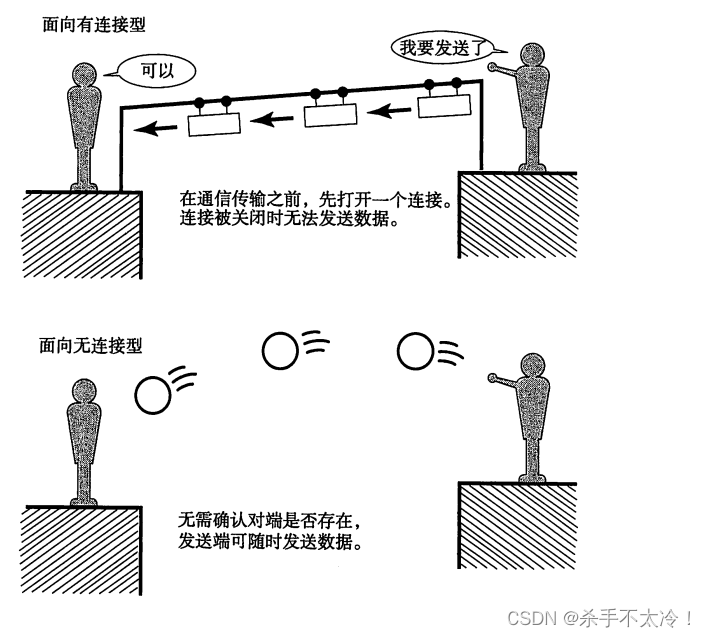
#项目说明:
说明:1time_steps=
滚动预测代码
y_norm = scaler.fit_transform(y.reshape(-1, 1))
y_norm = torch.FloatTensor(y_norm).view(-1)
# 重新预测
window_size = 12
future = 12
L = len(y)
首先对模型进行训练;
然后选择所有数据的后window_size个数据,通过训练,每次通过前window_size个数据预测未来一个数据,之后新预测的一个数据append加到preds中,这样经过循环future次后,通过滚动循环的方式,预测未来future=12天的数据,完成滚动预测。
最后通过可视化查看预测结果。
preds = y_norm[-window_size:].tolist()
model.eval()
for i in range(future):
seq = torch.FloatTensor(preds[-window_size:])
with torch.no_grad():
model.hidden = (torch.zeros(1,1,model.hidden_size),
torch.zeros(1,1,model.hidden_size))
preds.append(model(seq).item())
true_predictions = scaler.inverse_transform(np.array(preds).reshape(-1, 1))
x = np.arange('2019-02-01', '2020-02-01', dtype='datetime64[M]').astype('datetime64[D]')
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.plot(x,true_predictions[window_size:])
plt.show()
完整代码解读:
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# 导入酒精销售数据
df = pd.read_csv('data\Alcohol_Sales.csv',index_col=0,parse_dates=True)
len(df)
df.head() # 观察数据集,这是一个单变量时间序列
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.show()
y = df['S4248SM144NCEN'].values.astype(float)
# print(len(y)) #325条数据
test_size = 12
# 划分训练和测试集,最后12个值作为测试集
train_set = y[:-test_size] #323条数据
test_set = y[-test_size:] #12条数据
# print(train_set.shape) #(313,) 一位数组
# 归一化至[-1,1]区间,为了获得更好的训练效果
scaler = MinMaxScaler(feature_range=(-1, 1))
#scaler.fit_transform输入必须是二维的,但是train_set却是一个一维,所有实验reshape(-1,1)
train_norm = scaler.fit_transform(train_set.reshape(-1, 1)) #np.reshape(-1, 1) 列=1,行未知
# print(train_norm.shape) #(313, 1) 这里将一维数据转化为二维
# 转换成 tensor
train_norm = torch.FloatTensor(train_norm).view(-1)
print(train_norm.shape) #torch.Size([313])
# 定义时间窗口,注意和前面的test size不是一个概念
window_size = 12
# 这个函数的目的是为了从原时间序列中抽取出训练样本,也就是用第一个值到第十二个值作为X输入,预测第十三个值作为y输出,这是一个用于训练的数据点,时间窗口向后滑动以此类推
def input_data(seq,ws):
out = []
L = len(seq)
for i in range(L-ws):
window = seq[i:i+ws]
label = seq[i+ws:i+ws+1]
out.append((window,label)) #将x和y以tensor格式放入到out列表当中,
return out
train_data = input_data(train_norm,window_size)
len(train_data) # 等于325(原始数据集长度)-12(测试集长度)-12(时间窗口)
class LSTMnetwork(nn.Module):
def __init__(self,input_size=1,hidden_size=100,output_size=1):
super().__init__()
self.hidden_size = hidden_size
# 定义LSTM层
self.lstm = nn.LSTM(input_size,hidden_size)
# 定义全连接层
self.linear = nn.Linear(hidden_size,output_size)
# 初始化h0,c0
self.hidden = (torch.zeros(1,1,self.hidden_size),
torch.zeros(1,1,self.hidden_size))
def forward(self,seq):
# 前向传播的过程是输入->LSTM层->全连接层->输出
# https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html?highlight=lstm#torch.nn.LSTM
# 在观察查看LSTM输入的维度,LSTM的第一个输入input_size维度是(L, N, H_in), L是序列长度,N是batch size,H_in是输入尺寸,也就是变量个数
# LSTM的第二个输入是一个元组,包含了h0,c0两个元素,这两个元素的维度都是(D∗num_layers,N,H_out),D=1表示单向网络,num_layers表示多少个LSTM层叠加,N是batch size,H_out表示隐层神经元个数
'''
pytorch中LSTM输入为[time_step,batch,feature],这里窗口time_step=12,feature=1[1维数据],batch我们这里设置为1
所以使用seq.view(len(seq),1,-1)将tensor[12]数据转化为tensor[12,1,1]
'''
lstm_out, self.hidden = self.lstm(seq.view(len(seq),1,-1), self.hidden)
# print(lstm_out) #torch.Size([12, 1, 100]) [time_step,batch,hidden]
# print(lstm_out.view(len(seq),-1)) #[12,100]
pred = self.linear(lstm_out.view(len(seq),-1))
# print(pred) #torch.Size([12, 1])
return pred[-1] # 输出只用取最后一个值
torch.manual_seed(101)
model = LSTMnetwork()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
epochs = 100
start_time = time.time()
for epoch in range(epochs):
for seq, y_train in train_data:
# 每次更新参数前都梯度归零和初始化
optimizer.zero_grad()
model.hidden = (torch.zeros(1,1,model.hidden_size),
torch.zeros(1,1,model.hidden_size))
y_pred = model(seq)
loss = criterion(y_pred, y_train)
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1:2} Loss: {loss.item():10.8f}')
print(f'\nDuration: {time.time() - start_time:.0f} seconds')
future = 12
# 选取序列最后12个值开始预测
preds = train_norm[-window_size:].tolist()
# 设置成eval模式
model.eval()
# 循环的每一步表示向时间序列向后滑动一格
for i in range(future):
seq = torch.FloatTensor(preds[-window_size:]) #第下一次循环的时候,seq总是能取到后12个数据,因此及时后面用pred.append()也还是每次用到最新的预测数据完成下一次的预测。
with torch.no_grad():
model.hidden = (torch.zeros(1,1,model.hidden_size),
torch.zeros(1,1,model.hidden_size))
"""
item理解:取出张量具体位置的元素元素值,并且返回的是该位置元素值的高精度值,保持原元素类型不变;必须指定位置
即:原张量元素为整形,则返回整形,原张量元素为浮点型则返回浮点型,etc.
"""
# print(model(seq),model(seq).item()) #tensor([0.1027]), tensor([0.1026])
preds.append(model(seq).item()) #每循环一次,这里会将新的预测值添加到pred中,
# 逆归一化还原真实值
true_predictions = scaler.inverse_transform(np.array(preds[window_size:]).reshape(-1, 1))
# 对比真实值和预测值
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
x = np.arange('2018-02-01', '2019-02-01', dtype='datetime64[M]').astype('datetime64[D]')
plt.plot(x,true_predictions)
plt.show()
# 放大看
fig = plt.figure(figsize=(12,4))
plt.grid(True)
fig.autofmt_xdate()
plt.plot(df['S4248SM144NCEN']['2017-01-01':])
plt.plot(x,true_predictions)
plt.show()
# 重新开始训练
epochs = 100
# 切回到训练模式
model.train()
y_norm = scaler.fit_transform(y.reshape(-1, 1))
y_norm = torch.FloatTensor(y_norm).view(-1)
all_data = input_data(y_norm,window_size)
start_time = time.time()
for epoch in range(epochs):
for seq, y_train in all_data:
optimizer.zero_grad()
model.hidden = (torch.zeros(1,1,model.hidden_size),
torch.zeros(1,1,model.hidden_size))
y_pred = model(seq)
loss = criterion(y_pred, y_train)
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1:2} Loss: {loss.item():10.8f}')
print(f'\nDuration: {time.time() - start_time:.0f} seconds')
# 重新预测
window_size = 12
future = 12
L = len(y)
preds = y_norm[-window_size:].tolist()
model.eval()
for i in range(future):
seq = torch.FloatTensor(preds[-window_size:])
with torch.no_grad():
model.hidden = (torch.zeros(1,1,model.hidden_size),
torch.zeros(1,1,model.hidden_size))
preds.append(model(seq).item())
true_predictions = scaler.inverse_transform(np.array(preds).reshape(-1, 1))
x = np.arange('2019-02-01', '2020-02-01', dtype='datetime64[M]').astype('datetime64[D]')
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.plot(x,true_predictions[window_size:])
plt.show()
代码说明:代码中包含了训练、测试和预测。但没有对该模型进行评估。