本文介绍
这篇文章主要给大家讲解如何在多个位置替换可变形卷积,它有三个版本分别是DCNv1、DCNv2、DCNv3,在本篇博文中会分别进行介绍同时进行对比,通过本文你可以学会在YOLOv8中各个位置添加可变形卷积包括(DCNv1、DCNv2、DCNv3),可替换的位置包括->替换C2f中的卷积、DarknetBottleneck中的卷积、主干网络(Backbone)中的卷积等多个位置,本文通过实战的角度进行分析,利用二分类数据集检测飞机为案例,训练结果,通过分析mAP、Loss、Recall等评估指标评估变形卷积的效果,在讲解的过程中有一部分知识点内容来自于论文,也有一部分是我个人的总结内容。
适用对象->适合魔改YOLOv8尝试多位置修改发表论文的用户
适用检测目标->各种类型的目标检测对象
概念介绍
首先我们先来介绍一个大的概念DCN全称为Deformable Convolutional Networks,翻译过来就是可变形卷积的意思,其是一种用于目标检测和图像分割的卷积神经网络模块,通过引入可变形卷积操作来提升模型对目标形变的建模能力。
什么是可变形卷积?我们看下图来看一下就了解了。

上图中展示了标准卷积和可变形卷积中的采样位置。在标准卷积(a)中,采样位置按照规则的网格形式排列(绿色点)。这意味着卷积核在进行卷积操作时,会在输入特征图的规则网格位置上进行采样。
而在可变形卷积(b)中,采样位置是通过引入偏移量进行变形的(深蓝色点),并用增强的偏移量(浅蓝色箭头)进行表示。这意味着在可变形卷积中,不再局限于规则的网格位置,而是可以根据需要在输入特征图上自由地进行采样。
通过引入可变形卷积,可以推广各种变换,例如尺度变换、(异向)长宽比和旋转等变换,这在(c)和(d)中进行了特殊情况的展示。这说明可变形卷积能够更灵活地适应不同类型的变换,从而增强了模型对目标形变的建模能力。
总之,标准卷积(规则采样)在进行卷积操作时按照规则网格位置进行采样,而可变形卷积通过引入偏移量来实现非规则采样,从而在形状变换(尺度、长宽比、旋转等)方面具有更强的泛化能力。
下面是一个三维的角度来分析大家应该会看的更直观。
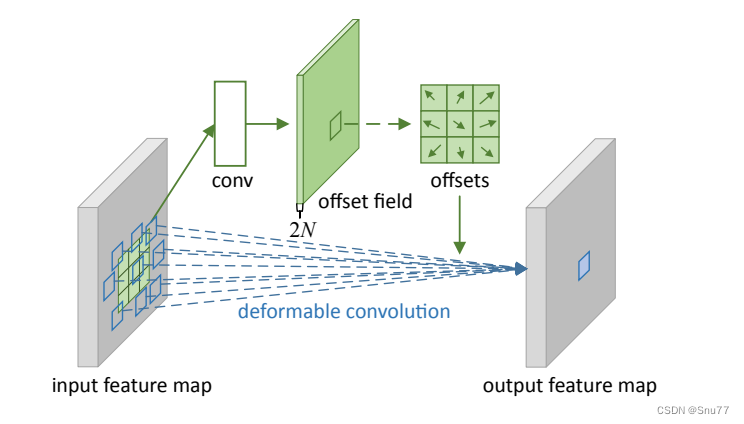
其中左侧的是输入特征,右侧的是输出特征,我们的卷积核大小是一个3x3的,我们将输入特征中3x3区域映射为输出特征中的1x1,问题就在于这个3x3的区域怎么选择,传统的卷积就是规则的形状,可变形卷积就是在其中加入一个偏移量,然后对于个每个点分别计算,然后改变3x3区域中每个点的选取,提取一些可能具有更丰富特征的点,从而提高检测效果。
下面我们来看一下在实际检测效果中,可变形卷积的效果,下面的图片分别为大物体、中物体、小物体检测,其中红色的部分就是我们提取出来的特征。

图中的每个图像三元组展示了三个级别的3×3可变形滤波器的采样位置(每个图像中有729个红色点),以及分别位于背景(左侧)、小物体(中间)和大物体(右侧)上的三个激活单元(绿色点)。
这个图示的目的是说明在不同的物体尺度上,可变形卷积中的采样位置如何变化。在左侧的背景图像中,可变形滤波器的采样位置主要集中在图像的背景部分。在中间的小物体图像中,采样位置的焦点开始向小物体的位置移动,并在小物体周围形成更密集的采样点。在右侧的大物体图像中,采样位置进一步扩展并覆盖整个大物体,以更好地捕捉其细节和形变。
通过这些图示,我们可以观察到可变形卷积的采样位置可以根据不同的目标尺度自适应地调整,从而在不同尺度的物体上更准确地捕捉特征。这增强了模型对于不同尺度目标的感知能力,并使其更适用于不同尺度物体的检测任务,这也是为什么开头的地方我说了本文适合于各种目标的检测对象。
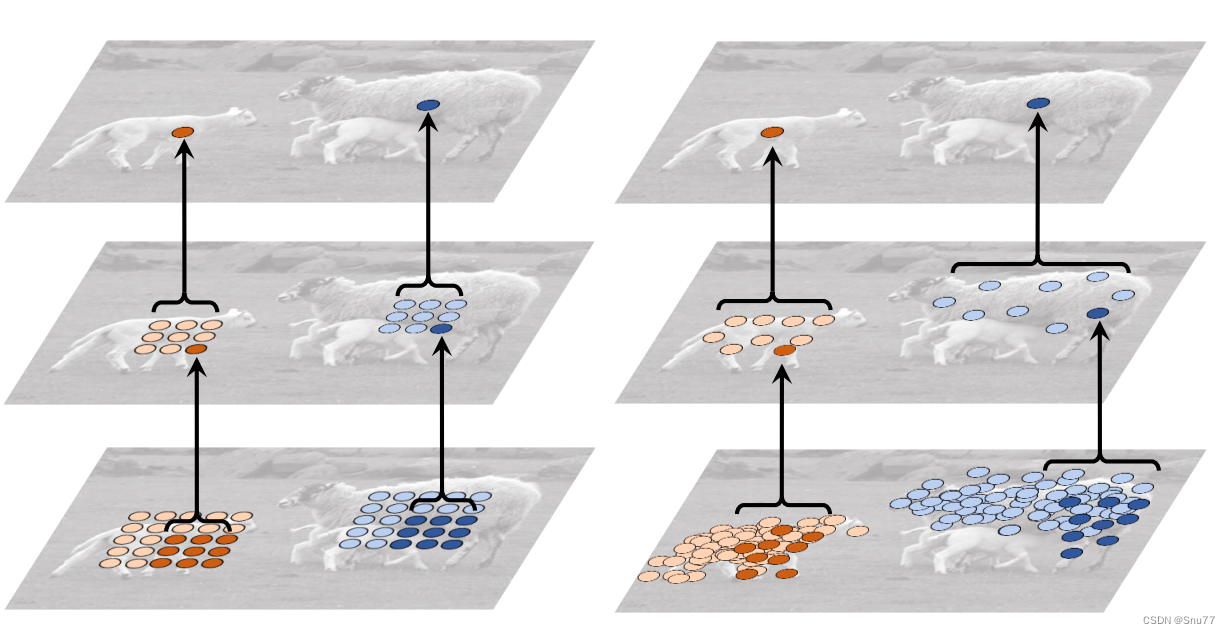
上图可能可能更加直观一些。
可变形卷积系列实战讲解
DCNv1
论文地址->DCNv1论文地址
代码地址->DCNv1代码地址
PS:如何使用请看DCNv3部分一起讲解
DCNv1(Deformable Convolutional Networks v1):DCNv1最早出现于2017年,也是DCN系列的首次提出,之后的v2、v3都是在其基础上进行了改进。它通过在传统卷积操作中引入偏移场(offset field)和可变形卷积操作来捕捉目标的局部形变。偏移场是由附加的学习参数生成的,并通过在输入特征图上进行采样来实现可变形卷积。
DCNv1的使用方法
DCNv1的使用和DCNv3一样只不过他的代码文件在"medvision/ops/deform_conv_2d.py"这个目录下,其他的方法流程和DCNv3一样或者和DCNv2一样,因为大家估计都是看DCNv2或者v3,这里不再重复讲解了,使用方法都一样。
DCNv2
论文地址->DCNv2论文地址
代码地址->代码在下面直接复制即可
DCNv2(Deformable Convolutional Networks v2):DCNv2于2018年提出,对原始的DCNv1进行了改进。DCNv2提出了一个新的可变形卷积操作,其中引入了可变形RoI池化层(感觉就多了这么一个池化层),用于对目标区域进行精确的兴趣区域池化操作。这种操作能够更准确地捕获目标的形变信息,进一步提升了模型性能。
DCNv2代码
class DCNv2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=1, dilation=1, groups=1, deformable_groups=1):
super(DCNv2, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = (kernel_size, kernel_size)
self.stride = (stride, stride)
self.padding = (padding, padding)
self.dilation = (dilation, dilation)
self.groups = groups
self.deformable_groups = deformable_groups
self.weight = nn.Parameter(
torch.empty(out_channels, in_channels, *self.kernel_size)
)
self.bias = nn.Parameter(torch.empty(out_channels))
out_channels_offset_mask = (self.deformable_groups * 3 *
self.kernel_size[0] * self.kernel_size[1])
self.conv_offset_mask = nn.Conv2d(
self.in_channels,
out_channels_offset_mask,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = Conv.default_act
self.reset_parameters()
def forward(self, x):
offset_mask = self.conv_offset_mask(x)
o1, o2, mask = torch.chunk(offset_mask, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
x = torch.ops.torchvision.deform_conv2d(
x,
self.weight,
offset,
mask,
self.bias,
self.stride[0], self.stride[1],
self.padding[0], self.padding[1],
self.dilation[0], self.dilation[1],
self.groups,
self.deformable_groups,
True
)
x = self.bn(x)
x = self.act(x)
return x
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
std = 1. / math.sqrt(n)
self.weight.data.uniform_(-std, std)
self.bias.data.zero_()
self.conv_offset_mask.weight.data.zero_()
self.conv_offset_mask.bias.data.zero_()
修改DCNv2的C2f模块和Bottleneck模块的代码如下!
class Bottleneck_DCN(nn.Module):
# Standard bottleneck with DCN
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = DCNv2(c_, c2, k[1], 1, groups=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_DCN(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_DCN(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))DCNv2的使用方法
我们将以上代码复制粘贴到"ultralytics/nn/modules/conv.py"目录下然后修改头文件,如下
然后找到"ultralytics/nn/modules/__init__.py" 文件,修改如下
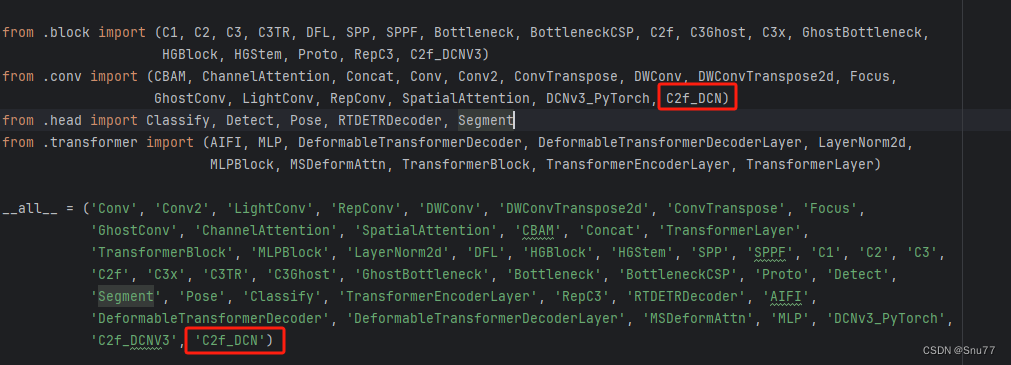
然后找到"ultralytics/nn/tasks.py"文件,修改如下
 然后在同文件下,找到方法parse_model然后对该方法的代码进行如下修改
然后在同文件下,找到方法parse_model然后对该方法的代码进行如下修改
 然后我们就可以在yaml文件中进行配置了,
然后我们就可以在yaml文件中进行配置了,
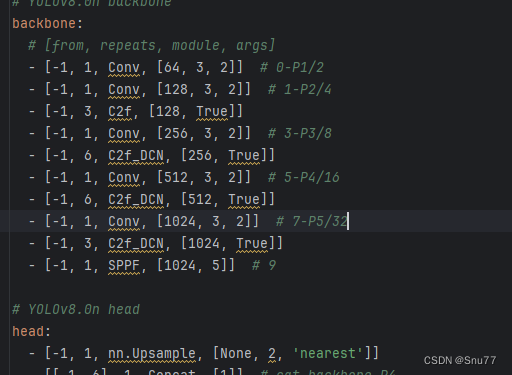
然后训练控制台就会输出你修改的网络结构。
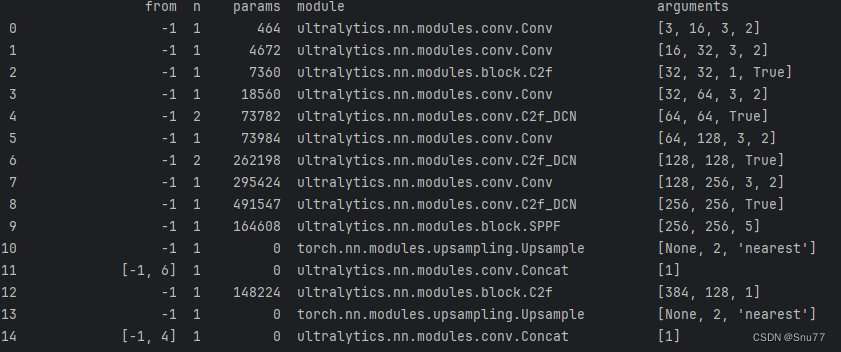
DCNv3
DCNv3(Deformable Convolutional Networks v3):DCNv3是在DCNv2的基础上于2020年提出的。DCNv3进一步改进了可变形卷积操作,引入了可变形RoI对齐层,用于更好地对准目标的特征。这种对齐操作能够更好地保持目标特征的空间对齐性,进而提升了模型的性能和准确性。
论文地址->目前还没找到
Github代码地址->官方DCNv3下载地址点击跳转Github下载
DCNv3的代码我们需要去到官方下载,在GIthub的下载方式中我们下载其中classification/ops_dcnv3文件夹即可
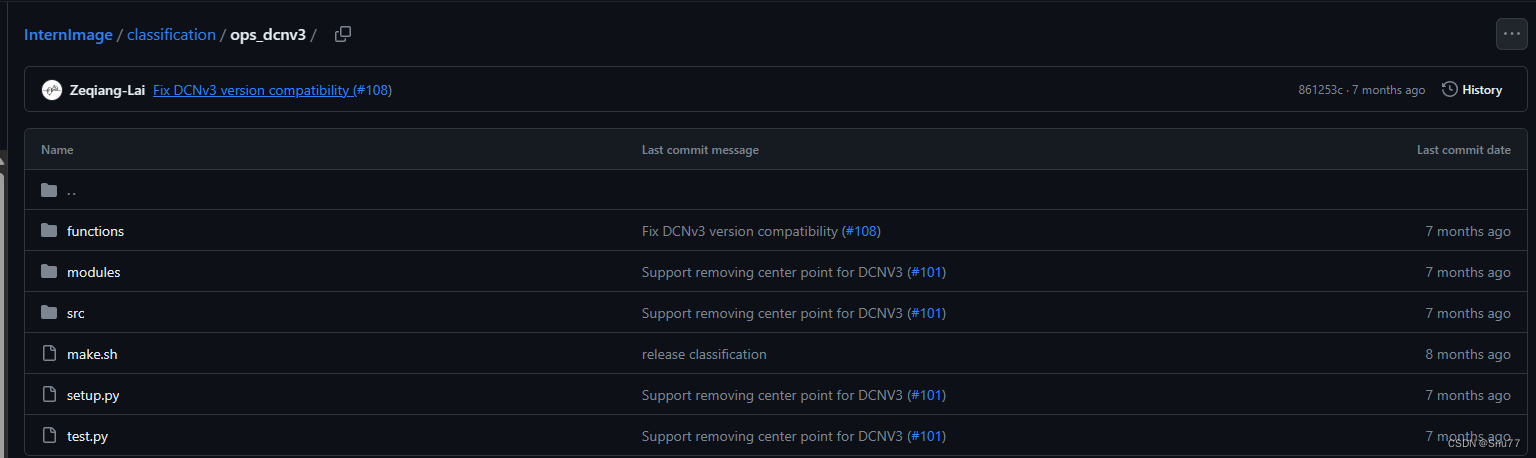
下载完成之后的ops_dcnv3将其放在ultralytics/的目录下面,
结构如下->
DCNv3的使用方法
PS:这里有两个版本一个是C++版本(运行速度更快),另一个是Pytorch版本。
Pytorch版本
我们找到该目录"ultralytics/nn/modules/conv.py"在文件开始的模块导入地方输入
from ultralytics.ops_dcnv3.modules.dcnv3 import DCNv3_pytorch # pytorch版将模块进行导入,然后我们将pytorch版本在conv.py文件中定义一个类进行一个简单的处理因为,我们的DCNv3刚拿过来是不能够直接添加到模型的,其中有些通道数不太一样。我们文件的末尾添加如下代码,这里只是提供了一个简单通用的实现版本大家如果有想法可以自己修改试试。
class DCNv3_PyTorch(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, groups=1, dilation=1):
super().__init__()
self.conv = Conv(in_channels, out_channels, k=1)
self.dcnv3 = DCNv3_pytorch(out_channels, kernel_size=kernel_size, stride=stride, group=groups,
dilation=dilation)
self.bn = nn.BatchNorm2d(out_channels)
self.gelu = nn.GELU()
def forward(self, x):
x = self.conv(x)
x = x.permute(0, 2, 3, 1)
x = self.dcnv3(x)
x = x.permute(0, 3, 1, 2)
x = self.gelu(self.bn(x))
return x
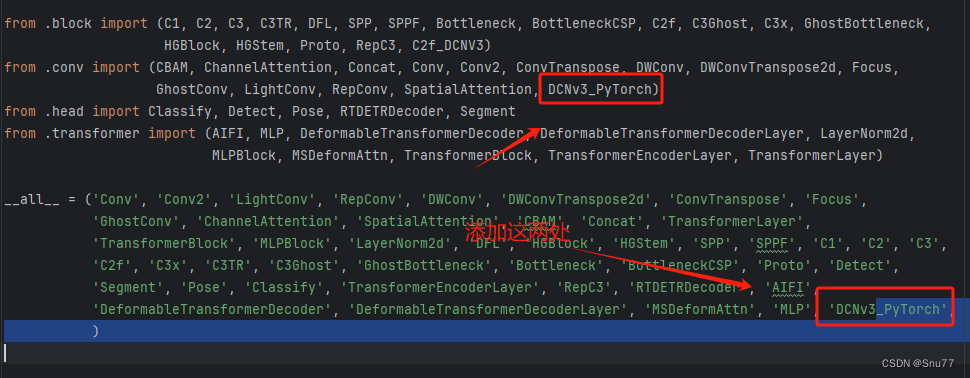
我们定义了上面的类之后,我们需要让其能够被我们的模型识别到,我们在同文件的函数头地方添加我们定义的类名。

之后我们找到该文件"ultralytics/nn/modules/__init__.py" 如下修改。
之后我们找到"ultralytics/nn/modules/block.py"文件,我们先导入定义的类,然后将其添加到C2f和Bottleneck模块中。
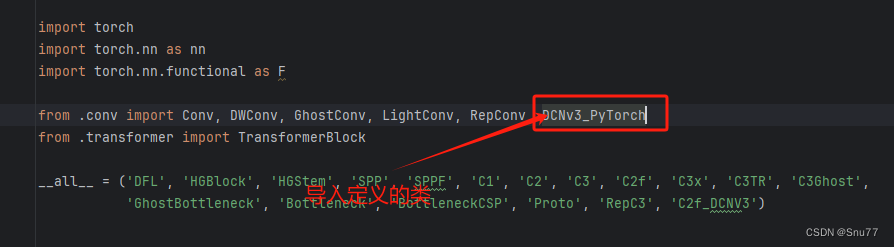
之后我们在文件的末尾添加如下代码
class Bottleneck_DCNV3(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = DCNv3_PyTorch(c_, c2, k[1], 1, groups=g)
self.add = shortcut and c1 == c2
def forward(self, x):
print('输入:', self.cv1(x).shape)
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_DCNV3(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_DCNV3(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))然后同样在文件头部位置将我们定义的类名输入进去 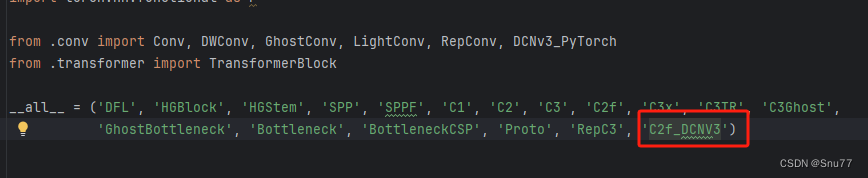 然后回到"ultralytics/nn/modules/__init__.py"文件, 添加如下
然后回到"ultralytics/nn/modules/__init__.py"文件, 添加如下
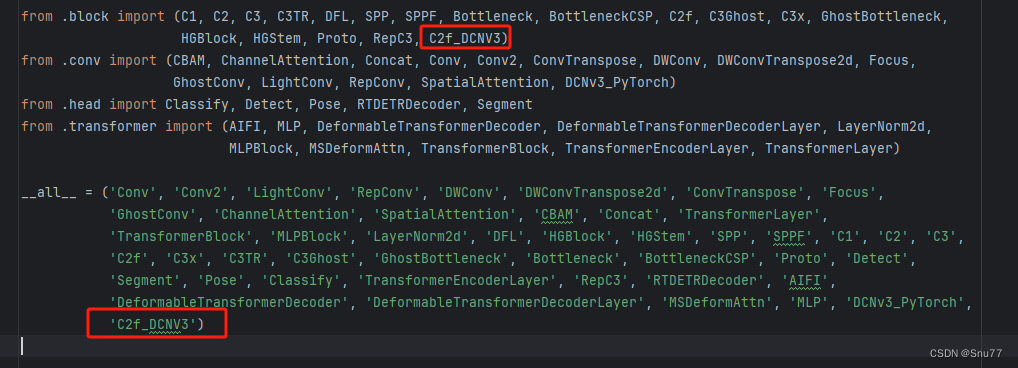
然后我们找到该文件"ultralytics/nn/tasks.py" 导入如下两个模块,我们定义的Conv模块和C2f模块。
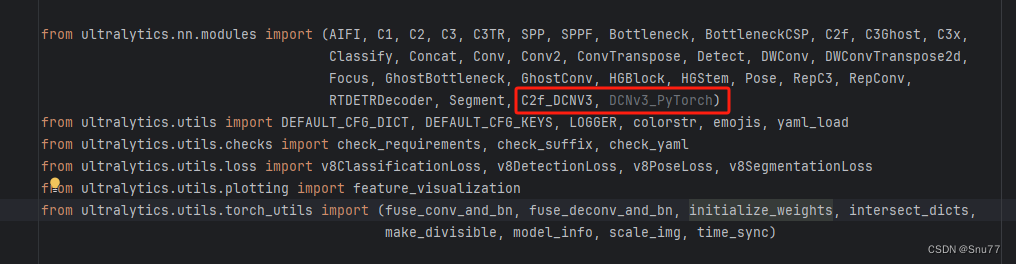
在这个文件我们找到parse_model这个方法其下面进行如下修改
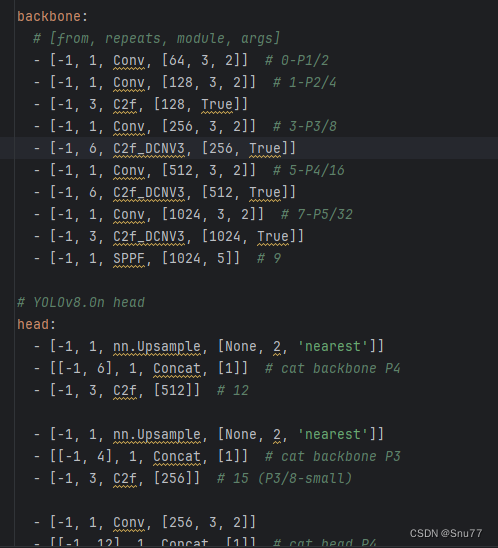
 到此我们就将DCNv3和C2f_DCNv3添加到了我们的模型中,同理其实修改过程很简单,大家可以自行尝试修改其他的模块类似于检测头中的卷积模块都可以进行替换魔改,到此我们就可以在yaml文件中配置我们的新模块了。我们修改yaml的配置文件如下
到此我们就将DCNv3和C2f_DCNv3添加到了我们的模型中,同理其实修改过程很简单,大家可以自行尝试修改其他的模块类似于检测头中的卷积模块都可以进行替换魔改,到此我们就可以在yaml文件中配置我们的新模块了。我们修改yaml的配置文件如下
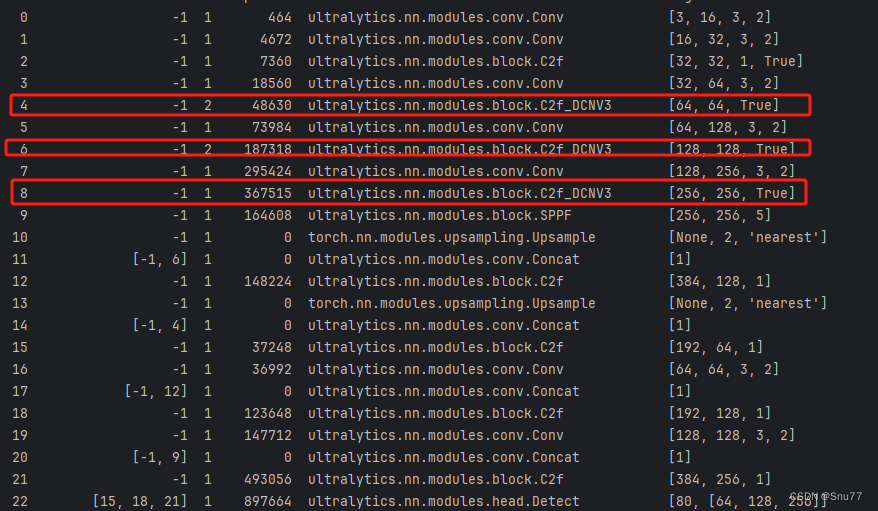
然后我们开始训练,控制台打印我们的网络结构如下->
C++版本
因为Windows版本编译很麻烦,此处暂时先不更新,后期单独出一期讲解。
可添加位置
其实我们将模块导入进去可以添加的地方有很多,上面的讲解都是以修改C2f为例子,其实我们可以将可变形卷积放在类似于解耦头的卷积部分,或者主干网络中的卷积部分都可以替换,只要保证输入和输出一致即可,当然修改太多反而会降低精度,一般对于修改Backbone、Neck、Head三部分其实都分别修改一处即可,修改太多反而会降低精度。
其它YOLOv8的文章推荐
YOLOv8改进有效涨点系列->适合多种检测场景的BiFormer注意力机制(Bi-level Routing Attention)
YOLOv8改进有效涨点系列->手把手教你添加动态蛇形卷积(Dynamic Snake Convolution)
详解YOLOv8网络结构/环境搭建/数据集获取/训练/推理/验证/导出/部署
YOLOv8性能评估指标->mAP、Precision、Recall、FPS、IoU
利用恒源云在云端租用GPU服务器训练YOLOv8模型(包括Linux系统命令讲解)