文章目录
- 前言
- DDPG特点
- 随机策略与确定性策略
- DDPG:深度确定性策略梯度
- 伪代码
- 代码实践
前言
之前的章节介绍了基于策略梯度的算法 REINFORCE、Actor-Critic 以及两个改进算法——TRPO 和 PPO。这类算法有一个共同的特点:它们都是在线策略算法,这意味着它们的样本效率(sample efficiency)比较低。本章将要介绍的深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法通过使用离线的数据以及Belllman等式去学习 Q Q Q函数,并利用 Q Q Q函数去学习策略。
DDPG特点
- DDPG是离线学习算法
- DDPG可以在连续的动作空间中进行使用
- Open AI Spinning Up 中的DDPG未实现并行运行
随机策略与确定性策略
首先来回顾一下随机策略与确定性策略相关内容
随机策略
- 离散动作: π ( a ∣ s ; θ ) = exp { Q θ ( s , a ) } ∑ a , exp { Q θ ( s , a ′ ) } \pi(a|s;\theta)=\frac{\exp\{Q_\theta(s,a)\}}{\sum_a,\exp\{Q_\theta(s,a^{\prime})\}} π(a∣s;θ)=∑a,exp{Qθ(s,a′)}exp{Qθ(s,a)},学习出价值函数之后再求取相应的softmax分布
- 连续动作: π ( a ∣ s ; θ ) ∝ exp { ( a − μ θ ( s ) ) 2 } \pi(a|s;\theta)\propto\exp\left\{\left(a-\mu_\theta(s)\right)^2\right\} π(a∣s;θ)∝exp{(a−μθ(s))2},学习出的策略符合高斯分布(均值,方差)
确定性策略
- 离散动作: π ( s ; θ ) = arg max a Q θ ( s , a ) \pi(s;\theta)=\arg\max_aQ_\theta(s,a) π(s;θ)=argmaxaQθ(s,a)策略不可微,但可以通过学习价值函数再求取argmax的方式得到相应的策略
- 连续动作: a = π ( s ; θ ) a=\pi(s;\theta) a=π(s;θ)策略可微,建立相应的函数映射,通过函数求导的方式进行策略学习
那么如何利用确定性策略学习连续动作呢?首先需要一个用于估计价值的Critic模块。 Q w ( s , a ) ≃ Q π ( s , a ) Q^w(s,a)\simeq Q^\pi(s,a) Qw(s,a)≃Qπ(s,a) L ( w ) = E s ∼ ρ π , a ∼ π θ [ ( Q w ( s , a ) − Q π ( s , a ) ) 2 ] L(w)=\mathbb{E}_{s\sim\rho^\pi,a\sim\pi_\theta}\left[\left(Q^w(s,a)-Q^\pi(s,a)\right)^2\right] L(w)=Es∼ρπ,a∼πθ[(Qw(s,a)−Qπ(s,a))2]
通过与环境的交互,可以获得状态的总体分布,又因为
a
=
π
(
s
;
θ
)
a=\pi(s;\theta)
a=π(s;θ),因此可以利用链式法则进行求导。首先是
Q
Q
Q函数对
a
a
a进行求导(
Q
Q
Q函数通常由网络学习出来,对
a
a
a向量进行求导相当于是调整相应的梯度以使得获得更大的
Q
Q
Q值),接着因为
a
=
π
(
s
;
θ
)
a=\pi(s;\theta)
a=π(s;θ),所以
a
a
a对
π
\pi
π进行求导。
J
(
π
θ
)
=
E
s
∼
ρ
π
[
Q
π
(
s
,
a
)
]
J(\pi_\theta)=\mathbb{E}_{s\sim\rho^\pi}[Q^\pi(s,a)]
J(πθ)=Es∼ρπ[Qπ(s,a)]
∇
θ
J
(
π
θ
)
=
E
s
∼
ρ
π
[
∇
θ
π
θ
(
s
)
∇
a
Q
π
(
s
,
a
)
∣
a
=
π
θ
(
s
)
]
\nabla_\theta J(\pi_\theta)=\mathbb{E}_{s\sim\rho^\pi}[\nabla_\theta\pi_\theta(s)\nabla_aQ^\pi(s,a)|_{a=\pi_\theta(s)}]
∇θJ(πθ)=Es∼ρπ[∇θπθ(s)∇aQπ(s,a)∣a=πθ(s)]
上式即为确定性策略梯度定理。确定性策略梯度定理的具体证明过程可参考《动手学强化学习》13.5 节。
DDPG:深度确定性策略梯度
在实际应用中,上述的带有神经函数近似器的actor-critic方法在面对有
挑战性的问题时是不稳定的。深度确定性策略梯度(DDPG)给出了在确定性策略梯度(DPG)基础上的解决方法:
• 经验重放(离线策略)
• 目标网络
• 在动作输入前标准化Q网络
• 添加连续噪声
下面我们来看一下 DDPG 算法的细节。DDPG 要用到4个神经网络,其中 Actor 和 Critic 各用一个网络,此外它们都各自有一个目标网络。DDPG 中 Actor 也需要目标网络因为目标网络也会被用来计算目标
Q
Q
Q值。DDPG 中目标网络的更新与 DQN 中略有不同:在 DQN 中,每隔一段时间将
Q
Q
Q网络直接复制给目标
Q
Q
Q网络;而在 DDPG 中,目标
Q
Q
Q网络的更新采取的是一种软更新(延时更新)的方式,即让目标
Q
Q
Q网络缓慢更新,逐渐接近网络,其公式为:
ω
−
←
τ
ω
+
(
1
−
τ
)
ω
−
\omega^-\leftarrow\tau\omega+(1-\tau)\omega^-
ω−←τω+(1−τ)ω−
通常 τ \tau τ是一个比较小的数,当 τ = 1 \tau=1 τ=1时,就和 DQN 的更新方式一致了。而目标 μ \mu μ网络(策略网络)也使用这种软更新的方式。
另外,由于
Q
Q
Q函数存在
Q
Q
Q值过高估计的问题,DDPG 采用了 Double DQN 中的技术来更新
Q
Q
Q网络。但是,由于 DDPG 采用的是确定性策略,它本身的探索仍然十分有限。回忆一下 DQN 算法,它的探索主要由
ϵ
\epsilon
ϵ-贪婪策略的行为策略产生。同样作为一种离线策略的算法,DDPG 在行为策略上引入一个
N
\mathcal{N}
N随机噪声(原论文使用的是OU噪声,后来许多实验证明高斯噪声具有更好的效果)来进行探索。

伪代码


代码实践
import gymnasium as gym
import numpy as np
from tqdm import tqdm
import torch
import torch.nn.functional as F
import util
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
# action_bound是环境可以接受的动作最大值
self.action_bound = action_bound
def forward(self, x):
x = F.relu(self.fc1(x))
return torch.tanh(self.fc2(x)) * self.action_bound
class QValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc_out = torch.nn.Linear(hidden_dim, 1)
def forward(self, s, a):
# 拼接状态和动作
cat = torch.cat([s, a], dim=1)
x = F.relu(self.fc1(cat))
x = F.relu(self.fc2(x))
return self.fc_out(x)
class DDPG:
''' DDPG算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma,
action_bound, sigma, tau, buffer_size, minimal_size, batch_size, device, numOfEpisodes, env):
self.action_dim = action_dim
self.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
# 初始化目标价值网络并设置和价值网络相同的参数
self.target_critic.load_state_dict(self.critic.state_dict())
# 初始化目标策略网络并设置和策略相同的参数
self.target_actor.load_state_dict(self.actor.state_dict())
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.gamma = gamma
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.tau = tau # 目标网络软更新参数
self.device = device
self.env = env
self.numOfEpisodes = numOfEpisodes
self.buffer_size = buffer_size
self.minimal_size = minimal_size
self.batch_size = batch_size
def take_action(self, state):
state = torch.FloatTensor(np.array([state])).to(self.device)
action = self.actor(state).item()
# 给动作添加噪声,增加探索
action = action + self.sigma * np.random.randn(self.action_dim)
return action
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) + param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device)
actions = torch.tensor(np.array(transition_dict['actions']), dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device)
terminateds = torch.tensor(transition_dict['terminateds'], dtype=torch.float).view(-1, 1).to(self.device)
truncateds = torch.tensor(transition_dict['truncateds'], dtype=torch.float).view(-1, 1).to(self.device)
q_targets = rewards + self.gamma * (self.target_critic(next_states, self.target_actor(next_states))) * (1 - terminateds + truncateds)
critic_loss = torch.mean(F.mse_loss(q_targets, self.critic(states, actions)))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
actor_loss = -torch.mean(self.critic(states, self.actor(states)))
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.soft_update(self.actor, self.target_actor) # 软更新策略网络
self.soft_update(self.critic, self.target_critic) # 软更新价值网络
def DDPGtrain(self):
replay_buffer = util.ReplayBuffer(self.buffer_size)
returnList = []
for i in range(10):
with tqdm(total=int(self.numOfEpisodes / 10), desc='Iteration %d' % i) as pbar:
for episode in range(int(self.numOfEpisodes / 10)):
# initialize state
state, info = self.env.reset()
terminated = False
truncated = False
episodeReward = 0
# Loop for each step of episode:
while (not terminated) or (not truncated):
action = self.take_action(state)
next_state, reward, terminated, truncated, info = self.env.step(action)
replay_buffer.add(state, action, reward, next_state, terminated, truncated)
state = next_state
episodeReward += reward
# 当buffer数据的数量超过一定值后,才进行Q网络训练
if replay_buffer.size() > self.minimal_size:
b_s, b_a, b_r, b_ns, b_te, b_tr = replay_buffer.sample(self.batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'terminateds': b_te,
'truncateds': b_tr
}
self.update(transition_dict)
if terminated or truncated:
break
returnList.append(episodeReward)
if (episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报
pbar.set_postfix({
'episode':
'%d' % (self.numOfEpisodes / 10 * i + episode + 1),
'return':
'%.3f' % np.mean(returnList[-10:])
})
pbar.update(1)
return returnList
超参数设置参考:
agent = DDPG(state_dim=env.observation_space.shape[0],
hidden_dim=256,
action_dim=env.action_space.shape[0],
actor_lr=3e-4,
critic_lr=3e-3,
gamma=0.99,
action_bound=env.action_space.high[0],
sigma=0.01,
tau=0.005,
buffer_size=10000,
minimal_size=1000,
batch_size=64,
device=device,
numOfEpisodes=200,
env=env)

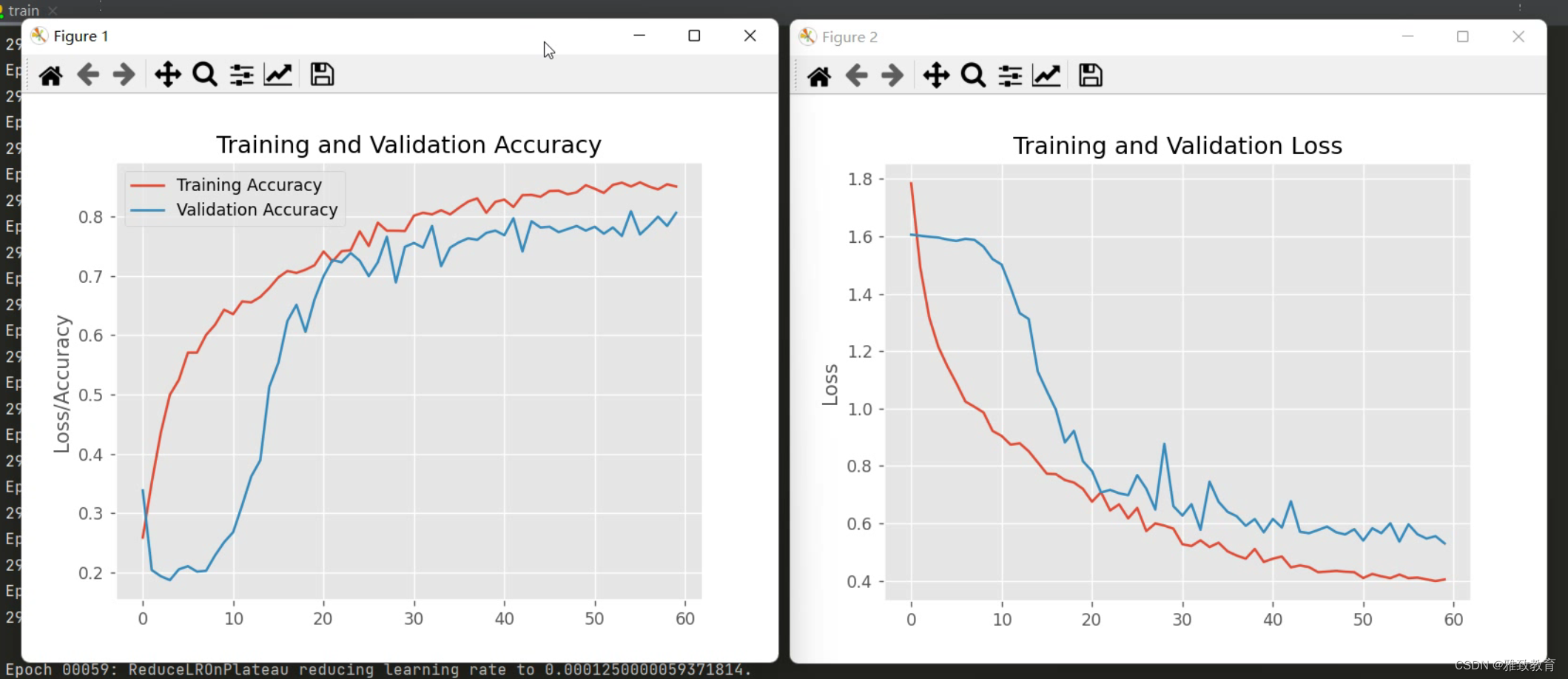
DDPG算法相比之前的在线学习算法,更加稳定,同时收敛速度更快。
深度确定性策略梯度算法(DDPG),它是面向连续动作空间的深度确定性策略训练的典型算法。相比于它的先期工作,即确定性梯度算法(DPG),DDPG 加入了目标网络和软更新的方法,这对深度模型构建的价值网络和策略网络的稳定学习起到了关键的作用。