JavaEE平台技术——Spring和Spring Boot
- 1. 控制反转
- 1.1. IoC是什么
- 1.2. IoC能做什么
- 1.3. IoC和DI
- 2. SpringBean对象定义
- 3. Spring容器
- 4. SpringBoot


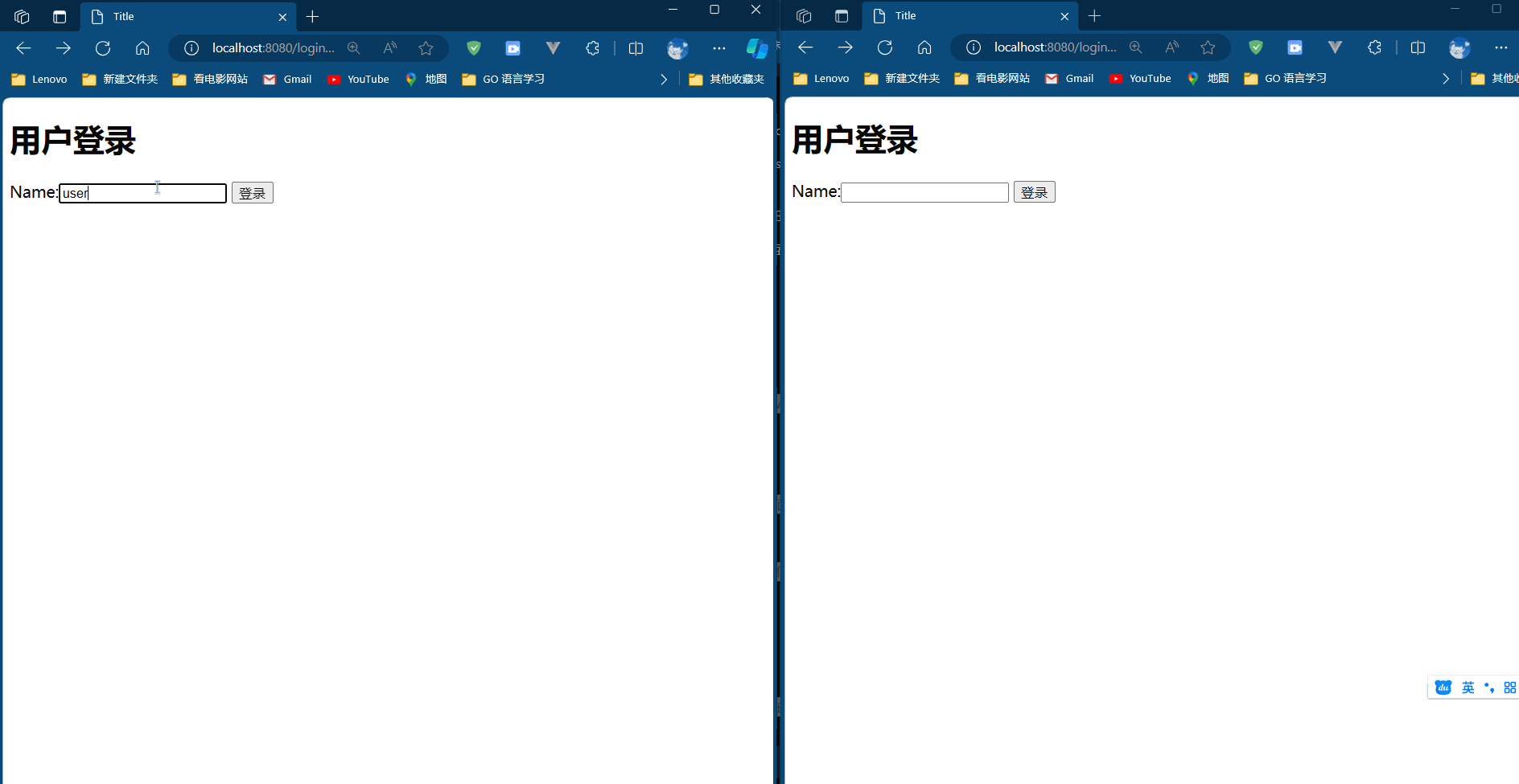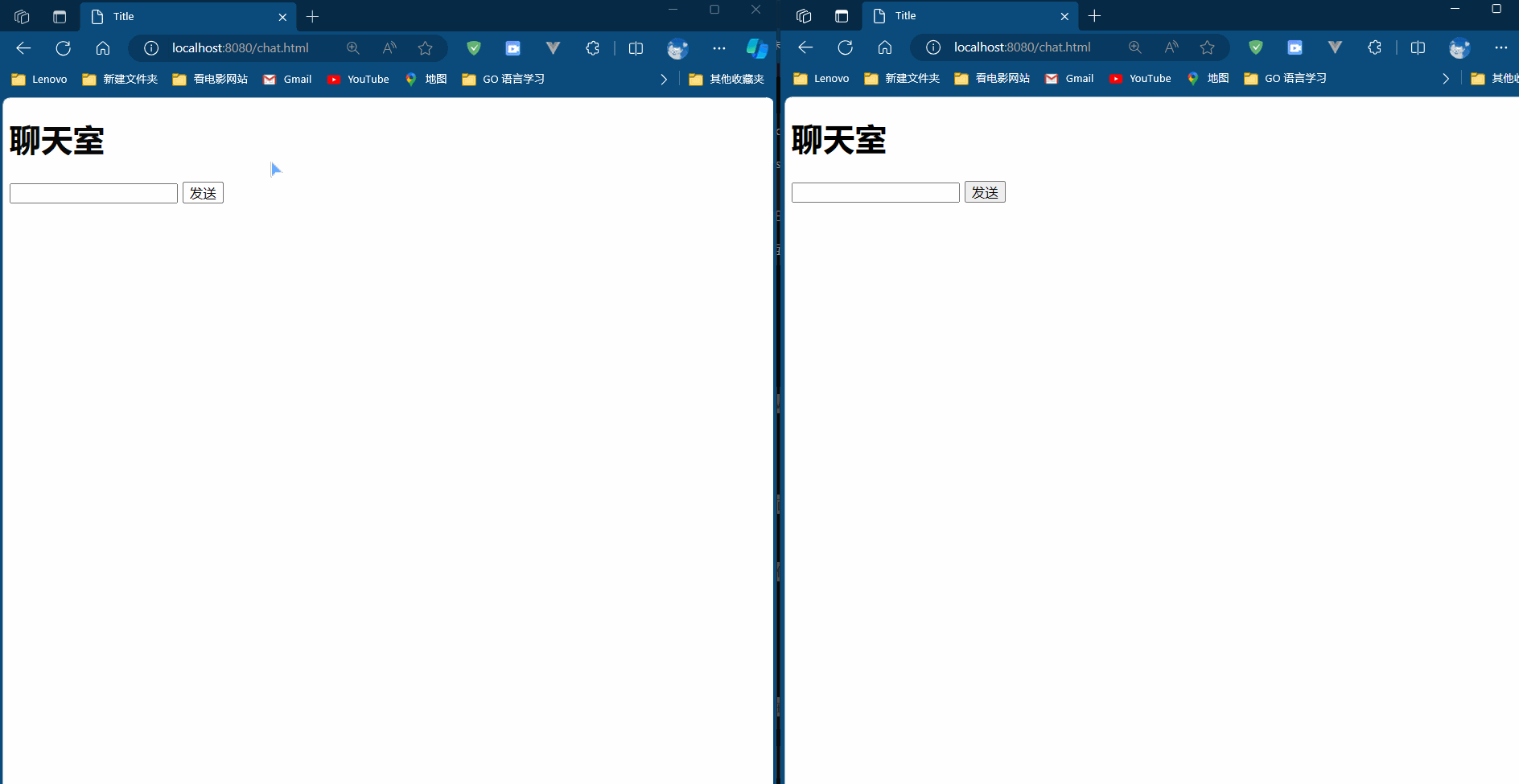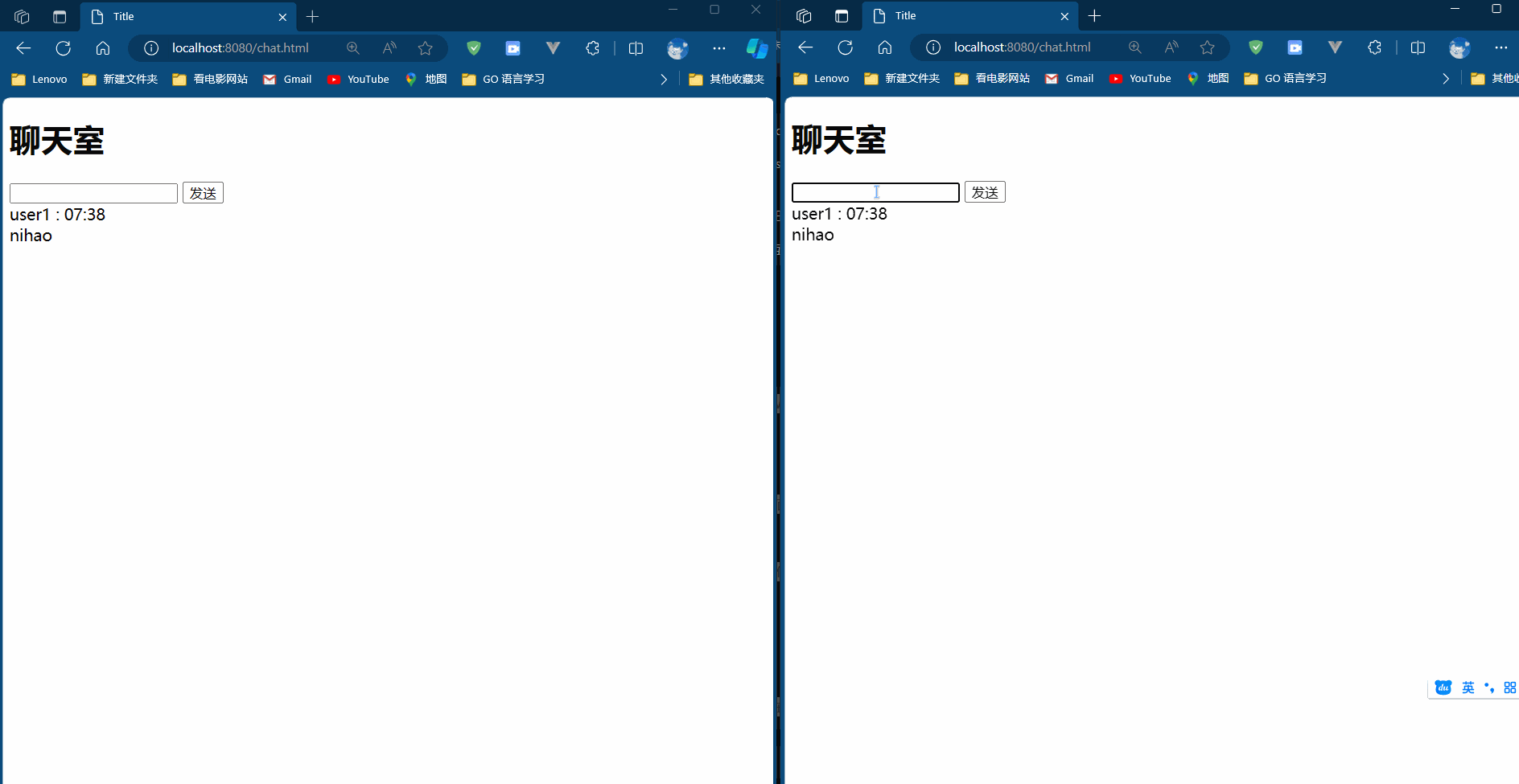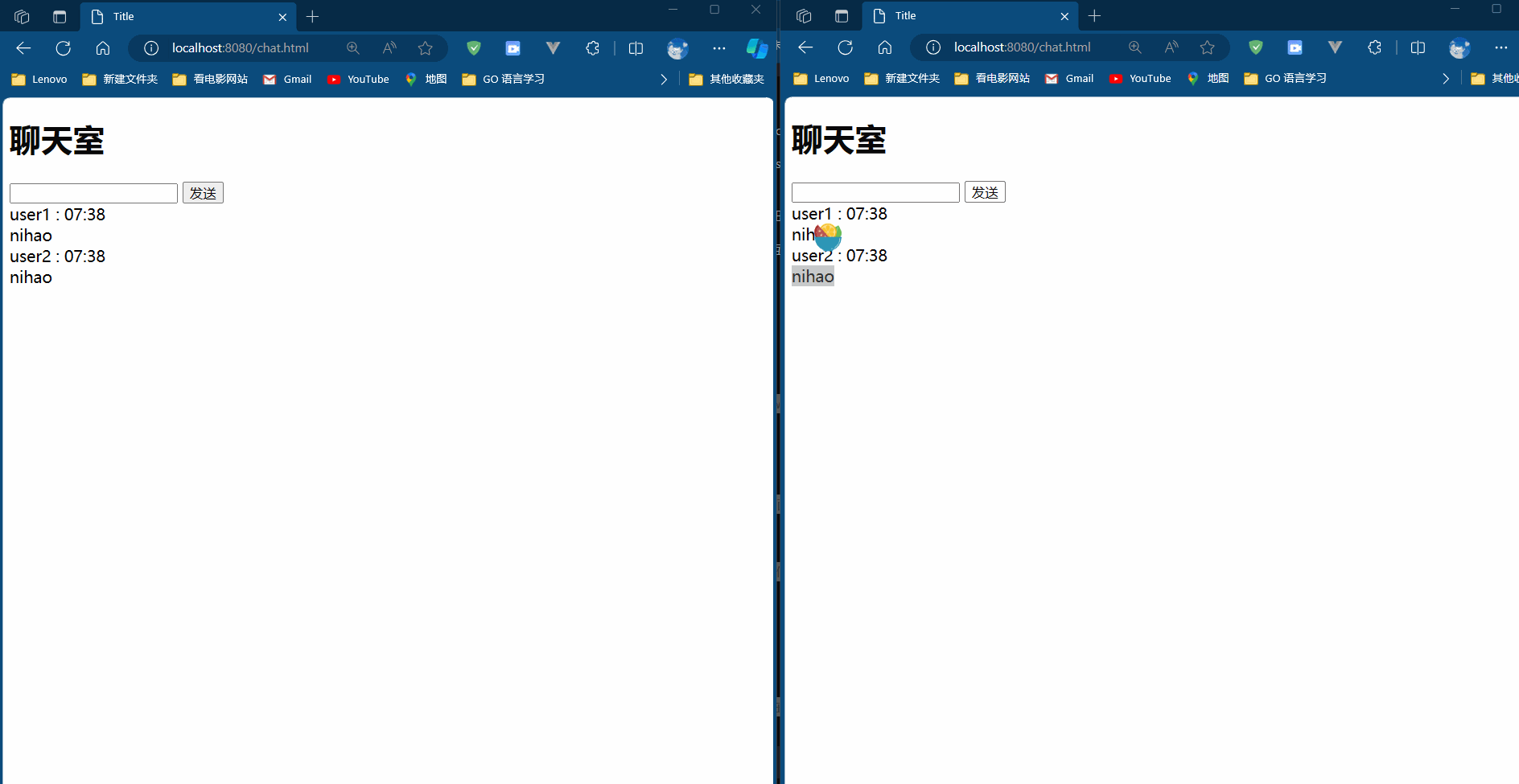
在观看这个之前,大家请查阅前序内容。
😀JavaEE的渊源
😀😀JavaEE平台技术——预备知识(Web、Sevlet、Tomcat)
😀😀😀JavaEE平台技术——预备知识(Maven、Docker)
1. 控制反转
来讲讲非常非常重要的东西吧!!!——Spring框架的两大核心特性,其中一个就是IoC!!!
🐷回顾到2003年,当时的Spring只是一个工程,因此当人们谈论Spring时,指的是Spring框架的一个版本。然而,随着20年的发展,如今的Spring已经不再是一个单一的工程,而是分化为十几甚至二十个不同的子项目,形成了一个庞大的项目列表。因此,如今谈论Spring时,通常有两种语义。一种语义是指Spring的整个生态系统,涵盖了从Spring框架到Spring Cloud、Spring Boot、Spring Data、Spring Integration、Spring Security、Spring DataFlow等等各种项目,它们都被归类为Spring的一部分。
🐷另一种更常见的语义是指Spring核心框架,即从Spring最初就存在的核心部分。这些核心部分通常指的是控制反转(IoC) 和 面向切面编程(AOP)。这两个概念构成了Spring框架最为关键的组成部分。


🐷根据这张Spring 5.0的图,可以看出它的架构已经发生了一些变化。
- 基本上,所有这些框架都被分成了两个部分。一部分是Reactive Stack,另一部分是Servlet Stack。
- 所有的附属框架,包括Spring Security、Spring MVC、Spring Data、以及它的JPA等,都发生了变化。
- 但是它的核心框架,也就是我们所说的IoC和AOP部分,仍然保持不变。
- 同时,它顶部的一部分,也就是最外层的一层,涉及到Spring Boot,和底部的核心框架部分仍然保持不变。在这两个栈上,它的核心部分仍然保持一致。
在今天的课程中,我们主要讲了最底层核心的IoC部分和最顶层的表面部分Spring Boot。在这两个部分之间,我们将在后续课程中逐个进行讲解。Spring最核心的特性是控制反转(IoC)。
为了方便理解下面的这个段落,A与B 我们可以带入一个示例:
对象A为Student 对象B为Score 这样我们就知道了他们的所属关系了。Student 包含的一个属性为Score ,所以A创建好了之后B也要创建好 并赋予A。
🐷关于IoC,可能如果您之前接触过Spring,您一定对此耳熟能详。网上有很多关于IoC的定义,我举一个比较形象的例子来说明。就像我们昨天看到的,对象与对象之间存在着关联。关联意味着一个对象有一个属性,它是另一个对象。当我实例化一个A对象时,如果它有一个属性是B对象,它们之间就存在关联。因此,当我实例化A对象时,我必须将B对象也实例化。两个对象都实例化后,A对象才能使用。此外,不仅需要实例化B对象,还需要将B对象设置为A对象的属性。
🐷在面向对象编程中,我们有一个设计原则叫做创建者设计原则。如果某个对象之间存在关联关系,并且该对象经常使用另一个对象,我们很可能会让该对象去创建它所使用的对象。也就是让A对象去创建B对象,然后将它们关联起来。这是一种比较正常的做法。那么什么是控制反转呢?
🐷控制反转意味着自己不控制B对象的创建和建立耦合的过程,而是将这件事交给别人处理。如果要将这件事交给别人处理,它内部肯定要提供一种方法,让别人去建立这样的耦合。它不会自己去建立耦合,而是通过外部的方式告诉它与哪个对象发生耦合。
建立耦合的方式!!!!
-
构造函数,在构造A对象时,我可以将一个B对象作为参数传递进来,从而将B对象与A对象关联起来。
-
通过set方法,提供一个set函数,让别人告诉我要与哪个对象发生关联。这就是控制反转的意思。

因此,控制反转意味着对于关联的对象,我没有控制权,而是将其控制权交给了其他人,这就是控制反转(Inversion of Control)。
控制反转引入了另一个问题,既然我把控制权交给了别人,那么谁来控制呢?
这时候容器就承担了控制的职责,或者说由其他人在创建对象时告诉你应该依赖于哪些对象。这就是依赖注入。因此,我们经常说控制反转和依赖注入是同义词。
其实这就是同一个概念的两个方面。
- 我放弃了控制权,必然需要别人告诉我该依赖哪些对象,这就是依赖注入。
- 如果我不放弃控制权,别人也无法进行依赖注入。
所以控制反转是我交出控制权,而依赖注入是别人注入依赖的对象。实际上这是同一个概念的两个不同方面。
这种方式的最大好处是实现了低耦合或松耦合、高内聚低耦合。
🐷通常情况下,我们会将其分开,也就是单独对A和B进行测试。
对B进行单独测试应该没有问题,因为它现在不依赖任何其他内容。
但是,如果要对A进行单独测试,我们刚才说过,它与B有关联关系,这意味着在其方法中会调用B对象的方法。
因此你无法将其拆分开来,因为A的代码是不可更改的,而在进行代码测试时,必须保持代码的原样。但A的代码中会调用B的方法,所以你无法进行测试。
🐷唯一的办法是解开它们的耦合。正是依赖注入或控制反转使得这样的测试成为可能。那么怎么可能呢?就是注入进来的东西是由外部注入的。在进行测试时,我注入的是什么?我注入的是一个Mock B而不是真正的B。什么是Mock B呢?Mock B是一个虚假的B,它实现了与B相同的方法,但内部没有实际的代码。你告诉它当调用你的方法时,给你什么样的参数,它就返回什么样的值。实际上,我们测试是有测试数据的,我们不会盲目地进行测试,我们会有测试数据。我们会预期在调用这些测试数据后,当调用B的方法时,它会返回什么样的值。Mock B的作用就是在其内部没有逻辑的情况下,你给它什么值它就返回什么值。就像一个模拟的组件一样,你给它一个值,它就返回一个值。这样,当我们针对这组数据对A进行测试时,我们测试的只是A的代码,而不包括B的代码。这就是所谓的切片测试。这是测试中最重要的一种方法。如果你的代码无法进行切片,那么你就无法进行测试,因为代码中必然存在耦合。要进行切片测试,就必须依赖于控制反转和依赖注入。
🐷🐷这也解释了为什么今天我们强调控制反转和依赖注入对于编写代码来说是非常重要的。
如果代码无法进行切片测试,一旦出错,你就只能在一大片互相关联的代码中寻找,找到具体出错的地方。这会极大地浪费时间。只有完成了切片测试并尽量排除了每一块的错误,最后将它们合并起来,才能减少错误。否则你将不得不盲目地寻找错误。因此,这就是控制反转和依赖注入的重要性。
🐷🐷那么Spring框架是如何实现控制反转和依赖注入的呢?

所有的对象都是由Spring容器来管理的。这个概念非常类似于我们之前讲的Servlet。Servlet将服务器的代码分成了容器和组件。所有的组件都由容器来管理,也是由容器来创建的。比如Servlet对象是由Servlet容器来创建的。Spring框架也采用了相同的思想。它有一个Spring容器,我们编写的代码都是所谓的业务对象,或者叫做Spring的Bean对象,还有人称之为POJO对象,POJO的全称是Plain Old Java Object。
🐷POJO是普通的Java对象。它们之间没有耦合,都是松散的。每个类有自己的定义,需要一些属性,但是属性的具体值是未知的。通过构造函数或者set方法,由外部提供具体的值。这些具体的值实际上是写在配置数据中的。
在接下来的示例中,我们会用注解的方式或者用Java代码的方式来编写这些配置数据。Spring容器在构建对象时,由于所有的对象都是进行了控制反转,都提供了构造函数和set方法来设定它们的关联关系,所以在构建这些对象时,它根据配置数据来决定这些对象之间应该是什么样的关联。最终形成了这样一个系统。
因此,当我们进行测试时,通过配置数据,让Spring容器构造的对象的关联是一个Mock对象或者是一个虚假的对象,而不是一个真实的对象。这样我们就可以对这部分代码进行单独的测试了。这就是Spring容器是如何实现控制反转的。
🐷它的主要意义并不是它在编写代码方面提供了多么强大的能力,而是它为我们现代软件工程中的软件测试提供了一种最基本的方法。
1.1. IoC是什么
Ioc—Inversion of Control,即“控制反转”,不是什么技术,而是一种设计思想。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解好Ioc呢?理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”,那我们来深入分析一下:
-
谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
-
为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
用图例说明一下,传统程序设计如图2-1,都是主动去创建相关对象然后再组合起来:
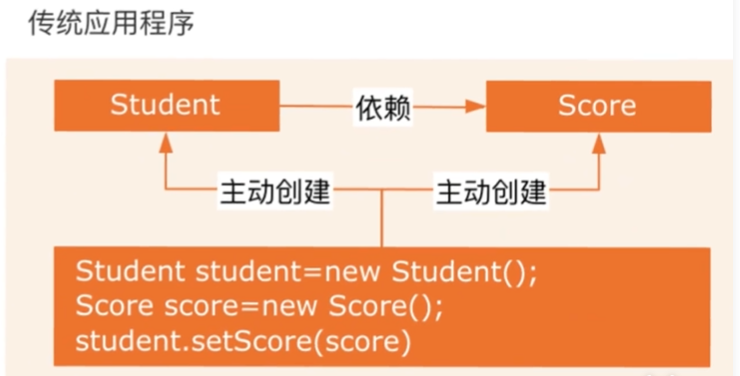
图2-1 传统应用程序示意图
当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了,如图2-2所示:
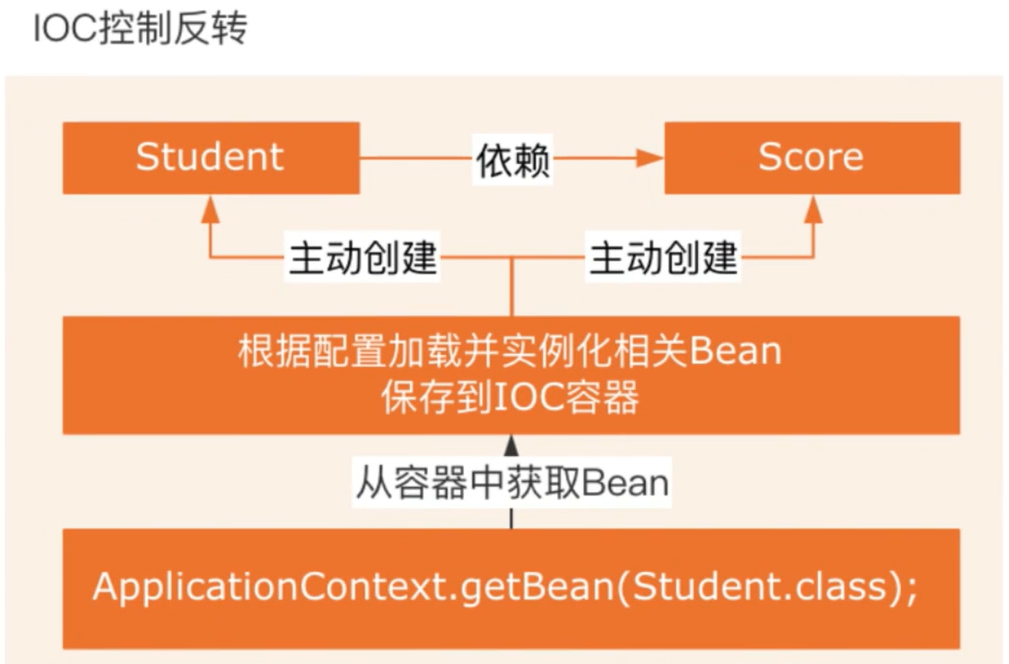
图2-2有IoC/DI容器后程序结构示意图
1.2. IoC能做什么
IoC不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一——好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
1.3. IoC和DI
DI—Dependency Injection,即“依赖注入”:是组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,那我们来深入分析一下:
-
谁依赖于谁:当然是某个容器管理对象依赖于IoC容器;“被注入对象的对象”依赖于“依赖对象”;也就是A依赖B
-
为什么需要依赖:容器管理对象需要IoC容器来提供对象需要的外部资源;
-
谁注入谁:很明显是IoC容器注入某个对象,也就是注入“依赖对象”;
-
注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IoC和DI由什么关系呢?其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系)。
所以2004年大师级人物Martin Fowler又给出了一个新的名字:“依赖注入”,相对IoC 而言,“依赖注入”明确描述了“被注入对象A 依赖 IoC容器配置依赖对象B”。
其实就是有个盒子, 原来你是直接 new, 现在是把他扔盒子里, spring 去 new, 这个 new 的过程你看不见, spring 干了 至于你什么时候想用从盒子里捞出来就行
2. SpringBean对象定义
先了解一下什么是JavaBean!先来看一段代码:
public class Person {
privete String name;
private int age;
public void setName(String newName) {
name = newName;
}
public String getName() {
return name;
}
public void setAge(int neweAge) {
age = newAge;
}
public int getAge() {
return age;
}
}
很熟悉吧,这就是每个初学者刚开始写程序的时候写的代码,这个阶段我们听说不应该把每个属性都暴露给调用者,应该根据封装的思想将其封装成私有属性,通过 getter 和 setter 来操作。于是我们满心欢喜写下刚才的代码,并庆祝自己一只脚踏进了面向对象编程的大门。
刚入门时,我总是迷茫,自己写的这个东西有什么用,每次写的 Demo 仿佛只是个玩具,看完例程再去读各种各样的框架时,总是感觉会从入门到放弃。其实,我们在不经意间就已经写了一个 Java Bean 了。回首过往,将经历连成线、串成网,就会发现念念不忘,必有回响。
正如 Java 是咖啡的一种,不是所有的咖啡都是 Java 一样。并非所有的类都是 Java Bean,其是一种特殊的类,具有以下特征:
- 提供一个默认的无参构造函数。
- 需要被序列化并且实现了 Serializable 接口。
- 可能有一系列可读写属性,并且一般是 private 的。
- 可能有一系列的 getter 或 setter 方法。
- 根据封装的思想,我们使用 get 和 set 方法封装 private 的属性,并且根据属性是否可读写来选择封装方法。
Java Bean 的作用
仔细观察 Java Bean 可发现,其最大的特征是私有的属性,getter 和 setter 方法也都是绕着这些属性来设计的。
想象一下存在这样一个箱子,其内部被分割成几个格子,每个格子用来存放特定的物品,工人取出或者放入物品后封箱,然后叫了个快递把箱子发出去了。这个箱子就是 Java Bean 啊,取出、放入就是getter、setter,物品就是属性,封箱发出就是序列化和传输。
那么 Java Bean 的作用也就是把一组数据组合成一个特殊的类便于传输。 Java Bean 可以用在图形界面的可视化设计、JSP 封装数据保存到数据库、Android AIDL 跨进程通信,Spring框架等场景中。
🐷配置数据 Spring框架,目前提供了XML、Java代码、注解,三种方式来写配置数据,XML的配置在里头,到今天还有 但是这个东西还有没有用,基本上没人用了,而且我们预计它在今年的新版本中间,就会把XML配置的功能给完全拿掉。
所以我们主要是讲其余两种方式的注解的方式。
🐷对于所有的Bean对象来说,你要告诉Spring的框架——它是个Bean对象,然后它要有一个名字,然后它能活多长。
🐷在Spring中,Bean的名字必须是唯一的,但默认情况下,Spring会为Bean提供一个默认的名字,它的默认名字是该类的类名的首字母小写。一个类在Spring容器中是可以有多个对象的,后面会解答关于它的生命周期的问题。
🐷对于Spring容器中的一个Bean对象,在编写这个类时,我们会告诉Spring容器它的生命周期方式:
-
Singleton(独生子):在整个Spring容器中,只存在一个对象实例。不管有多少地方要求这个类的对象,都会获得同一个实例。这种方式节省内存,但要注意对象的属性是不可修改的,因为所有地方共享同一个实例。如果试图在执行期间修改Singleton Bean的属性,可能会导致线程冲突。
-
Prototype(原型):每次请求一个Bean对象,Spring容器都会创建一个新的实例。这意味着每次请求该Bean时都会得到一个全新的实例。这种方式更加灵活,但可能会导致内存占用过多,因为Spring容器无法限制对象数量。
-
Request:每个HTTP请求生成个新Bean对象
-
Session:每个Session生成一一个新Bean对象
-
Application:在ServletContext范围内生成唯一Bean对 象
🐷在大多数情况下,Singleton是默认的生命周期方式,因为它节省内存并且在大多数情况下是足够的。但要注意不要在Singleton Bean的实例中修改属性,以避免线程冲突。如果需要每次都获得一个新的实例,可以选择使用Prototype方式,但需要谨慎考虑内存开销。在Spring中,你也可以使用其他自定义的生命周期方式,根据具体需求配置Bean的作用域。
在Spring中,可以使用注解或代码的方式来定义Bean对象,这两种方式都可以告诉Spring容器哪些类是Bean对象以及如何创建它们。
🐷🐷使用注解方式:你可以在一个Java类的前面添加注解 @Component,这个类就会被Spring容器扫描到,并自动创建成Bean对象。
@Component
@Scope("prototype" )
public class Toyota implements Car{
}
你也可以在注解中指定Bean的名称和作用域(默认是Singleton)。例如,你可以在一个类前面添加 @Component 注解,如 @Component("toyota"),这会告诉Spring容器将该类创建为一个Bean,名字是 “toyota”。示例代码如下:
@Component("toyota")
public class Toyota implements Car {
// ...
}
🐷🐷使用代码方式:你可以创建一个Java配置类,并在该类中使用 @Configuration注解。然后,你可以在该配置类中定义方法,这些方法返回的对象将被Spring容器创建为Bean对象。你需要在方法前添加 @Bean 注解,并在方法内部返回要创建的对象。示例代码如下:
@Configuration
public class AppConfig {
@Bean
@Scope("singleton")
public Car haval(){
return new Haval();
}
}
🐷这两种方式都告诉Spring容器如何创建Bean对象。使用注解方式通常更简单,特别是当对象的创建过程较为简单时。使用代码方式通常用于需要特殊逻辑或需要创建不同参数配置的Bean对象。
🐷总之,无论是使用注解还是使用代码方式,都能告诉Spring容器哪些类应该被实例化为Bean对象。 Spring容器会根据配置来创建这些Bean,并管理它们的生命周期和作用域。
3. Spring容器
🐷Spring的容器是通过BeanFactory来创建和管理Bean对象的。从Spring 1.0开始就有了BeanFactory。
- 它负责读取配置信息
- 创建对象实例
- 注入它们之间的依赖关系
- 最终管理Bean对象的生命周期
因此,BeanFactory承担了所有这些任务,实际上从一开始就负责了所有的事情。
🐷尽管一开始使用BeanFactory,但在今天,我们通常使用的是ApplicationContext。
ApplicationContext是BeanFactory的一个子接口。它继承了BeanFactory的所有能力,并且额外增加了一些功能:
- 支持国际化
- 处理文件资源
- URL资源等能力
- 它还在Spring容器内部定义了事件,并添加了更多的上下文功能。
因此,我们更倾向于使用ApplicationContext而不是BeanFactory。
值得一提的是,在面试过程中经常会有一些问题与BeanFactory和ApplicationContext的原理以及源代码有关。这种面试方式是否有意义呢?实际上并没有多大意义。在编写代码时,我们更关心的是如何操作容器以及如何从容器中获取资源。我们知道容器有一个ApplicationContext,它是BeanFactory的子类,负责执行所有的操作。我们可以通过它来了解容器中发生的一切,并可以通过它来完成一些容器本身没有完成的任务,比如让容器加载某个东西。尽管我们基本上都依赖于容器来完成这些工作,但它实际上为我们提供了一种方式,即通过ApplicationContext来完成这些工作。
总之,在面试过程中,经常会被问到类似的问题。但实际上,我们平时写代码时很少会用到这些知识。然而,如果你要自己编写一个框架,这些知识就是一个很好的面向对象设计的范本。
🐷我们知道ApplicationContext是我们经常使用的一个从容器中获取东西的接口,通过它我们可以操作容器。所有容器能做的事情实际上都可以通过这个接口中的方法来完成,我们不需要去亲自干预容器。总的来说,控制反转就是让对象之间的依赖关系自己不管了,交给容器去管理。容器通过构造函数和set方法来实现依赖注入,而配置通常使用Java配置和注解来完成。
🐷Spring框架的发展趋势是简化所有的配置,其中一个主要标志就是@Autowired注解。容器不需要我们告诉它该跟谁依赖,应该绑定在一起。@Autowired提供了一种默认的方式来绑定对象之间的耦合关系。通常@Autowired会用在构造函数和set方法的前面。如果在容器中找到了多个符合条件的Bean对象,@Autowired会绑定和变量名相同的名称。
推荐
@Component
public class Boss_constructor {
private Car car;
private Office office;
@Autowired
public Boss_constructor(Car toyota, Office office){
this.car= toyota;
this.office = office;
}
}
@Autowired 看IOC里有没有 有一个 注进来!
@Autowired注解也可以直接标注在方法的前面,它的作用是从容器中获取Bean对象并注入。如果找不到对应的Bean对象,那么这个值会被设为空值。除了直接标注在方法前面,@Autowired也可以用在Bean的前面来标识这是一个Bean对象。
我们推荐构造Bean对象的方式是通过代码来写。尽管set方法也可以,但是在Spring的文档中,它提到set方法主要是用来解决循环依赖的问题。
🐷循环依赖指的是A对象依赖B对象,B对象依赖C对象,C对象又依赖A对象,这样的循环依赖会导致构造函数无法构造出对象。在Spring框架中,如果遇到这种循环依赖问题,可以通过set方法来解决。因为set方法是在构造对象之后调用的,所以可以先构造出所有对象,然后再分别设置它们的依赖关系,这样就能避免循环依赖导致的构造失败。
@Component(boss_Setter")
public class Boss_Setter {
private Office office;
private Car car;
@Autowired
public void setCar(Car toyota){
this.car = toyota;
}
@Autowired
public void setOffice( Office office){
this.office = office;
}
}
Bean对象用代码的方式来写
@Bean
@Autowired
public Boss boss(Toyota car, Office officel{
return new Boss(car, office);
}
Spring框架的文档提到了如果遇到循环依赖,可以使用
@Lazy注解来延迟加载。在代码中加入@Lazy注解后,就可以避免循环依赖导致的构造失败。但是需要注意的是,@Lazy注解属于特例,通常情况下我们都应该尽量避免对象之间的循环依赖。
除了构造函数和set方法,还有一种注入方式是通过属性来实现。不过这种方式已经过时了,不推荐使用。在最新的Spring版本中,官方已经明确表示推荐使用构造函数和set方法来实现依赖注入,不再支持通过属性进行注入。这是因为直接通过属性来注入违反了对象的封装性原则。

关于Spring对象的生命周期,Spring框架提供了生命周期接口,主要分为
- 容器级的生命周期接口
- 容器级的生命周期接口对所有的Bean对象都有效;
- Bean级的生命周期接口
- Bean级的生命周期接口针对特定的Bean对象,让它实现特定的接口来获取在创建过程中的一些值。
在容器中实例化Bean对象的过程是先调用容器级接口postProcessBeforeInstantiation,在实例化之前执行一些操作。

🐷🐷根据Spring框架的生命周期,可以实现多种接口来影响Bean对象的创建和初始化过程。其中包括容器级的接口postProcessBeforeInstantiation和postProcessAfterInstantiation,以及Bean级的接口InitializingBean和DisposableBean。此外,还有一些Aware接口,例如BeanNameAware可以让Bean对象知道自己在容器中的名字,以及BeanFactoryAware和ApplicationContextAware可以让Bean对象获取容器的相关信息。
在Spring中,推荐使用构造函数和set方法来实现依赖注入。此外,还可以通过
@Lazy注解来解决循环依赖的问题,但这仅仅是特殊情况。除了这些方法,还可以通过initMethod和destroyMethod来定义Bean的初始化和销毁方法。在编写代码时,应尽量避免使用System.out来打印信息,而应该使用日志打印,这样可以更好地控制日志的输出和管理。在服务器端运行代码时,尤其要注意不要使用System.out,而要使用日志框架,如Spring默认的日志框架logback,以保证代码的正确运行和调试。
4. SpringBoot
🐷Spring Boot是建立在整个Spring框架之上的顶层,它的主要目的是简化配置和统一管理依赖。在没有Spring Boot的时候,我们需要一个个独立引入Jar包来管理依赖。而有了Spring Boot之后,通过引入一个Starter,就可以将一组相关的Jar包一起引入,因为通常我们会以组的方式来使用这些Jar包。
Spring Boot提供了两个重要的变化。在没有Spring Boot之前,我们打出的是一个War包,需要在服务器上安装Tomcat来部署这个War包。而Spring Boot则采用了一种全新的方式,它将Tomcat内嵌在项目中,打成一个可执行的Jar包,直接在服务器上运行这个Jar文件,就会启动内嵌的Tomcat并运行项目。这种方式在当时可能是为了简化部署流程,因为我们只需要运行一个Jar包就可以了,不再需要单独安装Tomcat。
另一个重要的变化是,Spring Boot为每个运行的应用程序提供了监控功能。虽然我们可能不会直接查看监控数据,因为返回的JSON数据往往难以理解,但我们可以使用第三方工具来读取Spring Boot提供的监控信息。在早期版本中,Spring Boot提供了一个简单的Admin UI界面来展示监控信息。
总的来说,Spring Boot的出现改变了服务器部署方式,使部署变得更加简单和高效。它还提供了简单的监控功能,让开发人员可以更方便地查看应用程序的状态和性能。同时,结合Docker的使用,使得部署和管理应用程序变得更加便捷和灵活。
Spring Boot引入了Starter的概念,用于简化依赖管理。
Starter是一种预打包好的Jar包,其中包含了一组相关的Jar包和默认配置,以满足特定的应用程序需求。Spring Boot的目标是帮助开发人员更轻松地引入和管理依赖。
每个Starter通常包括以下内容:
-
一组相关的Jar包:Starter中包含了应用程序所需的相关依赖的Jar包,以避免手动引入每个单独的Jar包。
-
默认配置:Starter中包含了默认配置,以减少开发人员的配置工作。这些配置可以在需要时进行自定义。application.yaml
-
版本管理:Starter帮助管理所有包含的依赖的版本,以确保它们兼容并且不会导致冲突。

Spring Boot的Starter分为不同的类型,每种类型针对不同的应用场景和功能需求。例如,有用于Web开发的Starter、用于数据库访问的Starter、用于测试的Starter等。
对于:

这个是Servlet Stack 的Web所有的相关Jar包全在这个Starter里头。
对于:

这个是跟测试有关的,一句话 引进来10几20个呢
使用Starter的好处是,你只需引入特定类型的Starter,就能轻松获得相关依赖和默认配置。如果需要自定义配置,你可以在项目中的配置文件中进行覆盖。
总之,Spring Boot的Starter是一个强大的工具,用于管理依赖和简化应用程序的配置。它使开发人员能够更快速地构建和部署应用程序,同时降低了潜在的冲突和配置错误的风险。
在引入Spring Boot后,一条简单的语句就能够将十几个甚至二十个Jar包一次性引入项目中,而不需要之前逐个引入,这使得项目对象模型(POM)的配置变得更为简洁。
在编译过程中,需要使用Spring Boot的Maven插件来进行编译。今年我们计划使用面向切面编程(AOP),并打算介绍一下去年没有涉及到的缓存(Cache)概念。

在项目中,我们预计会使用Redis和Test Web。因为Spring Boot被打包为一个可执行Jar文件,所以该文件中必须包含main函数。

该main函数无需修改,你只需告诉它配置在哪里即可。可以看到,它会自动在默认目录下进行扫描。如果你不符合默认条件,就需要手动添加配置。这里需要注意的是@SpringBootApplication注解由三个注解组成:
- @Configuration
- @ComponentScan
- @EnableAutoConfiguration
@Configuration表示可以在该类中编写配置,因为它是一个配置类。
@ComponentScan用于扫描指定目录中带有注解的类,这些注解表明它们是Bean对象。
@EnableAutoConfiguration用于读取默认配置以及Property的Yaml文件,完成整个项目的配置。
Spring Boot的配置文件通常放置在application.yaml或者application.properties文件中。除了在这两个文件中定义配置外,我们还可以在其他地方定义配置,比如在运行Jar文件时可以添加命令行参数或者在环境变量中设置参数。
在读取配置的顺序方面,它首先会读取Java虚拟机的配置信息,然后是操作系统的环境变量,接着是Java
-jar命令行的参数,最后是application文件中的配置。


读取配置后,就会形成一个完整的配置,可以在所有Bean对象中使用。你只需使用依赖注入(DI)的方式,使用@Value注解来将配置值注入到对象属性中。
最后,我们讨论了Actuator,它通过提供RestFUL API的方式来获取应用程序的信息和健康状况参数。
| 名称 | 说明 |
|---|---|
| autoconfig | 这个endpoint会为我们提供一份SpringBoot的自动配置报告,告诉我们哪些自动配置模块生效了,以及哪些没有生效,原因是什么。 |
| beans | 给出当前应用的容器中所有bean的信息。 |
| configprops | 对现有容器中的ConfigurationProperies提供的信息进行“消毒”处理后给出汇总信息。 |
| info | 提供当前SpringBoot应用的任意信息,我们可以通过Environment或者application.properies等形式提供以info.为前缀的任何配置项,然后info这个endpoint就会将这些配置项的值作为信息的一部分展示出来。 |
| health | 针对当前SpringBoot应用的健康检查用的endpoint。 |
| env | 关于当前SpringBoot应用对应的Environment信息。 |
| metrics | 当前SprinBoot应用的metrics 信息。 |
| trace | 当前SpringBoot应用的trace信息。 |
| mapping | 如果是基于SpringMVC的Web应用,mapping 这个endpoint将给出@RequestMapping相关信息。 |