✨个人主页: 北 海
🎉所属专栏: MySQL 学习
🎃操作环境: CentOS 7.6 阿里云远程服务器
🎁软件版本: MySQL 5.7.44

文章目录
- 1.数据库概念
- 1.1.什么是数据库
- 1.2.数据库存储介质
- 1.3.常见数据库
- 2.数据库基本操作
- 2.1.连接数据库
- 2.2.使用数据库
- 2.3.服务器、数据库、表关系
- 3.MySQL语句分类
- 4.MySQL架构
- 5.存储引擎
- 5.1.查看存储引擎
- 5.2.存储引擎间的区别
1.数据库概念
1.1.什么是数据库
数据库是按照数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合
我们可以直接把数据存放到文件中,这样也能保证数据长期存储,那为什么还要搞一个 数据库 呢?
因为一般的文件并没有提供很好的数据管理能力(站在我们用户角度),比如对于一个大小为几个 GB 的文档文件,如果我们想要快速的查找某个字段,就需要先读取文件信息,再进行遍历查找,效率是非常低的
文件存储的缺点:
- 安全性问题:数据容易被修改,可能造成误操作
- 不利于数据查询与管理:数据直接存储,没有被高效组织
- 不利于存储海量数据:数据量过大时,会导致文件体积膨胀
- 在程序中不方便控制:读取文件中的数据需要借助文件流,操作繁琐
但数据库就不一样了,具备简单、高效、可靠管理数据的特性,可以轻而易举的对数据进行操作;数据库由两部分组成:客户端 Client、服务器 Server,是一种 基于 CS 模式的网络服务,用户只需要使用 客户端 向 服务器 发出 SQL 语句,等待结果即可,这是非常方便的
我们学习的 MySQL 就是这种工作模式,在安装完 MySQL 后,启动的 mysqld 就是它的 服务器,所谓的登录 MySQL 也就是登录 客户端

mysqld中的d表示单词daemon,即 守护进程,这是一种特殊的进程,父进程为1号进程,即系统进程,无需依赖bash进程运行,而是直接运行在后台,这样它就能不断在后台运行
MySQL 是一套给我们 提供数据存储服务的网络程序,当我们说起 MySQL 时,应该想到:客户端、服务器、磁盘共同组成的服务体系

1.2.数据库存储介质
MySQL 数据库是将数据存储在 磁盘 中,称为 磁盘数据库;除此之外,还可以将数据存储在 内存 中,称为 内存数据库 / 主存数据库,比如 Redis 就是这种存储模式

磁盘数据库 将数据存储在 磁盘 中,在 持久化保存 上有明显优势,但 IO 次数势必会增多,为了提高自己的存储效率,磁盘数据库 拥有自己的缓存机制,即 高效 IO
内存数据库 中的数据存储在 内存 中,最大的优点就是 数据读写非常快,可以大大提高操作效率;内存数据库 并非完全不使用磁盘,比如数据库的启动信息、初始数据就得存储在磁盘中,其他涉及操作的数据存储在 内存 中,直接进行运算,为了防止数据丢失,内存数据库 通常会定期将数据转存到磁盘中,确保持久化存储
磁盘数据库和内存数据库都是数据库管理系统的存储方式,它们各自有自己的特点和适用场景
1.3.常见数据库
以下是几种常见的数据库
SQL Server: 微软的产品,深受.Net开发者的喜爱,适合中大型项目的开发Oracle:甲骨文公司推出的产品,适合大型项目,或者具有复杂逻辑的项目,其并发性能一般不如MySQLMySQL:由瑞典公司MySQL AB开发,是世界上最受欢迎的数据库,并发性能好,对简单的SQL处理效果好,适用于 电商、SNS、论坛 等项目开发,后被甲骨文公司收购PostgreSQL:起源于加州大学伯克利分校的计算机科学系,是一个独立的、开源的数据库管理系统,由全球的志愿者开发和维护,无论是私用、商用还是学术研究,都可以免费使用、修改和分发SQLite:由Dwayne Richard Hipp于 2000 年创建,是一种轻量级、嵌入式的关系型数据库,遵循ACID原则(原子性、一致性、隔离性、持久性),并且它的占用资源非常低,仅需几百KB,广泛用于移动应用、嵌入式系统、桌面应用、Web浏览器、游戏等各种应用程序中H2:一种由纯Java编写的轻量级的嵌入式关系型数据库管理系统,以嵌入式库的形式存在,适用于Java应用程序的内部嵌入,虽然它不适用于大规模或高并发的生产数据库,但对于小型项目和原型开发非常有用

MySQL 风靡全球的重要原因之一就是 免费,深受广大开发者的喜爱
2.数据库基本操作
2.1.连接数据库
首先是连接数据库,可以这样操作
注意: 连接数据库前需要确保 MySQL 服务已启动
mysql -u 用户 -p -h IP地址 -P 端口
其中:
-u后跟想要登录MySQL的用户名,比如root-p表示使用密码登录,可以紧跟密码,也可以回车后输入-h表示MySQL服务部署机器的IP地址-P表示MySQL服务进程所使用的端口号
如果是直接在云服器中登录,可以不指定 -h 和 -P,并且我们当前只有一个 root 用户,只需这样操作即可连接数据库
mysql -u root -p
输入密码后,登录 MySQL

出现 mysql> 就表示登录成功了
2.2.使用数据库
查看当前 MySQL 系统中有哪些数据库
mysql> show databases;

注:Test 是我之前创建的数据库,其他数据都属于系统数据库,不可删除
创建一个名为 DataBase1 的数据库
mysql> create database DataBase1;

在当前环境中,MySQL 运行所产生的数据都存储在 /var/lib/mysql 目录中,当我们新建一个数据库后,实际就是在 mysql 目录中新建了一个目录(文件夹)
注:
- 查看此目录需要先退出
MySQL,直接输入quit退出 - 因为是系统级文件,需要借助
root身份才能查看
ll /var/lib/mysql

使用数据库,MySQL 中会有很多数据库,在进行 建表、查询 等操作前,需要先指明使用哪一个数据库进行操作
mysql> use DataBase1;
执行指令后,可以通过函数判断是否成功
mysql> select database();

结果显示正常,证明当前正在使用 DataBase1 数据库
创建一张表 T1,包含 序号、姓名 两个列属性
mysql> create table T1
(
id int,
name varchar(32)
);

创建表后,可以查看表的详细信息,同时验证表是否已经创建成功了
mysql> desc T1;

表结构中有很多属性,现在可以先不用管具体是什么意思,只需要知道当前存在一个 int 和 varchar 类型的字段就行了
如果想进行清屏操作,可以使用 system clear 进行清屏
mysql> system clear
创建表的本质也是在创建文件,同样可以去到之前的目录中,具体进入 DataBase1 目录,可以看到这个目录下确实多了一个名为 T1 的相关文件
ll /var/lib/mysql/DataBase1

至于这两个文件具体是什么,得结合存储引擎来理解
有了表结构后,可以向表中插入部分数据
注意: 插入的数据格式要与表的格式对应,不能向不存在的字段中插入数据
现在直接进行全列插入,即插入 序号、姓名 两个信息
mysql> insert into T1 values (1, '张三');
mysql> insert into T1 values (2, '李四');
mysql> insert into T1 values (3, '王五');

在 MySQL 中,执行指令后出现 Query OK 表示指令执行成功,如果出现其他提示信息,大概率是语法问题,检查 插入数据格式、标点符号 是否出现问题
查询 T1 表中已经插入的数据
mysql> select * from T1;

可以看到数据已经成功插入 T1 表中了
创建数据库、创建表、插入数据、查询数据 已经覆盖绝大多数业务场景了,不过实际并没有这么简单,比如表结构需要慎重创建,符合 三大范式;查询数据时,需要配合各种筛选条件进行查询,如 where 子句、聚合条件、多表查询等;MySQL 中还提供了高效的数据管理机制,比如 索引、事务、权限管理,具体细节需要慢慢学习
2.3.服务器、数据库、表关系
不难发现,在使用 MySQL 中,执行结果总是以 行、列 形式呈现的,这是因为 行列构成表,而 MySQL中一切皆为表

这种行列式结构最大的优点就是直观,便于我们快速查看数据信息
- 行:数据信息
- 列:数据属性
与之前 MySQL 知识进行串联,可以得出结论:用户登录客户端,向服务器发出指令,创建数据库的本质是创建目录(文件夹),创建表的本质是在数据库中创建文件,插入数据就是往文件中写入数据,查询结果时是以行列式呈现的,表是 MySQL 中最常见、最常用的结构

一个数据库中不只存在一张表,SQL 指令执行结果也可以看作一张表
3.MySQL语句分类
MySQL 中的语句可分为三类:
DDL数据定义语句:用来维护存储数据的结构,常用于对数据库、表进行操作DML数据操纵语句:用来对数据进行操作,比如对表中的数据进行增删改查DCL数据控制语句:主要负责权限和事务的管理,可以给用户赋予数据库的权限

注:DML 数据操纵语句中还细分出了一个 DQL 数据查询语句,例如查询时携带的各种条件
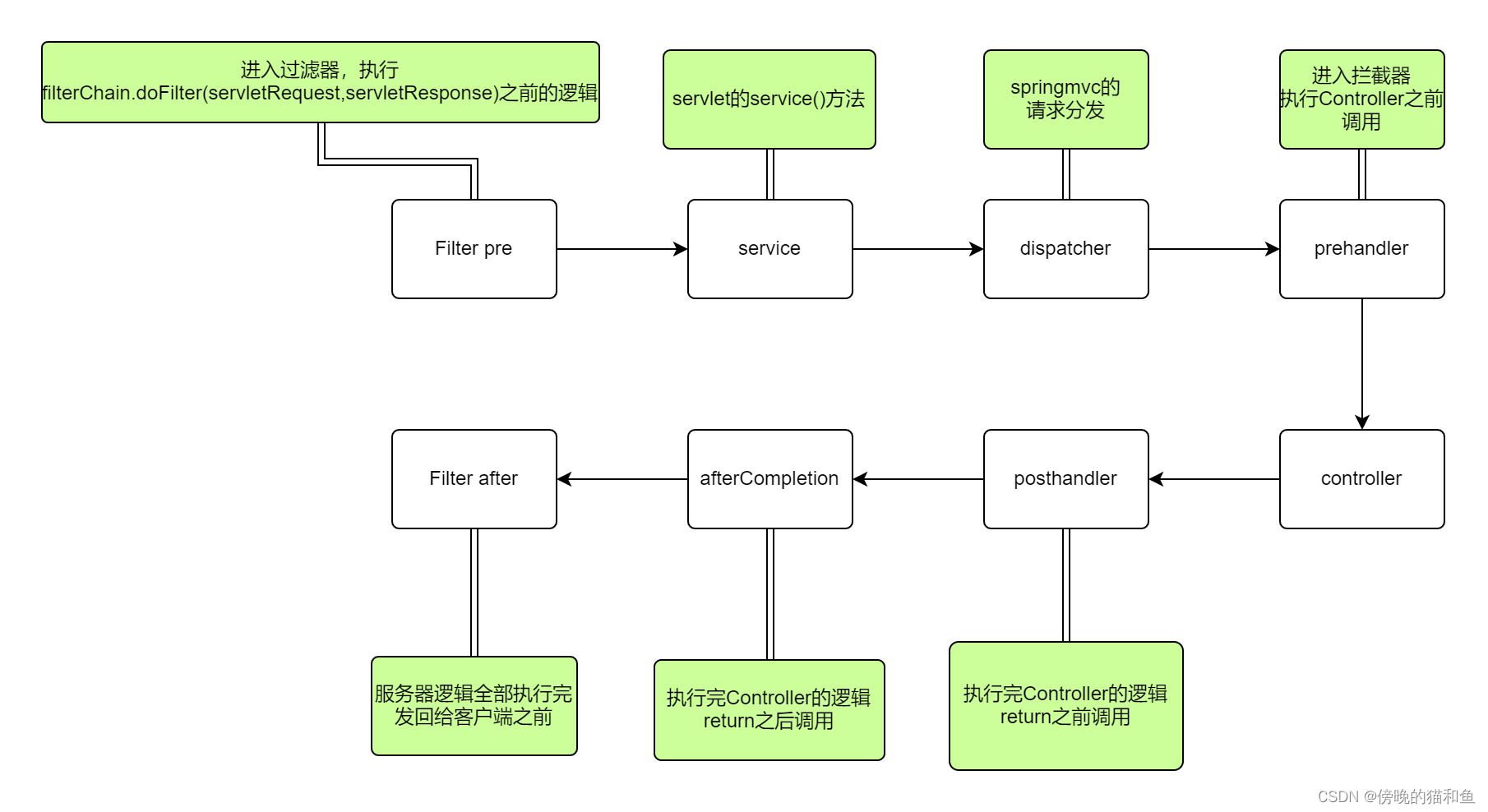
4.MySQL架构
MySQL 是一个可移植的数据库,可以在几乎所有操作系统上运行,但主要在 Linux 类似的服务器后端中运行
得益于优秀的分层设计,MySQL 能保证在各个平台运行时,物理体系结构的一致性,具体分层如下

图片来源:一文搞懂MySQL体系架构!!
大体可以分为三层
- 第一层:解决安全和连接管理
- 第二层:词法、语法分析以及
SQL语句优化 - 第三层:完成数据的存储方案
5.存储引擎
存储引擎是数据库系统如何存储数据、为存储的数据建立索引和更新、查询数据等技术的实现方法
MySQL 的核心就是 插件式存储引擎,支持多种存储引擎
5.1.查看存储引擎
MySQL 中可以选择使用不同的存储引擎,不同的存储引擎所带来的效果不同,可以理解为汽车引擎,V6、水平对置、W12、转子马达 之间还是有差异的
如何查看当前支持哪些存储引擎?
mysql> show engines;
如果觉得不方便查看,可以输入 mysql> show engines \G; 表示格式化显示

当前 MySQL 支持的存储引擎有很多,可以查看创建数据库时默认使用的存储引擎
vim /etc/my.cnf

这其实就是当时配置 my.cnf 时我们指定的存储引擎 InnoDB,也是 MySQL 中常用的存储引擎之一;也可以在表创建成功后,查看使用了哪个引擎
mysql> show create table T1;

创建表时,如果不指定,就使用 my.cnf 中的默认存储引擎,如果指定了,就使用用户指定的存储引擎,根据实际业务场景决定,非常灵活
5.2.存储引擎间的区别
| 存储引擎 | 事务支持 | ACID 兼容性 | 锁定级别 | 数据表类型 | 支持的索引类型 | 外键约束 | 全文搜索 | 备注 |
|---|---|---|---|---|---|---|---|---|
| InnoDB | 是 | 是 | 行级锁 | 事务表 | B+Tree、全文 | 是 | 是 | MySQL 默认存储引擎,适用于事务处理。 |
| MRG_MYISAM | 否 | 否 | 表级锁 | 非事务表 | BTree | 否 | 否 | 合并(合并式)存储引擎,不常用。 |
| MEMORY | 是 | 是 | 表级锁 | 临时表 | 哈希表 | 否 | 否 | 将数据存储在内存中,适用于临时数据。 |
| BLACKHOLE | 否 | 否 | 表级锁 | 非事务表 | 无 | 否 | 否 | 黑洞存储引擎,丢弃所有写入数据。 |
| MyISAM | 否 | 否 | 表级锁 | 非事务表 | BTree、全文 | 否 | 是 | 早期 MySQL 默认存储引擎,性能较快。 |
| CSV | 否 | 否 | 表级锁 | 非事务表 | 无 | 否 | 否 | 存储数据以逗号分隔值(CSV)格式。 |
| ARCHIVE | 否 | 否 | 表级锁 | 非事务表 | 无 | 否 | 否 | 用于存储归档数据,数据压缩比较高。 |
| PERFORMANCE_SCHEMA | 否 | 否 | 无锁定 | 系统表 | 无 | 否 | 否 | 用于性能监控和分析系统性能。 |
| FEDERATED | 是 | 是 | 表级锁 | 非事务表 | 无 | 是 | 否 | 用于访问远程数据库的存储引擎。 |
表格由 Chat-GPT 生成
存储引擎有很多,主要记住两个就行了:InnoDB 和 MyISAM,这两个数据库几乎覆盖了 80% 的业务场景,至于它俩的区别也很简单:
InnoDB适合需要事务支持、数据完整性和高并发性能的应用MyISAM可能适用于只读数据、全文搜索或特定用途的应用


![[MICROSAR Adaptive] --- Hello Adaptive World](https://img-blog.csdnimg.cn/4455584816014653a92c1ee87af203d7.png)