前言
如此前这篇文章《学术论文GPT的源码解读与微调:从chatpaper、gpt_academic到七月论文审稿GPT》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去,而如果涉及到论文的修订/审稿,则市面上已有的学术论文GPT的效果则大打折扣
原因在哪呢?本质原因在于无论什么功能,它们基本都是基于API实现的,而关键是API毕竟不是万能的,API做翻译/总结/对话还行,但如果要对论文提出审稿意见,则API就捉襟见肘了,故为实现更好的review效果,需要使用特定的对齐数据集进行微调来获得具备优秀review能力的模型
继而,我们在第一版中,做了以下三件事
- 爬取了3万多篇paper、十几万的review数据,并对3万多篇PDF形式的paper做解析
当然,paper中有被接收的、也有被拒绝的 - 为提高数据质量,针对paper和review做了一系列数据处理
- 基于RWKV进行微调,然因其遗忘机制比较严重,故最终效果不达预期
所以,进入Q4后,我司项目团队开始做第二版(我司目前总共在不断迭代三大LLM项目,除了论文审稿GPT之外,还有:AIGC模特生成系统、企业知识库问答),并着重做以下三大方面的优化
- 数据的解析与处理的优化,meta的一个ocr 能提取出LaTeX
- 借鉴GPT4做审稿人那篇论文,让ChatGPT API帮爬到的review语料,梳理出来 以下4个方面的内容
1 重要性和新颖性,2 论文被接受的原因,3 论文被拒绝的原因,4 改进建议 - 模型本身的优化,llama longlora或者mistral
第一部分 多种PDF数据的解析
1.1 Meta nougat
nougat是Meta推出的学术PDF解析工具,其主页和代码仓库分别为
- nougat主页
https://facebookresearch.github.io/nougat/ - nougat仓库
https://github.com/facebookresearch/nougat
对比下
- nougat比较好的地方在于可以把公式拆解成latex,很多模型底模会学习到latex的规则,会较之直接地希腊符号好些,另外就是识别出来的内容可以通过“#”符号来拆解文本段
缺陷就是效率很低、非常慢,拿共约80页的3篇pdf来解析的话,大概需要2分钟,且占用20G显存,到时候如果要应用化,要让用户传pdf解析的话,部署可能也会有点难度 - sciencebeam的话就是快不少,同样量级的3篇大约一分钟内都可以完成,和第一版用的SciPDF差不多,只需要cpu就可以驱动起来了
当然,还要考虑的是解析器格式化的粒度,比如正文拆成了什么样子的部分,后续我们需不需要对正文的特定部分专门取出来做处理,如果格式化粒度不好的话,可能会比较难取出来
// 待更
第二部分 第二版数据处理的优化:借鉴GPT4审稿的思路
2.1 斯坦福:让GPT4首次当论文的审稿人
近日,来自斯坦福大学等机构的研究者把数千篇来自Nature、ICLR等的顶会文章丢给了GPT-4,让它生成评审意见、修改建议,然后和人类审稿人给出的意见相比较
- 在GPT4给出的意见中,超50%和至少一名人类审稿人一致,并且超过82.4%的作者表示,GPT-4给出的意见相当有帮助
- 这个工作总结在这篇论文中《Can large language models provide useful feedback on research papers? A large-scale empirical analysis》,这是其对应的代码仓库
所以,怎样让LLM给你审稿呢?具体来说,如下图所示

- 爬取PDF语料
- 接着,解析PDF论文的标题、摘要、图形、表格标题、主要文本
- 然后告诉GPT-4,你需要遵循业内顶尖的期刊会议的审稿反馈形式,包括四个部分
成果是否重要、是否新颖(signifcance andnovelty)
论文被接受的理由(potential reasons for acceptance)
论文被拒的理由(potential reasons for rejection)
改进建议(suggestions for improvement) - 最终,GPT-4针对上图中的这篇论文一针见血地指出:虽然论文提及了模态差距现象,但并没有提出缩小差距的方法,也没有证明这样做的好处
2.2 为了让模型对review的学习更有迹可循:规划Review的格式很重要(需要做选取和清洗)
上一节介绍的斯坦福这个让GPT4当审稿人的工作,对我司做论文审稿GPT还挺有启发的
- 正向看,说明我司这个方向是对的,至少GPT4的有效意见超过50%
- 反向看,说明即便强如GPT4,其API的效果还是有限:近一半意见没被采纳,证明我司做审稿微调的必要性、价值性所在
- 审稿语料的组织 也还挺关键的,好让模型学习起来有条条框框 有条理 分个 1 2 3 4 不混乱
比如要是我们爬取到的审稿语料 也能组织成如下这4块,我觉得 就很强了,模型学习起来 会很快
1) 成果是否重要、是否新颖
2) 论文被接受的理由
3) 论文被拒的理由
4) 改进建议
对于上面的“第三大点 审稿语料的组织”,我们(特别是阿荀)创造性的想出来一个思路,即让通过提示模板让ChatGPT来帮忙梳理咱们爬的审稿语料,好把审稿语料 梳理出来上面所说的4个方面的常见review意见
那怎么设计这个提示模板呢?借鉴上节中斯坦福的工作,提示模板可以如下设计
// 待更
第三部分 从LongLora版LLaMA到Mistral
3.1 LongLora
longlora仓库
https://github.com/dvlab-research/LongLoRA
longlora中文资料
https://zhuanlan.zhihu.com/p/659226557
3.2 Mistral 7B:通过分组查询注意力 + 滑动窗口注意力超越13B模型
今年5月,DeepMind和Meta的三位前员工在巴黎共同创立了Mistral AI(其CEO Arthur Mensch此前在DeepMind巴黎工作,CTO Timothée Lacroix和首席科学家Guillaume Lample则在Meta共同参与过LLaMA一代的研发,很像当年OpenAI的部分员工出走成立Anthropic啊),今年10月,他们发布了第一个基座大模型,即Mistral 7B
据其对应的论文《Mistral 7B》称( 另,这是其GitHub地址)

- Mistral 7B在所有评估基准中均胜过了目前最好的13B参数模型(Llama 2),并在推理、数学和代码生成方面超越了发布的34B参数模型(Llama 34B)
Mistral 7B outperforms the previous best 13B model (Llama 2, [26]) across all testedbenchmarks, and surpasses the best 34B model (LLaMa 34B, [25]) in mathematics and codegeneration. - 该模型采用了分组查询注意力(GQA),GQA显著加快了推理速度,还减少了解码期间的内存需求,允许更高的批处理大小,从而提高吞吐量
GQA significantly accelerates the inference speed, and also reduces the memory requirement during decoding, allowing for higher batch sizes hence higher throughput - 同时结合滑动窗口注意力(slidingwindow attention,简称SWA)以有效处理任意长度的序列,
SWA is designed to handle longer sequences more effectively at a reduced computational cost
此外,作者提供了一个针对遵循指令进行了微调的模型,名为Mistral 7B-Instruct,它在人工和自动化基准测试中均超过了LLaMA 2 13B-chat模型
3.2.1 什么是滑动窗口注意力
vanilla attention的操作次数在序列长度上是二次型的,记忆量随着token数量线性增加。在推理时,由于缓存可用性的降低,这导致了更高的延迟和更小的吞吐量(The number of operations in vanilla attention is quadratic in the sequence length, and the memory increases linearly with the number of tokens. At inference time, this incurs higherlatency and smaller throughput due to reduced cache availability)
为了缓解这个问题,我们使用滑动窗口注意力(sliding window attention)

- 每个token最多可以关注来自上一层的W个token(论文中,W = 3)。请注意,滑动窗口之外的token仍然影响下一个单词预测
each token can attend to at most W tokens from the previous layer (here, W = 3). Note that tokensoutside the sliding window still influence next word prediction. - 在每个注意力层,信息可以向前移动W个token。因此,在k层注意力之后,信息最多可以向前移动k个×W个token
At each attention layer, information can moveforward by W tokens. Hence, after k attention layers, information can move forward by up to k ×W tokens.
3.2.2 Rolling Buffer Cache
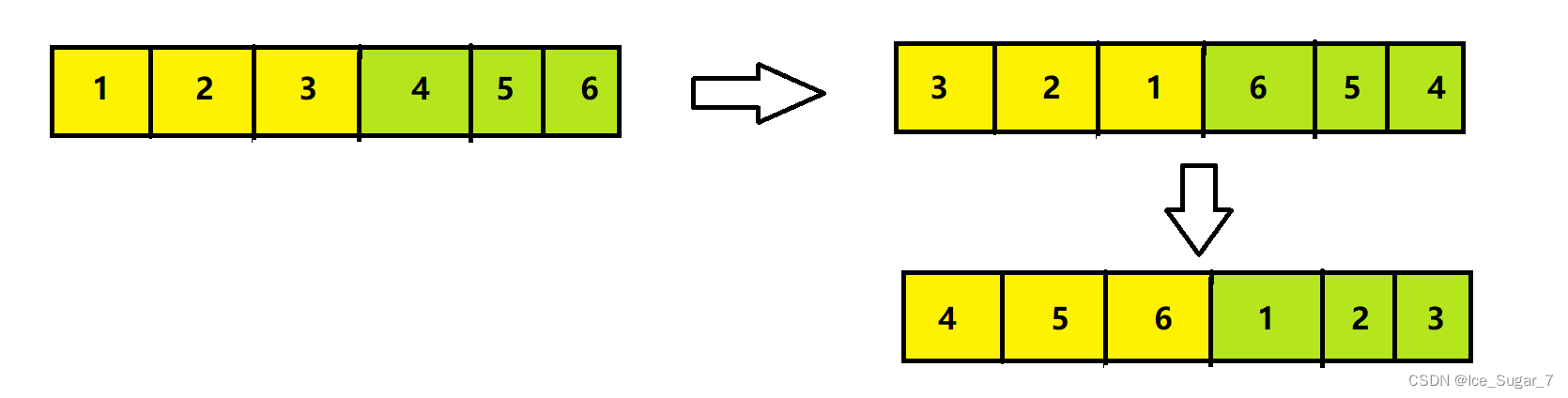
固定的注意力长度意味着我们可以使用滚动缓存来限制我们的缓存大小(A fixed attention span means that we can limit our cache size using a rollingbuffer cache)

- 缓存的大小是固定的W,时间步长i的键和值存储在缓存的位置i mod W中。因此,当位置i大于W时,缓存中过去的值就会被覆盖,缓存的大小就会停止增加
The cache has a fixed size of W, and the keys and values for the timestep i are storedin position i mod W of the cache. As a result, when the position i is larger than W, past valuesin the cache are overwritten, and the size of the cache stops increasing
以“The cat sat on the mat”为例..
当 i = 0 时,指The,0 mod 3=0
当 i = 1 时,指cat,1 mod 3=1
当 i = 2 时,指sat,2 mod 3=2
当 i = 3 时,指on,3 mod 3=0
当 i = 4 时,指the,4 mod 3=1
当 i = 5 时,指mat,5 mod 3 = 2 - 在32k token的序列长度上,这减少了8倍的缓存内存使用,而不影响模型质量
On a sequence length of 32k tokens, this reduces the cache memory usageby 8x, without impacting the model quality.
3.2.3 预填充与分块
在生成序列时,我们需要一个一个地预测token,因为每个token都以前面的token为条件。然而,prompt是提前知道的,我们可以用prompt预填充(k, v)缓存,即
- 如果prompt非常大,我们可以把它分成更小的块,用每个块预填充缓存。为此,我们可以选择窗口大小作为我们的分块大小。因此,对于每个块,我们需要计算缓存和块上的注意力
- 下图展示了注意力掩码在缓存和分块上的工作原理
在预填充缓存时,长序列被分块,以限制内存使用
我们把一个序列分成三个块来处理,“The cat sat on”,“the mat and saw”,“the dog go to”。上图中显示了第三块(“the dog go to”)发生的情况:它使用因果掩码(最右块)来关注自己,使用滑动窗口(中心块)来关注缓存,并且不关注过去的token,因为它们在滑动窗口之外(左块)
// 待更
参考文献与推荐阅读
- GPT4当审稿人那篇论文的全文翻译:【斯坦福大学最新研究】使用大语言模型生成审稿意见
- GPT-4竟成Nature审稿人?斯坦福清华校友近5000篇论文实测,超50%结果和人类评审一致
- 几篇mistral-7B的中文解读
从开源LLM中学模型架构优化-Mistral 7B
开源社区新宠Mistral,最好的7B模型 - Mistral 7B-来自号称“欧洲OpenAI”Mistral AI团队发布的最强7B模型
创作、修改、完善记录
- 11.2日,开写本文
- 11.3日,侧重写第二部分、GPT4审稿的思路
- 11.4日,侧重写第三部分中的Mistral 7B
- 11.5日,继续完善Mistral 7B的部分