Python等级考试(1~6级)全部真题・点这里
一、单选题(共25题,每题2分,共50分)
第1题
列表L1中全是整数,小明想将其中所有奇数都增加1,偶数不变,于是编写了如下图所示的代码。
请问,图中红线处,代码应该是?( )

A: x || 2
B: x ^ 2
C: x && 2
D: x % 2
答案:D
本题代码中,for x in L1 是在L1列表中循环,每次取出的值x交给if语句进行判断,如果除以2的余数不等于0,就是奇数,则x+1,若等于0则x
第2题
小明为了学习选择排序的算法,编写了下面的代码。针对代码中红色文字所示的一、二、三处,下面说法正确的是?( )
a = [8,4,11,3,9]
count = len(a)
for i in range(count-1):
mi = i
for j in range(i+1,count):
if a[mi] > a[j]: #代码一
mi = j #代码二
if i!=mi:
a[mi],a[i] = a[i],a[mi] #代码三
print(a)
A: 如果找到更大的元素,则记录它的索引号。
B: 如果找到更小的元素,则记录它的索引号。
C: 在一趟选择排序后,不管是否找到更小的元素,mi所在元素都得与i所在的元素发生交换。
D: 代码三所在的行必然要运行。
答案:B
在选择排序算法中,每次循环都会找到当前未排序部分中的最小元素,并将其与当前位置进行交换。代码一中的条件判断 a[mi] > a[j] 用于找到更小的元素,代码二中的赋值操作 mi = j 用于记录更小元素的索引号。因此,正确的说法是选择排序算法会记录找到更小元素的索引号。
第3题
小明编写了一段演示插入排序的代码,代码如下。请问红色“缺失代码”处,应该填写哪段代码?( )
a = [8,4,11,3,9]
count = len(a)
for i in range(1, count):
j = i
b = a[i]
while j>0 and b<a[j-1] :
a[j] = a[j-1]
缺失代码
a[j] = b
print(a)
A: j=j-1
B: j=j+1
C: j=i+1
D: j=i-1
答案:A
本题考查学生对插入排序算法的理解。当前位置数字需要通过循环,逐个与之前位置的数字进行比较,所以正确答案是A,j=j-1,用于下一次循环时,获取前一个数字。
第4题
在计算机中,信息都是采用什么进行存储?( )
A: 二进制数
B: 八进制数
C: 十进制数
D: 十六进制数
答案:A
计算机以二进制形式表示和存储数据,使用0和1两个数字来表示信息的状态。这是因为计算机内部使用的是电子电路,它的工作原理可以通过开关的打开和关闭来表示不同的状态,而二进制正好可以表示这两种状态。
第5题
十进制数(100)10,转化为二进制数为( )2?
A: 0010011
B: 1010001
C: 1100100
D: 0101100
答案:C
要将十进制数转换为二进制数,可以通过不断除以2并取余数的方式进行转换。具体步骤如下:
将十进制数100除以2,商为50,余数为0。
将商50再次除以2,商为25,余数为1。
将商25再次除以2,商为12,余数为1。
将商12再次除以2,商为6,余数为0。
将商6再次除以2,商为3,余数为0。
将商3再次除以2,商为1,余数为1。
将商1再次除以2,商为0,余数为1。
将上述余数从下往上排列,得到二进制数1100100。因此,十进制数(100)10 转化为二进制数为(1100100)2。
第6题
十六进制数每一位至多可以表示几位二进制位?( )
A: 2
B: 3
C: 4
D: 16
答案:C
十六进制数是一种基数为16的数制,使用0-9和A-F表示数。每一位十六进制数可以表示的二进制位数是4位。这是因为每个十六进制位对应的二进制位数是从0000到1111,共16种可能性。因此,每一位十六进制数可以表示4位二进制位。
第7题
八进制数(35)8,转化为十进制数为( ) 10?
A: 100011
B: 110001
C: 232
D: 29
答案:D
要将八进制数转换为十进制数,可以按照权重展开的方式计算。八进制数的每一位的权重是8的幂次,从右往左依次为0、1、2、3…。具体步骤如下:
将八进制数35的最右边一位(个位)的数值3乘以8的0次方(8^0),得到3。
将八进制数35的左边一位(十位)的数值5乘以8的1次方(8^1),得到40。
将步骤1和步骤2的结果相加,3 + 40 = 43。
因此,八进制数(35)8 转化为十进制数为(29)10。
第8题
执行代码a=min(3,2,4.3),变量a的值是?( )
A: 3
B: 2
C: 4.3
D: 4
答案:B
函数 min() 是Python内置函数,用于返回参数中的最小值。在这个例子中,min(3,2,4.3) 的参数是3、2和4.3,其中最小值是2。因此,变量 a 的值为2。
第9题
print(max(‘python+’))的运行结果是?( )
A: ‘p’
B: p
C: ‘y’
D: y
答案:D
函数 max() 会返回参数中的最大值。在这个例子中,max(‘python+’) 的参数是字符串 ‘python+’,其中最大值是字母 y。所以,print(max(‘python+’)) 的运行结果是字母 y。
第10题
a=5.12596
print(round(a,2))运行结果是?( )
A: 5
B: 5.1
C: 5.12
D: 5.13
答案:D
函数 round() 是Python内置函数,用于将数字进行四舍五入。在这个例子中,变量 a 的值是 5.12596。通过调用 round(a,2),将 a 四舍五入到小数点后两位。因此,运行结果是 5.13。
第11题
type([{2.6}])运行的结果是?( )
A: float
B: dict
C: True
D: list
答案:D
在这个例子中,[{2.6}] 是一个列表,包含一个字典元素 {2.6}。通过调用 type() 函数并传入该列表作为参数,可以获取该列表的类型。因此,运行结果是列表(list)。
第12题
执行如下代码
a=[1,2,3,4]
print(list(enumerate(a)))
运行结果是?( )
A: ((0, 1), (1, 2), (2, 3), (3, 4))
B: [(0, 1), (1, 2), (2, 3), (3, 4)]
C: [1,2,3,4]
D: (1,2,3,4)
答案:B
enumerate() 是Python内置函数,用于将可迭代对象的元素生成带有索引的枚举对象。在这个例子中,变量 a 是一个列表 [1,2,3,4]。enumerate(a) 会生成一个枚举对象,将 a 的每个元素和对应的索引组成元组,并以列表的形式返回。因此,运行结果是 [(0, 1), (1, 2), (2, 3), (3, 4)],其中每个元组表示元素在列表中的索引和对应的值。
第13题
set(‘hello’)运行结果是?( )
A: (‘h’, ‘e’, ‘l’, ‘l’,‘o’)
B: {‘h’, ‘e’, ‘l’, ‘l’,‘o’}
C: {‘e’, ‘h’, ‘l’, ‘o’}
D: (‘e’, ‘h’, ‘l’, ‘o’)
答案:C
set() 是Python内置函数,用于创建一个集合对象。在这个例子中,参数是字符串 'hello',set('hello') 会将字符串中的每个字符作为集合的元素,去除重复的元素,然后返回一个集合对象。因此,运行结果是 {'e', 'h', 'l', 'o'},表示包含字符串中所有字符的集合。注意,集合是无序的,所以元素的顺序可能会有所变化。
第14题
print(sum([5,10,min(7,4,6)]))的运行结果是?( )
A: 22
B: 21
C: 4
D: 19
答案:D
在这个例子中,[5, 10, min(7, 4, 6)] 是一个列表,包含三个元素:5、10和通过调用 min(7, 4, 6) 求得的最小值。其中,min(7, 4, 6) 的最小值是 4。然后,sum() 函数用于计算列表中所有元素的总和。所以,sum([5, 10, min(7, 4, 6)]) 的运行结果是 19,即 5 + 10 + 4 = 19。因此,答案是 D: 19。
第15题
divmod(100,3)的执行结果是?( )
A: (1, 33)
B: (33, 1)
C: [33,1]
D: [1,33]
答案:B
函数 divmod() 是Python内置函数,用于同时返回除法运算的商和余数。在这个例子中,divmod(100,3) 进行了100除以3的运算。商是33,余数是1。因此,执行结果是 (33, 1),其中第一个元素是商,第二个元素是余数。所以,答案是 B: (33, 1)。
第16题
下列表达式结果是False的是?( )
A: all({})
B: all([10])
C: all([‘1’,‘2’,‘3’,‘’])
D: all([‘1’,‘2’,‘3’])
答案:C
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 True,如果是返回 True,否则返回 False。 元素除了是 0、空、None、False 外都算 True。
第17题
将字符串或数字转换为浮点数的函数是?( )
A: chr()
B: float()
C: int()
D: str()
答案:B
float() 函数用于将整数和字符串转换成浮点数。
第18题
以下表达式的值为True是?( )
A: bool(2022)
B: bool(0)
C: bool()
D: bool({})
答案:A
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。bool({2022})中间有元素,所以为True。
第19题
有这样一段程序:
a=[“香蕉“,”苹果”,”草莓”,“哈密瓜”]
fs=open(“fruits.csv”,”w”)
fs.write(“,”.join(a)+‘\n’)
fs.close()
该段程序执行后,该csv文件中的内容是?( )
A: 香蕉 苹果 草莓 哈密瓜
B: 香蕉,苹果,草莓,哈密瓜
C: 香蕉苹果草莓哈密瓜
D: [“香蕉”,“苹果”,“草莓”,“哈密瓜”]
答案:B
open(“fruits.csv”,“w”)表示打开CSV文件,进行写入操作(“w"表示可覆盖写入)。”,“.join(a)表示将a列表中的元素取出,并用”,"连接成新的字符串,写入文件。
第20题
关于文件的读写操作,下列说法不正确的是?( )
A: read( )函数读取文件内容后,生成的是一个字符串 。
B: readline( )每次只读取文件中的一行,并返回字符串类型数据。
C: readlines( )函数每次按行读取整个文件的内容,并返回list类型数据。
D: 读取文件内容只能用reader( )对象。
答案:D
文件内容的读取可以视不同情况选择不同的函数,reader()也是其中之一。
第21题
关于下列列表,说法正确的是?( )
s=[ [“佩奇”,“100”,“86”,“85”,“90”],
[“苏西”,“78”,“88”,“98”,“89”],
[“佩德罗”,“80”,“66”,“80”,“92”]]
A: 这是一组二维数据
B: 这样的数据不能存储到CSV文件中
C: 无法读取[“佩奇”,“100”,“86”,“85”,“90”]这条数据
D: 必须手动写入到CSV文件中
答案:A
二维列表的每个元素本身也是列表。可通过循环读取元素并写入CSV文件。
第22题
有关于write()函数的说法正确的是?( )
A: write( )函数只能向文件中写入一行数据
B: write( )函数的参数不是字符串类型
C: write( )函数也可以向文件中写入多行数据
D: write( )函数和writelines( )函数完全相同
答案:C
write()函数可向文件中写入一行或多行数据。其参数必须为字符串,而writelines( )函数既可以传入字符串也可以传入一个字符序列,并写入文件。
第23题
对于在csv文件中追加数据,下列说法正确的是?( )
A: 只能以单行方式追加数据
B: 只能以多行方式追加数据
C: 多行数据追加的函数是writerow( )
D: 以单行方式或多行方式追加都可以
答案:D
在CSV中追加数据可以用writerow( )函数进行一行一行写入,也可以用writerows( )函数进行多行写入数据。
第24题
Python的异常处理try…except…else…finally机制中,以下哪部分语句一定能得到全部执行?( )
A: try子句
B: except子句
C: else子句
D: finally子句
答案:D
无论是否发生异常,finally 子句中的代码都会被执行。即使在 try 子句或 except 子句中遇到了 return 语句或抛出了新的异常,finally 子句仍然会得到执行。因此,答案是 D: finally子句。
第25题
Python的异常处理机制中,以下表述哪项是错误的?( )
A: 如果当try中的语句执行时发生异常,Python就执行匹配该异常的except子句。
B: 如果当try中的语句执行时发生异常,try代码块的剩余语句将不会被执行。
C: 如果在try子句执行时没有发生异常,Python将执行else语句后的语句。
D: 异常处理结构能够发现程序段中的语法错误。
答案:D
异常处理结构只能处理运行时错误(运行时异常),而不能捕获和处理语法错误。语法错误是指违反了Python语法规则的错误,例如拼写错误、缩进错误等。这些错误会导致程序无法正常运行,无法被异常处理机制捕获和处理。因此,异常处理机制不能发现程序段中的语法错误。所以,答案是 D: 异常处理结构不能发现程序段中的语法错误。
二、判断题(共10题,每题2分,共20分)
第26题
二进制数转化为十进制数的方法是:按权展开、逐项相加,如:(101)2=(10)10。( )
答案:错误
每个二进制位上的数字乘以相应的权值(2的幂),然后将它们相加,得到对应的十进制数。
(1 * 2^2) + (0 * 2^1) + (1 * 2^0)
= (4) + (0) + (1)
= (5)10
因此,(101)2 转化为十进制数为 (5)10,即 (101)2 = (5)10。
第27题
语句print(round(2.785, 2))运行后的结果是2.79。( )
答案:正确
round() 函数是Python内置函数,用于对数字进行四舍五入。在这个例子中,round(2.785, 2) 表示将数字 2.785 保留两位小数进行四舍五入。由于小数点后第三位是 5,根据四舍五入的规则,结果会向上取整为 2.79。
第28题
map() 不会根据提供的函数对指定序列做映射。( )
答案:错误
map() 会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
第29题
语句print(tuple(range(5)))的输出结果是(0, 1, 2, 3, 4)。( )
答案:正确
range() 函数是Python内置函数,用于生成一个整数序列。在这个例子中,range(5) 生成一个从 0 到 4(不包括 5)的整数序列。然后,tuple() 函数用于将这个整数序列转换为元组。所以,tuple(range(5)) 的结果是 (0, 1, 2, 3, 4),即包含从 0 到 4 的整数的元组。
第30题
运行语句set(‘2022’),其输出结果是{‘2’,‘0’,‘2’,‘2’} ( )
答案:错误
set() 函数用于创建一个集合对象,并且集合对象中的元素是唯一的,不允许重复。在这个例子中,参数是字符串 '2022',set('2022') 会将字符串中的每个字符作为集合的元素,去除重复的元素,然后返回一个集合对象。由于字符串 '2022' 中的字符 '2' 和 '0' 重复出现,集合中的元素就只包含了这两个字符。所以,set('2022') 的输出结果是 {'2', '0'},而不是 {'2', '0', '2', '2'}。因此,判断是不正确的。
第31题
f=open(‘ss.csv’,’r’)
n=f.read().strip(“\n”).split(“,”)
f.close()
这段代码的功能是读取文件中的数据到列表。( )
答案:正确
第32题
一维数组可以用列表实现,二维数组则不能用列表实现。( )
答案:错误
一维数组和二维数组都可以使用列表实现。
在Python中,列表是一种灵活的数据结构,可以容纳不同类型的元素,并且可以嵌套使用来表示多维数据结构。
一维数组可以用列表来表示,例如 [1, 2, 3, 4, 5] 就是一个一维数组的列表表示。
二维数组也可以用列表来表示,其中每个元素都是一个一维数组。例如 [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 就是一个二维数组的列表表示。
在Python中,可以通过索引来访问列表中的元素,因此可以使用列表来实现一维和二维数组的各种操作。
所以,判断是不正确的。一维数组和二维数组都可以用列表实现。
第33题
用with open (‘fruits.csv’,’r’)as f 语句,打开fruits.csv文件,在处理结束后不会自动关闭被打开的文件,因此需要写上f.close( )语句。( )
答案:错误
使用 with open('fruits.csv', 'r') as f 语句打开文件时,文件在处理结束后会自动关闭,不需要显式地调用 f.close() 来关闭文件。
with 语句是一种上下文管理器,用于管理资源的分配和释放。在这个例子中,打开文件 'fruits.csv' 并将文件对象赋值给变量 f。当代码块执行完毕或发生异常时,with 语句会自动关闭文件,释放相关的资源,无需手动调用 f.close()。
这种使用 with 语句来打开文件的方式更加简洁和安全,可以确保文件的正确关闭,即使在处理过程中出现异常也能够正常处理。
第34题
异常处理结构中,finally程序段中的语句不一定都会得到执行。( )
答案:错误
在异常处理结构中,finally 程序段中的语句一定会得到执行,无论是否发生异常。
不论在 try 子句中是否发生异常,finally 程序段中的代码都会被执行。即使在 try 子句中遇到了 return 语句或抛出了新的异常,finally 程序段仍然会得到执行。这是因为 finally 用于定义必须执行的清理代码,无论异常是否发生,都需要执行一些必要的操作,比如关闭文件或释放资源。
第35题
在计算机中,每一个二进制位可以表示0和1两种信息。( )
答案:正确
在计算机中,每个二进制位(bit)可以表示两种信息,即 0 和 1。二进制是一种基于2的数制系统,使用两个数字 0 和 1 来表示信息。计算机中的所有数据都以二进制形式存储和处理,其中每个二进制位都可以代表一个布尔值,即 0 或 1。
三、编程题(共3题,共30分)
第36题
下面程序实现对二维数据的处理,请你补全代码。
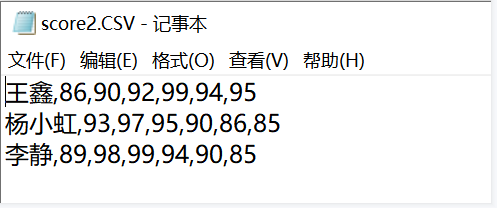
f=open('/data/score2.csv','r')
a=[]
for i in f:
a.append(i.strip().split(','))
f.close()
①
for i in a:
s=''
for j in i:
②
print(s)
程序执行结果为:
[['王鑫', '86', '90', '92', '99', '94', '95'], ['杨小虹', '93', '97', '95', '90', '86', '85'], ['李静', '89', '98', '99', '94', '90', '85']]
王鑫 86 90 92 99 94 95
杨小虹 93 97 95 90 86 85
李静 89 98 99 94 90 85
答案:
f = open('/data/score2.csv', 'r')
a = []
for i in f:
a.append(i.strip().split(','))
f.close()
print(a,'\n') # ①
for i in a:
s = ''
for j in i:
s += f'{j:<6}' # ②
print(s)
在代码的第①处,输出列表内容。
在代码的第②处,使用了字符串格式化和对齐操作,f'{j:<6}' 的意思是将变量 j 格式化为字符串,并使用左对齐方式占据 6 个字符的宽度。这样可以在输出时保持每个字段的对齐。
第37题
在三位数的自然数中,找出至少有一位数字是5的,至少能被3整除的所有整数,并统计个数,具体代码如下:
count=0
lst=[]
for i in range( ① ):
if i%3==0:
a=i%10
b=i//10%10
c= ②
if ③ :
count+=1
lst.append(i)
print("这样的三位数有:",lst)
print("总数量有:",count)
答案:
count = 0
lst = []
for i in range(100, 1000): # ①
if i % 3 == 0:
a = i % 10
b = i // 10 % 10
c = i // 100 # ②
if a == 5 or b == 5 or c == 5: # ③
count += 1
lst.append(i)
print("这样的三位数有:", lst)
print("总数量有:", count)
在代码的第①处,使用 range(100, 1000) 表示遍历三位数的范围,从 100 到 999。
在代码的第②处,通过整除运算可以得到三位数中百位的数字。
在代码的第③处,通过判断个位、十位、百位中是否有数字为 5 来筛选满足条件的数。
执行结果将输出满足条件的三位数列表和总数量。
第38题
输入一个正数,以下代码编程求出它的平方根。请你补全代码。
in_var = float(input("请输入一个需要开方的正数,可以使用2位小数:\n x = "))
if in_var < 0:
x = - in_var
else:
x = in_var
low = 0.0
high = x
s_root = ①
if x > 0 and x < 1:
high = 1.0
low = 0
s_root = ②
if x >= 0:
while abs( ③ ) > 0.0001:
if x > 1.0:
if s_root ** 2 < x:
low = s_root
else:
high = s_root
s_root = ④
if x == 1.0 and x == 0.0:
s_root = x
else:
if s_root ** 2 < x:
low = s_root
else:
high = s_root
s_root = ⑤
if in_var >= 0:
print("所求数的平方根为:s_root = %.1f"%(s_root))
答案:
in_var = float(input("请输入一个需要开方的正数,可以使用2位小数:\n x = "))
if in_var < 0:
x = -in_var
else:
x = in_var
low = 0.0
high = x
s_root = (low + high) / 2 # ①
if x > 0 and x < 1:
high = 1.0
low = 0
s_root = (low + high) / 2 # ②
if x >= 0:
while abs(s_root ** 2 - x) > 0.0001: # ③
if x > 1.0:
if s_root ** 2 < x:
low = s_root
else:
high = s_root
s_root = (low + high) / 2 # ④
if x == 1.0 and x == 0.0:
s_root = x
else:
if s_root ** 2 < x:
low = s_root
else:
high = s_root
s_root = (low + high) / 2 # ⑤
if in_var >= 0:
print("所求数的平方根为:s_root = %.1f" % (s_root))
在代码的第①、②、④、⑤处,使用二分法来逼近平方根的值。通过不断更新 low 和 high 的值,计算 s_root 的新值,直到满足指定的精度要求(这里设定为 0.0001)。
在代码的第③处,通过判断 s_root 的平方与 x 的差的绝对值是否小于指定的精度来决定是否继续迭代。
最后输出计算得到的平方根结果。