- 因为项目每次用到,每次重新搭都踩坑,特此记录一些坑,防止花费大量时间在搭建和整合上面
- 安装
准备好压缩包elasticsearch-6.2.4解压
- 在config文件夹下配置文件elasticsearch.yml,可更改自行喜欢的端口和配置账号密码
- 安装中文分词器
![]()
注意分词器版本要和elasticsearch一致
解压后的后的文件夹放入 ES 根目录下的 plugins 目录下,重启 ES 即可使用
Releases · medcl/elasticsearch-analysis-ik · GitHub
二、配置集群
3.1创建 elasticsearch-cluster 文件夹
在内部复制三个 elasticsearch 服务。
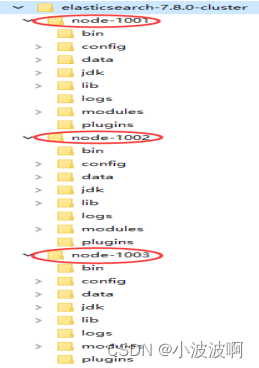
3.2修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
node-1001 节点
#节点 1 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1001
node.master: true
node.data: true
#ip 地址
#必须要指定ip,若localhost则只能本机访问
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"node-1002 节点
#节点 2 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1002
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1002
#tcp 监听端口
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"如果有必要,删除每个节点中的 data 目录中所有内容 。防止报错
3.3启动集群
分别依次双击执行节点的bin/elasticsearch.bat, 启动节点服务器(可以编写一个脚本启动),启动后,会自动加入指定名称的集群。
3.4测试集群
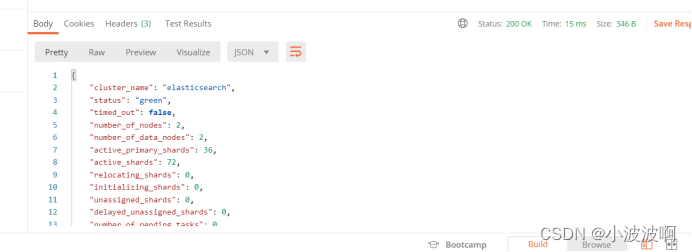
一、用Postman,查看集群状态
GET http://127.0.0.1:1001/_cluster/health
GET http://127.0.0.1:1002/_cluster/health
GET http://127.0.0.1:1003/_cluster/health
若有返回则成功
三、分片
四、springboot集成
1.首先在pom.xml添加maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<!--<version>2.2.6.RELEASE</version>-->
<!--这里可不具体版本,会自动按照springboot版本注入合适版本-->
</dependency>版本要求具体看官方
Spring Data Elasticsearch - Reference Documentation
2.在springboot配置文件添加
有两种方式
第一种是通过tcp 9300端口连接,这种springboot版本和elasticsearch版本比较兼容
Spring.data.elasticsearch.repositories.enabled= true
Spring.data.elasticsearch.cluster-nodes= 127.0.0.1:9300
Spring.data.elasticsearch.cluster-name= elasticsearch
这种方式用的是ElasticSearchTemplate
另一种是通过http方式
Spring.elasticsearch.rest.uris= 172.0.11.121:9201
这种方式用的是 ElasticSearchRestTemplate
这种方式,对springboot和elasticsearch的版本必须要符合官方要求
若项目中含有redis依赖
则在启动类添加
System.setProperty("es.set.netty.runtime.available.processors","false");不使用es的netty,使用redis的。
3.需要存入数据到es的实体类需要添加注解
@Document(indexName = "shopping", shards = 3, replicas = 1,type="product")
//indexName相当于数据库的库名,type 相当于表名
public class Product {
//必须有 id,这里的 id 是全局唯一的标识,等同于 es 中的"_id"
@Id
private Long id;//商品唯一标识
/**
* type : 字段数据类型
* analyzer : 分词器类型
* index : 是否索引(默认:true)
* Keyword : 短语,不进行分词
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title;//商品名称
@Field(type = FieldType.Keyword)
private String category;//分类名称
@Field(type = FieldType.Double)
private Double price;//商品价格
@Field(type = FieldType.Keyword, index = false)
private String images;//图片地址
}4.配置类
ElasticsearchRestTemplate是spring-data-elasticsearch项目中的一个类,和其他spring项目中的 template类似。
在新版的spring-data-elasticsearch 中,ElasticsearchRestTemplate 代替了原来的ElasticsearchTemplate。
原因是ElasticsearchTemplate基于TransportClient,TransportClient即将在8.x 以后的版本中移除。所以,我们推荐使用ElasticsearchRestTemplate。
ElasticsearchRestTemplate基于RestHighLevelClient客户端的。需要自定义配置类,继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法,创建RestHighLevelClient对象。
- 需要自定义配置类
继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法,创建RestHighLevelClient对象。
import lombok.Data;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
@ConfigurationProperties(prefix = "elasticsearch")
@Configuration
@Data
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration{
private String host ;
private Integer port ;
//重写父类方法
@Override
public RestHighLevelClient elasticsearchClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(host, port));
RestHighLevelClient restHighLevelClient = new
RestHighLevelClient(builder);
return restHighLevelClient;
}
}- DAO 数据访问对象
import com.lun.model.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ProductDao extends ElasticsearchRepository<Product, Long>{
}- crud操作
import com.lun.dao.ProductDao;
import com.lun.model.Product;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESProductDaoTest {
@Autowired
private ProductDao productDao;
/**
* 新增
*/
@Test
public void save(){
Product product = new Product();
product.setId(2L);
product.setTitle("华为手机");
product.setCategory("手机");
product.setPrice(2999.0);
product.setImages("http://www.atguigu/hw.jpg");
productDao.save(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//修改
@Test
public void update(){
Product product = new Product();
product.setId(2L);
product.setTitle("小米 2 手机");
product.setCategory("手机");
product.setPrice(9999.0);
product.setImages("http://www.atguigu/xm.jpg");
productDao.save(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//根据 id 查询
@Test
public void findById(){
Product product = productDao.findById(2L).get();
System.out.println(product);
}
@Test
public void findAll(){
Iterable<Product> products = productDao.findAll();
for (Product product : products) {
System.out.println(product);
}
}
//删除
@Test
public void delete(){
Product product = new Product();
product.setId(2L);
productDao.delete(product);
}
//POSTMAN, GET http://localhost:9200/product/_doc/2
//批量新增
@Test
public void saveAll(){
List<Product> productList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Product product = new Product();
product.setId(Long.valueOf(i));
product.setTitle("["+i+"]小米手机");
product.setCategory("手机");
product.setPrice(1999.0 + i);
product.setImages("http://www.atguigu/xm.jpg");
productList.add(product);
}
productDao.saveAll(productList);
}
//分页查询
@Test
public void findByPageable(){
//设置排序(排序方式,正序还是倒序,排序的 id)
Sort sort = Sort.by(Sort.Direction.DESC,"id");
int currentPage=0;//当前页,第一页从 0 开始, 1 表示第二页
int pageSize = 5;//每页显示多少条
//设置查询分页
PageRequest pageRequest = PageRequest.of(currentPage, pageSize,sort);
//分页查询
Page<Product> productPage = productDao.findAll(pageRequest);
for (Product Product : productPage.getContent()) {
System.out.println(Product);
}
}
}- 复杂查询搜索操作
import com.lun.dao.ProductDao;
import com.lun.model.Product;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESSearchTest {
@Autowired
private ProductDao productDao;
/**
* term 查询
* search(termQueryBuilder) 调用搜索方法,参数查询构建器对象
*/
@Test
public void termQuery(){
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");
Iterable<Product> products = productDao.search(termQueryBuilder);
for (Product product : products) {
System.out.println(product);
}
}
/**
* term 查询加分页
*/
@Test
public void termQueryByPage(){
int currentPage= 0 ;
int pageSize = 5;
//设置查询分页
PageRequest pageRequest = PageRequest.of(currentPage, pageSize);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");
Iterable<Product> products =
productDao.search(termQueryBuilder,pageRequest);
for (Product product : products) {
System.out.println(product);
}
}
}封装api
:ElasticsearchTemplate的使用 - 简书