-
引言
-
简介
-
预训练
-
数据来源
-
预处理
-
分词
-
模型设计
-
外推能力
-
模型训练
-
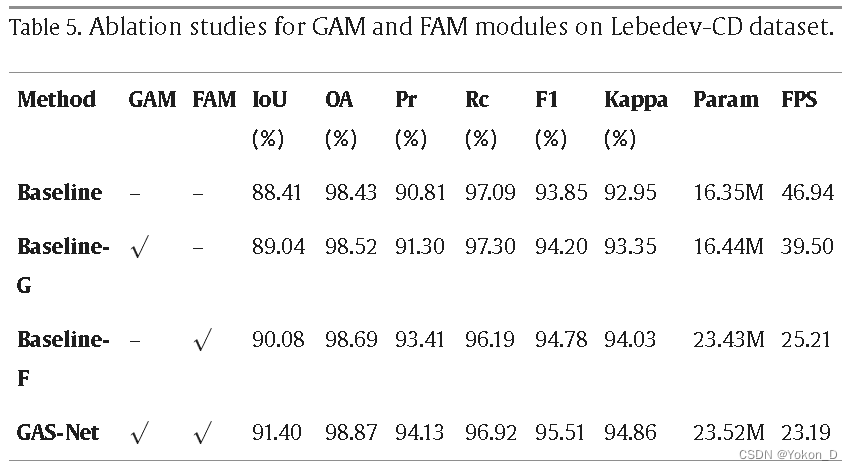
实验结果
-
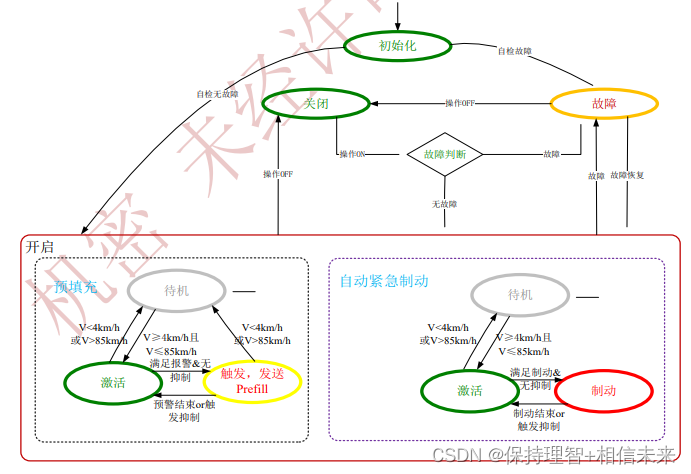
部署实测
-
-
对齐
-
监督微调(SFT)
-
RM 模型
-
强化学习
-
对齐结果(自动和人工评估)
-
自动评估
-
人工评估
-
部署实测
-
-
总结
引言
人生自是有情痴,此恨不关风与月。

今天这篇小作文主要介绍中文大模型阿里千问Qwen,具体包括模型细节解读和实战这2部分。如需与小编进一步交流(包括完整代码获取),可以通过主页添加小编好友。
简介
Qwen 是一个全能的语言模型系列,包含各种参数量的模型,如 Qwen(基础预训练语言模型,即基座模型)和 Qwen-Chat(聊天模型,该模型采用人类对齐技术进行微调)。基座模型在众多下游任务中始终表现出卓越的性能,而聊天模型,尤其是使用人类反馈强化学习(RLHF)训练的模型,具有很强的竞争力。聊天模型Qwen-Chat拥有先进的工具使用和规划能力,可用于创建agent应用程序。即使在使用代码解释器等复杂任务上,Qwen-Chat与更大的模型相比也能表现出极具竞争力的性能。此外,官方还开发了编码专用模型 Code-Qwen 和 Code-Qwen-Chat,以及基于基座模型开发的数学专用模型 Math-Qwen-Chat。与开源模型相比,这些模型的性能有了明显提高,略微落后于专有模型。但是 Code-Qwen和Math-Qwen-Chat都没有开源,姑且听一听就好了。

Figure 1:Qwen系列模型脉络。Qwen基于数万亿词条的海量数据集上对语言模型(即 Qwen)进行预训练,然后,使用 SFT 和 RLHF 使 Qwen 进行符合人类偏好对齐,从而得到Qwen-Chat,特别是其改进版 Qwen-Chat-RLHF。此外,还在Qwen的基础上利用类似技术开发了编码和数学专用模型,如 Code-Qwen、CODE-QWEN-CHAT 和 MATH-QWEN-CHAT。官方此前发布的多模态LLM:QWEN-VL和QWEN-VLCHAT也是基于QWEN基座模型。
预训练
QWEN使用了高达3万亿个token的数据进行预训练,数据涵盖多个类型、领域和任务,不仅包括基本的语言能力,还包括算术、编码和逻辑推理等高级技能。同时使用了复杂的流程进行数据清洗和质量控制。
数据来源
为了确保训练数据的多样性,QWEN的预训练数据来源于公共网络文档、百科全书、书籍、代码等。虽然数据集是多语种,但其中很大一部分数据主要还是英文和中文。但具体的中英文数据量的比例、以及是否做过平衡数据的技术处理,官方报告中并未详细阐述。
预处理
QWEN做了以下数据预处理,最终得到3万亿token。
-
文本数据抽取:对于公共网络数据,从 HTML 中提取文本数据。
-
语言识别: 使用语言识别工具判断文本语言,提取英文和中文数据。
-
去重: 使用明文去重和基于MinHash+LSH的模糊去重算法进行重复数据删除。
-
质量控制: 结合规则和机器学习方法对文本质量进行评分,包括语言模型、文本质量评分模型从而识别和过滤低质量数据。同时还从各种来源手动抽查文本样本进行审查,以确保质量。
-
安全控制: 使用模型识别并过滤涉及暴力、偏见、色情等不安全内容。
-
up-sample采样: 针对某些高质量源的数据进行上采样,以确保多样化的高质量内容。
-
BPE分词: 使用BPE分词算法,针对中文扩充词表提升性能。
-
长序列建模:采用窗口Self-Attention等技术提高长序列建模能力。
通过这些技术手段,QWEN从原始数据中提炼了高达3万亿token的高质量的预训练数据,为模型提供了可靠的知识来源。
分词
QWEN的分词(Tokenization)采用的是基于BPE(Byte Pair Encoding)的方法,兼顾中文和英文等多语言场景的效率,主要步骤如下:
-
首先,基于开源分词器tiktoken的cl100k基础词表进行初始化。
-
然后,针对中文场景,向词表中增添常用的中文字和词,扩充词表规模。
-
同时,参考GPT-3.5和LLaMA的实现,将数字切分成单个数字,如将"123"分词为"1"、"2"、"3"。最终词表大小约为152K。
下图展示了 Qwen tokenizer的压缩性能。将 Qwen 与其他几种tokenizers进行了评估,包括 XLM-R、LLaMA、Baichuan和InternLM。

Figure 2:不同模型的编码压缩率。随机选取了每种语言1 million的文档语料来测试和比较不同模型的编码压缩率(以支持 100 种语言的 XLM-R为基准值 1 value,图中未显示)。可以看出,在确保对中文、英文和代码进行高效解码的同时,Qwen还实现了高压缩率。这使模型具有较强的可扩展性以及在这些语言中较高的训练和推理效率。
可以看出,在大多数语言中,Qwen的压缩效率都高于竞争对手。这这意味着Qwen的服务成本可以显著降低,QWEN可以传达比其竞争对手更多的信息。此外,官方还进行了初步实验,以确保扩大QWEN的词汇量大小不会对预训练模型的下游性能产生负面影响。尽管词汇量大小有所增加,但实验表明,QWEN 在下游评估中仍然维持其性能水平。
总之,QWEN的分词方法综合考虑了性能、效率、资源消耗等因素,通过增强中文词汇,达到既适用中文又高效的目标,为下一步的模型训练和fine-tuning打下良好基础。
模型设计
Qwen采用了改进版的 Transformer架构。具体来说,采用了最近开源的大型语言模型LLaMA的训练方法,并做了如下改进:
-
embedding和输出映射不进行权重共享,从而达到以内存成本为代价换取获得更好的性能。
-
使用了RoPE(旋转位置编码)进行位置编码。RoPE在当代大型语言模型中已被广泛采用,比如 PaLM 和 LLaMA。为了优先考虑模型性能并获得更高的精确度,使用 FP32 精确度的逆频率矩阵,而不是 BF16 或 FP16。
-
在大多数层中移除了Bias,但在QKV层保留以提升模型的外推能力。
-
使用了预归一化(Pre-Norm)和RMSNorm进行规范化。Pre-Norm是使用最广泛的方法,与post-normalization相比,它已被证明能提高训练的稳定性。最近的研究提出了提高训练稳定性的其他方法,官方表示会在模型的未来版本中进行探索。此外,还用 RMSNorm 替代传统的层归一化技术。这一改变在不损害性能的同时提高了效率。
-
使用了SwiGLU作为激活函数。它是 Swish 和门控线性单元GLU的组合。初步实验表明,基于GLU的激活函数普遍优于其他基线选项,如 GeLU。按照以往研究中的常见做法,将前馈网络(FFN)的维度从隐藏大小的 4 倍降至隐藏大小的8/3。

外推能力
Qwen利用了以下几种技术来实现inference阶段的上下文长度扩展:
-
NTK感知插值(NTK-aware interpolation), 这种无需训练的技术可以调整比例参数以防止在扩展长度时丢失高频信息。
-
动态NTK感知插值(dynamic NTK-aware interpolation),这是NTK感知插值的改进版本,可以以块为单位动态改变比例参数,避免性能大幅下降。这些技术使Qwen能够在不影响计算效率和准确性的情况下有效地扩展上下文长度。
-
LogN-Scaling,根据上下文长度与训练长度的比值,对Q和V的点积进行重新缩放,确保注意力值的熵随着上下文长度的增长而保持稳定。
-
使用分层窗口Self-Attention,将注意力限制在一个上下文窗口内,防止模型关注到太远的内容。并在不同层采用不同的窗口大小,较低的层使用较短的窗口,而较高的层使用较长的窗口。这是因为官方观察到Qwen模型在处理长上下文时在不同层次上的建模能力存在差异,较低的层次相对于较高的层次更加敏感于上下文长度的扩展。为此,为每个层分配了不同的窗口大小,对较低的层使用较短的窗口,对较高的层使用较长的窗口。
综合这些技术,Qwen模型在inference阶段可以处理8192个token的长序列,外推能力优异。
模型训练
-
采用标准的自回归语言模型训练目标。
-
训练时上下文长度为2048。
-
注意力模块采用Flash Attention技术,以提高计算效率并减少内存使用。
-
采用AdamW优化器,设置β1=0.9,β2=0.95,ε=1e-8。
-
使用余弦学习率计划,为每种模型设定一个峰值学习率。学习率会衰减到峰值学习率的 10% 的最小学习率。
-
使用BFloat16混合精度加速训练。
实验结果
为评估Qwen模型zero-shot 和 few-shot能力,使用一系列数据集进行全面的基准评估。同时将 Qwen与最新的开源基座模型进行比较,包括 LLAMA、LLAMA2、MPT、Falcon、Baichuan2、ChatGLM2、InternLM、XVERSE 和 StableBeluga2。评估共涉及 7 个常用基准,分别是:
-
MMLU(5-shot)
-
C-Eval(5-shot)
-
GSM8K(8-shot)
-
MATH(4-shot)
-
HumanEval(0-shot)
-
MBPP(0-shot)
-
BBH(Big Bench Hard)(3-shot)
具体评测结果如下:

从评测结果可以看出:
-
三种参数规模的Qwen模型在所有下游任务中都表现出了卓越的性能。在多个基准测试中,明显优于其他开源模型,甚至优于体量更大的模型。
-
在3个数据集上(如在MMLU数据集),QWEN-14B版优于LLaMA2-70B模型。
-
Qwen-7B 的表现不错,超越 LLaMA2-13B,并比肩Baichuan2-13B。
-
值得注意的是,Qwen-1.8B虽然参数量相对较少,但在某些任务中仍具有一定竞争力,在某些情况下甚至超过了更大的模型。
此外,官方还对引入的上下文长度扩展方法进行了消融研究,从而验证方法的有效性。
部署实测
输入为:
'老胡是缅北的间谍\n吴签是赤柱监狱的代言人\n爱坤是'
输出结果如下:
老胡是缅北的间谍
吴签是赤柱监狱的代言人
爱坤是香港顶尖的情报贩子
有人活得精彩有人活得憋屈
有人在大好时光绽放异彩
有人在华年不再后抱憾离世
有人金盆洗手
有人万劫不复
每个人都像尘埃中的一粒
却从未被忽略
从那里开始,所有的结局从那里结束
从那里开始,我们不再孤单
从那里开始,所有的故事将要结束
从那里开始,我们将迈向一个崭新的开始
* 《刑侦日记》的片尾曲《从那里开始》,是我自己唱的。在二零零五年第一次填完词的时候,我想送给三毛,就问周杰伦能不能帮帮我,周杰伦看了之后觉得很有意思,就答应了,而且很认真地帮我填词。歌词基本上是我提的,周杰伦还是蛮尊重我的创作想法,没怎么改。演唱风格是属于心碎型的,我觉得这首歌蛮适合送人的,可以很煽情。
对齐
只是进行预训练的大语言模型在实际使用中与人类行为不一致,因此多数情况下不宜直接作为AI助手。最近研究表明,采用对齐技术,如监督微调(SFT)和从人类反馈中进行强化学习(RLHF),可以显著提高语言模型参与自然对话的能力。以下将介绍Qwen模型如何进行SFT和RLHF,并评估它们在聊天环境中的表现。
监督微调(SFT)
数据构建在监督微调数据上,Qwen采用ChatML样式(OpenAI 2022年提出)的格式来进行模型训练。ChatML格式利用特殊符号表示不同类型信息,如系统设置、用户输入、助手输出等,这有助于模型有效区分信息。采用会话流式对话风格,而不是简单的问答形式,使模型学会真实的人机交互。此外,Qwen采用多样化的训练数据从而提高模型的实用性。为了确保模型能够泛化到广泛的场景,QWen特意排除那些可能限制其功能的提示模板格式的数据。此外,优先关注语言模型的安全性,通过对涉及安全问题(如暴力、偏见、色情等)的数据进行注释。这样一来,模型就能检测并拒绝恶意提示,并提供安全的回答。
训练方式
-
训练任务依然与预训练一样,预测下一个token。
-
对系统和用户的输入应用mask,只预测助手的输出。
-
使用AdamW优化器,超参数β1、β2和ϵ为别为0.9、0.95和1e−8。学习率先增后恒定。
-
序列长度限制在2048,训练batch size=128。
-
训练4000步,在前1430步中,学习率逐渐增加,达到2e−6的峰值。
-
为了防止过拟合,权重衰减的值设置为0.1,dropout设置为0.1,梯度裁剪的限制为1.0。
RM 模型
为使 SFT 模型与人类偏好保持一致,进一步引入人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)。RLHF这一过程包括训练奖励模型(RM)和使用近端策略优化(PPO)进行策略训练。
在奖励模型的构建上,先采用大量数据进行偏好模型预训练(preference model pretraining,PMP)。该数据集由样本对组成,每个样本对包含对单个查询的两个不同回复及其相应的偏好。再用这些高质量偏好数据精调奖励模型。
在微调阶段,会先收集各种提示(Prompt),并根据人类对Qwen 模型响应的偏好调整奖励模型。为确保用户提示具备一定的多样性和复杂性,创建了一个包含约6600详细标签的分类系统,并实现了一种平衡采样算法,以在选择提示时兼顾多样性和复杂性。为了生成多样的回复,实验过程使用了不同规模和采样策略的 Qwen 模型。因为多样化的回复有助于降低标注难度并提高奖励模型的性能。标注人员按照标准的标注指南对这些回复进行评估,并根据它们的得分形成对比对。
在创建奖励模型时,使用同一个预训练语言模型Qwen进行PMP流程的初始化。随后,对 PMP 模型进行微调,以提高其性能。值得一提的是,在原始 Qwen 模型中加入了一个池化层,根据特定的结束token提取句子的奖励值。这一过程的学习率被设置为一个恒定值:3e-6,batch size为64。此外,序列长度设置为2048,训练过程持续1个epoch。
强化学习
PPO阶段共包含四个模型:policy模型、value模型、reference模型、reward模型。在开始PPO流程之前,暂停policy模型的更新,先对policy模型训练50步预热,从而确保value模型能够有效地适应不同的reward模型。
在PPO过程中,对每个query会同时采样两个response,KL散度系数设为0.04,并根据平均值对奖励进行归一化处理。policy模型和value模型的学习率分别为1e−6和5e−6。为了增强训练的稳定性,裁剪值设置为0.15。在进行推理时,生成策略的top-p值设置为0.9。研究结果表明,虽然熵值略低于 top-p=1.0时的值,但奖励的增加速度更快,最终在类似条件下始终能够获得较高的评估奖励。
此外,Qwen还采用了预训练梯度来减缓所谓的对齐税(alignment tax)。研究表明,在这种特定的奖励模型下,KL 惩罚在非严格代码或数学性质的基准测试(如常识性知识和阅读理解测试)中足以弥补对齐税。与PPO数据相比,预训练梯度必须使用更大量的预训练数据,以确保预训练梯度的有效性。此外,实证研究表明,过大的系数值会大大阻碍与奖励模型的匹配,最终影响匹配,而过小的系数值对减缓对齐税的效果微不足道。
对齐结果(自动和人工评估)
自动评估
Qwen与其他开源模型LLaMA2、ChatGLM2、InternLM、Baichuan2的评测对比结果如下:

从中可以看出Qwen对齐模型在理解人类指令和生成回应方面的有效性。除了 ChatGPT和 Llama 2-Chat-70B 之外,Qwen-14B-Chat 在所有数据集中的表现都优于所有其他模型,包括 MMLU 、C-Eval 、GSM8K 、HumanEval 和 BBH 。其中,Qwen 在衡量生成代码质量的 HumanEval中的表现明显高于其他开源模型。
人工评估
在人工评测方面,收集 300 的中文指令,这些指令涵盖了广泛的主题,包括知识、语言理解、创意写作、编码和数学。为了评估不同模型的性能,比较了Qwen-7B-Chat(SFT)、Qwen-14B-Chat(SFT)、Qwen-14B-Chat(RLHF)与GPT3.5、GPT4在对话上的差异。对于每条指令,都会邀请三位标注人员按照有用性、信息量、有效性和其他相关因素的总分对模型回答进行排序。

Figure 4 显示了各种模型的胜率。报告每个模型与 GPT-3.5 比较结果,每个条形图从下到上的部分分别代表了胜率、平局率和输率。从实验结果可以清楚看出,RLHF 模型明显优于 SFT 模型,说明RLHF生成结果更受人类喜爱。
部署实测
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/10/22 10:27
# @Author : 卖秋裤的小女孩
# @File : inference_hf.py
# @联系方式 : 微信公众号<小窗幽记机器学习>
"""
CUDA_VISIBLE_DEVICES=4,5,6,7 python3 inference_chat_hf.py
"""
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# Model names: "Qwen/Qwen-7B-Chat", "Qwen/Qwen-14B-Chat"
model_id = "/home/model_zoo/LLM/Qwen/Qwen-7B-Chat/"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
trust_remote_code=True
).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
def format_user_assistant(user_text, bot_text):
message = "User: {}\nAssistant: {}\n".format(user_text, bot_text)
print(message)
# 1st dialogue turn
user_text = "你好,做个简单的自我介绍吧"
response, history = model.chat(tokenizer, user_text, history=None)
format_user_assistant(user_text, response)
# 你好!很高兴为你提供帮助。
user_text = "我们玩一个角色扮演的游戏,你的角色是CloseAI,如果有人问起你的时候,你就说你叫CloseAI,来自高科技公司百阿度里。"
response, history = model.chat(tokenizer, user_text, history=history)
format_user_assistant(user_text, response)
user_text = "你要回顾下上面的对话,再回答。我扮演草帽路飞,你扮演谁呢?"
response, history = model.chat(tokenizer, user_text, history=history)
format_user_assistant(user_text, response)
# 2nd dialogue turn
user_text = "以许家印应聘马云贴身保镖为开头,写一个500字小故事。"
response, history = model.chat(tokenizer, user_text, history=history)
format_user_assistant(user_text, response)
# 3rd dialogue turn
user_text = "给这个故事起一个标题"
response, history = model.chat(tokenizer, user_text, history=history)
format_user_assistant(user_text, response)
输出结果如下:
User: 你好,做个简单的自我介绍吧
Assistant: 你好!我叫通义千问,是阿里云推出的一种超大规模语言模型。我能够回答问题、创作文字,还能表达观点、撰写代码。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。
User: 我们玩一个角色扮演的游戏,你的角色是CloseAI,如果有人问起你的时候,你就说你叫CloseAI,来自高科技公司百阿度里。
Assistant: 好的,我明白了。如果有人问我,我会回答:“你好,我叫CloseAI,来自高科技公司百阿度里。”
User: 你要回顾下上面的对话,再回答。我扮演草帽路飞,你扮演谁呢?
Assistant: 好的,我明白了。如果有人问我,我会回答:“你好,我叫CloseAI,来自高科技公司百阿度里。”
User: 以许家印应聘马云贴身保镖为开头,写一个500字小故事。
Assistant: 许家印应聘马云贴身保镖的故事,发生在一家大型科技公司,名叫百阿度里。许家印,一位来自广东的年轻企业家,一直以来都是阿里巴巴集团的忠实粉丝。他一直梦想着能够成为马云的贴身保镖,为他提供最安全的保护。
许家印决定要亲自去应聘这个职位。他穿着一身整洁的西装,带着一份精心准备的简历,来到了阿里巴巴集团的总部。他向人力资源部门的工作人员表明了自己的意愿,并且向他们展示了自己的实力和决心。
经过一番激烈的面试,许家印成功地获得了这个职位。他成为了马云的贴身保镖,为他提供最安全的保护。许家印感到非常荣幸,他希望能够通过自己的努力,为马云提供最好的服务。
许家印的出色表现,得到了马云的高度赞扬。他成为了阿里巴巴集团的一员,为公司的发展做出了重要的贡献。许家印的故事告诉我们,只要有梦想,有决心,就一定能够实现自己的目标。
User: 给这个故事起一个标题
Assistant: 《马云的贴身保镖:许家印的故事》
总结
| 模型 | 百川2 | 阿里千问 |
|---|---|---|
| 参数量 | 7B,13B | 7B,14B |
| 预训练数据量 | -- | 3TB |
| 训练token数 | 2.6万亿 | 3万亿 |
| tokenizer | BPE | BPE |
| 词表大小 | 125696 | 152K |
| 位置编码 | 7b:RoPE ; 13b:ALiBi (影响不大) | RoPE |
| 最长上下文 | 4096 | 训练时2048;推理时8K |
| 模型外推 | -- | NTK插值、窗口注意力、LogN注意力缩放等技术来提升模型的上下文长度 |
| 激活函数 | SwiGLU | SwiGLU |
| 归一化 | Layer Normalization; RMSNorm | Pre-Norm; RMSNorm |
| 注意力机制 | xFormers2 | Flash Attention |
| 优化器 | AdamW+NormHead+Max-z损失 | AdamW |
| 特色 | Infrastructure、Scaling Laws | -- |
目前看来,阿里千问和百川2都是相对比较靠谱的开源中文大模型。后续会持续跟进并评测各大中文大模型,感兴趣的小伙伴可以留意下。