将要做什么事的介绍
近期博客写了少了,是因为近小半年来我正在打造一款可私布在企业内部并结合企业自有领域(零售商超先行)数据的智能导购引擎。截止目前为止还算顺利,并且我将很快将在中国本土的一家生鲜百货超市上线这一款生成式AI,帮助用户改善购物体验提升效率。
这可能是中国第一款采AIGC技术的电商产品,它能根据你的文字提示,自动为你生成购物建议、搜索建议和评论摘要等。

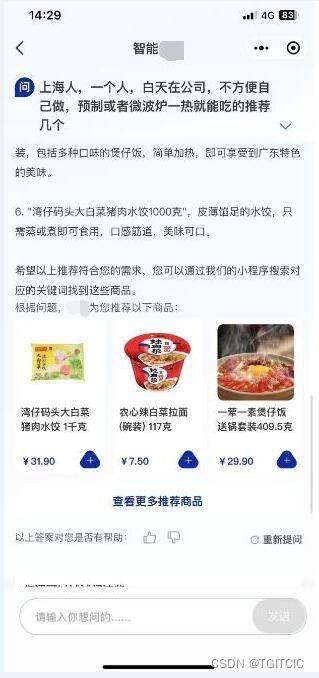
举个例子,假如你告诉它:“我想吃水果,但是我不喜欢太甜,糖分高的就算了。”这时,这款AI就会立马为你解析各种水果的糖分含量,然后根据你的需求,为你推荐平台上的低糖水果。
如果你对某个产品感兴趣,还可以继续深入询问,比如:“这个苹果的糖分含量是多少?”这样一来,你就可以省去大量的搜索和比较时间,让购物变得更加轻松高效。
值得一提的是,全球电商巨头亚马逊也在试验类似的功能,这足以看出,生成式AI在电商领域的应用前景十分广阔,已经得到了业界巨头的认可。 说实话,这款AI就像你的私人购物助手,不仅能帮你省时省力,还能帮你做出更科学的选择。
是什么激发了灵感
本人自身所处新零售领域,也接触到了不少圈内人士。在去年GPT刚出现时,大家谈到过一个话题。说:
在双11,想给自己的妻子、孩子、好友买点东西!可是买什么好呢?传统的购买就是自己在网上狂搜一把或者到处听别人PUA、推销。
但是,经常有人会有一种:我不知道具体要买什么,但是我有一个购买的愿镜、愿望。我希望可以有一个搜索把这样的愿望实现成一个个的物品加入到我的购物篮中就好。
亦或者看到一个桌上摆着的色香味俱全的菜,但是它是如何做出来的呢?用的是哪些具体的成份?它的步骤是什么?
这显然不是现在的任何电商购物网站、APP可以做得到的。因为当你把这样的愿望输入相关的搜索,你得到的结果大多为0。
基于这样的愿望、述求式的搜索,诞生了这么一个点子。
过程是很“磨难”的
愿望是美好的、过程的确很艰幸。首先要解决的是如何把一个通用的大模型去和一个特有的业务领域有机的结合起来。
在2023年年初,随着GPT的一火再火。我们可以看到很多大厂的元老纷纷“下海”创业大模型,一时间大模型如雨后春笋一般到处开花。
可是,我们一直没有发觉一款真正的和某一个具体的领域、业务结合应用的实际业务场景。绝大部分都是在讲一些原理,而用来跑业务领域的到写这篇博文为止还都是在跑GIT上那个著名的“奥运会数据”sample。
因此当一个企业“烧”掉了大量的成本而结果只跑了一个“奥运会数据”或者是说可以喂入“维基百科”的内容或者说只是实现了一个“客服”功能而己。这对一个企业来说显然是不公平的。
但是经过一段时间的摸索,我们还是找到了这样的一种有机结合。在这个过程中解决了大量之前未知和己知未解决的问题,很多技术点连博客、论文都没有更不要说相关案例来作参考了,我们纯粹是在摸着石头过河。
企业的数据是私有模型的关键
要做一个私有领域的智能AI,数据的质量是很重要的,特别是企业自身元数据的重新梳理整理归纳上显得很重要。数据质量直接决定了这样的特有领域AI最终的反应是否近人情、会人意,再说了通俗点,就是我们希望它是一款“接地气的AI”。
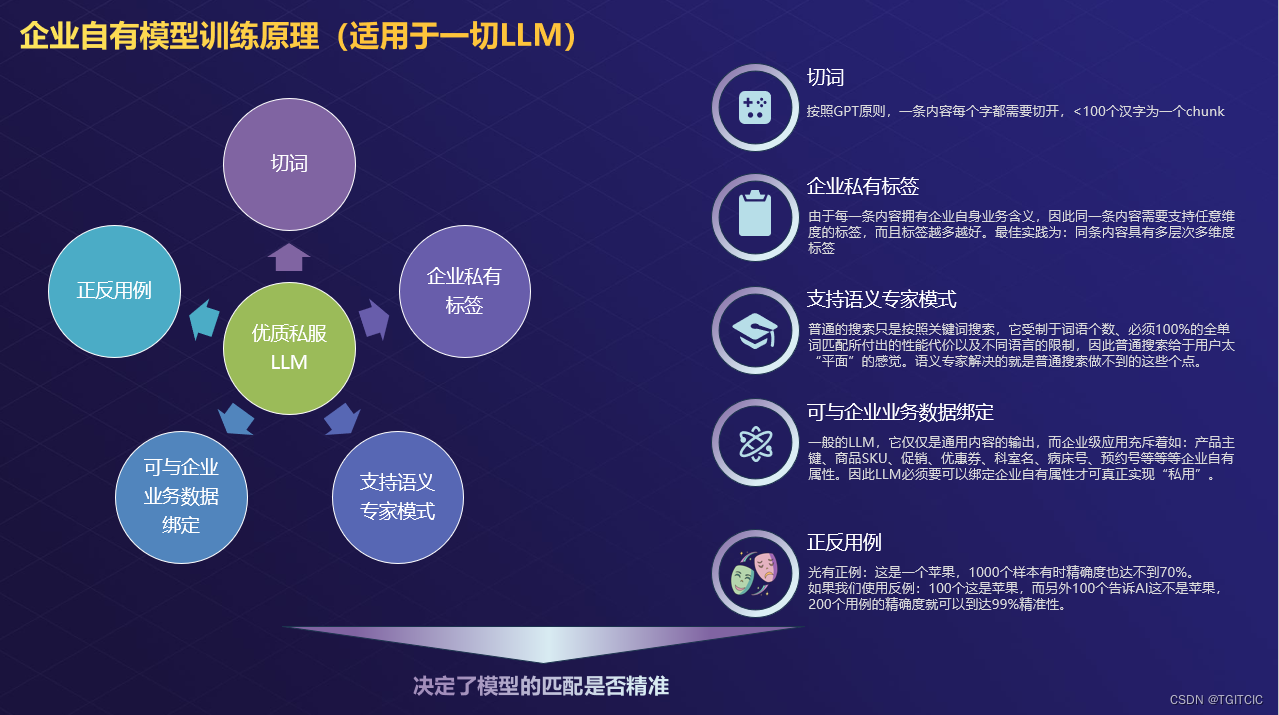
在集成企业自有模型时,这种集成不能再使用传统的行列维度以及传统的BI、大数据去考虑这个模型的建模和梳理方案论。而是需要使用“语义”分析、神经网络的概念去思考这么一个重整企业原有数据维度的问题。
拿一个未梳理好的企业数据来结合AI后的反例说明问题
反例
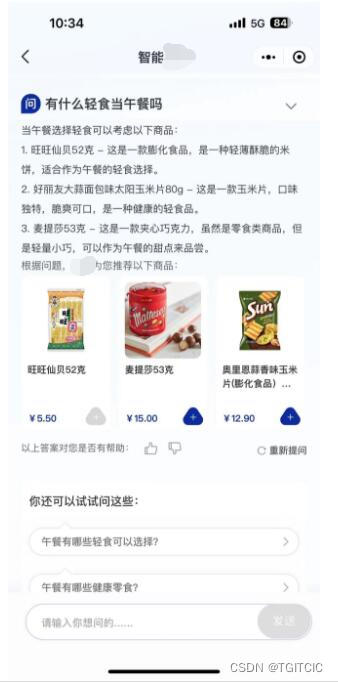
上例我们可以看到一个按照传统关系型数据库建模的数据,给到AI后在AI最终跑到TO C端表现出来的回答也是不符合要求的。
正例
而一个梳理良好的企业私有数据模型在AI最终表现出来的效果如下

拿一个零售领域的数据来做例子:

我们知道例如:2.5公斤车厘子这一类属于规格维度,我们把它称为第一维度。
在这一维度就有可能会扩展出6位数其它维度出来,甚至还可以自由扩展亦或者可以让AI自我完善、学习来自行扩展这一维度。
而第二维度的:商品基本属性也不是固定的。
第三个维度就是:业务场景或者又称为“活动场景”是我们经常用来做一些大促、促销、地推活动定义的,它也可以是任意扩展、翻新、甚至淘汰过时不用了,这都不可能是背后的人去一个个定义它们的。
在这三个维度即:规格->基本属性->场景间,我们假设三个维度一交错,那么这个数据量会以亿为单位,它们彼此间的关联不一定每一个都是强关联,也不可能用人脑和现有技术去做这个关联,这3个维度的关联如果用线来表示恐怕比繁星的数量还多。
因此一个质量好的企业私有数据模型必须要可以支持这种关系,这种关系我们把它称为“语义相关”或者用GPT现出后的一个耳熟能详的名词,即:涌现。
就是要让AI去自我扩展和关联而不是人为的去做这个“打标动作”,包括“前AI”我是把AIGC出现前的任何AI归为了“前AI时代”的那种“人为打标”。就拿上面这三个维度来说,就算是你有足够的人手去打标,你要打多少标?这让我想起了阿凡提回答“你能说一下我的头发有多少根”的那个问题了。
超长上下文以及本土化的工具集成的问题
支持超长上下文
无论是GPT还是CLAUDE还是GLM6B亦或是其它,都无法逃脱上下文长度这个“梗”。在训练和使用企业私有模型问题上,我们就碰到了这个问题。
即:我们的切实需要是可以让一个AI无限轮和一个人、或者一个系统对话下去同时又不能抛弃掉对话的完整度。
对于这个问题,网上目前能解决的唯有:ChatPDF。翻遍资料、论坛甚至论文,无解决方案。而ChatPDF的方案又只是一个开源免费仅供作为hello world级别的Sample,是无法商用的。
在这一问题上我们付出了巨大的心思并最终成功独创出了一套解决方案。目前这套解决方案无论是在效率还是准确率以及上下文相关联性来说远超过了ChatPDF。
本土化电商工具的集成心路
我们都知道我国自有本土化电商特别是O2O如:饿了么、美团、支付宝内的本地生活口碑网小程序、APP、WeChat等种类繁多。
由于前文我说到的,目前国内还无一例把一个LLM去和具体某个领域集成起来的方案,所以都以为只要做成API不就可以和之前一样对接了吗?
这样的想法在方案一开始落地时“害”了我们,我们为此也付出了两次推翻原有方案重写引擎的惨痛教训。好在我们有着极大的韧性+耐心,最终,我们也实现了首个可以和国内本土化电商模式工具集成的方案,没有之一,只有唯一。
整个方案可私布在企业内部
作为一个“有责任心的AI模型”,企业的数据是企业珍贵的资产,我们有责任保护好企业的数据不泄漏、不出境。
同时我们还在模型层做足了安全的功课、先后报备、申报、等保3、安全扫描、内容过滤保护是整个方案可以落地的保证。
如果我们把一个可以集成企业私有数据的模型的实现视作一座大山,这座山目前还无一例“登顶”的案例,那么“安全”相关课题可以看作是登天。
只有作一个“有责任”的AI,才能深受客户的信任,要不然这不是在帮客户了而是害客户。
展望一下未来
随着和企业的深入集成,在图搜图-图搜文-文搜图以及其它多媒体领域我们都在实现国内很多首个突破。
该方案上线在即。当它落地后我们还将探索更多的AI与TO B端深入结合的场景。我把我的个人宗旨定位为:积极拥抱生成式AI、并创新式的赋能各To B领域。
未来,随着AI技术的不断发展和深入应用,我们的生活将变得越来越智能,越来越便捷。
如我在之前的一系列博客中所述,随着国家对六大支柱产业的定义未来无限可能,程序员大有可为。一切在于“要转型、要转身快”。
未来无限可能,拥抱AI使人“年轻”。让我们一起拥包AI积极的投入到伟大祖国的建设领域中来吧。
![[iOS开发]iOS中TabBar中间按钮凸起的实现](https://img-blog.csdnimg.cn/c1d165277d964a16a5c86362ad8e9250.png)