
Python等级考试(1~6级)全部真题・点这里
一、单选题(共25题,每题2分,共50分)
第1题
十六进制数100,对应的十进制数为 ?( )
A: 128
B: 256
C: 28
D: 56
答案:B
考查学生将十六进制数转为十进制数。本质上就是int(‘100’,16),答案为256。
第2题
下图代码中,问号处应该填写的答案是哪个?( )

A: “9”
B: 9
C: “10”
D: 10
答案:D
hex() 函数用于将10进制整数转换成16进制。本题中答案为十进制数10,不能加引号。
第3题
下列4个表达式中,答案不是整数6的是?( )
A: abs(-6)
B: int(6.88)
C: round(5.55)
D: min(float(6),9,8,7)
答案:D
考查学生对内置数值处理函数的理解。abs()是取绝对值,int()默认会取整,round()四舍五入,float()会把整数转为浮点数,min()获取列表中的最小值,所以,上列4个表达式,只有选项D的答案是6.0浮点数,不是整数6
第4题
min()函数用于获取参数中的最小值,如果 a = min(‘654’) ,请问下面表达式中,正确的是哪一个?( )
A: print(max(chr(a),3,2))
B: print(max(bin(a),3,2))
C: print(max(float(a),3,2))
D: print(max(hex(a),3,2))
答案:C
本题考查学生对常用编码与数制函数的理解与掌握,正确答案选C 。因为 min(‘654’) 得到的是一个字符,而chr()、bin()、hex()三个函数的参数都必须是整数,所以唯一正确的是选项C ,float()函数可以将字符转换成浮点数。
第5题
对于CSV格式数据文件,下列描述错误的是?( )
A: CSV文件使用逗号分隔值。
B: CSV文件的扩展名为.CS。
C: CSV格式是一种通用的,相对简单的文件格式。
D: “记事本”和“Excel”可直接读入和保存CSV格式文件。
答案:B
CSV文件的扩展名通常是.csv,而不是.cs。所以选项B描述是错误的。
第6题
下列程序将建立一个CSV格式文件,划线处正确的代码选项应该为?( )
a=['老虎','狗','大象','牛']
f=open('动物.CSV',______)
f.write(','.join(a)+'\n')
f.close()
A: ‘W’
B: ‘R’
C: ‘w’
D: ‘r’
答案:C
在给定的程序中,我们需要以写入模式打开文件,因此正确的代码选项是C: ‘w’。选项A: 'W’是错误的,因为Python中的文件模式是区分大小写的。选项B: 'R’和选项D: 'r’是用于读取模式的,不适用于此情况。所以,正确的代码选项是C: ‘w’。
第7题
动物.CSV的文件内容如下:‘老虎’, ‘狗’, ‘大象’, ‘牛’,下列程序从该CSV文件读出数据,并输出列表格式,划线处正确的代码选项应该为?( )
f=open('动物.CSV','r')
a=f.read().strip().split(______)
f.close()
print(a)
A: ‘,’
B: ‘,’
C: ‘\n’
D: ‘\t’
答案:B
在给定的程序中,我们需要使用逗号作为分隔符将CSV文件的内容拆分为列表。因此,正确的代码选项是B: ‘,’。选项A: ‘,‘是错误的,因为逗号的英文字符是’,’,而不是’,'。选项C: '\n’表示换行符,不适用于这种情况。选项D: '\t’表示制表符,也不适用于这种情况。所以,正确的代码选项是B: ‘,’。
第8题
下面程序生成CSV格式文件:
王鑫,86,90,92,99,94,95
杨小虹,93,97,95,90,86,85
李静,89,98,99,94,90,85
程序如下:
a=[['王鑫','86','90','92','99','94','95'],['杨小虹','93','97','95','90','86','85'],['李静','89','98','99','94','90','85']]
f=open('成绩.CSV','w')
for i in a:
f.write(','.join(i)+______)
f.close()
划线处的代码应该为?( )
A: ‘r’
B: ‘w’
C: ‘\t’
D: ‘\n’
答案:D
CSV格式结果换行,所以选D。
第9题
一个“成绩.CSV”文件(用“记事本”打开)如下:
王鑫,86,90,92,99,94,95
杨小虹,93,97,95,90,86,85
李静,89,98,99,94,90,85
下面程序执行结果是?( )
f=open('成绩.CSV','r')
a=[]
for i in f:
a.append(i.strip().split(','))
f.close()
print(a)
A: [[‘王鑫’, ‘86’, ‘90’, ‘92’, ‘99’, ‘94’, ‘95’], [‘杨小虹’, ‘93’, ‘97’, ‘95’, ‘90’, ‘86’, ‘85’], [‘李静’, ‘89’, ‘98’, ‘99’, ‘94’, ‘90’, ‘85’]]
B: [[‘王鑫’, ‘86’, ‘90’, ‘92’, ‘99’, ‘94’, ‘95\n’], [‘杨小虹’, ‘93’, ‘97’, ‘95’, ‘90’, ‘86’, ‘85\n’], [‘李静’, ‘89’, ‘98’, ‘99’, ‘94’, ‘90’, ‘85\n’]]
C: [[‘王鑫,86,90,92,99,94,95’], [‘杨小虹,93,97,95,90,86,85’], [‘李静,89,98,99,94,90,85’]]
D: [‘王鑫,86,90,92,99,94,95\n’, ‘杨小虹,93,97,95,90,86,85\n’, ‘李静,89,98,99,94,90,85\n’]
答案:A
在给定的程序中,我们首先打开名为"成绩.CSV"的文件,并使用循环遍历文件中的每一行。我们使用strip()方法去除每一行的换行符,并使用split(‘,’)方法根据逗号将每一行拆分为列表。拆分后的列表被添加到名为"a"的列表中。最后,我们关闭文件并打印列表"a"的内容。
程序的执行结果是一个包含每一行数据的列表,每一行数据又是一个以逗号分隔的子列表。每个子列表表示一行记录的不同字段。
第10题
猜一个2022以内的随机数,用计算机解决该问题,比较合适的算法?( )
A: 二分查找算法
B: 解析算法
C: 枚举算法
D: 冒泡排序算法
答案:A
第11题
现在一组初始记录无序的数据’8,9,5,2,1’,使用冒泡算法,按从小到大的顺序排列,则第三轮排序的结果为?( )
A: [8,5,2,1,9]
B: [2,1,5,8,9]
C: [5,2,1,8,9]
D: [1,2,8,9,5]
答案:B
根据冒泡排序按从小到大的顺序第一轮应是[8, 5, 2, 1, 9],第二轮是[5,2,1,8,9],第三轮是[2,1,5,8,9]
第12题
有如下列表a=[3,5,35,74,1,28,7],采用选择排序算法进行升序排序,请问第三轮排序之后的结果是?( )
A: [1,3,5,35,74,28,7]
B: [1,3,5,7,28,35,74]
C: [1,3,5,74,35,28,7]
D: [1,3,5,7,35,74,28]
答案:C
选择排序算法的工作原理是从未排序的部分中选择最小的元素,并将其放置在已排序部分的末尾。在每一轮排序中,选择排序算法会找到未排序部分的最小元素,并将其与未排序部分的第一个元素交换位置。根据这个过程,我们来看第三轮排序之后的结果。
初始列表:[3, 5, 35, 74, 1, 28, 7]
第一轮排序后:[1, 5, 35, 74, 3, 28, 7]
第二轮排序后:[1, 3, 35, 74, 5, 28, 7]
第三轮排序后:[1, 3, 5, 74, 35, 28, 7]
第13题
程序运行过程中出现的错误或意外,不包括以下选项?( )
A: 语法错误
B: 电脑不好
C: 运行错误
D: 逻辑错误
答案:B
程序运行过程中可能出现的错误或意外包括语法错误、运行错误和逻辑错误。语法错误是指程序中存在语法规则违反的错误,导致程序无法正常编译或解释。运行错误是指程序在运行时发生的错误,如变量未定义、除以零等。逻辑错误是指程序在逻辑上存在错误,导致程序输出与预期不符。
然而,电脑性能不好并不是程序运行过程中出现的错误或意外,它只是可能影响程序运行速度或性能的因素之一。
第14题
关于Python在处理程序异常时,下列说法不正确的是?( )
A: 每一个try模块只能设定一个except模块
B: 执行except模块部分,可以让程序继续运行
C: 程序有错误时执行except中的代码,没有错误时执行try中的代码
D: 异常处理可以弥补程序漏洞,使得程序在一些情况下不会终止运行。
答案:A
可以设定多个except模块,以处理不同的错误。
第15题
divmod()函数的功能是用来求模和计算余数。对应变量x和y,divmod(x,y)返回的结果是以下哪一项?( )
A: (x//y, x%y)
B: (x/y, x%y)
C: (x%y, x//y)
D: (x%y, x/y)
答案:A
函数divmod(x, y)返回一个包含两个值的元组,第一个值是x除以y的整数商(向下取整),第二个值是x除以y的余数。
第16题
bool()函数用于将给定参数或表达式转换为布尔类型,以下使用了bool()函数的实例中,哪项返回True值?( )
A: bool(0)
B: bool( )
C: bool(1515+1414<420)
D: bool(-1)
答案:D
布尔函数bool()将非零的整数值转换为True。因此,bool(-1)的结果是True。
其他选项的结果是:
A: bool(0)的结果是False,因为0被视为False值。
B: bool()函数在没有参数的情况下返回False。
C: bool(1515+1414<420)的结果是False,因为表达式的结果为False。
第17题
查看对象的属性和属性值等信息,可以使用以下哪种函数?( )
A: vars()
B: dir()
C: help()
D: map()
答案:A
vars()函数用于返回对象的属性和属性值的字典。它接受一个对象作为参数,并返回一个包含该对象所有属性和属性值的字典。这个函数可以用于查看对象的属性和属性值,包括实例变量、实例方法以及从其类继承的属性和方法。
第18题
round(20/3) 的返回值是以下哪一项?( )
A: 6
B: 2
C: 7
D: 1
答案:C
当除法运算的结果进行四舍五入时,round()函数会根据最接近的整数来返回结果。在这种情况下,20除以3的结果是6.666666666666667,四舍五入后的整数是7。因此,round(20/3) 的返回值是7。
第19题
语句sorted([9,6,8,2,5],reverse = True)的返回结果是以下哪一项?( )
A: [2,5,6,8,9]
B: [9,6,8,2,5]
C: [9,8,6,5,2]
D: [0]
答案:C
sorted()函数用于对可迭代对象进行排序,默认情况下按升序排序。通过设置reverse=True参数,可以将排序顺序反转为降序。
在这个例子中,给定的列表是[9, 6, 8, 2, 5],通过sorted()函数进行降序排序后的结果是[9, 8, 6, 5, 2]。因此,选项C是正确的。
第20题
执行语句"{1}{0}“.format(“中国”, “加油”,”!"),输出结果是以下哪一项?( )
A: ‘中国加油!’
B: ‘加油中国!’
C: ‘中国加油’
D: ‘加油中国’
答案:D
在format()方法中,大括号中的数字表示要插入的参数的索引位置。在这个例子中,“{1}“表示插入第二个参数,也就是"加油”,”{0}“表示插入第一个参数,也就是"中国”。因此,输出结果为’加油中国’。
第21题
关于语句float(2022)与float(‘2022’)运行后的输出结果,以下哪一项正确?( )
A: 均为2022
B: 均为2022.0
C: float(2022)的输出为2022,float(‘2022’)运行后出错
D: float(2022)的输出为2022.0,float(‘2022’)运行后出错
答案:B
在Python中,float()函数用于将参数转换为浮点数。当整数作为参数传递给float()函数时,它会将整数转换为相应的浮点数。同样地,当字符串表示一个有效的浮点数时,它也可以被转换为浮点数。
在这个例子中,float(2022)将整数2022转换为浮点数,输出结果为2022.0。同样地,float(‘2022’)将字符串’2022’解析为浮点数2022.0。
第22题
语句max([(1,2),(2,3),(3,4),(2,5)])运行后的输出结果是以下哪一项?( )
A: 5
B: (2,5)
C: (4,5)
D: (3, 4)
答案:D
max()函数用于返回给定可迭代对象中的最大值。在这个例子中,给定的可迭代对象是包含元组的列表。max()函数将根据元组的第一个元素进行比较,并返回具有最大第一个元素的元组。
在给定的列表中,(1,2)、(2,3)、(3,4)和(2,5)是四个元组。它们的第一个元素分别是1、2、3和2。其中,(3,4)具有最大的第一个元素3,因此输出结果为(3, 4)。
第23题
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列。下列程序
example = '7890'
for i,j in enumerate(example):
print(i,j)
运行后的输出打印结果为以下哪一项?( )
A:
0,0
1,7
2,8
3,9
B:
0,7
1,8
2,9
3,0
C:
0 0
1 7
2 8
3 9
D:
0 7
1 8
2 9
3 0
答案:D
enumerate()函数会将可遍历的数据对象与索引组合成一个序列,并在每次迭代时返回索引和对应的元素。在这个程序中,可遍历的数据对象是字符串’7890’。
在循环中,enumerate(example)会返回索引和元素的元组。通过for i, j的赋值语句,索引被赋值给变量i,元素被赋值给变量j。
在每次迭代中,print(i, j)将索引i和元素j打印出来。由于字符串’7890’中的元素是逐个遍历的,输出结果为选项D
第24题
关于all()函数的用法,以下语句中能够返回True值的是哪一项?( )
A: all(0)
B: all([0])
C: all([0,1,2])
D: all([‘0’,‘1’,‘2’])
答案:D
第25题
如果要设计班级通讯录管理功能,需要往address.csv文件中追加新记录,则应该使用以下哪一种打开文件的方式?( )
A: open(‘address.csv’,‘a+’)
B: open(‘address.csv’,‘w+’)
C: open(‘address.csv’,‘wb+’)
D: open(‘address.csv’,‘rb+’)
答案:A
在Python中,all()函数用于判断可迭代对象中的所有元素是否都为真。它接受一个可迭代对象作为参数,并返回一个布尔值。如果可迭代对象中的所有元素都为真(非零、非空字符串、非空列表等),则返回True;否则返回False。
在选项D中,all([‘0’,‘1’,‘2’])将会返回True。所有的字符串都是非空的,因此整个列表被视为真。
二、判断题(共10题,每题2分,共20分)
第26题
有这样一个表达式:
ord('a') - ord('A')
这个表达式运行的结果是整数 32 。( )
答案:正确
考查学生对ord()函数的理解。ord()函数的返回值为整数,字符 ‘a’ 与 ‘A’ 之间的差为整数32,所以本题答案是正确的。
第27题
一维数据的存储常常采用空格、逗号、换行、分号等符号分隔元素。( )
答案:正确
考查一维数据的分隔格式。
第28题
a=[['王鑫','86','90','92','99','94','95'],['杨小虹','93','97','95','90','86','85'],['李静','89','98','99','94','90','85']]
其中,杨小虹同学的第三门成绩95的数据类型是整数。( )
答案:错误
应是字符串
第29题
二维数据的处理等同于二维列表的操作,借助循环遍历可实现对每个数据的处理。( )
答案:正确
二维数据的循环遍历处理方式
第30题
关于程序的异常处理,可以使用try…except…或try…except…except…语句进行捕获控制。( )
答案:正确
遇到错误语句,try代码块的剩余语句将忽略,根据错误情况转而执行相应的except语句块。
第31题
使用input()函数可以一次从键盘输入一个字符串,按回车键结束输入。( )
答案:正确
input()函数用于从用户处获取输入,并将其作为字符串返回。当调用input()函数时,程序会等待用户输入,并且用户可以在键盘上输入一个字符串。按下回车键会结束输入,并将输入的字符串作为函数的返回值。
第32题
set是一个不允许元素重复的集合。由于set里的元素位置允许随意,所以不能用索引访问。( )
答案:正确
在Python中,set是一个无序且不允许元素重复的集合数据类型。这意味着在一个set中,每个元素都是唯一的,且元素的顺序是不确定的。
由于set是无序的,它不支持使用索引来访问元素。set中的元素没有固定的位置,因此不能通过索引来获取特定元素。如果需要访问set中的元素,通常可以使用迭代或其他集合操作方法来处理。
因此,由于元素位置允许随意,不能用索引访问set中的元素。
第33题
help()函数用来查看函数或模块的帮助信息,但不能直接查看对象里所提供方法的帮助信息。( )
答案:正确
help()函数是用来查看函数、模块、类以及对象的帮助信息的,包括对象所提供的方法的帮助信息。通过调用help()并传递对象作为参数,可以获取关于该对象的详细说明和用法。
第34题
sum()函数可以对列表进行求和,但不能对元组进行求和。( )
答案:错误
sum()函数在Python中可以用于对可迭代对象进行求和。可迭代对象可以是列表、元组、集合等。
无论是列表还是元组,都可以作为sum()函数的参数进行求和操作。
例如,你可以使用sum([1, 2, 3])对列表进行求和,结果为6。同样地,你也可以使用sum((1, 2, 3))对元组进行求和,结果同样为6。
因此,sum()函数既可以对列表进行求和,也可以对元组进行求和。
第35题
在Python编程语言中,‘0b10’ 表示二进制数10,并且这个数换算为十进制,就是整数2。( )
答案:正确
本题考查学生对二进制表示方式的理解,同时也考查学生对十进制与二进制相互转换的理解。
三、编程题(共3题,共30分)
第36题
如下图有一个名为“book.csv”的文件,小明想计算所有库存书籍的总价,于是编写了下面代码。请将红色①②处的代码补充完整。
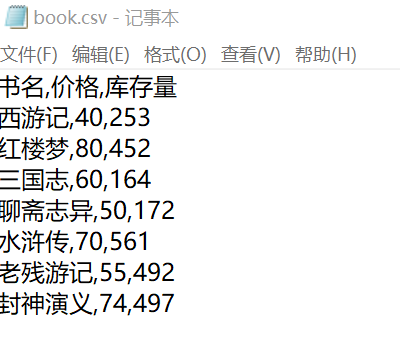
b = 0
s = 0
with open('/data/book.csv', 'r', encoding='utf-8') as f:
for line in f. ① ():
a = line.strip("\n").split(",")
b = b+1
if b >1: # 第一行是标题,所以从第二行开始计算
s = s + int(a[1]) * ②
print('总价:' , s)
答案:
b = 0
s = 0
with open('/data/book.csv', 'r', encoding='utf-8') as f:
for line in f.readlines(): # ① 读取文件的每一行
a = line.strip("\n").split(",")
b = b + 1
if b > 1: # 第一行是标题,所以从第二行开始计算
s = s + int(a[1]) * int(a[2]) # ② 计算每本书的总价并累加
print('总价:', s)
在①处,使用f.readlines()方法读取文件的每一行,返回一个包含所有行的列表。
在②处,根据CSV文件的结构,a[1]表示每本书的数量,a[2]表示每本书的价格,将它们转换为整数后进行相乘,然后累加到总价s中。
这样,代码就完成了对CSV文件中所有库存书籍总价的计算。
第37题
小敏想用二分法对关键字14进行查找,请你帮她补全代码。
lst=[3,12,7,45,9,10,31,90,1,23,14,52]
①
key=14
n=len(a)
i,j=0,n-1
flag=-1
while ② :
mid=(i+j)//2
if key==a[mid]:
flag=mid
break
elif key>a[mid]:
③
else:
j=mid-1
if ④ :
print(str(key)+'没找到!')
else:
print(str(key)+'已找到!')
答案:
lst=[3,12,7,45,9,10,31,90,1,23,14,52]
a=sorted(lst) # ① 对列表进行排序
key=14
n=len(a)
i,j=0,n-1
flag=-1
while i<=j: # ② 使用循环进行二分查找
mid=(i+j)//2
if key==a[mid]:
flag=mid
break
elif key>a[mid]:
i=mid+1 # ③ 更新左边界
else:
j=mid-1 # 更新右边界
if flag==-1: # ④ 判断是否找到关键字
print(str(key)+'没找到!')
else:
print(str(key)+'已找到!')
在①处,对列表lst进行排序,以便使用二分查找算法。
在②处,使用while循环进行二分查找,循环条件为i <= j。
在③处,根据二分查找的原理,通过比较关键字key和中间元素lst[mid]的大小关系,更新左边界i或右边界j。
在④处,判断是否找到关键字,如果flag仍为初始值-1,则表示关键字未找到。
这样,代码就完成了使用二分法对关键字14进行查找的过程。如果找到了关键字,则输出"14已找到!“,否则输出"14没找到!”。
第38题
标准考试答题卡一般采用2B铅笔填涂,填涂好的答题卡经过扫描后得到相应的数字化图像,再通过光学识别,完成答题卡信息数据的采集、分析与统计。计算机判断答题卡中信息点被填涂的标准是灰度值小于132为黑色,灰度值大于等于132为白色。灰度值计算公式:灰度值=0.299×红色分量(R)+0.587×绿色分量(G)+0.114×蓝色分量(B),若分别输入n个信息点的RGB颜色值,则其判断程序如下:
n=int(input("请输入信息点个数:"))
count=0
for i in range(1,n+1):
R=int(input(”请输入红色分量:”))
①
B= int(input(”请输入蓝色分量:”))
Gray_scale= ②
if ③ :
print(“黑色”)
count=count+1
else:
print(“白色”)
print("黑色像素总共有:"+ ④ +"个")
答案:
n = int(input("请输入信息点个数:"))
count = 0
for i in range(1, n + 1):
R = int(input("请输入红色分量:"))
G = int(input("请输入绿色分量:")) # ① 输入绿色分量
B = int(input("请输入蓝色分量:"))
Gray_scale = 0.299 * R + 0.587 * G + 0.114 * B # ② 计算灰度值
if Gray_scale < 132: # ③ 判断灰度值是否小于132
print("黑色")
count = count + 1
else:
print("白色")
print("黑色像素总共有:" + str(count) + "个") # ④ 输出黑色像素总数
在①处,补充输入绿色分量的代码,与红色分量和蓝色分量一样,将其转换为整数类型。
在②处,根据给定的灰度值计算公式,计算灰度值 Gray_scale。
在③处,通过判断灰度值是否小于132,确定信息点的颜色是黑色还是白色。
在④处,将变量 count 转换为字符串类型,并将其与其他字符串拼接输出黑色像素的总数。
这样,代码就完成了根据RGB颜色值判断答题卡信息点颜色的过程,并统计了黑色像素的总数。






![[SSD综述 1.4] SSD固态硬盘的架构和功能导论](https://img-blog.csdnimg.cn/3314a649fd594853894c6587026dd1cc.png)


