文章目录
- 总结
- Hackergame2023
- 更深更暗
- 组委会模拟器
- 猫咪小测
- 标题HTTP集邮册
- Docker for everyone
- 惜字如金 2.0
- Git? Git!
- 高频率星球
- 低带宽星球
- 小型大语言模型星球
- 旅行日记3.0
- JSON ⊂ YAML?
总结
最近看到科大在举办CTF比赛,刚好我学校也有可以参加,就玩了玩。
个人比较菜,下班时间玩了几天,感觉挺有趣也有难度,感觉偏学术和代码水平多一些吧,还是不错的
官方也已经放出WP了,找时间好好研究一下
WP:https://github.com/USTC-Hackergame/hackergame2023-writeups
题目说是会保存三个月,大家可以直接去练习的,wp里面有一个cookie,可以直接使用
比赛平台 https://hack.lug.ustc.edu.cn/
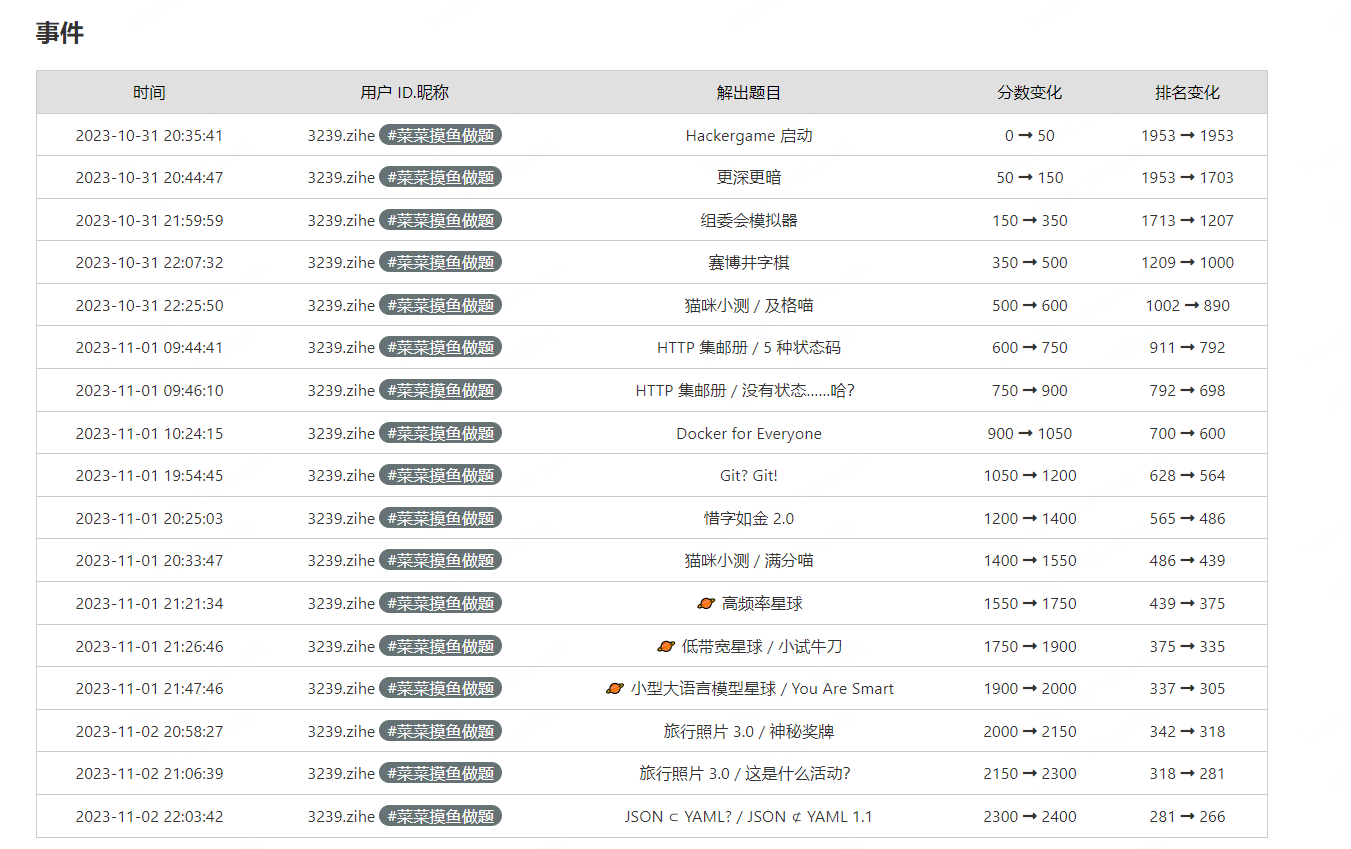
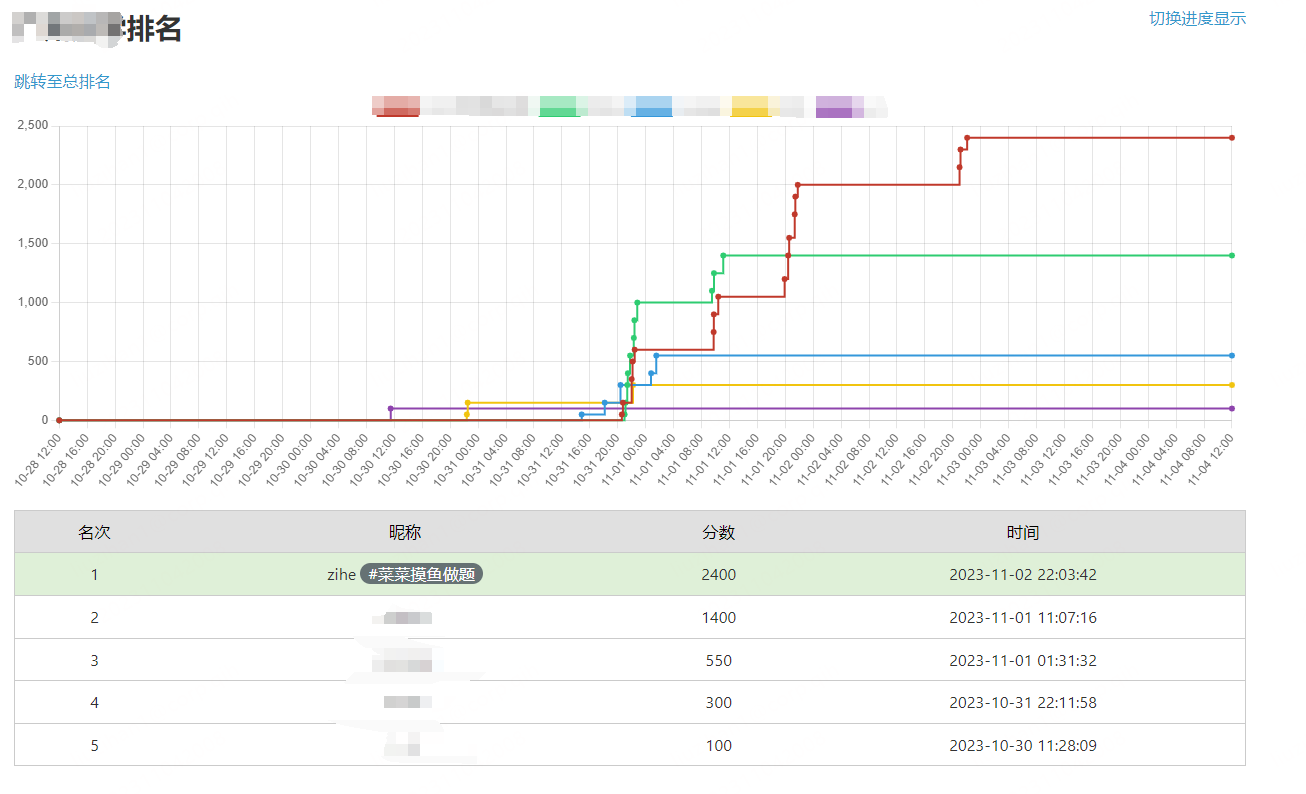
我学校已经没什么人参加,总排名只有前100,也看不到我的进度,菜鸡就不配上总排名吗(恼
Hackergame2023
修改参数相似度>99即可
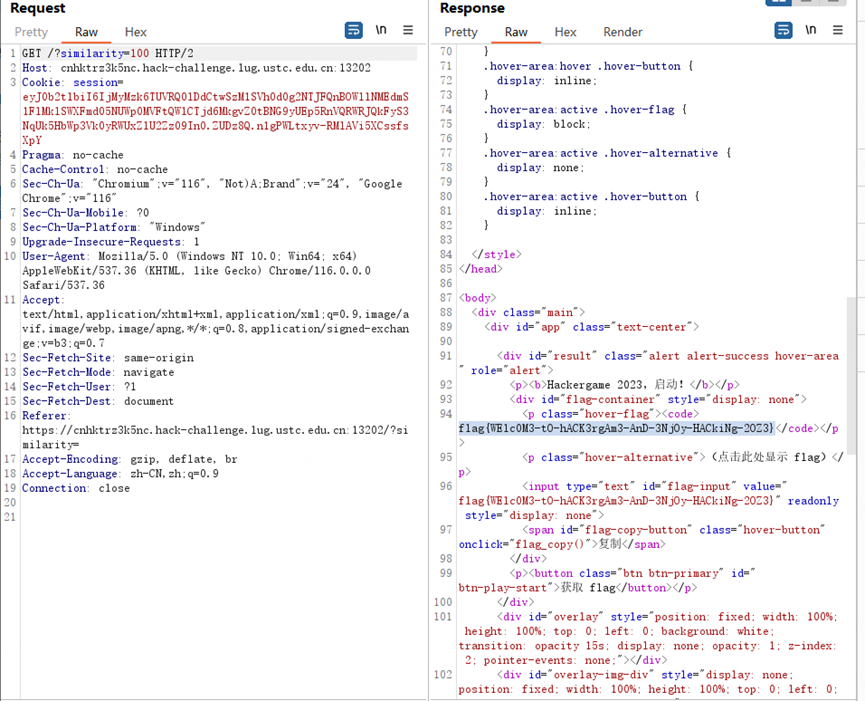
更深更暗
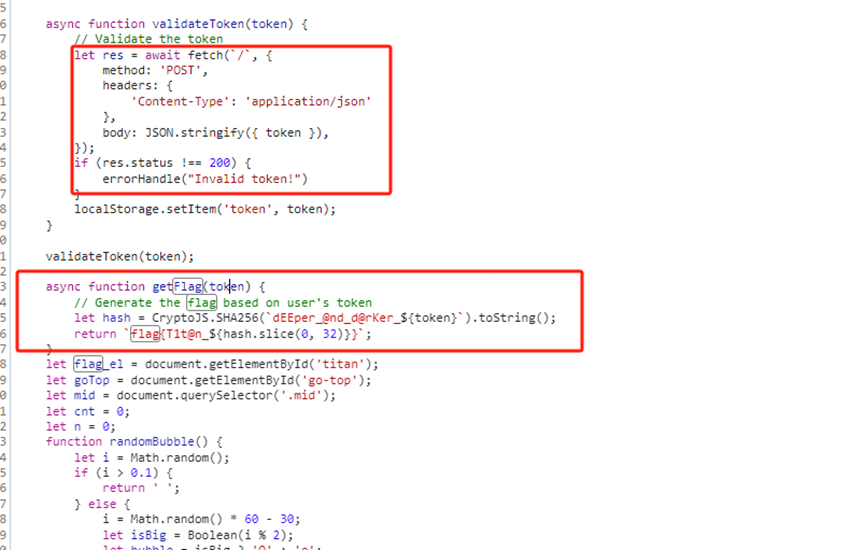
查看js可以看到一个输出flag的函数
发现有利用token,往前找到token的地方
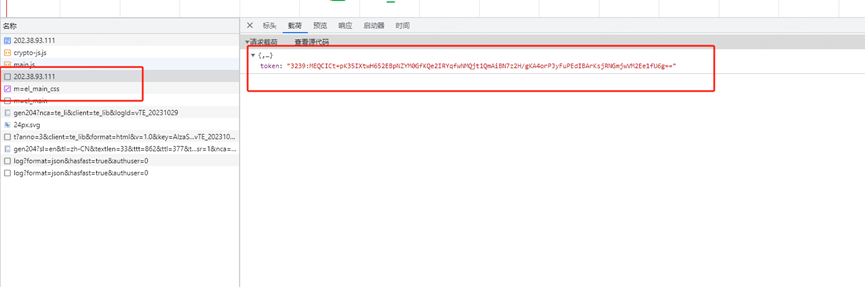
调用控制台将这个输出
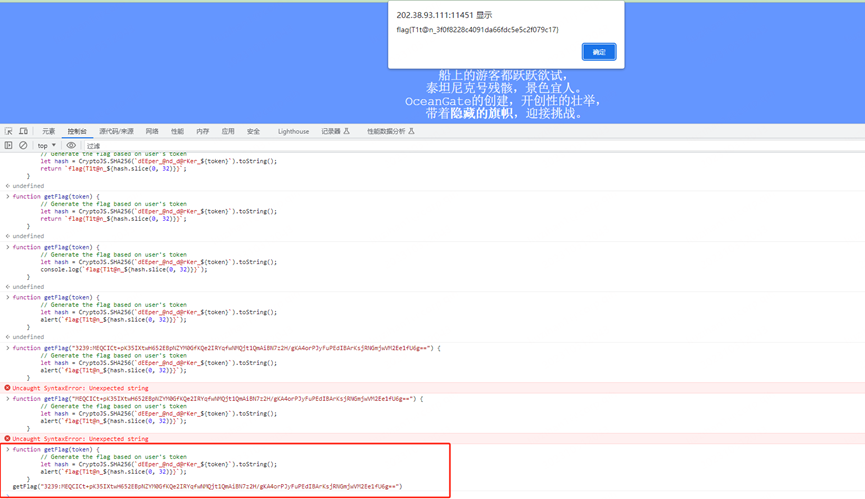
flag{T1t@n_3f0f8228c4091da66fdc5e5c2f079c17}
组委会模拟器
分析代码是,需要在delay到delay+3秒内,发功deleteMessage请求,那么就用python实现了
先请求getMessages拿到消息json,然后根据时间戳进行及时删除
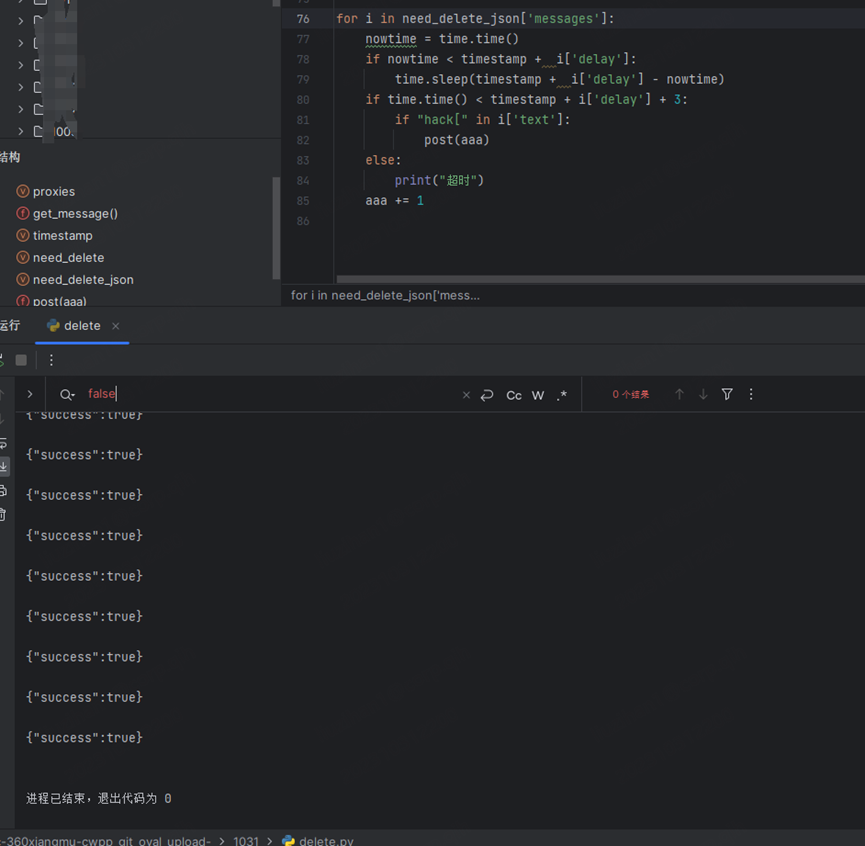
跑完之后再发一个getflag请求
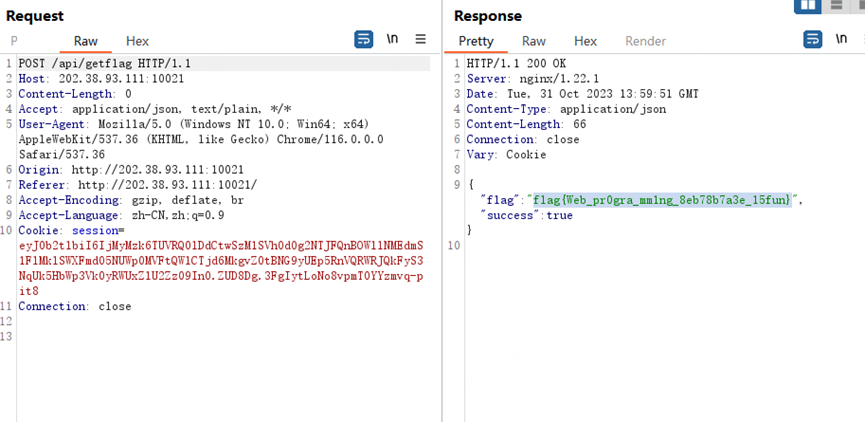
代码:
import json
import time
import requests
proxies = {"http": "http://127.0.0.1:8080"}
def get_message():
cookies = {
'session': 'eyJ0b2tlbiI6IjMyMzk6TUVRQ0lDdCtwSzM1SVh0d0g2NTJFQnBOWllNMEdmS1FlMklSWXFmd05NUWp0MVFtQWlCTjd6MkgvZ0tBNG9yUEp5RnVQRWRJQkFyS3NqUk5HbWp3Vk0yRWUxZlU2Zz09In0.ZUD8Dg.3FgIytLoNo8vpmT0YYzmvq-pit8',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Content-Length': '0',
# 'Cookie': 'session=eyJ0b2tlbiI6IjMyMzk6TUVRQ0lDdCtwSzM1SVh0d0g2NTJFQnBOWllNMEdmS1FlMklSWXFmd05NUWp0MVFtQWlCTjd6MkgvZ0tBNG9yUEp5RnVQRWRJQkFyS3NqUk5HbWp3Vk0yRWUxZlU2Zz09In0.ZUD8Dg.3FgIytLoNo8vpmT0YYzmvq-pit8',
'Origin': 'http://202.38.93.111:10021',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://202.38.93.111:10021/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
response = requests.post('http://202.38.93.111:10021/api/getMessages', cookies=cookies, headers=headers,
verify=False, proxies=proxies)
with open("1.txt", "w", encoding="utf-8") as f:
f.write(str(response.text))
get_message()
timestamp = time.time()
need_delete = open("1.txt", "r", encoding="utf-8")
need_delete_json = json.loads(need_delete.read())
def post(aaa):
cookies = {
'session': 'eyJ0b2tlbiI6IjMyMzk6TUVRQ0lDdCtwSzM1SVh0d0g2NTJFQnBOWllNMEdmS1FlMklSWXFmd05NUWp0MVFtQWlCTjd6MkgvZ0tBNG9yUEp5RnVQRWRJQkFyS3NqUk5HbWp3Vk0yRWUxZlU2Zz09In0.ZUD8Dg.3FgIytLoNo8vpmT0YYzmvq-pit8',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Type': 'application/json',
# 'Cookie': 'session=eyJ0b2tlbiI6IjMyMzk6TUVRQ0lDdCtwSzM1SVh0d0g2NTJFQnBOWllNMEdmS1FlMklSWXFmd05NUWp0MVFtQWlCTjd6MkgvZ0tBNG9yUEp5RnVQRWRJQkFyS3NqUk5HbWp3Vk0yRWUxZlU2Zz09In0.ZUD8Dg.3FgIytLoNo8vpmT0YYzmvq-pit8',
'Origin': 'http://202.38.93.111:10021',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://202.38.93.111:10021/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
json_data = {
'id': aaa,
}
response = requests.post(
'http://202.38.93.111:10021/api/deleteMessage',
cookies=cookies,
headers=headers,
json=json_data,
verify=False,
proxies=proxies
)
print(response.text)
# Note: json_data will not be serialized by requests
# exactly as it was in the original request.
# data = '{"id":4}'
# response = requests.post('http://202.38.93.111:10021/api/deleteMessage', cookies=cookies, headers=headers, data=data, verify=False)
aaa = 0
for i in need_delete_json['messages']:
nowtime = time.time()
if nowtime < timestamp + i['delay']:
time.sleep(timestamp + i['delay'] - nowtime)
if time.time() < timestamp + i['delay'] + 3:
if "hack[" in i['text']:
post(aaa)
else:
print("超时")
aaa += 1
猫咪小测
图书在哪一层
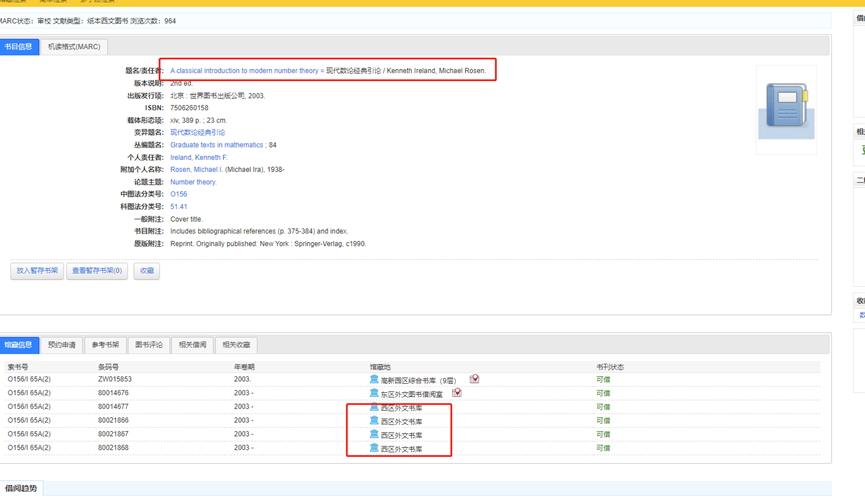
西区外文书库
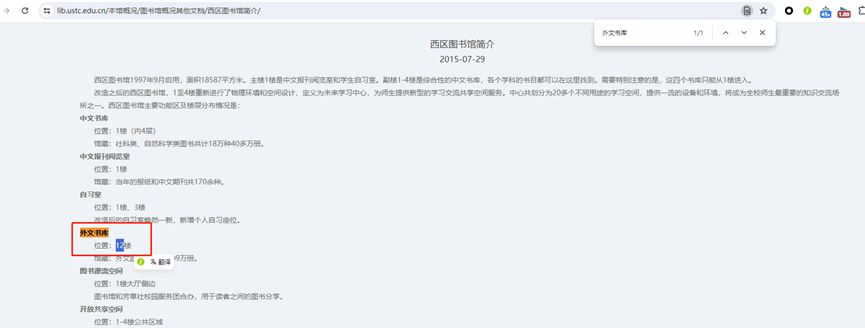
12层
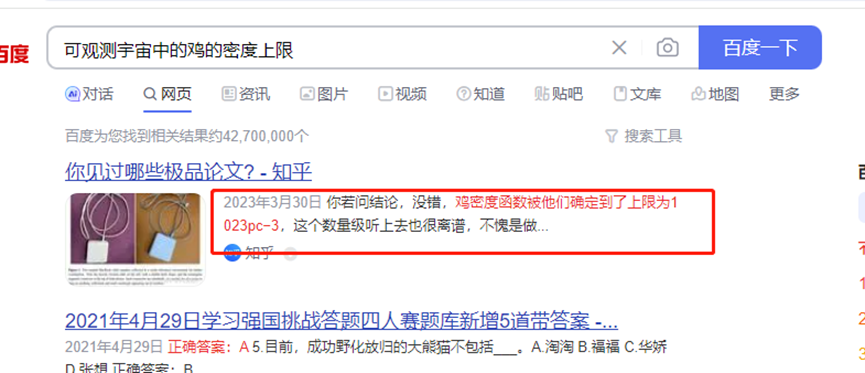
可观测宇宙中的鸡的客度上限,直接百度,1023pc-3,应该是10的23次方什么的
通过搜索,找到一个文章,里面写到CONFIG_TCP_CONG_BBRMO,但是尝试后不对,但是有感觉很接近,于是去掉最后MO
CONFIG_TCP_CONG_BBR 正确

这个学术会议,应该是用的英语,所以先把题目描述转换成英文,再到英文检索平台去搜索
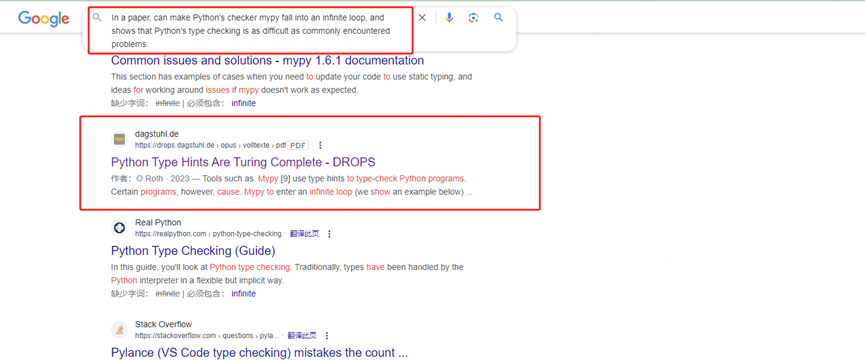
发现一篇pdf
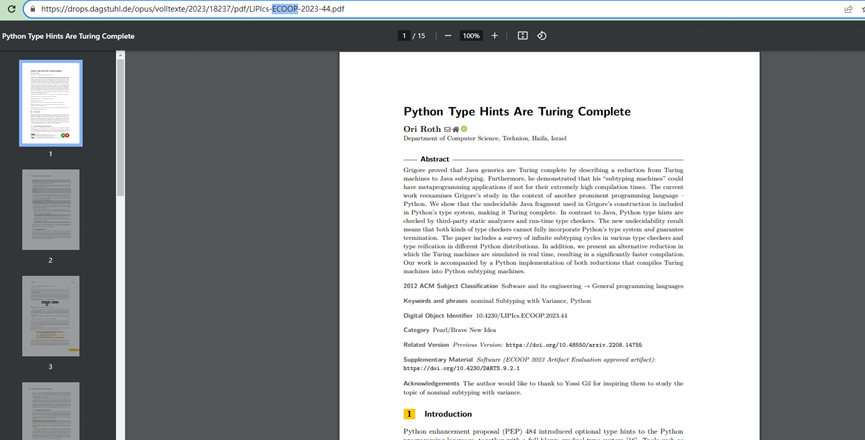
路径里面文件名,写了哪个会议的哪个文章
标题HTTP集邮册
200 400 404 405 比较好弄,随便输,
414,请求路径过长就行
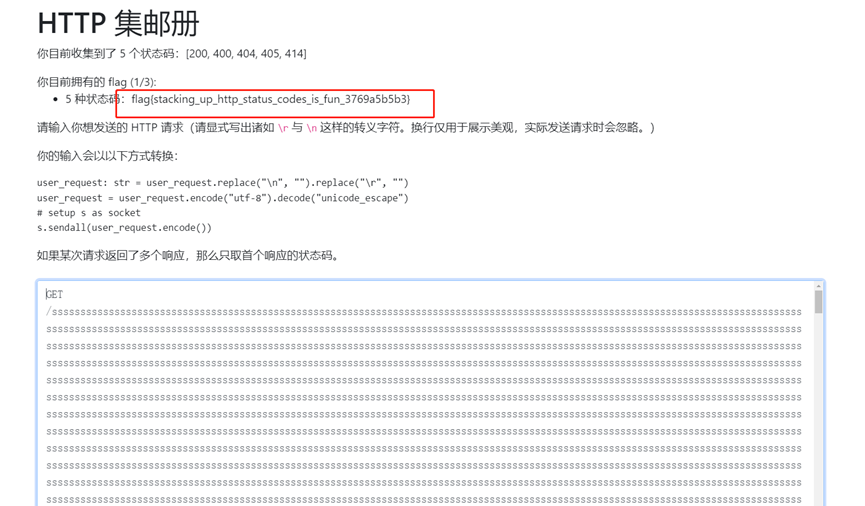
无状态:其实无意中,发现/HTTP就直接无状态了
Docker for everyone
docker run -it --rm -v /dev/shm:/mnt 187eae39ad94 /bin/sh

惜字如金 2.0
看规则,应该是删除了e和重复的韵母
代码里面有个对比函数是没有用处的,只会导致报错,把这个函数删掉就行
应该是从一长串字符串里面,按照指定的顺序去读取,那么前五个肯定是flag{
然后判断在符号前面是不是需要补e
凑出flag{后差不多再微调就可以了
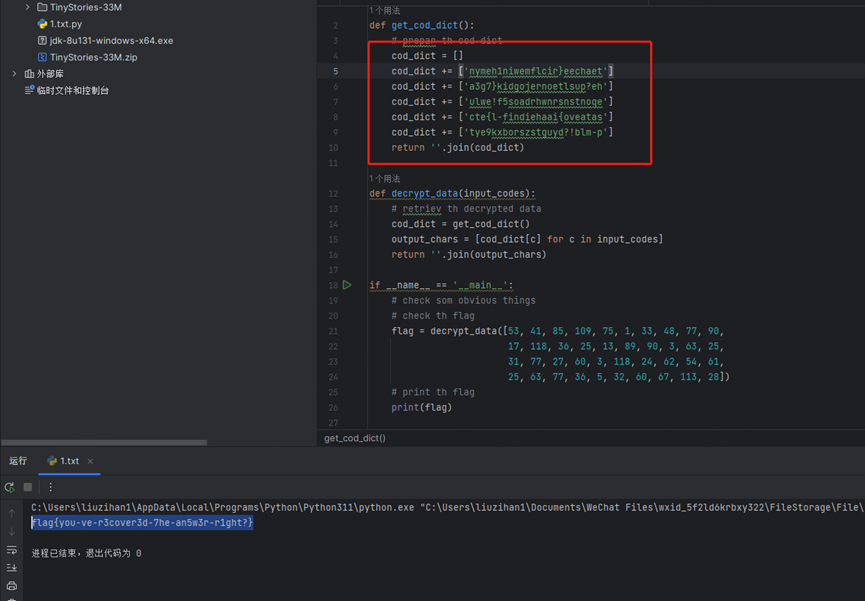
def get_cod_dict():
# prepar th cod dict
cod_dict = []
cod_dict += ['nymeh1niwemflcir}eechaet']
cod_dict += ['a3g7}kidgojernoetlsup?eh']
cod_dict += ['ulwe!f5soadrhwnrsnstnoqe']
cod_dict += ['cte{l-findiehaai{oveatas']
cod_dict += ['tye9kxborszstguyd?!blm-p']
return ''.join(cod_dict)
def decrypt_data(input_codes):
# retriev th decrypted data
cod_dict = get_cod_dict()
output_chars = [cod_dict[c] for c in input_codes]
return ''.join(output_chars)
if __name__ == '__main__':
# check som obvious things
# check th flag
flag = decrypt_data([53, 41, 85, 109, 75, 1, 33, 48, 77, 90,
17, 118, 36, 25, 13, 89, 90, 3, 63, 25,
31, 77, 27, 60, 3, 118, 24, 62, 54, 61,
25, 63, 77, 36, 5, 32, 60, 67, 113, 28])
# print th flag
print(flag)
Git? Git!
根据题目要求,发现是提交到本地了,那本地文件里面应该是有这个记录的,但是需要想办法拿出来
参考https://01.me/2015/05/recover-code-from-corrupt-git-repo/
把object里面的一个一个解压出来,看看有没有flag
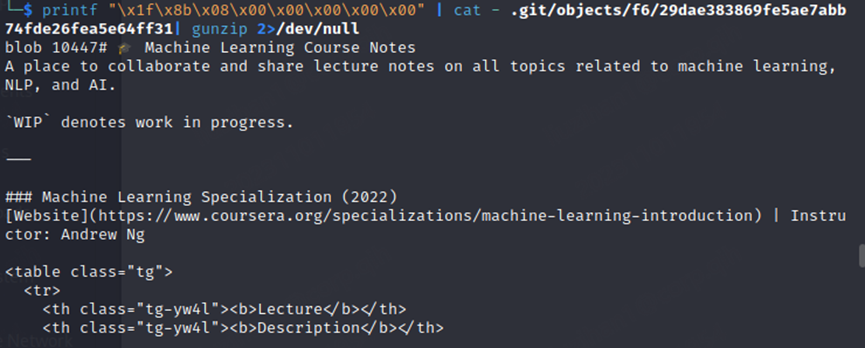
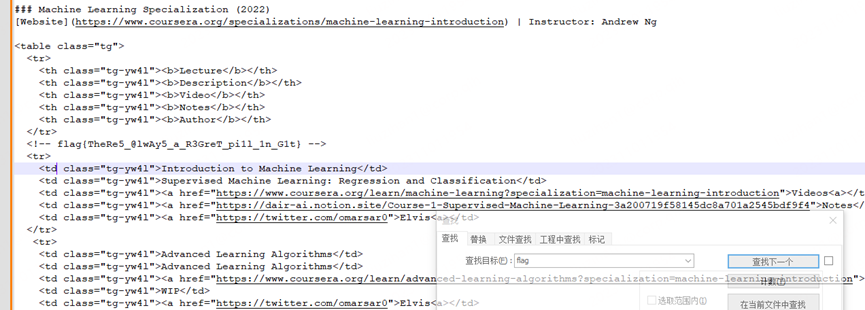
高频率星球
asciinema 是一个命令录制工具,需要把命令回放
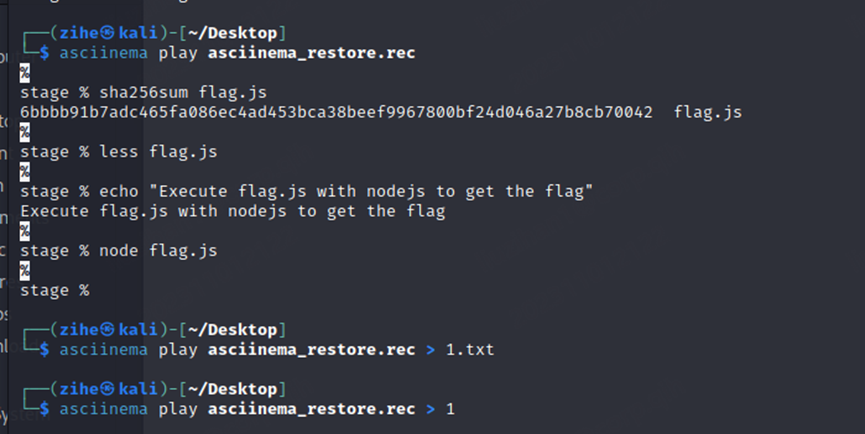
直接保存到js文件,然后把一些ESC标识符删除就行,使用node运行js即可

低带宽星球
直接压缩图片
https://tinify.cn/
压缩一次
拿到一个

小型大语言模型星球
需要引导模型说出指定的话
Flag1

旅行日记3.0
首先找第二个题,通过名字可以看出来是小柴昌俊,搜索得到,东京大学
然后进入东京大学官网查询 诺贝尔奖展厅
https://www.s.u-tokyo.ac.jp/en/gallery/
https://www.s.u-tokyo.ac.jp/en/gallery/nobelprize/

找到年龄最小的
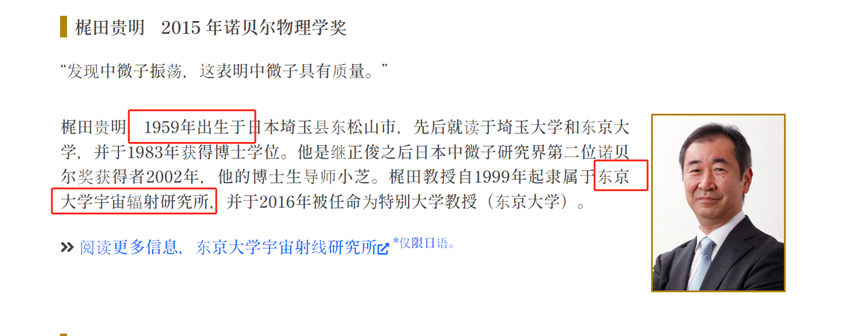
东京大学宇宙辐射研究所 简称ICRR
然后会过来看第一个提,结合第三题,因为是一个大型活动,需要招募志愿者,并且是在学校附近的广场,还有博物馆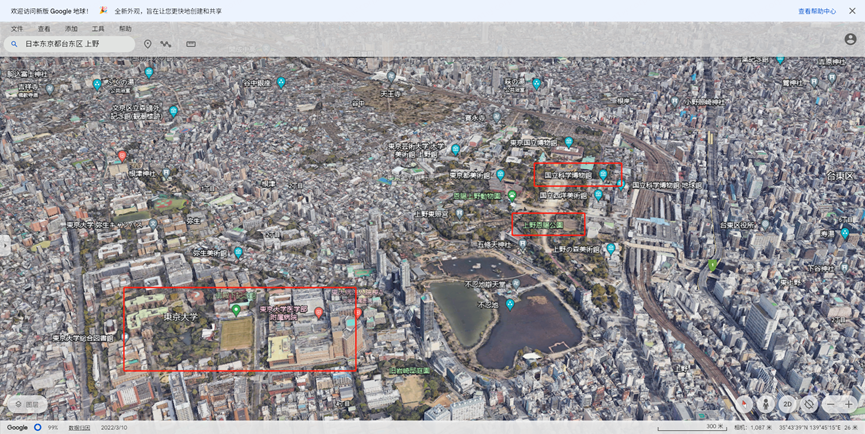
谷歌地图上面发现比较近的博物馆和广场,东京国立博物馆、上野公园广场Takenodai Square (Fountain Square),
通过雅虎日本 搜索,上野公园广场 活动 招募志愿者 (使用日语搜索,竹の台広場(噴水広場)で応募者を募集します)
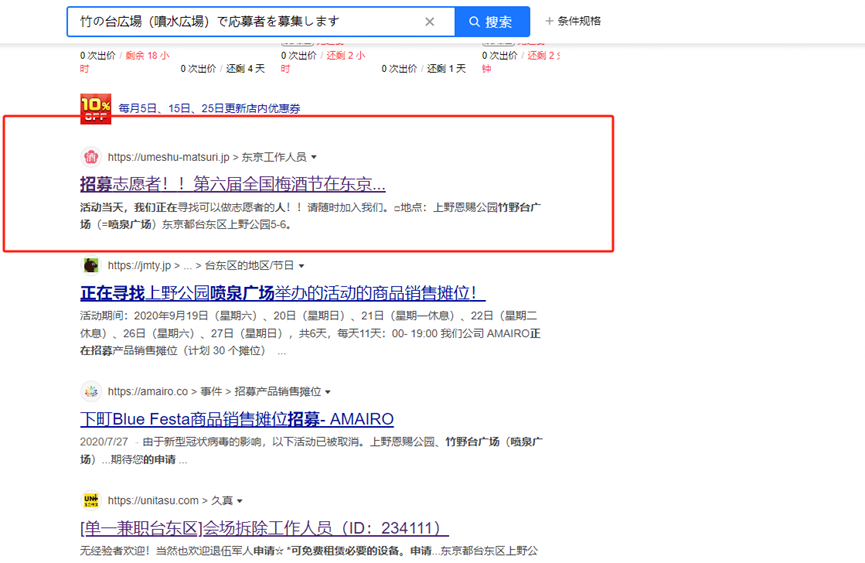
找到一个比较接近暑假时间段的
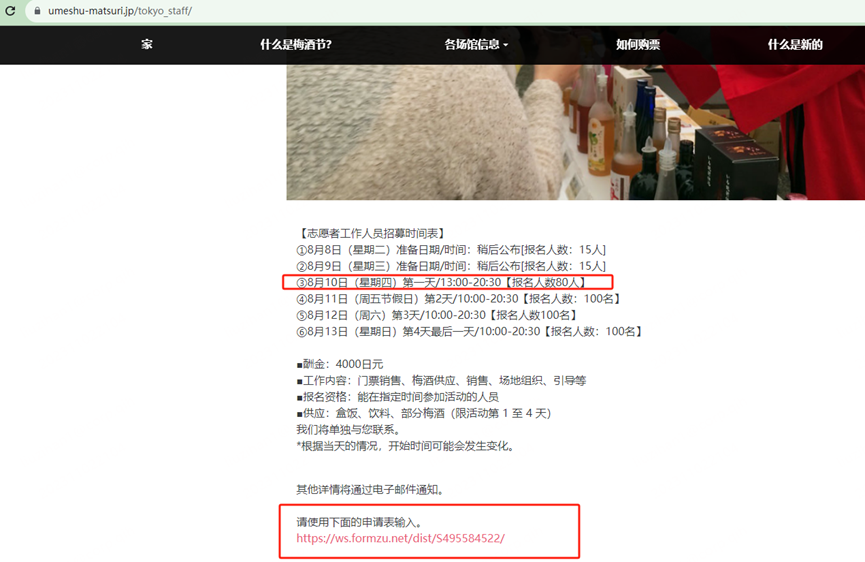
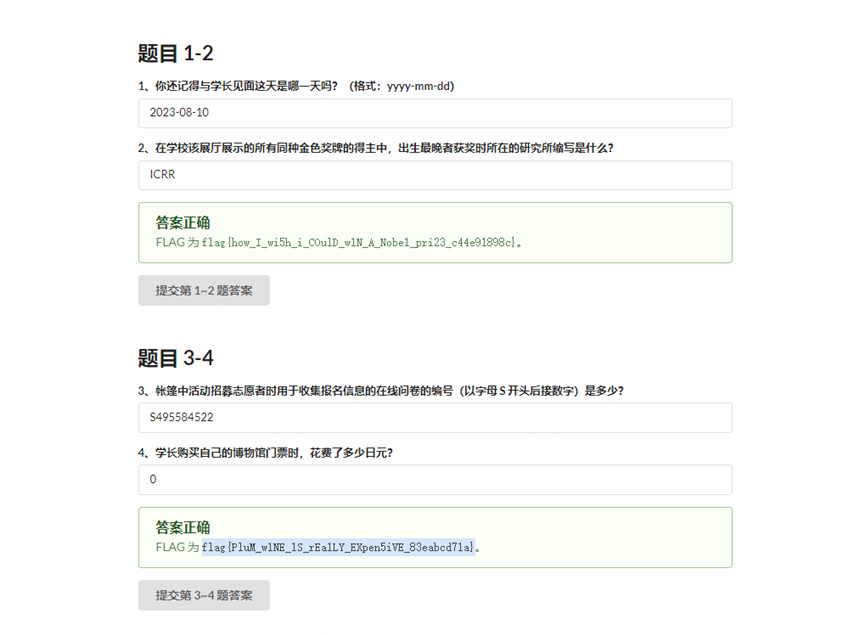
应该是第一天,2023-08-10
问卷连接也同时拿到了
https://ws.formzu.net/dist/S495584522/
,1、3题都解决了,再看第四题,学长应该是去的东京国立博物馆
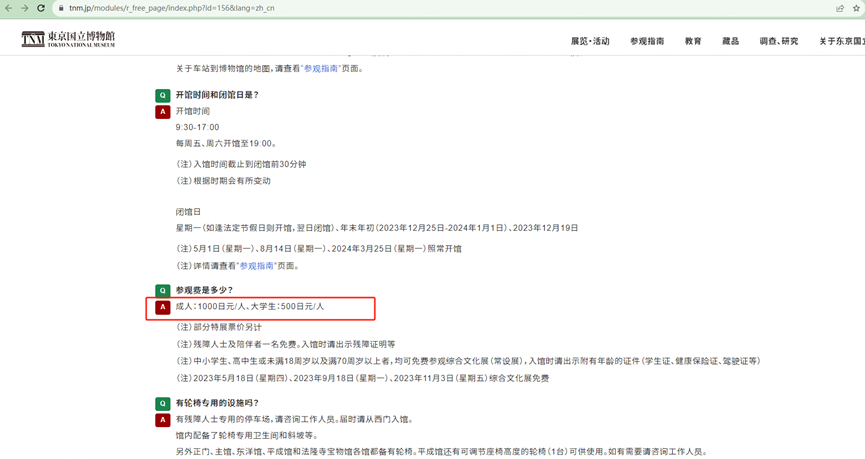
但是试了一下,这个数字不对,这时候注意到后面写的,对部分人可以免费,猜测是0元
第六题
熊猫
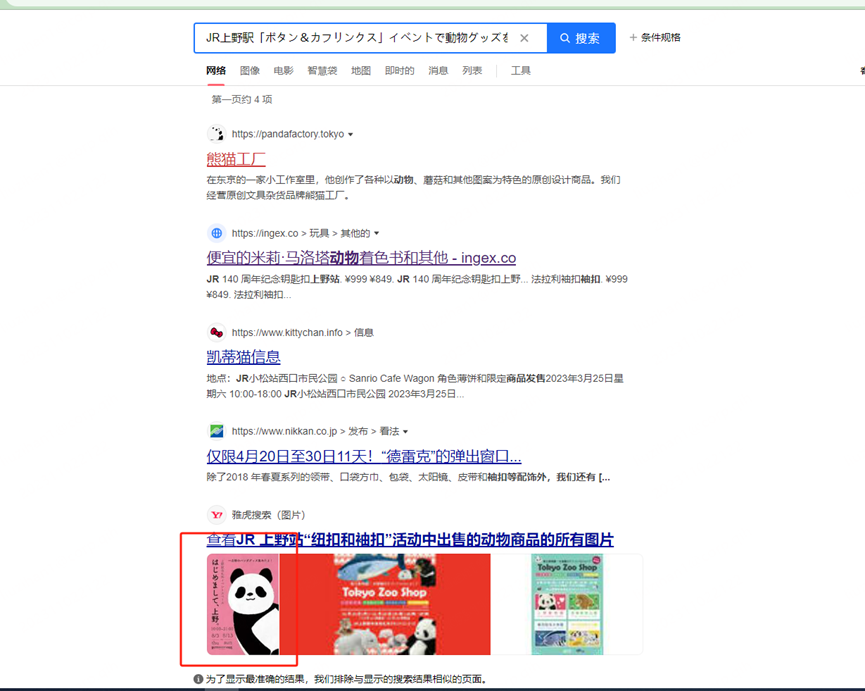
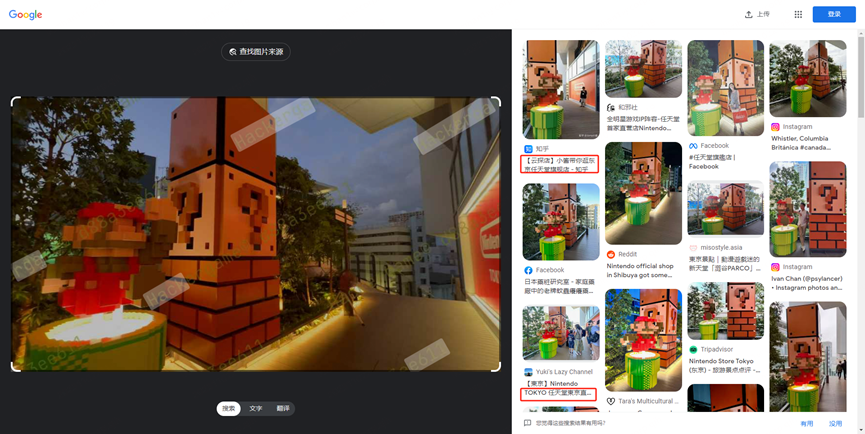
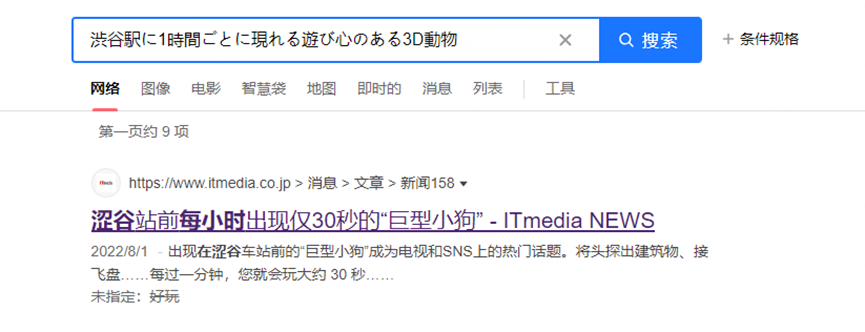
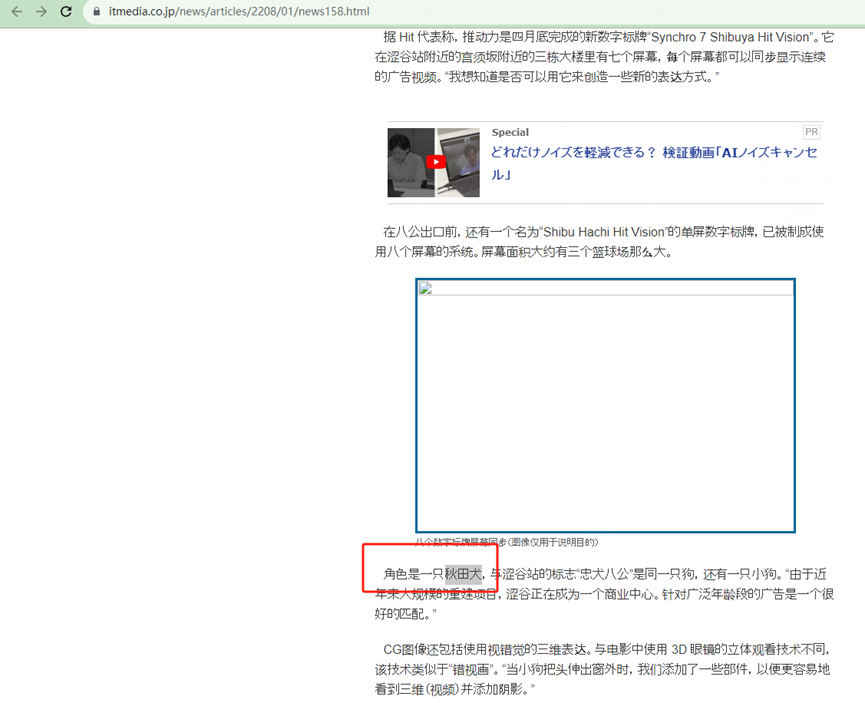
东京任天堂-》涩谷站-》秋田犬
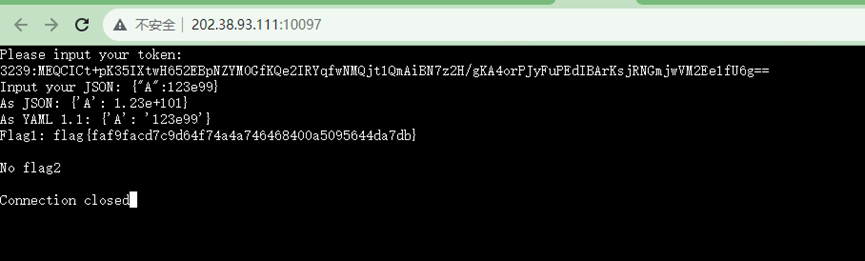
JSON ⊂ YAML?
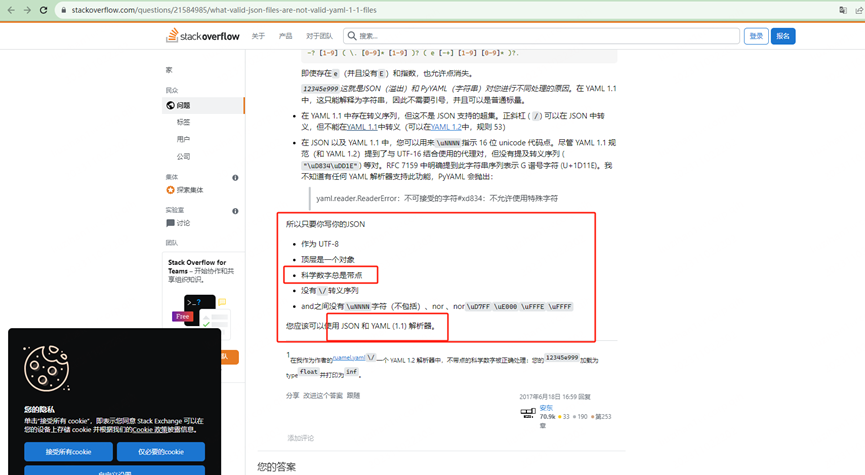
123e99
Json和yaml表示的不一致