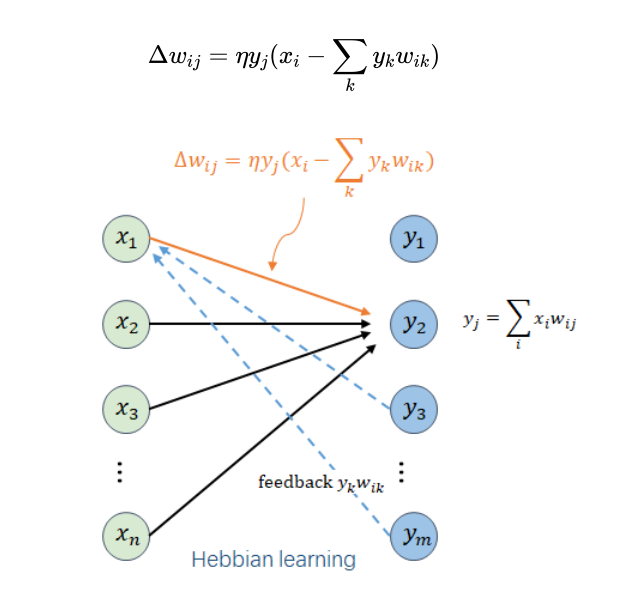
Web图
将Web当做有向图
-
节点:网页
-
边:超链接

PageRank
不同网页的重要性是不同的,在web-graph中,节点之间的连接性有巨大的差异。我们根据链接结果来对网页进行排序
想法:用链接来投票
-
如果有更多的链接指向一个网页(入链接),那么这个网页就会更重要(链接数目)
-
来源于重要的网页的入链接的权重更大(链接质量)
-
整个计算是一个递归过程

每个边的分数都是其源页面的重要性的一部分,每个页面的重要性是入边的投票和

流模型
我们定义页面 j j j 的得分为 r j r_j rj。该得分来源于所有指向 j j j 的边。 r i r_i ri 是页面 i i i 的重要性分数, d i d_i di 是页面 i i i 出边的数目。
这个指标同时体现了:1.被越多边指,得分越高。2.被重要页面的边指,得分更高

利用上面的式子,对于下面的图结构,我们可以得到三个方程

上面方程组,有三个方程,三个未知数,而且没有常数。因此,我们==可以得到无数组解(得到的一组解同乘一个系数仍然成立)。==我们只想要一个解,因此我们给上面的方程组添加约束,强制其只有一个解。

如果方程组的规模大了,直接求解很麻烦
矩阵方程
我们将上述方程组表示成矩阵形式。如果 i i i 对 j j j 有出边,那么第 i i i 列第 j j j 行,也就是 $M_{ji}=\frac{1}{d_i} \$。否则为0。注意到方程组转化成了 r = M r r = Mr r=Mr,也就是 M r = 1 ⋅ r Mr = 1 \cdot r Mr=1⋅r ,因此, r r r 是 M M M 的特征向量

- 注意到, M M M 是列随机矩阵:每一列的和都为 1。这代表该列对应的 page 的所有出边。
- r i r_i ri 是页面 i i i 的重要性得分,并且我们约束了:所有文档的正确性得分之和为 1
特征向量方程
方程组表示为 r = M r r = Mr r=Mr,因此 r r r 是 M M M 的特征向量。实际上, r r r 是首要的特征向量,其特征值对应为 1
- 因为 M M M 是列随机矩阵,因此 M M M 最大的特征值为 1
幂迭代法
是一个寻找最显著的特征向量(对应最大特征值的特征向量)的方法
过程
对一个有 N 个节点的 web 图
- 初始时,假设所有节点的得分相同,都是 1 N \frac{1}{N} N1
- 使用 M ⋅ r M \cdot r M⋅r 对 r r r 进行迭代
- 直到向量 r ( t + 1 ) − r ( t ) r^{(t+1)} - r^{(t)} r(t+1)−r(t) 的长度小于一个设定值

下面得到的这一序列会逐渐接近 M M M 的最显著的特征向量

PageRank的三个问题

能收敛吗?能收敛到想要的值吗?结果合理吗?
- 无法收敛的情况

-
收敛到不想要的结果的情况

问题
-
有一些点是死胡同,没有出边。当分数流过来之后就出不去了,这会使分数发生泄露
-
spider trap:有一些点的出边会形成一个循环,这样的话,最终这一个循环中的点会吸取所有的分数

解决方法:传送
对 spider trap的解决
增加了随机跳的功能。在每一个时间步,浏览者会有两种选择

通常 β \beta β 取 0.8到0.9之间的值
-
对于spider trap,经过几个时间步之后,就能跳出去

- spider trap的结果不是我们想要的,而在有限的步数内可以跳走以保证我们不会陷入 spider trap
对死胡同的解决
以 1.0 的概率从死胡同跳走

死胡同是个问题,因为这并不满足我们一开始的设想(矩阵 M M M 是列随机矩阵,每一列的和都是 1)。我们在一个点是死胡同时,通过传送让矩阵 M M M 变成列随机矩阵
随机传送的式子
每一个时间步都有两种选择
这假设了没有死胡同。我们可以通过预处理来消除所有死胡同,或者显式地遵循死胡同的概率为1.0的随机传送链接。

写成矩阵形式。在计算时我们将 M M M 替换成 A A A

例子