开发前准备:
环境管理:Anaconda
python: 3.8
显卡:NVIDIA3060
pytorch: 到官网选择conda版本,使用的是CUDA11.8
编译器: PyCharm
简述:
本次使用seaborn库中的flights数据集来做试验,我们通过获取其中年份月份与坐飞机的人数关系,来预测未来月份的坐飞机人数。(注意:很多信息都在注释里有,所以就不会详细解释,多看注释)
需要导入的模块
import torch
import torch.nn as nn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 使用from而不是import是因为 我们只需要导入MinMaxScaler类,而不需要访问该模块中的其他函数或变量
from sklearn.preprocessing import MinMaxScaler
# 自定义的模块,用来写构造lstm的
import method
获取数据集与处理
有两种方式获取,一种是从网上拉取,一种是下载到本地,因为网络问题,所以我就下载到了本地,联网获取的方式也有,只不过被注释了。
# 获取到seaborn数据集
# dataset_names = sns.get_dataset_names()
# 打印数据集名称
# for name in dataset_names:
# print(name)
# 因为下载总是报错,所以从本地加载
# 使用其中的飞行数据集,获取到的数据类型是Pandas中的DataFrame
flight_data = sns.load_dataset("flights", data_home='C:/Users/51699/Desktop/seaborn-data', cache=True)
# 打印一下前5行数据,看看是个什么造型的数据
print("大概结构----")
print(flight_data.head())
# 打印数据形状,结果是(144,3),144/12=12,表示是有12年的数据,
print("数据形状---")
print(flight_data.shape)
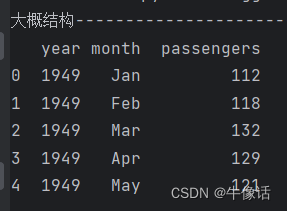
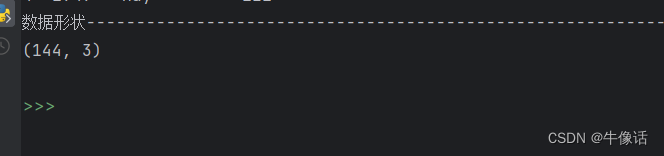
可以看到打印出来的数据结构,包含年份,月份,乘客信息。flight_data 的数据类型是DataFrame。数据形状,是一个144行,3列的矩阵,144/12=12,表示这里总共有12年的数据,144个月。
下面从数据集中获取列名,并从中取出乘客的数据
print("列名信息---------------------------------------------------------------------------")
print(columns)
# 获取passengers列下的所有数据,并转化为浮点数
all_data = flight_data['passengers'].values.astype(float)
print("乘客数量数据---------------------------------------------------------------------------")
print(all_data)
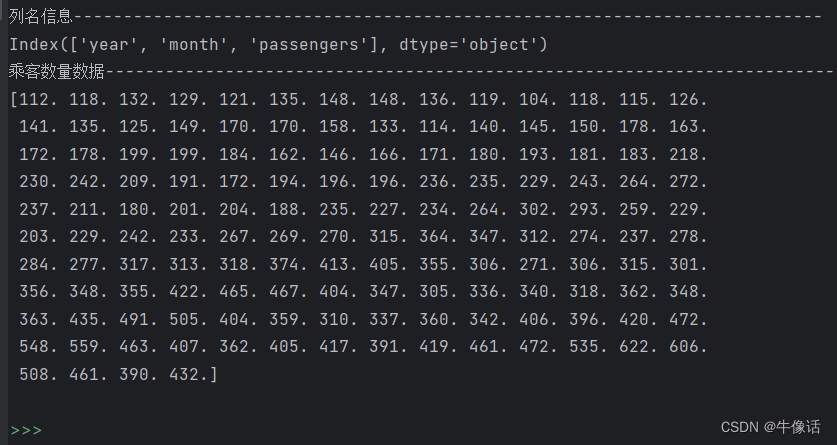
下面需要把144条数据的后12条作为测试数据,144-12=132条数据作为训练数据。然后把切分好的数据,做归一化处理,消除特征关系。可以看出下面的打印内容,所有数据都被限制到了-1和1之间。
# 数据总量为144,我们使用前132条作为训练,后12条用来做测试,所以需要把数据分为训练集和测试集
test_data_size = 12
# 将all_data中除了最后test_data_size个元素之外的所有元素作为训练集,赋值给变量train_data
train_data = all_data[:-test_data_size]
print("训练集长度---")
print(len(train_data))
# 将all_data中最后test_data_size个元素作为测试集,赋值给变量test_data
test_data = all_data[-test_data_size:]
print("测试集长的胡---")
print(len(test_data))
# 归一化处理把乘客数量缩小到-1和1之间 目的是将不同特征的数据量纲统一,消除特征之间的量纲影响,使得不同特征之间具有可比性
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
print("归一化后的前5条和后5条数据---------------------------------------------------------------------------")
print(train_data_normalized[:5])
print(train_data_normalized[-5:])
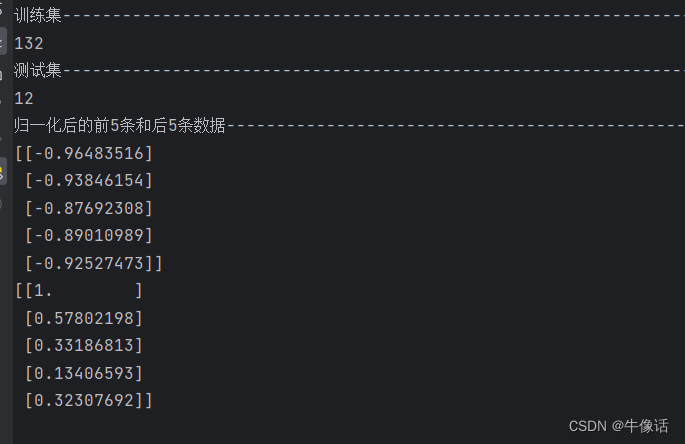
把归一化后的乘客数据,转化为tensor张量,只有张量才能让GPU运算
# 把归一化后的乘客数据,转化为tensor张量,因为PyTorch模型都是要使用tensor张量训练,其中参数-1表示,根据数据自动推断维度的大小。
# 这意味着PyTorch将根据数据的长度和形状来动态确定张量的维度。
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
print("乘客np转化为PyTorch张量---------------------------------------------------------------------------")
print(train_data_normalized)
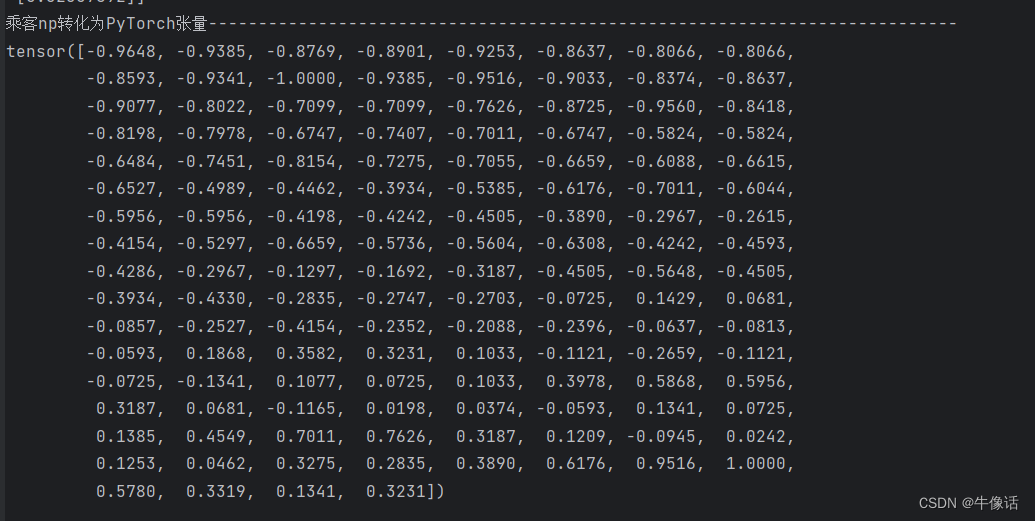
到目前为止,我们已经有了一个一维的张量,接下来就需要制作训练集,训练集一般包含训练的数据,和这组训练数据对应的标签。因为一年有12个月,所以我们就取数据中的第1个到第12个作为训练的数据,第13个作为标签,这就是第一组数据。第二组我们取第2个到第13个数据作为训练数据,第14个作为标签,这就是第二组数据,依次类推,我们就有132组训练数据。
# 将我们的训练数据转换为序列和相应的标签,可以使用任何序列长度,这取决于领域知识。然而,在我们的数据集中,由于我们有每月的数据且一年有12个月,因此使用序列长度为12是方便的
train_window = 12
# 从下面的打印可以看出,第一个tensor中的第一个是训练数组,内容是1-12月的值;第二个是标签数组,内容是13月的值。
# 第二个tensor中的第一个训练数组是2-13月的值,第二个标签数组是14月的值
# 训练集总数是132,每12个为一组,第13个是标签,每次往后移动一个数字,所以有132组
train_inout_seq = method.create_inout_sequences(train_data_normalized, train_window)
print("训练的序列和相应的标签:-------------------------------------------------------------------")
print(train_inout_seq)
其中method.create_inout_sequences是另外一个自定义模块里的方法
# 将我们的训练数据转换为序列和相应的标签
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L - tw):
train_seq = input_data[i:i + tw]
train_label = input_data[i + tw:i + tw + 1]
inout_seq.append((train_seq, train_label))
return inout_seq
红色框内的是训练数据,蓝色的是标签
定义模型类
下面继续在method模块中,定义我们的类LSTM。其中lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)相,其实就是pytorch的impose函数,他要接收一个三维的向量,因为LSTM的隐含层是需要接收三个参数的。
# 定义LSTM模型
class LSTM(nn.Module):
# 构造函数,初始化网络使用
# input_size:对应于输入中特征的数量。虽然我们的序列长度为12,但每个月只有1个值,即乘客总数,因此输入大小将为1
# hidden_layer_size:指定每层神经元的数量。我们将有一个100个神经元的隐藏层
# output_size:输出中项目的数量,由于我们想要预测未来1个月内乘客人数,因此输出大小将为1
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
def forward(self, input_seq):
# self.lstm是已经被实例化过的lstm,第一个参数是输入的序列,第二个参数是隐藏层的状态,隐式调用了向前传播函数,本质就是input方法
# 返回值lstm_out是最终的输出,hidden_cell是隐藏层的状态
# print(input_seq.view(len(input_seq), 1, -1))
# input_seq.view(len(input_seq), 1, -1)需要转化为3维张量,因为LSTM的隐含层是接收三个参数的
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
# self.linear是一个全连接(线性)神经网络层
predictions = self.linear(lstm_out.view(len(input_seq), -1))
# 返回线性层输出张量中的最后一个元素作为最终地预测值
return predictions[-1]
初始化模型信息
接下来就要声明LSTM类,以及一些初始化,关于损失函数和步长的更新方法都在注释里有解释。
# 创建一个LSTM模型对象,用于处理序列数据
model = method.LSTM()
# 创建一个均方误差损失函数对象,用于计算预测值与真实值之间的差异
loss_function = nn.MSELoss()
# 创建一个Adam优化器对象,用于更新模型参数以最小化损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 在PyTorch中定义一个全连接(线性)神经网络层,并将其添加到模型中
model.add_module('linear', nn.Linear(100, 1))
print("模型信息:---")
print(model)

训练模型
训练模型,每一组模型训练的时候,都要清除前面一组训练留下的隐含层信息,梯度清零的主要原因是为了梯度消失和梯度爆炸问题。y_pred = model(seq)就是调用了上面LSTM类中的forward,
epochs = 150
for i in range(epochs):
for seq, labels in train_inout_seq: # 遍历训练数据
optimizer.zero_grad() # 梯度清零
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size)) # 初始化隐藏层状态(不是参数)
# print(seq)
# print(labels)
y_pred = model(seq) # 模型前向传播
single_loss = loss_function(y_pred, labels) # 计算损失函数
single_loss.backward() # 反向传播求梯度
optimizer.step() # 更新参数
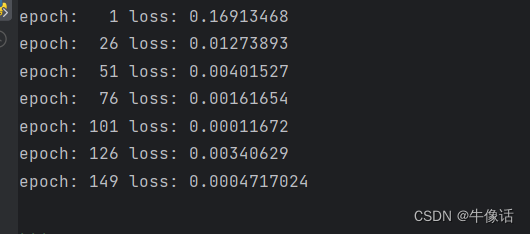
if i % 25 == 1: # 每25个epoch打印损失
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}') # 打印最终损失
LSTM类中的forward方法里的input_seq.view(len(input_seq), 1, -1)变形后如下,这些就是第一轮要进入到LSTM中训练的数据,每次进入一个,总共进入12次,正向传播,然后返回一个均方误差,用来和标签值计算损失,计算梯度,反向传播更新隐含层中的参数权重。
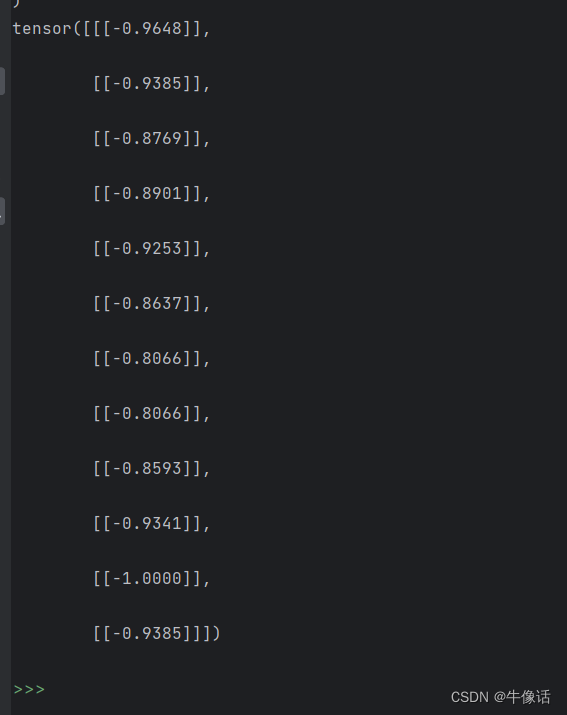
下图就是第一组数据的训练过程
下面是每25组数据训练完后和标签的误差值
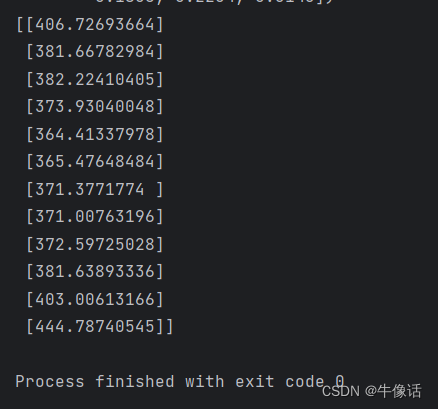
测试预测
下面是测试集代码,注释写的很清晰了,就不过多赘述了
# 预测测试集中的乘客数量
fut_pred = 12
# 获取最后12个月的数据
test_inputs = train_data_normalized[-train_window:].tolist()
print(test_inputs)
# 将模型设置为评估模式
model.eval()
for i in range(fut_pred):
# 将输入数据转换为PyTorch张量
seq = torch.FloatTensor(test_inputs[-train_window:])
# 隐藏层状态清零
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
print(seq)
# 第一次循环,会预测出第13个月的乘客数量
# 第二次循环,会把第一次预测的结果,作为12月
# tensor([0.1253, 0.0462, 0.3275, 0.2835, 0.3890, 0.6176, 0.9516, 1.0000, 0.5780,
# 0.3319, 0.1341, 0.3231])
# tensor([0.0462, 0.3275, 0.2835, 0.3890, 0.6176, 0.9516, 1.0000, 0.5780, 0.3319,
# 0.1341, 0.3231, 0.2997])
test_inputs.append(model(seq).item())
# 将预测结果还原到原始数据范围
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
print(actual_predictions)
下面是往后预测是12个月的数据
多参数预测
上面的试验,用的是单参数,但是为了让模型的拟合性更好,肯定是要使用多参数,那么上面的LSTM类中的__init__方法,input_size就需要改变,比如我们现在要预测每天坐飞机的人数,有机票价格,天气,湿度三个条件,数据量为一年。因为是三个特征值,那么input_size就是3,那么我们用3天来做序列长度,那么训练集应该是
训练值x=[
[ [0.1,0.2,0.3] ,[0.4,0.5,0.6] ,[0.7,0.8,0.9] ] ,//第一天,第二天,第三天
[ [0.4,0.5,0.6] ,[0.7,0.8,0.9] ,[0.11,0.12,0.13] ],//第二天,第三天,第四天
…
一直到第363行。就是第363天,因为366天没有数据
]
标签值y=[ 0.8,0.7,0.2…一直到第365 ]
0.8表示x中的第一行标签值,其含义是第四天的人数。
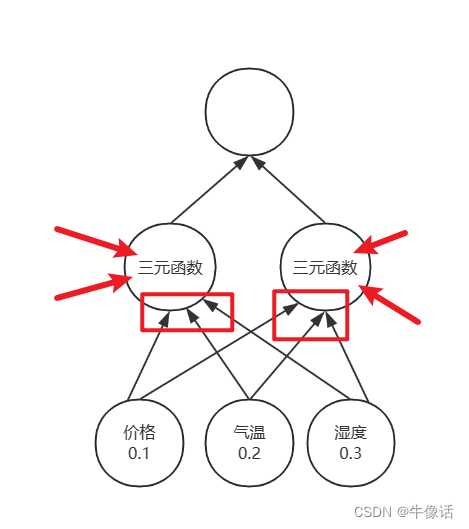
神经网络的结构大概如上,红色箭头表示上一次训练隐含层的输入,红框表示输入层参数,可以看出来,还是要输入一个三维的张量,其中一维是输入层输入的,另外两个是上个时刻隐含层输入的。