自定义函数用的最多的是单行函数,所以这里只介绍自定义单行函数。
Coding
导入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>编写代码
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyUDF extends GenericUDF {
/**
* 开始处理 SQL 之前执行一次,这里我们对参数做一个判断
* @param arguments 检查传进来的参数 inspector: 检察员,鉴别器
* @return
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 判断参数的个数
if (arguments.length != 1){
throw new UDFArgumentException("只接受一个参数");
}
ObjectInspector argument = arguments[0];
// 判断参数的类型 primitive:原始类型(int、char、boolean等) category: 类别
if (!argument.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(1,"只接受基本类型的参数");
}
// 参数类型直接受 String 类型
PrimitiveObjectInspector primitiveObjectInspector = (PrimitiveObjectInspector) argument;
if (primitiveObjectInspector.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("只接受String类型的参数");
}
// 函数本身返回 int 需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数的逻辑处理,每处理一行数据就调用一次这个方法
* 注意: 是一行数据
* @param arguments 输入参数
* @return 返回值
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
if (arguments[0].get()==null){
return 0;
}
return arguments[0].get().toString().length();
}
/**
* 获取在执行计划中展示的字符串
* explain HQL
* 这个不用实现,直接返回空字符串即可
*/
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
创建临时函数
(1)打成jar包上传到服务器/opt/module/hive/datas/myudf.jar
(2)将jar包添加到hive的classpath,临时生效
hive (default)> add jar /opt/module/hive/datas/myudf.jar;

(3)创建临时函数与开发好的java class关联
hive (default)> create temporary function my_len as “MyUDF”;(要求是全类名,这里我的类直接在java目录下)

(4)即可在hql中使用自定义的临时函数
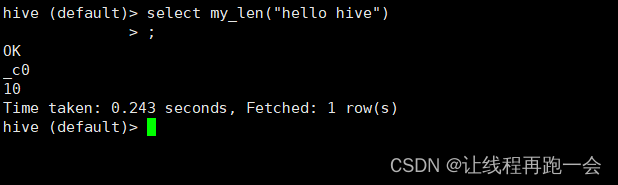
hive (default)> select my_len("hello world");

(5)删除临时函数
hive (default)> drop temporary function my_len;
注意:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
创建永久函数
add jar 是临时生效,所以在创建永久函数的时候,需要指定路径(因为永久函数是存储在Hive Metastore中的函数,可以在多个查询和会话中共享和重用。通过将JAR文件存储在HDFS上,并确保Hive可以访问该路径,可以方便地共享和使用这些函数。)
指定using jar为HDFS路径的好处包括:
- 共享性:HDFS是Hadoop分布式文件系统,可以在集群中的多个节点之间共享数据。将JAR文件存储在HDFS上,可以使得Hive函数在集群中的任何节点上都可以访问和使用。
- 可靠性:HDFS具有高度的容错性和可靠性,可以确保JAR文件的可用性和持久性。即使某个节点发生故障,JAR文件也可以从其他节点恢复。
- 一致性:通过在HDFS上存储JAR文件,可以确保所有Hive会话和查询都使用相同版本的函数代码。这有助于维护数据一致性和结果的一致性。
上传 jar 包到 HDFS :

create function my_len
as "MyUDF"
using jar "hdfs://hadoop102:8020/udf/myudf.jar";
测试使用效果:
show functions like "*my_len"
注意:永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上 库名.函数名