ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【五】SpringBoot整合elasticSearch | https://blog.csdn.net/zhenghuishengq/article/details/134212200 |
SpringBoot整合elasticSearch
- 一,SpringBoot整合ElasticSearch
- 1,需要的依赖以及版本
- 2,创建config配置类并测试连接
- 3,增删改查测试
- 3.1,索引插入数据
- 3.2,根据id查询数据
- 3.3,删除一条数据
- 4,普通查询
- 4.1,match条件查询
- 4.2,term精确匹配
- 4.3,prefix前缀查询
- 4.4,通配符查询wildcard
- 4.5,范围查询
- 4.6,fuzzy模糊查询
- 4.7,highlight高亮查询
- 5,聚合查询
- 5.1,aggs聚合查询
- 5.2,获取最终结果
一,SpringBoot整合ElasticSearch
前面几篇讲解了es的安装,dsl语法,聚合查询等,接下来这篇主要就是讲解通过java的方式来操作es,这里选择通过springboot的方式整合ElasticSearchSearch
在学习这个整合之前,可以查看对应的官网资料:https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/7.17/connecting.html
1,需要的依赖以及版本
首先创建springboot项目,然后需要的依赖如下,我前面用的是7.7.0的版本,因此这里继续使用这个版本。其他的依赖根据个人需要选择
<properties>
<java.version>8</java.version>
<elasticsearch.version>7.7.0</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.7.0</version>
</dependency>
</dependencies>
2,创建config配置类并测试连接
随后创建一个config的配置类,用于连接上ElasticSearch,我这边是单机版,并没有集群
/**
* 连接es的工具类
*/
@Configuration
public class ElasticSearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("xx.xx.xx.xx", 9200, "http")));
return client;
}
}
在创建好了之后,可以直接在test类中进行测试,看能否连接成功
@RunWith(SpringRunner.class)
@SpringBootTest
public class StudyApplicationTests {
@Resource
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println(restHighLevelClient);
}
}
在运行之后,如果打印出了以下这句话,表示整合成功
org.elasticsearch.client.RestHighLevelClient@7d151a
3,增删改查测试
3.1,索引插入数据
首先先创建一个users的索引,并向里面插入一条数据。插入和更新都可以用这个方法
//创建一个user索引,并且插入一条数据
@Test
public void addData() throws IOException {
//创建一个索引
IndexRequest userIndex = new IndexRequest("users");
User user = new User();
user.setId(1);
user.setUsername("Tom");
user.setPassword("123456");
user.setAge(18);
user.setSex("女");
//添加数据
userIndex.source(JSON.toJSONString(user), XContentType.JSON);
IndexResponse response = client.index(userIndex, ElasticSearchConfig.COMMON_OPTIONS);
//响应数据
System.out.println(response);
}
随后再在kibana中查询这个索引,可以看到这条数据是已经插入成功的,并且索引页创建成功
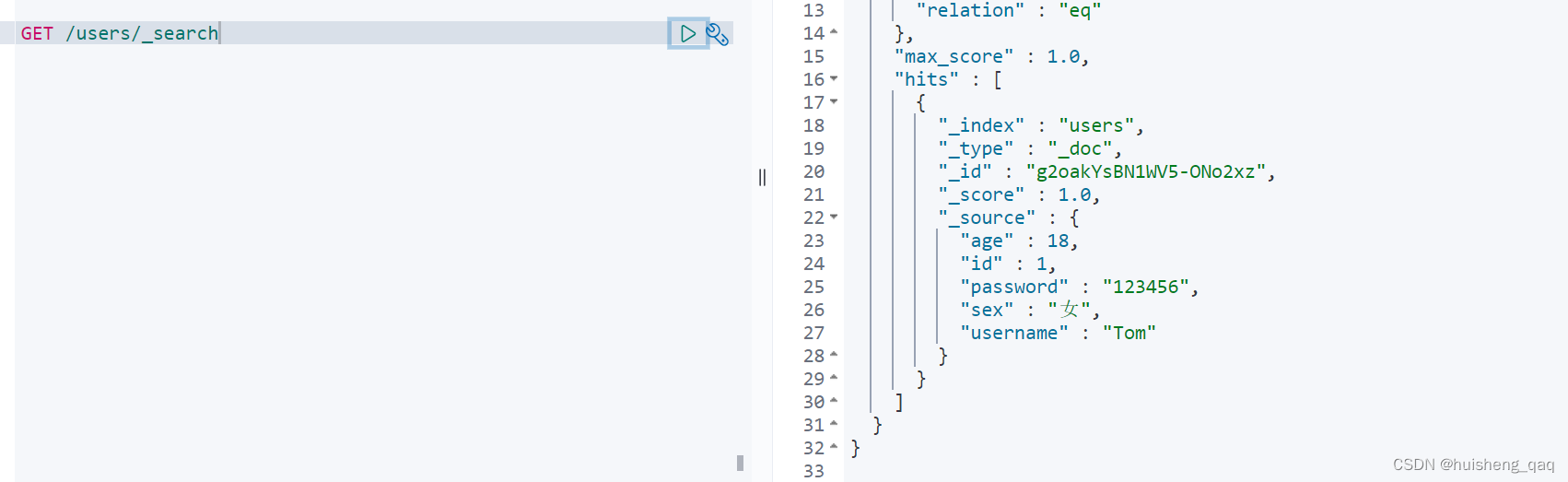
3.2,根据id查询数据
查询id为1的数据,需要通过QueryBuild构造器查询
@Test
public void getById() throws IOException {
SearchRequest request = new SearchRequest("users");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("id", "1"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
}
3.3,删除一条数据
删除刚刚创建的这条数据,这里直接设置id为1即可
@Test
public void deleteById() throws Exception{
DeleteRequest request = new DeleteRequest("users");
request.id("1");
DeleteResponse delete = client.delete(request, ElasticSearchConfig.COMMON_OPTIONS);
System.out.println(delete);
}
4,普通查询
这里主要是结合本人写的第三篇Query DSL的语法,通过java的方式写出依旧是先创建一个员工的信息索引,并且设置字段得我属性
PUT /employees
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"job":{
"type": "keyword"
},
"salary":{
"type": "integer"
}
}
}
}
随后批量的插入10条数据
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "huisheng1","job":"python","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "huisheng2","job":"java","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "huisheng3","job":"python","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "huisheng4","job":"java","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "huisheng5","job":"javascript","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "huisheng6","job":"javascript","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "huisheng7","job":"c++","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "huisheng8","job":"c++","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "huisheng9","job":"java","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "huisheng10","job":"java","salary": 9000}
4.1,match条件查询
首先是分页查询,分页查询的queryDSL的语法如下
GET /employees/_search
{
"query": {
"match": {
"job": "java"
}
}
}
java的语法如下
SearchRequest request = new SearchRequest("employees");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("job", "java"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
短语匹配的语法如下
builder.query(QueryBuilders.matchPhraseQuery("job","java"));
多字段查询的语法如下
String fields[] = {"job","name"};
builder.query(QueryBuilders.multiMatchQuery("java",fields));
queryString的语法如下
builder.query(QueryBuilders.queryStringQuery("java"));
4.2,term精确匹配
GET /employees/_search
{
"query": {
"term": {
"job": "java"
}
}
}
精确匹配通过java的方式如下
builder.query(QueryBuilders.termQuery("job","java"));
4.3,prefix前缀查询
PUT /employees/_search
{
"query":{
"prefix":{
"name":{
"value":"huisheng1"
}
}
}
}
前缀查询的java方式如下
builder.query(QueryBuilders.prefixQuery("name","huisheng1"));
4.4,通配符查询wildcard
GET /employees/_search
{
"query": {
"wildcard": {
"job": {
"value": "*py*"
}
}
}
}
通配符查询的java方式如下
builder.query(QueryBuilders.wildcardQuery("job","py"));
4.5,范围查询
POST /employees/_search
{
"query": {
"range": {
"salary": {
"gte": 25000
}
}
}
}
范围查询的java方式如下
builder.query(QueryBuilders.rangeQuery("salary").gte(25000));
4.6,fuzzy模糊查询
GET /employees/_search
{
"query": {
"fuzzy": {
"job": {
"value": "javb",
"fuzziness": 1 //表示允许错一个字
}
}
}
}
模糊查询的java方式如下
builder.query(QueryBuilders.fuzzyQuery("job","javb").fuzziness(Fuzziness.ONE));
4.7,highlight高亮查询
GET /employees/_search
{
"query": {
"term": {
"job": {
"value": "java"
}
}
},
"highlight": {
"fields": {
"*":{}
}
}
}
高亮查询的java方式如下
builder.query(QueryBuilders.termQuery("job","java"));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("job");
builder.highlighter(highlightBuilder);
5,聚合查询
5.1,aggs聚合查询
先通过job进行分组查询,再拿到结果后再进行stats查询,求最大值,最小值,平均值等
POST /employees/_search
{
"size": 0,
"aggs": {
"name": {
"terms": {
"field": "job"
},
"aggs": {
"stats_salary": {
"stats": {
"field": "salary"
}
}
}
}
}
}
其java代码如下,需要注意的点就是,如果存在二级聚合,那么需要调用这个 subAggregation 方法,如果只需要聚合的结果而不需要查询的结果,可以直接在SearchSourceBuilder的实例设置为0即可。
@Test
public void toAgg() throws Exception{
//创建检索请求
SearchRequest searchRequest = new SearchRequest();
//指定索引
searchRequest.indices("employees");
//构建检索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//构建聚合条件
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("jobData").field("job");
aggregationBuilder.subAggregation(AggregationBuilders.stats("salaryData").field("salary"));
//将聚合条件加入到检索条件中
builder.aggregation(aggregationBuilder);
//只要聚合的结果,不需要查询的结果
builder.size(0);
searchRequest.source(builder);
//执行检索
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("检索结果:" + searchResponse);
}
打印的结果如下,和预期要打印的结果是一致的
{"took":4,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":10,"relation":"eq"},"max_score":null,"hits":[]},"aggregations":{"sterms#jobData":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"java","doc_count":4,"stats#salaryData":{"count":4,"min":9000.0,"max":50000.0,"avg":25750.0,"sum":103000.0}},{"key":"c++","doc_count":2,"stats#salaryData":{"count":2,"min":20000.0,"max":20000.0,"avg":20000.0,"sum":40000.0}},{"key":"javascript","doc_count":2,"stats#salaryData":{"count":2,"min":18000.0,"max":25000.0,"avg":21500.0,"sum":43000.0}},{"key":"python","doc_count":2,"stats#salaryData":{"count":2,"min":18000.0,"max":35000.0,"avg":26500.0,"sum":53000.0}}]}}}
除了上面的state求全部的最大值,最小值等,还可以分别的求最大值,最小值,平均值,个数等,求平均值的的示例如下,需要使用到这个 AvgAggregationBuilder 构造器
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("salaryData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(avgAggregationBuilder);
求最大值的示例如下,需要使用到这个 MaxAggregationBuilder 构造器
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("maxData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(maxAggregationBuilder);
求最小值的示例如下,需要使用到这个 MinAggregationBuilder 构造器
MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("minData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(minAggregationBuilder);
求总个数的示例如下,需要使用到这个 ValueCountAggregationBuilder 构造器
ValueCountAggregationBuilder countBuilder = AggregationBuilders.count("countData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(countBuilder);
5.2,获取最终结果
上面在查询之后,会获取 SearchResponse 的对象,这里面就值执行查询后返回的结果
SearchResponse searchResponse
随后可以直接过滤结果,通过for循环去遍历这个 getHits
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Employees employees = JSON.parseObject(sourceAsString, Employees.class);
System.out.println(employees);
}
或者直接获取聚合操作结果的值
//获取jobData聚合。还有Avg、Max、Min等
Terms maxData = aggregations.get("jobData");
for (Terms.Bucket bucket : maxData.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("job职业:" + keyAsString + " 数量==> " + bucket.getDocCount());
}