✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、代码参考
- 五、论文参考
- 六、系统视频
- 结语
一、前言
随着现代科技的发展和人们生活水平的提高,旅游已经变成了一种日常的休闲方式。同时,大数据技术的出现为旅游行业提供了机遇。通过收集和分析海量的数据,我们能够更深入地理解游客的行为和需求,进一步优化旅游服务,提高游客满意度。因此,基于大数据的热门旅游景点数据分析成为了当前研究的热点问题。本课题旨在通过对旅游规模数据、实时客流量、旅游线路推荐、省内省外游客来源、景点排行、游客驻留时间数据、游客特征等方面的分析,为旅游行业提供更准确的决策支持。
当前,虽然很多旅游企业已经开始利用大数据技术来提升他们的服务,但是在数据收集、处理和分析方面仍然存在一些问题。首先,数据来源不全面,很多旅游企业只能从自己的业务系统中收集数据,忽略了其他来源的数据,如社交媒体、搜索引擎等。其次,数据处理方法不够先进,很多旅游企业仍然采用传统的数据处理方法,无法处理海量数据和实时数据。最后,数据分析不深入,很多旅游企业只是简单地统计数据,没有深入挖掘数据的潜在价值。
本课题的主要目的是通过对热门旅游景点的数据分析,为旅游行业提供更准确的决策支持。具体来说,本课题将实现以下目标:
收集和分析旅游规模数据,了解旅游市场的整体情况;
收集和分析实时客流量数据,预测未来的客流量趋势;
根据游客来源数据,分析不同地区的游客数量和偏好,为旅游线路设计提供参考;
根据景点排行数据,了解游客对不同景点的评价和偏好,为景点优化提供参考;
收集和分析游客驻留时间数据,了解游客在景点的停留时间和游览路线,为景区管理提供参考;
根据游客特征分析,了解不同类型游客的需求和偏好,为个性化服务提供参考。
本课题的研究意义在于为旅游行业提供更准确的决策支持,帮助旅游企业提高服务质量和效率。具体来说,本课题的研究成果将有助于解决当前旅游行业中存在的一些问题,如数据收集不全、数据处理方法落后、数据分析不深入等。同时,本课题的研究成果还将为旅游行业的发展提供新的思路和方法,如基于大数据的旅游线路设计、景点优化和个性化服务等。因此,本课题的研究成果具有重要的理论和实践意义。
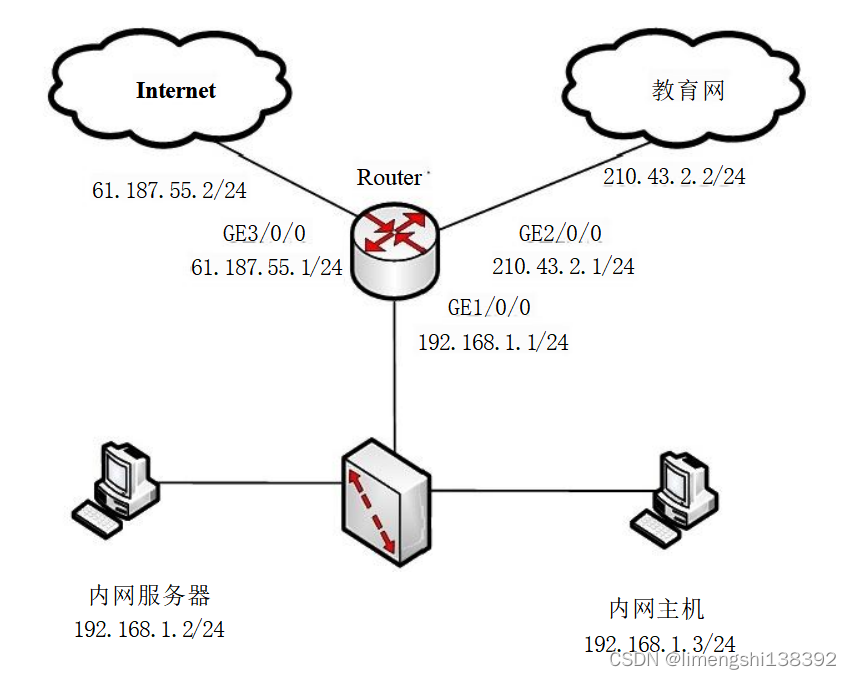
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
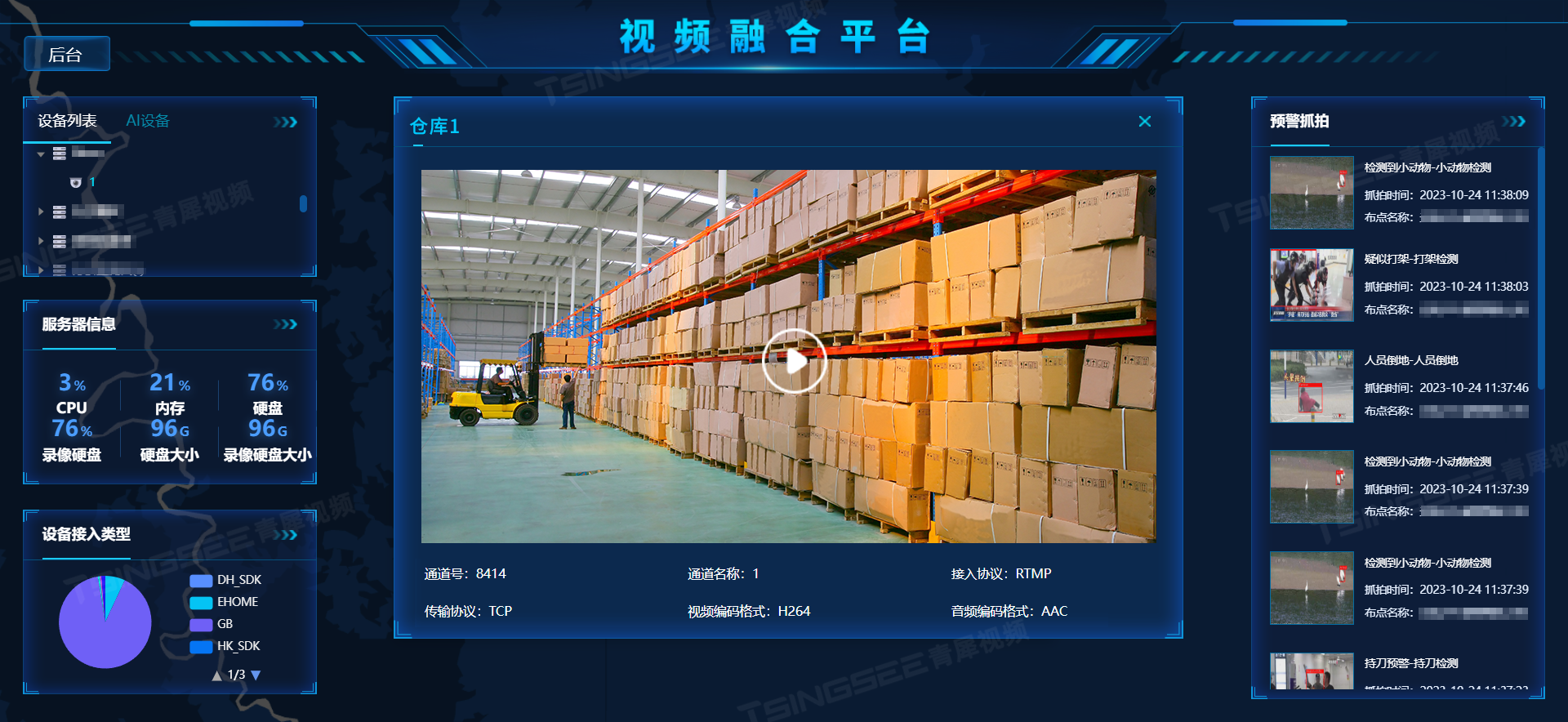
三、系统界面展示
- 热门旅游景点数据分析界面展示:







四、代码参考
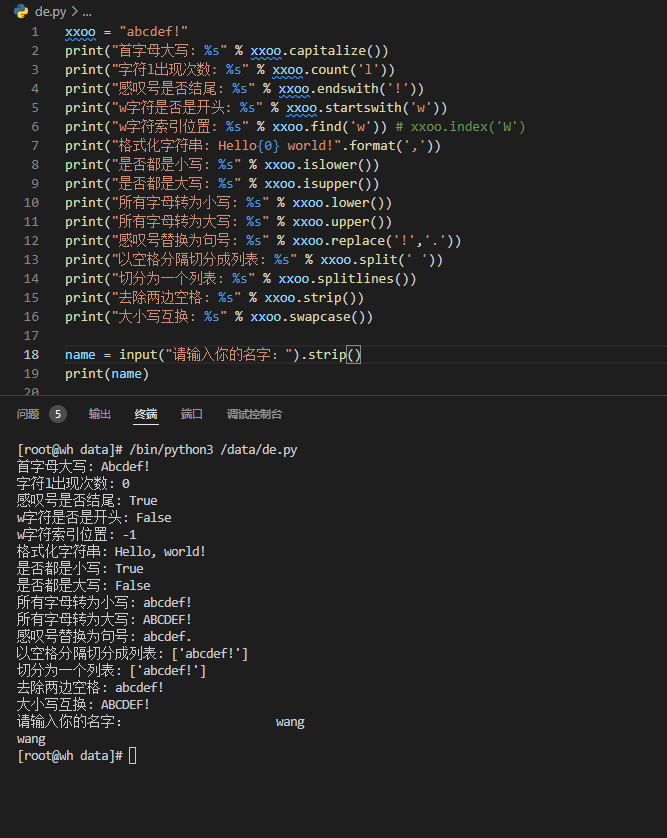
- 热门旅游景点数据分析项目实战代码参考:
class MySpider:
def open(self):
self.con = sqlite3.connect("lvyou.db")
self.cursor = self.con.cursor()
sql = "create table lvyou (title varchar(512),price varchar(16),destination varchar(512),feature text)"
try:
self.cursor.execute(sql)
except:
self.cursor.execute("delete from Lvyou")
self.baseUrl = "https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af"
self.chrome = webdriver.Chrome()
self.count = 0
self.page = 0
self.pageCount = 0
def close(self):
self.con.commit()
self.con.close()
def insert(self, title, price, destination, feature):
sql = "insert into lvyou (title,price,destination,feature) values (?,?,?,?)"
self.cursor.execute(sql, [title, price, destination, feature])
def show(self):
self.con = sqlite3.connect("lvyou.db")
self.cursor = self.con.cursor()
self.cursor.execute("select title,price,destination,feature from lvyou")
rows = self.cursor.fetchall()
for row in rows:
print(row)
self.con.close()
def spider(self, url):
try:
self.page += 1
print("\nPage", self.page, url)
self.chrome.get(url)
time.sleep(3)
html = self.chrome.page_source
root = BeautifulSoup(html, "lxml")
div = root.find("div", attrs={"id": "xy_list"})
divs = div.find_all("div", recursive=False)
for i in range(len(divs)):
title = divs[i].find("h2").text
price = divs[i].find("span", attrs={"class": "base_price"}).text
destination = divs[i].find("p", attrs={"class": "product_destination"}).find("span").text
feature = divs[i].find("p", attrs={"class": "product_feature"}).text
print(title, '\n预付:', price, "\n", destination, feature)
if self.page == 1:
link = root.find("div", attrs={"class": "pkg_page basefix"}).find_all("a")[-2]
self.pageCount = int(link.text)
print(self.pageCount)
if self.page < self.pageCount:
url = self.baseUrl + "&filters=p" + str(self.page + 1)
self.spider(url)
self.insert(title, price, destination, feature)
except Exception as err:
print(err)
def process(self):
url = "https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af"
self.open()
self.spider(url)
self.close()
'''
spider = MySpider()
spider.open()
spider.spider("https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af")
spider.close()
'''
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
print("Start.....")
spider.process()
print("Finished......")
elif s == "2":
spider.show()
else:
break
class MySpider:
def open(self):
self.con = MySQLdb.connect(host="127.0.0.1", port=3306, user='root', password="19980507",
db="lvyou", charset='utf8')
self.cursor = self.con.cursor()
sql = "create table lvyou (title varchar(512),price varchar(16),destination varchar(512),feature text)"
try:
self.cursor.execute(sql)
except:
self.cursor.execute("delete from lvyou")
self.baseUrl = "https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af"
self.chrome = webdriver.Chrome()
self.count = 0
self.page = 0
self.pageCount = 0
def close(self):
self.con.commit()
self.con.close()
def insert(self, title, price, destination, feature):
sql = "insert into lvyou (title,price,destination,feature) values (%s,%s,%s,%s)"
self.cursor.execute(sql, [title, price, destination, feature])
def show(self):
self.con = MySQLdb.connect(host="127.0.0.1", port=3306, user='root', password="19980507",
db="lvyou", charset='utf8')
self.cursor = self.con.cursor()
self.cursor.execute("select title,price,destination,feature from lvyou")
rows = self.cursor.fetchall()
i=1
for row in rows:
print(i,row)
i+=1
print("Total:",len(rows))
self.con.close()
def spider(self, url):
try:
self.page += 1
print("\nPage", self.page, url)
self.chrome.get(url)
time.sleep(3)
html = self.chrome.page_source
root = BeautifulSoup(html, "lxml")
div = root.find("div", attrs={"id": "xy_list"})
divs = div.find_all("div", recursive=False)
for i in range(len(divs)):
title = divs[i].find("h2").text
price = divs[i].find("span", attrs={"class": "base_price"}).text
destination = divs[i].find("p", attrs={"class": "product_destination"}).find("span").text
feature = divs[i].find("p", attrs={"class": "product_feature"}).text
print(title, '\n预付:', price, "\n", destination, feature)
if self.page == 1:
link = root.find("div", attrs={"class": "pkg_page basefix"}).find_all("a")[-2]
self.pageCount = int(link.text)
print(self.pageCount)
if self.page < self.pageCount:
url = self.baseUrl + "&filters=p" + str(self.page + 1)
self.spider(url)
self.insert(title, price, destination, feature)
except Exception as err:
print(err)
def process(self):
url = "https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af"
self.open()
self.spider(url)
self.close()
'''
spider = MySpider()
spider.open()
spider.spider("https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af")
spider.close()
'''
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
print("Start.....")
spider.process()
print("Finished......")
elif s == "2":
spider.show()
else:
break
五、论文参考
- 计算机毕业设计选题推荐-热门旅游景点数据分析论文参考:

六、系统视频
热门旅游景点数据分析项目视频:
大数据毕业设计选题推荐-热门旅游景点数据分析-Hadoop
结语
大数据毕业设计选题推荐-热门旅游景点数据分析-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目