执行计划生成的几种方式
1. EXPLAIN FOR
语法:
EXPLAIN PLAN FOR
SQL语句
SELECT * FROM TABLE(dbms_xplan.display());
优点:
- 无需真正执行SQL
缺点:
- 没有输出相关的统计信息,例如产生了多少逻辑读、物理读、递归调用等情况
- 无法判断处理了多少行
- 无法判断表执行了多少次
例子:
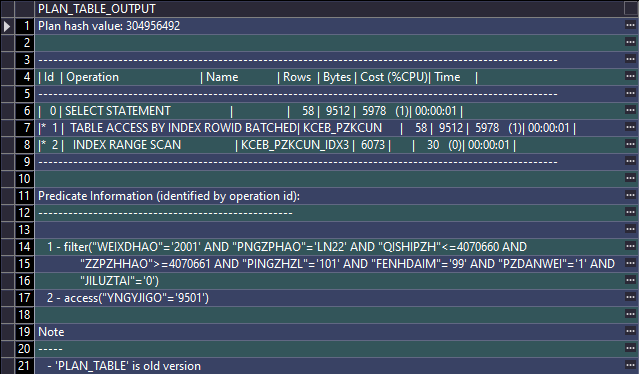
EXPLAIN PLAN FOR
SELECT *
FROM kceb_pzkcun
WHERE yngyjigo = '9501'
AND weixdhao = '2001'
AND pingzhzl = '101'
AND fenhdaim = '99'
AND pngzphao = 'LN22'
AND qishipzh <= 4070660
AND 4070661 <= zzpzhhao
AND pzdanwei = '1'
AND jiluztai = '0';
SELECT * FROM TABLE(dbms_xplan.display());
2. SET AUTOTRACE ON|TRACEONLY[EXPLAIN]
注:该功能只能在SQLPLUS模式下使用
语法:
SET AUTOTRACE ON|TRACEONLY;
SQL语句;
SET AUTOTRACE OFF;
优点:
- 可以输出运行时的相关统计信息
- 虽然要等待语句执行完毕,但是可以通过TRACEONLY选项来控制返回结果不输出
缺点:
- 必须要等待语句执行完毕
- 无法看到表被访问了错少次
例子:
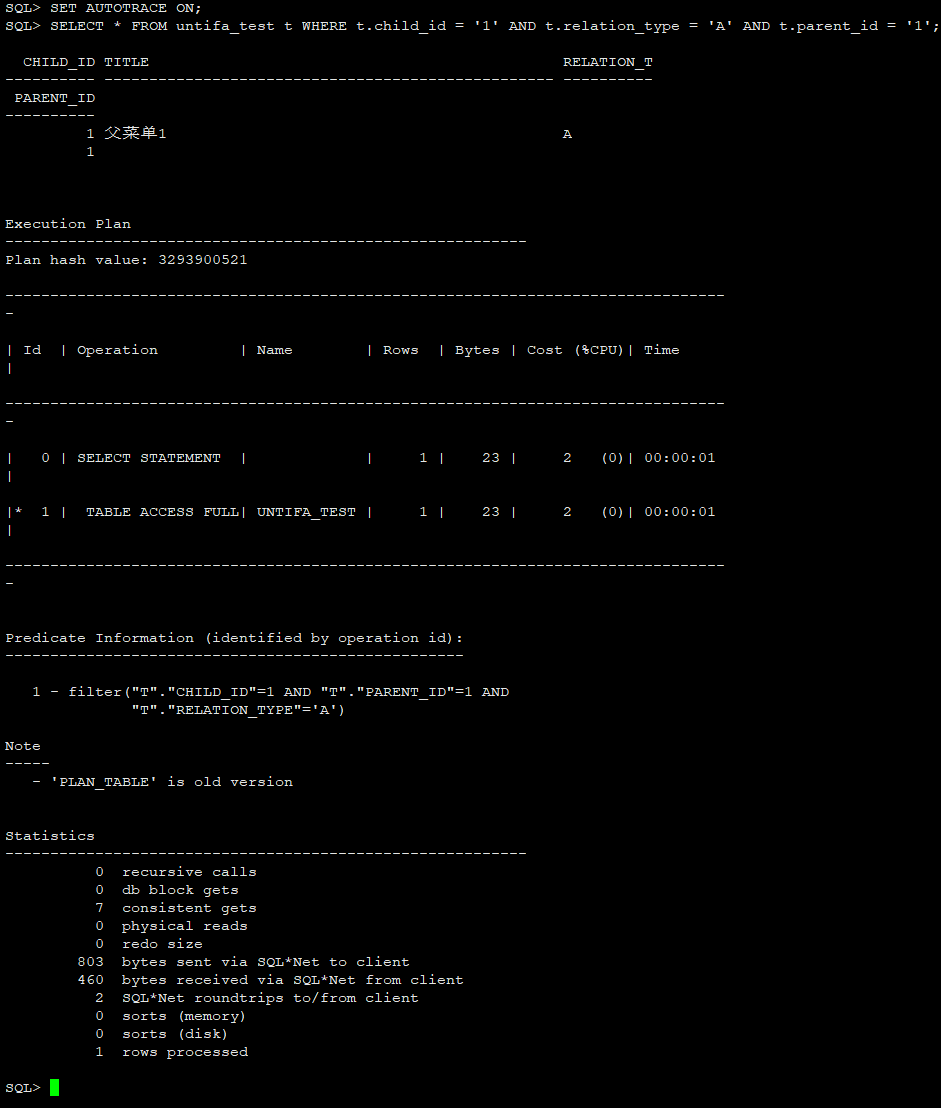
SET AUTOTRACE ON;
SELECT * FROM untifa_test t WHERE t.child_id = '1' AND t.relation_type = 'A' AND t.parent_id = '1';
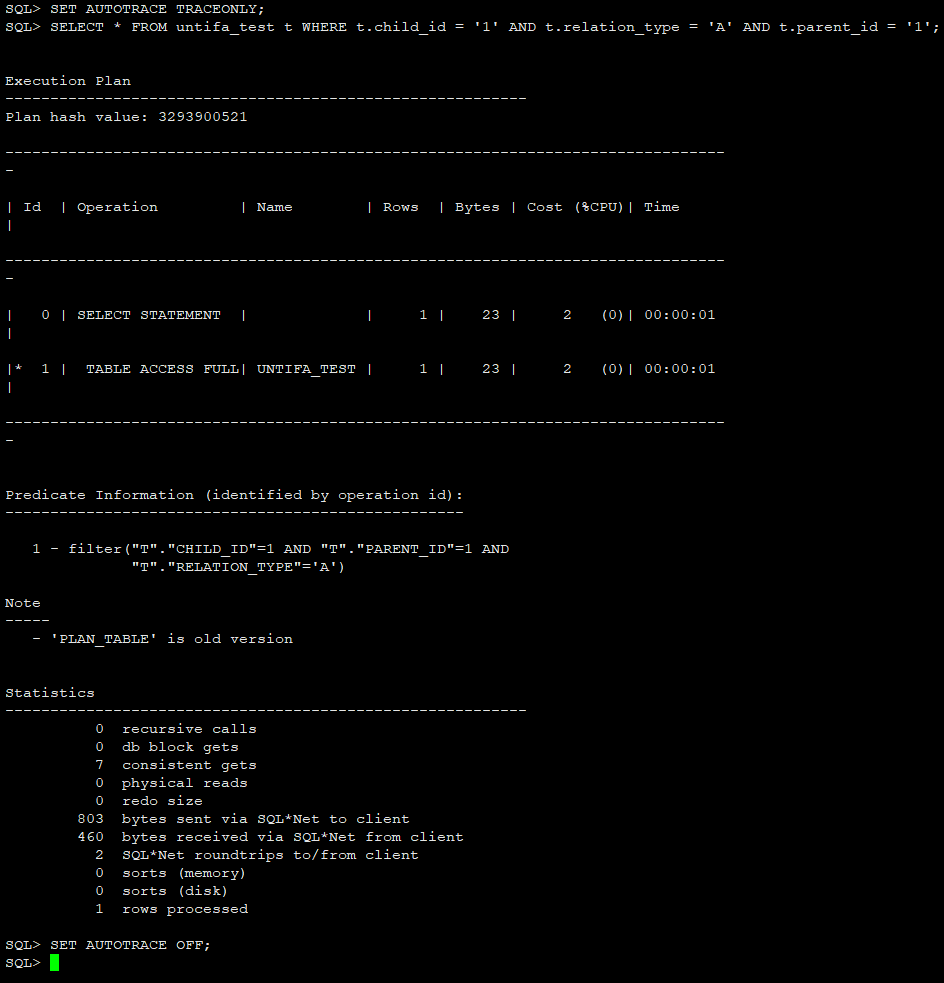
SET AUTOTRACE TRACEONLY;
SELECT * FROM untifa_test t WHERE t.child_id = '1' AND t.relation_type = 'A' AND t.parent_id = '1';
SET AUTOTRACE OFF;
3. STATISTICS_LEVEL=ALL
上面两种方法,使用AUTOTRACE或者EXPLAIN PLAN FOR 获取的执行计划来自于PLAN_TABLE。PLAN_TABLE是一个会话级的临时表,里面的执行计划并不是SQL真实的执行计划,它只是优化器估算出来的。真实的执行计划不应该是估算的,应该是真正执行过的。SQL执行过的执行计划存在于共享池中,具体存在于数据字典V$SQL_PLAN中,带有A-Time的执行计划来自于V$SQL_PLAN,是真实的执行计划,而通过AUTOTRACE、通过EXPLAIN PLAN FOR获取的执行计划只是优化器估算获得的执行计划。
以下这种方法可以获取真执行计划
语法:
ALTER SESSION SET STATISTICS_LEVEL=ALL;
SQL语句;
SELECT v.last_active_time, v.*
FROM v$sql v
WHERE v.last_active_time >
to_date('日期', '日期格式')
AND v.parsing_schema_name = 'SCHEMA'
AND v.sql_text LIKE '%SQL语句%'
ORDER BY v.last_active_time DESC;
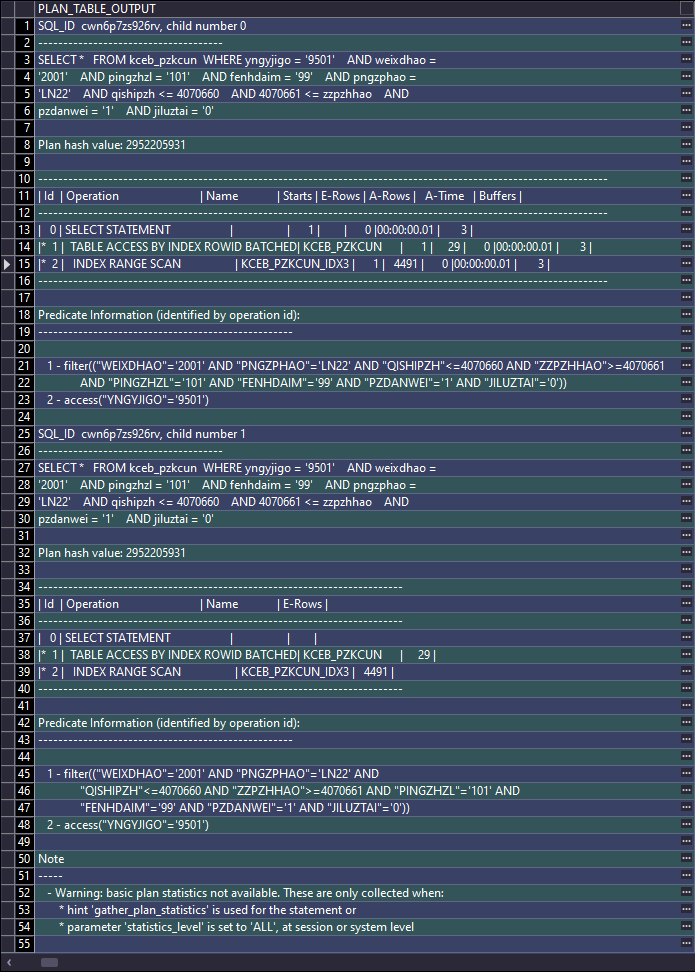
SELECT *
FROM TABLE(dbms_xplan.display_cursor(sql_id => 'cwn6p7zs926rv',
cursor_child_no => NULL,
format => 'allstats last'));
优点:
- 可以得到运行时的相关信息
缺点:
- 必须要等待语句执行完毕才能得到结果
- 无法控制结果打印输出
Starts 表示这个操作执行的次数
E-Rows表示优化器估算的行数,就是普通执行计划中的Rows
A-Rows表示真实的行数
A-Time表示累加的总时间。与普通执行计划不同的是,普通执行计划中的Time是假的,而A-Time是真实的。
Buffers表示累加的逻辑读
Reads表示累加的物理读
需要注意的是,普通执行计划估算出来的行数,受直方图统计信息的影响,可能会使优化器对执行计划的选择产生误判(例如本该走HASH JOIN,结果变成NESTED LOOPS)。因此,直方图统计信息应该定期更新。
获取真执行计划需要相应的权限GRANT SELECT ANY DICTIONARY TO HXAPP;
例子:
SHOW PARAMETER STATISTICS_LEVEL;
ALTER SESSION SET STATISTICS_LEVEL=ALL;
SELECT *
FROM kceb_pzkcun
WHERE yngyjigo = '9501'
AND weixdhao = '2001'
AND pingzhzl = '101'
AND fenhdaim = '99'
AND pngzphao = 'LN22'
AND qishipzh <= 4070660
AND 4070661 <= zzpzhhao
AND pzdanwei = '1'
AND jiluztai = '0';
SELECT v.last_active_time, v.*
FROM v$sql v
WHERE v.last_active_time >
to_date('2023/11/02 14:00:00', 'yyyy/mm/dd hh24:mi:ss')
AND v.parsing_schema_name = 'HXAPP'
AND v.sql_text LIKE '%kceb_pzkcun%'
ORDER BY v.last_active_time DESC;
SELECT *
FROM TABLE(dbms_xplan.display_cursor(sql_id => 'cwn6p7zs926rv',
cursor_child_no => NULL,
format => 'allstats last'));
4. dbms_xplan.display_cursor
语法:
SELECT *
FROM TABLE(dbms_xplan.display_cursor(sql_id => '',
cursor_child_no => n,
format => 'allstats last'));
select * from table( dbms_xplan.display_awr(‘&sql_id’) ); --该方法是从awr性能视图里面获取
如果有多个执行计划,可用以下方法查出:
select * from table(dbms_xplan.display_cursor(‘&sql_id’,0));
select * from table(dbms_xplan.display_cursor(‘&s ql_id’,1));
5. 事件10046 trace跟踪(未验证)
步骤1:alter session set events ‘10046 trace name context forever,level 12’; --开启追踪
步骤2:执行sql语句;
步骤3:alter session set events ‘10046 trace name context off’; --关闭追踪
步骤4:select tracefile from v$process where addr=(select paddr from v$session where sid=(select sid from v$mystat where rownum<=1)); --找到跟踪后产生的文件
步骤5:tkprof trc文件 生成目标文件 sys=no sort=prsela,exeela,fchela --格式化命令
6. awrsqrpt.sql
生成awr报告查看
具体参考:
Oracle-AWR报告生成方法
浅析数据库访问数据的几种方式
常见的执行计划及简单解释
一、访问表执行计划
1、table access full:全表扫描。它会访问表中的每一条记录(读取高水位线以内的每一个数据块)。
2、table access by user rowid:输入源rowid来自于用户指定。
3、table access by index rowid:输入源rowid来自于索引。
4、table access by global index rowid:全局索引获取rowid,然后再回表。
5、table access by local index rowid:分区索引获取rowid,然后再回表。
6、table access cluster:通过索引簇的键来访问索表。
7、external table access:访问外部表。
8、result cache:结果集可能来自于缓存。
9、mat_view rewrite access:物化视图。
二、与B-TREE索引相关的执行计划
1、index unique scan:只返回一条rowid的索引扫描,或者unique索引的等值扫描。
2、index range scan:返回多条rowid的索引扫描。
3、index full scan:顺序扫描整个索引。
4、index fast full scan:多块读方式扫描整个索引。
5、index skip scan:多应用于组合索引中,引导键值为空的情况下索引扫描。
6、and-equal:合并来自于一个或多个索引的结果集。
7、domain index:应用域索引。
三、与BIT-MAP索引相关的执行计划
1、bitmap conversion:将位转换为rowid或相反。
2、bitmap index:从位图中取一个值或一个范围。
3、bitmap merge
4、bitmap minus:
5、bitmap or:
四、与表连接相关的执行计划
1、merge join:排序合并连接。
2、nested loops:嵌套循环连接。
3、hash join:哈希连接。
4、cartesian:笛卡尔积连接。
5、connect by:层次查询索引,多来自于start with子句。
6、outer:外链接。
1)merge join outer:
2)nested loops outer:
3)hash join outer:
7、anti:反连接。
1)merge join anti:
2)nested loops anti:
3)hash join anti:
8、semi:半连接。
1)merge join semi:
2)nested loops semi:
3)hash join semi:
五、与集合相关的执行计划
1、union-all:
2、union(union-all,sort unique):
3、concatenation:
4、intersection:
5、minus:
六、与分区相关的索引
1、partition single:访问单个分区。
2、partition iterator:访问多个分区。
3、partition all:访问所有分区。
4、partition inlist:基于in列表中的值来访问分区。
七、与sort相关的执行计划
1、sort unique:排序、去重。
2、sort join:为merge join的第一步,排序操作,一般与merge join联合使用。
3、sort aggregate:当分组好的数据上使用分组函数时。
4、sort order by:单纯的排序
5、sort group by:排序并分组
6、buffer sort:对临时结果进行一次内存排序。
八、其他执行计划
1、view:
2、count:
3、stopkey:目标sql中存在rownum<10这种情况。
4、hash group by:
5、inlist iterator:
6、filter:过滤,相当于处理过的排序合并连接。
7、remote:与dblink相关的执行计划。
8、for update:
9、sequence:使用了oracle序列。
10、collection iterator:使用了表函数提取记录。
11、fast dual:访问dual表。
12、first row:获取查询的第一条记录。
13、load as select:使用select进行直接路径insert操作,通常加/+append/提示。
14、fixed table:访问固定的(X/V)表。
15、fixed index:访问固定的索引。
16、window buffer:支持分析函数的内部操作。
了解几种基础概念
- 1、ROWID的概念,Oracle的一个虚拟列,用于命中索引后回表(根据ROWID去文件块的某个位置读取数据),ROWID在该行的生命周期内是唯一的,即即使该行产生行迁移,行的ROWID也不会改变(对表空间进行改动、表重建或者重命名、impdp或expdp、数据库的备份和恢复、分区改动、表压缩等行为会造成ROWID的改变)
- 2、Recursive SQL概念:用户的ddl,dml操作会带来一些隐藏操作,显而易见的就是会修改数据字典,数据字典信息存储在内存中
- 3、Row Source(行源) :通俗点说就是查询或连接时的摸个表经过where条件过滤后剩下的结果集
- 4、Driving Table(驱动表):该表又称为外层表(OUTER TABLE)。这个概念用于嵌套与HASH连接中。
- 5、Probed Table(被探查表) 与4相反
- 6、组合索引(concatenated index):由多个列构成的索引,如create index idx_emp on emp(col1, col2, col3, ……),则我们称idx_emp索引为组合索引。在组合索引中有一个重要的概念:引导列(leading column),在上面的例子中,col1列为引导列。当我们进行查询时可以使用”where col1 = ? ”,也可以使用”where col1 = ? and col2 = ?”,这样的限制条件都会使用索引,但是”where col2 = ? ”查询就不会使用该索引。所以限制条件中包含先导列时,该限制条件才会使用该组合索引。
- 7、可选择性(selectivity):其实就是 distinct 这列/count(1)
- 8、ORACLE数据库逻辑结构包括:数据库块(block),区(extent),段(segment),表空间(tablespace)。高水位线存在于段中,用于标识段中已使用过的数据块与未使用过的数据块二者间交界.扫描表数据时,高水位线以下的所有数据块都必须被扫描。
高水位线存在于段,且位置记录在段头,也就是段的第一个数据块中。因此可以转储段头信息来看高水位线信息。段又分数据段、索引段、临时段、回滚段等.当创建段的时候会分配区,区是由若干个物理连续的数据块组成.区的分配是需要初始化数据块的,默认初始化单位为1M。注意:高水位线并不是初始化的交界片,被初始化过的数据块并不一定被使用过。
了解Oracle数据库读取数据的方法
直接访问数据
- 1、全表扫描
从第一个区(EXTENT)的第一个块(BLOCK)开始扫描,读取高水位线(High Water Mark)标记以下所有格式化块
可以过虑行
如允许则执行多块读 DB_FILE_MULTIBLOCK_READ_COUNT
数据量很大时,比索引范围扫描快
注意:数据量越多,全表扫描所需要的时间就越多,然后直接删了表数据呢?查询速度会变快?其实并不会的,因为即使我们删了数据,高位水线并不会改变,也就是同样需要扫描那么多数据块
- 2、通过ROWID
rowid需要10个字节来存储,由18个字符组成分4个部分。伪列类似表的列,但不实际存在于表中。ROWID也就是表数据行所在的物理存储地址,所谓的ROWID扫描是通过ROWID所在的数据行记录去定位。
前6位表示对象编号(Data Object number),其后3位文件编号(Relative file number),接着其后6位表示块编号(Block number), 再其后3位表示行编号(Row number)
ROWID编码方法是:A ~ Z表示0到25;a ~ z表示26到51;0~9表示52到61;+表示62;/表示63;刚好64个字符。 - 3、随机访问数据块 SAMPLE table scan
SELECT * FROM untifa_test SAMPLE BLOCK (41);
索引访问数据
- 1、索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)来说的,也就是建立唯一性索引才能索引唯一性扫描,唯一性扫描,其结果集只会返回一条记录。 - 2、索引范围扫描(INDEX RANGE SCAN)
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,一般不包括唯一性索引,因为唯一性索引走索引唯一性扫描。 当扫描的对象是非唯一性索引的情况,WHERE条件为BETWEEN、=、<、>等等的情况就是索引范围扫描,注意,可以是等值查询,也可以是范围查询。如果WHERE条件里有一个索引键值列没限定为非空的,那就可以走索引范围扫描,如果该索引列是非空的,那就走索引全扫描
前面说了,同样的SQL建的索引不同,就可能是走索引唯一性扫描,也有可能走索引范围扫描。在同等的条件下,索引范围扫描所需要的逻辑读和索引唯一性扫描对比,索引范围扫描可能返回多条记录,所以优化器为了确认,肯定会多扫描,所以在同等条件,索引范围扫描所需要的逻辑读至少会比相应的唯一性扫描的逻辑读多1。 - 3、索引全扫描(INDEX FULL SCAN)
适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。
索引全扫描过程简述:索引全扫描是指扫描目标索引所有叶子块的索引行,但不意思着需要扫描所有的分支块,索引全扫描时只需要访问必要的分支块,然后定位到位于改索引最左边的叶子块的第一行索引行,就可以利用改索引叶子块之间的双向指针链表,从左往右依次顺序扫描所有的叶子块的索引行。 - 4、索引快速全扫描(INDEX FAST FULL SCAN)
索引快速全扫描和索引全扫描很类似,也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描类似,也是扫描所有叶子块的索引行,这些都是索引快速全扫描和索引全扫描的相同点
索引快速全扫描和索引全扫描区别:
索引快速全扫描只适应于CBO(基于成本的优化器)
索引快速全扫描可以使用多块读,也可以并行执行
索引全扫描会按照叶子块排序返回,而索引快速全扫描则是按照索引段内存储块顺序返回
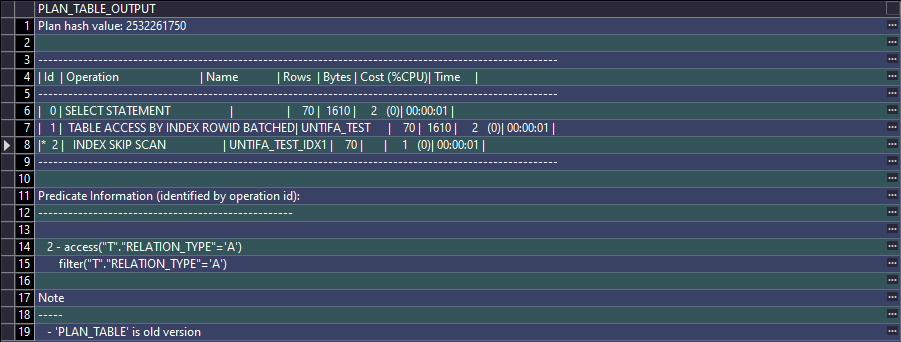
索引快速全扫描的执行结果不一定是有序的,而索引全扫描的执行结果是有序的,因为索引快速全扫描是根据索引行在磁盘的物理存储顺序来扫描的,不是根据索引行的逻辑顺序来扫描的 - 5、索引跳跃式扫描(INDEX SKIP SCAN)
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),索引跳跃式扫描可以使那些在where条件中没有目标索引的前导列指定查询条件但是有索引的非前导列指定查询条件的目标SQL依然可以使用跳跃索引,定义解释有点绕,举个例子说明,新建了复合索引:
create index UNTIFA_TEST_IDX1 on UNTIFA_TEST (PARENT_ID, RELATION_TYPE)
tablespace TEST_DATA
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
EXPLAIN PLAN FOR
SELECT * FROM untifa_test t WHERE t.relation_type = 'A';
SELECT * FROM TABLE(dbms_xplan.display());



![[动态规划] (四) LeetCode 91.解码方法](https://img-blog.csdnimg.cn/img_convert/0f7695a6f589d1b823bdbdcd4a2f9dec.png)