Python等级考试(1~6级)全部真题・点这里
一、单选题(共25题,每题2分,共50分)
第1题
二进制数101100111对应的十六进制数的数值是?
A:6
B:369
C:167
D:165
答案:B
将二进制数101100111分组为每4位一组,得到:10 1100 111。然后将每个4位二进制数转换为对应的十六进制数:
10 -> 2
1100 -> C
111 -> 7
将这些十六进制数字组合在一起,得到2C7,这个值在十进制中等于369。因此,正确答案是B。
第2题
Python中表示合法的八进制整数是?
A:0o129
B:0o12A
C:0O1708
D:0O1207
答案:D
在Python中,合法的八进制整数应该以前缀"0o"或"0O"开始,后跟八进制数字(0-7)的序列。
第3题
在Python中,int(‘10’,16)语句的作用是?
A:将十进制数10转化为十六进制数16
B:将十六进制数10转化为十进制数16
C:将字符串“10”转化为二进制整数
D:将字符串“10”转化为十六进制整数
答案:B
在Python中,int(‘10’, 16)语句的作用是将字符串表示的十六进制数转换为十进制数。
具体来说,int(‘10’, 16)将字符串"10"解析为十六进制数,然后将其转换为相应的十进制数。在这个例子中,字符串"10"表示十六进制数的值为16,因此这个语句的结果将是16。
第4题
八进制7与十六进制7相加,其对应的十进制数是?
A:21
B:7
C:14
D:77
答案:C
八进制的数字7对应的十进制数是7,十六进制的数字7对应的十进制数也是7。当这两个数相加时,其结果是14。
第5题
关于语句f=open(‘c:/abc.csv’, ‘r’),下列描述不正确的是?
A:f是变量名
B:以只读方式打开文件
C:如果文件abc.csv不存在,会创建abc.csv
D:'c:/abc.csv’代表c盘中一个名为’abc.csv’的文件
答案:C
打开文件的模式为’r’,表示只读方式打开文件。如果文件不存在,会抛出文件不存在的错误,而不会创建一个新的文件。
第6题
有如下从csv文件中读入数据的程序段,程序中存在错误的地方是?
f=open("abc.csv","r")
m=[]
for lines in f:
m.append(lines.strip("\n").split("\"))
f.close()
print(m)
A:“r”
B:lines.strip(“\n”)
C:split(“”)
D:f.close()
答案:C
在这个程序段中,调用split(“”)时使用了空字符串作为分隔符。然而,split()方法的参数应该是非空的分隔符字符串,用于将字符串拆分成多个部分。在这种情况下,应该提供一个有效的分隔符,例如逗号(,)或其他适当的字符。
第7题
对于a=len([2,3,4,5,[7,8],(9,10)]),a的值是?
A:4
B:6
C:8
D:7
答案:B
这是因为在列表中有6个元素,其中包括数字2、3、4、5、[7,8]和(9,10)。因此,len()函数返回列表中元素的数量,即6。
第8题
有关Python文件常用读写方式的描述,错误的是?
A:read() 每次读取整个文件
B:read() 生成的文件内容是一个字符串
C:readline() 每次只读取文件的一行
D:readlines() 每次按行读取整个文件内容,将读取到的内容放到一个字符串中
答案:D
事实上,readlines() 方法每次按行读取文件内容,并返回一个包含所有行的列表。每行作为列表中的一个元素,而不是放到一个字符串中。
第9题
以下代码,下列说法错误的是?
add=['北京','上海','广州','深圳']
f=open('city.csv','w')
f.write(','.join(add)+'\n')
f.close()
A:f=open(‘city.csv’,‘w’)说明当前是写入模式
B:f.write(‘,’.join(add)+‘\n’)语句改成f.write(’ ‘.join(add)+’\n’),程序运行效果一样
C:删除f.close()语句,不能正确保存文件
D:当前程序的功能是将列表对象输出到CSV文件
答案:B
将 , 替换为 ’ ’ (一个空格)会改变最后生成的文件内容。原始代码中使用逗号分隔每个城市名称,而改为空格后,城市名称之间将使用空格分隔。
因此,修改代码中的 , 为 ’ ’ 会导致程序输出的文件内容不同。
第10题
当发生异常时,下列描述正确的是?
A:需要捕获异常,然后进行相应的处理
B:需要把可能发生错误的语句放在except模块里
C:需要把处理异常的语句放在try模块里
D:需要为每一个try模块设定且只能设定一个except模块
答案:A
选项A 当可能发生异常的代码块被执行时,可以使用try-except语句来捕获异常,并在except块中处理异常情况。
选项B 异常应该在try块中捕获,而不是except块中。try块用于包含可能引发异常的代码,而except块用于处理捕获到的异常。
选项C 处理异常的语句通常放在except块中,而不是try块中。try块用于包含可能引发异常的代码,而except块用于处理捕获到的异常。
选项D 一个try块可以有多个except块,每个块可以处理不同类型的异常。这样可以根据不同的异常类型采取不同的处理方式。
因此,正确答案是A
第11题
下列程序段在运行时输入"2",则输出结果是?
try:
a=eval(input())
print(a)
except NameError:
print('Error!')
A:”2”
B:2.0
C:Error!
D:2
答案:D
程序首先使用eval(input())语句读取输入的内容,并将其解析为表达式。在这种情况下,输入的内容是"2",它被解析为整数2。
然后,print(a)语句打印变量a的值,即2。
由于没有发生NameError异常,所以不会执行except NameError块中的代码。
第12题
下列程序运行结果是?
a="2"
b="3"
c=int(a+b)
print(c)
A:5
B:“5”
C:5.0
D:23
答案:D
在程序中,变量a被赋值为字符串"2",变量b被赋值为字符串"3"。然后,使用int(a+b)将字符串a和b连接起来,并将连接后的结果转换为整数。
由于字符串"a"和"b"都是纯文本,它们在连接时只是简单地拼接在一起,而不是进行数值相加。因此,连接后的结果是"23"。
最后,使用print©打印变量c的值,即"23"。
第13题
执行代码a,b,c=sorted((1,3,2))之后,变量b的值为?
A:1
B:3
C:2
D:(1,3,2)
答案:C
在这行代码中,我们使用 sorted() 函数对元组 (1, 3, 2) 进行排序,并将排序后的结果通过解构赋值的方式分别赋值给变量 a、b 和 c。
元组 (1, 3, 2) 经过排序后的结果为 (1, 2, 3),因此,变量 a 被赋值为 1,变量 b 被赋值为 2,变量 c 被赋值为 3。
所以,正确答案是 C:2。
第14题
x = min(‘5678’),下列选项中语法错误的一项是?
A:print(max(float(x),7,6))
B:print(max(ord(x),7,6))
C:print(max(bin(x),7,6))
D:print(max(int(x),7,6))
答案:C
在这个选项中,使用 bin(x) 将变量 x 转换为二进制字符串。然而,max() 函数是用于比较值的,而不是用于比较字符串。因此,在 max(bin(x),7,6) 中,将二进制字符串与整数 7 和 6 进行比较是不合法的。
正确的做法是将 bin(x) 转换为整数后再进行比较,例如 int(bin(x), 2)。
第15题
以下表达式的值为Fasle的是?
A:all (())
B:any([‘0’])
C:any((0,))
D:all([‘a’,‘b’])
答案:C
在这个表达式中,any() 函数用于判断可迭代对象中是否存在至少一个元素为真值。在 (0,) 这个元组中,元素 0 被视为假值。因此,表达式 any((0,)) 的值为 False。
第16题
以下表达式的值为True的是?
A:bool([])
B:bool(None)
C:bool(“False”)
D:bool(range(0))
答案:C
在这个表达式中,bool() 函数用于判断给定的值是否为真值。对于非空字符串,无论其具体内容是什么,它都被视为真值。因此,表达式 bool(“False”) 的值为 True。
第17题
print(divmod(22,7))的运行结果是?
A:3.0
B:3
C:[3,1]
D:(3,1)
答案:D
divmod() 函数是一个内置函数,用于执行整数除法和取模运算,并返回结果作为一个元组 (商, 余数)。
在这个例子中,22 除以 7 的商是 3,余数是 1。因此,表达式 divmod(22, 7) 返回元组 (3, 1)。
print() 函数用于打印输出,所以打印结果为 (3, 1)。
第18题
下列表达式的结果与其他三项不相同的是?
A:abs(-3.4)
B:round(abs(-3.4))
C:abs(round(-3.4))
D:min(round(3.4),round(3.8))
答案:A
A:abs(-3.4)
在这个表达式中,abs(-3.4) 表示对 -3.4 进行绝对值运算,结果是 3.4,即 -3.4 的绝对值。
其他三个选项的结果如下:
B:round(abs(-3.4)) 的结果是 3,即 -3.4 的绝对值取整后的结果。
C:abs(round(-3.4)) 的结果是 3,即 -3.4 取整后的绝对值。
D:min(round(3.4), round(3.8)) 的结果是 3,即 3.4 和 3.8 取整后的最小值。
所以,正确答案是 A:abs(-3.4)。
第19题
关于ascii()函数,描述不正确的是?
A:ascii()返回一个对象的字符串
B:ascii()返回一个对象的ASCII码的值
C:ascii()的返回值的类型必然是字符串
D:ascii(1)的结果是"1"
答案:B
关于 ascii() 函数,描述不正确的是:
B:ascii()返回一个对象的ASCII码的值
在这个选项中,描述错误在于 ascii() 函数并不返回对象的 ASCII 码的值。实际上,ascii() 函数返回一个对象的字符串表示,该字符串表示对象在 ASCII 编码中的表示形式。
其他选项的描述如下:
A:ascii() 返回一个对象的字符串。这是正确的描述,ascii() 函数将对象转换为字符串表示。
C:ascii() 的返回值的类型必然是字符串。这也是正确的描述,无论输入对象是什么类型,ascii() 函数始终返回字符串类型的结果。
D:ascii(1) 的结果是 “1”。这是正确的描述,ascii(1) 返回表示整数 1 的字符串 “1”。
所以,正确答案是 B:ascii() 返回一个对象的 ASCII 码的值。
第20题
下列关于表达式的计算结果,不正确的是?
A:bool(2*3-0)的值为“True”
B:bool(2*3-2)的值为“True”
C:bool(2*3-3)的值为“True”
D:bool(2*3-6)的值为“True”
答案:D
在这个表达式中,2*3-6 的结果是 0。而在布尔上下文中,0 被视为假值,即 bool(0) 的值为 False。
第21题
下列输出结果为"1+2+3=6"的是?
A:print(1+2+3=6)
B:print(1+2+3,‘=6’)
C:print(1,2,3,sep=‘+’,‘=6’)
D:print(1,2,3,sep=‘+’,end=‘=6’)
答案:D
在这个选项中,使用 print() 函数打印了 1、2、3 这三个数值,并使用 sep=‘+’ 参数指定了它们之间的分隔符为 “+”。然后,使用 end=‘=6’ 参数指定了打印结束时的附加内容为 “=6”。
因此,输出结果为 “1+2+3=6”。
第22题
下列函数能创建一个新的列表的是?
A:sorted()
B:list()
C:dict()
D:set()
答案:B
下列函数能创建一个新的列表的是:
B:list()
list() 函数是一个内置函数,用于创建一个新的空列表。可以使用 list() 函数创建一个空列表,并随后通过添加元素来填充它。
其他选项的功能如下:
A:sorted() 函数用于对可迭代对象进行排序,它返回一个新的已排序的列表,但不会创建一个新的列表。
C:dict() 函数用于创建一个新的空字典,而不是列表。
D:set() 函数用于创建一个新的空集合,也不是列表。
所以,正确答案是 B:list()。
第23题
关于算法的说法,下列说法正确的是?
A:采用顺序查找算法,一定能找到数据
B:算法必须有输入和输出
C:对分查找算法不需要对数据进行排序
D:顺序查找算法不需要对数据进行排序
答案:D
顺序查找算法是一种简单直接的搜索算法,它逐个比较目标值和列表中的元素,直到找到匹配的元素或搜索完整个列表。顺序查找算法并不要求数据在执行查找之前进行排序,因此可以直接应用于未排序的数据。
第24题
有如下列表a=[8,7,9,6,3,8],采用冒泡排序进行降序排序,请问第2趟排序之后的结果是?
A:[9,8,7,6,8,3]
B:[8,9,7,8,6,3]
C:[9,8,7,8,6,3]
D:[9,8,8,6,7,3]
答案:C
冒泡排序是一种比较相邻元素并交换它们位置的排序算法。在每一趟排序中,较大的元素会逐渐向右移动到列表的末尾。
在第1趟排序后,最大的元素 9 已经移动到了列表的末尾。在第2趟排序中,剩余的元素继续进行比较和交换,直到第2大的元素 8 移动到列表的倒数第二个位置。
因此,第2趟排序之后的结果是 [9,8,7,8,6,3]。
第25题
有如下列表a=[8,7,9,6,3,8],采用选择排序进行升序排序,请问第2趟排序之后的结果是?
A:[7,8,6,3,8,9]
B:[3,6,9,7,8,8]
C:[7,6,3,8,8,9]
D:[3,6,7,8,8,9]
答案:B
选择排序是一种每次从未排序部分中选择最小元素并放置到已排序部分末尾的排序算法。
在第1趟排序后,最小的元素 3 被放置到了列表的第一个位置。在第2趟排序中,剩余的元素继续进行比较,找到最小的元素 6,并将其放置到已排序部分的末尾。
因此,第2趟排序之后的结果是 [3,6,9,7,8,8]。
二、判断题(共10题,每题2分,共20分)
第26题
在Python中,0x10010转化为十进制数是18。
答案:错误
以0x开头表示该数为十六进制数,十六进制数0x10010对应的十进制数为65552,而不是18。
第27题
hex(int(‘12’,16))的结果是’0x18’。
答案:错误
在Python中,hex() 函数用于将整数转换为十六进制字符串。而 int(‘12’, 16) 将字符串 ‘12’ 解释为十六进制数,转换为对应的整数值。
所以,hex(int(‘12’, 16)) 的结果是 ‘0x12’,它表示十六进制数 18。
第28题
在Python中,可以使用下面代码读取文件中的数据到列表。
f = open('city.csv','r')
name = f.read().strip('\n').split(';')
f.close()
答案:正确
这段代码的作用是打开名为’city.csv’的文件,并以只读模式读取文件内容。然后,使用read()方法读取文件的全部内容,并使用strip('\n')方法去除每行末尾的换行符。接下来,使用split(';')方法将文件内容按照分号进行分割,并将分割后的结果存储在名为name的列表中。最后,使用close()方法关闭文件。
第29题
在Python中open(‘city.csv’,‘r’)命令的作用是以只读方式打开文件名为city的csv格式文件。
答案:正确
open('city.csv','r')命令在Python中的作用是以只读方式打开名为’city.csv’的文件,其中’city.csv’是一个csv格式的文件。
第30题
在Python中,向csv文件中写入数据时,用逗号合并列表name中的元素,可以使用f.write(‘,’.join(name)+‘\n’)语句(f为文件对象名)。
答案:正确
在Python中,可以使用f.write(','.join(name)+'\n')语句将列表name中的元素用逗号合并,并写入到csv文件中。这里的f是文件对象名,','.join(name)将列表中的元素用逗号连接起来,+'\n'表示在写入数据后添加一个换行符,以保证每行数据的正确格式。
第31题
try-except-else-finally异常处理结构中,不论try程序段中的语句有没有错误,finally程序段中的语句都会得到执行。
答案:正确
在try-except-else-finally异常处理结构中,不论try程序段中的语句有没有错误,finally程序段中的语句都会得到执行。无论try块中是否发生异常,finally块中的代码都会被执行。这使得finally块成为一个适合放置清理代码的地方,例如关闭文件或释放资源等。
第32题
在Python中,执行print(ascii(ord(‘A’)+12))语句,打印一个整型数值结果。
答案:错误
在Python中,执行print(ascii(ord('A')+12))语句会打印一个字符串结果,而不是整型数值。ord('A')返回字符’A’的ASCII码值,然后加上12,ascii()函数将结果转换为对应的ASCII字符表示形式。因此,print()函数会打印一个字符串结果,而不是整型数值。对于这个特定的例子,输出将是字符串"Q"。
第33题
在Python中,sorted()函数可以实现对列表中数据的排序,但排序后不改变原列表中数据的位置。
答案:正确
在Python中,sorted()函数可以对列表中的数据进行排序,而且排序后不会改变原列表中数据的位置。sorted()函数会返回一个新的已排序的列表,而原始列表保持不变。这使得可以在不改变原始数据顺序的情况下对列表进行排序操作。
第34题
在Python中,表达式divmod(26,10) 的输出结果为(2,6)或(3,-4)。
在Python中,表达式divmod(26,10)的输出结果为(2, 6)。divmod()函数返回一个包含商和余数的元组,其中26除以10的商为2,余数为6。所以,正确的输出结果是(2, 6)。关于(3, -4)的结果是不正确的,因为divmod(26, 10)的余数不可能为负数。
答案:错误
第35题
在Python中,chr(ord(‘b’)-32)语句的功能是将小写字母b转换为大写字母B。
答案:正确
在Python中,chr(ord('b')-32)语句的功能是将小写字母’b’转换为大写字母’B’。ord('b')返回字符’b’的ASCII码值,然后减去32,得到大写字母’B’的ASCII码值,最后使用chr()函数将ASCII码值转换为对应的字符。因此,该语句的功能是将小写字母’b’转换为大写字母’B’。
三、编程题(共3题,共30分)
第36题
明明请你帮忙寻找100-999之间的所有“水仙花数”,并统计个数。“水仙花数”是指一个三位数各位数字的立方和等于该数本身。
例如:153=111+555+333。要求输出结果如下所示:
153
370
371
407
请编程实现上述功能,补全代码。
for i in range( ① ):
x=i
a=x % 10
x= ( ② )
b=x % 10
c=x // 10
if ( ③ ):
print(i)
答案:
for i in range(100, 1000):
x = i
a = x % 10
x = x // 10
b = x % 10
c = x // 10
if (a * a * a + b * b * b + c * c * c == i):
print(i)
在上述代码中,我们使用循环遍历100到999之间的所有三位数。对于每个数,我们提取个位数、十位数和百位数,并计算它们的立方和。如果立方和等于该数本身,则打印该数。
第37题
查找“支撑数”。在已知一组整数中,有这样一种数非常怪,它们不在第一个,也不在最后一个,而且刚好都比左边和右边相邻的数大,你能找到它们吗? 输入一个数组,输出每个支撑数的数值以及它们在数组中位置编号。
示例:
输入:
1 3 2 4 1 5 3 9 7 10 8 23 85 43
输出:
3 2
4 4
5 6
9 8
10 10
85 13
请编写程序实现上述功能,补全代码。
s=input()
x=s.split(' ')
a=[]
for i in range(0,len(x)):
a.append(int( ① )
b=[]
c=[]
n=0
for i in range(1, ② ):
if (a[i]>a[i-1] and ③ ):
b.append(a[i])
c.append( ④ )
for i in range( ⑤ ):
print(b[i],' ',c[i])
答案:
s=input()
x=s.split(' ')
a=[]
for i in range(0,len(x)):
a.append(int(x[i]))
b=[]
c=[]
for i in range(1, len(a)-1):
if (a[i]>a[i-1] and a[i]>a[i+1]):
b.append(a[i])
c.append(i+1)
for i in range(len(b)):
print(b[i],' ',c[i])
上述代码中,我们首先将输入的字符串按空格分割为一个整数列表。然后,我们遍历列表中的元素,将其转换为整数并存储在列表a中。接下来,我们使用两个空列表b和c来存储支撑数的数值和它们在数组中的位置编号。
在第二个循环中,我们遍历a列表中除了第一个和最后一个元素的其他元素。对于每个元素,我们检查它是否大于其左边和右边相邻的元素。如果满足条件,则将该元素添加到列表b中,并将其位置编号加1后添加到列表c中。
最后,我们遍历列表b和c,并打印每个支撑数的数值和它们在数组中的位置编号。
第38题
请读取某班级语文学科的成绩文件score.txt的数据,数据内容如下图显示:
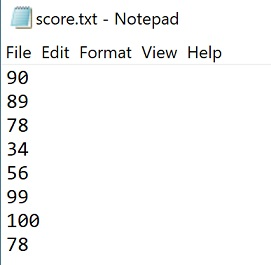
下列代码实现了读取数据并对每个成绩从小到大排序后并输出,请你补全代码。
with open('/data/ ① ', 'r') as f:
list = f.readlines()
for i in range(0, len(list)):
list[i] = list[i].strip('\n')
list[i]= ( ② )
( ③ )
print(list)
f.close
答案:
with open('/data/score.txt', 'r') as f:
list = f.readlines()
for i in range(0, len(list)):
list[i] = list[i].strip('\n')
list[i]=int(list[i])
list.sort()
print(list)
f.close
在上述代码中,我们使用open()函数打开名为score.txt的文件,并使用readlines()方法读取文件中的数据。然后,我们遍历数据列表,并使用strip('\n')方法去除每个成绩字符串中的换行符。接下来,我们使用int()函数将每个成绩字符串转换为整数类型。
然后,我们使用sort()方法对数据列表进行排序,将每个成绩从小到大排列。最后,我们打印排序后的数据列表。
最后,我们使用close()方法关闭文件。



![【python基础】python切片—如何理解[-1:],[:-1],[::-1]的用法](https://img-blog.csdnimg.cn/ebbdf6cc99254ecdbc5d7843e4fbf1a0.png#pic_center)