前言
这里我们主要是来探讨一下 mysql 中 in 的使用, find_in_set 的使用
这两者 在我们实际应用中应该也是 非常常用的了
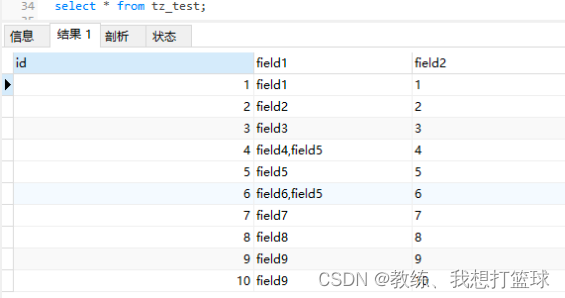
测试数据表如下
CREATE TABLE `tz_test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(16) DEFAULT NULL,
`field2` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `field1` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
然后测试数据如下
将 in 拆分为多个 range 查询
执行 sql 如下 “select * from tz_test where field1 in ("field1", "field5");”
explain 如下, 然后 这个查询会将 sql 拆分为 类似于如下效果
“select * from tz_test where field1 > =‘field1’ and field1 <= ‘field1’ ” + “select * from tz_test where field1 > =‘field5’ and field1 <= ‘field5’ ”

然后我们来看一下 迭代这多个 range 查询的地方
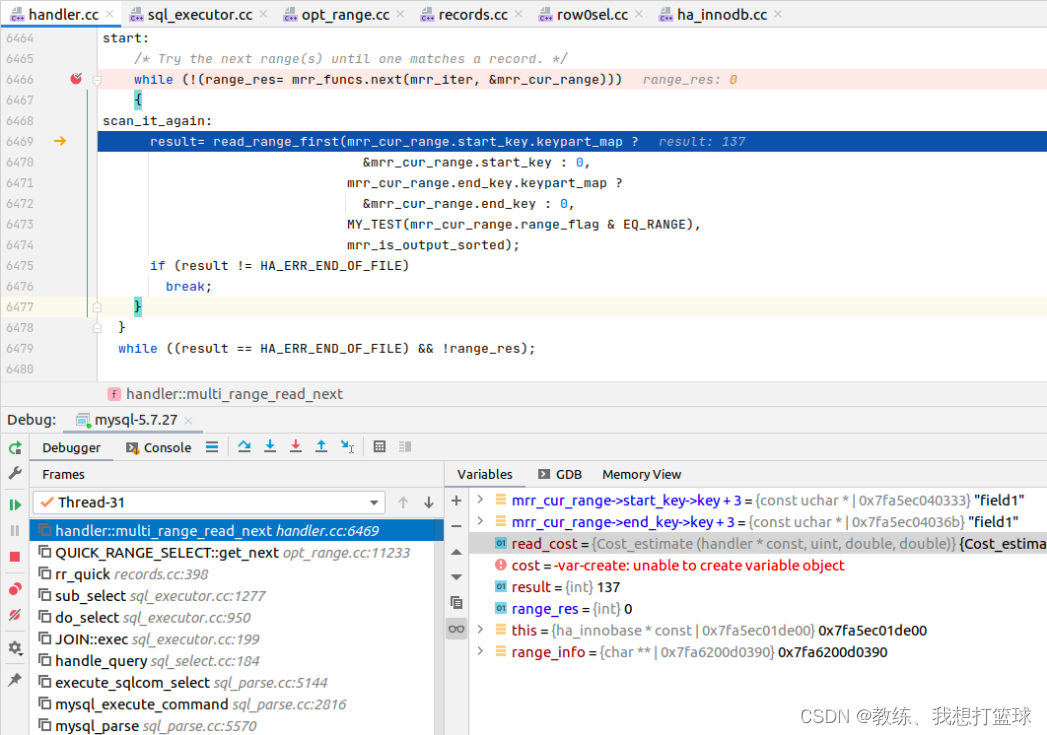
第一个 range 区间如下 实现类似于 “select * from tz_test where field1 > =‘field1’ and field1 <= ‘field1’”
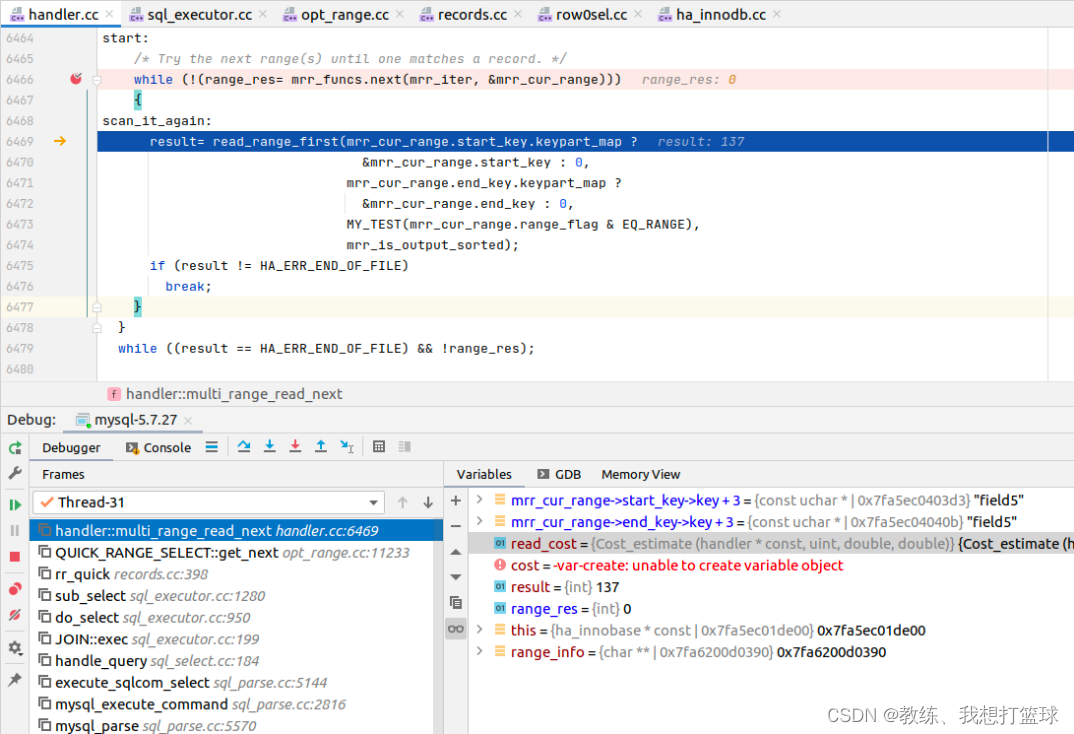
第二个 range 区间如下 实现类似于 “select * from tz_test where field1 > =‘field5’ and field1 <= ‘field5’”
总共执行的 row_search_mvcc 的查询如下
其中, 第二个 ”field2” 和 第二个 ”field6” 的查询是在 do..while 中 read_range_next 中去查询的
第一个 field1 和 field2 是在 “select * from tz_test where field1 > =‘field1’ and field1 <= ‘field1’” range 查询中
第一个 field5 和 field6 是在 “select * from tz_test where field1 > =‘field5’ and field1 <= ‘field5’” range 查询中
至于 range 的查询流程, 这里就不多 赘述了, 可以参考前面 mysql range 查询

in 的全表扫描
执行 sql 如下 “select * from tz_test where field1 in ("field9", "field5");”
explain 如下, 可以看到的是 进行了 全表扫描

在 row_search_mvcc 中没有做条件过滤限制
in 的条件限制是在外面 Item_func_in 中进行处理的, 来判断当前 字段 是否在目标 列表中
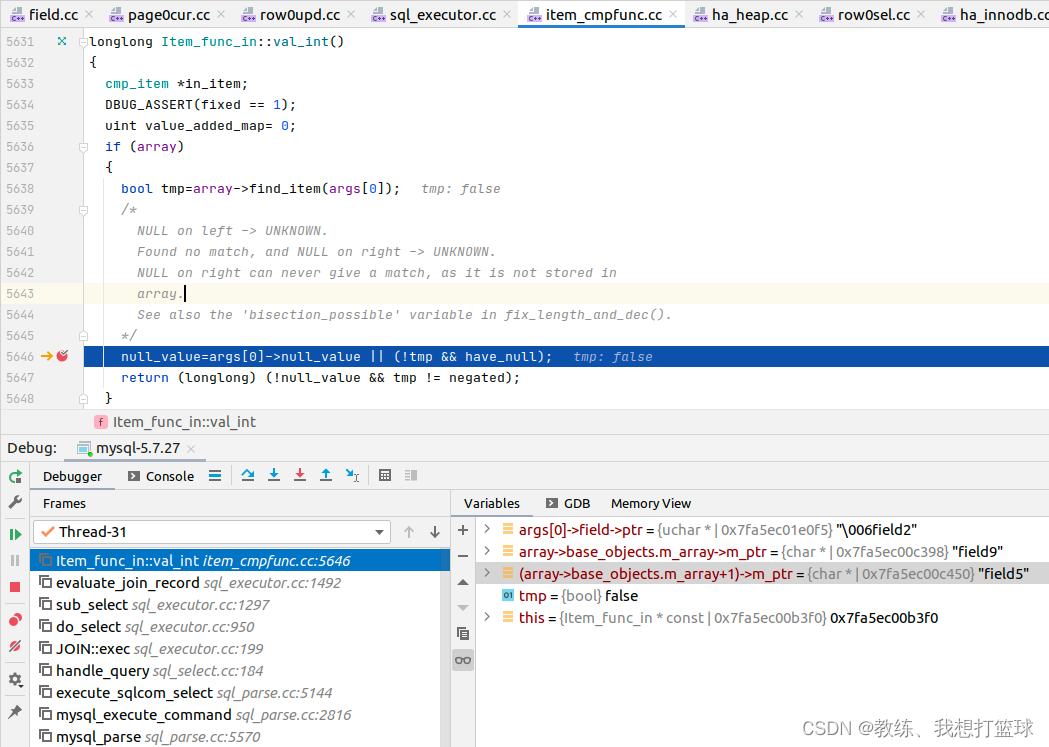
然后外层 evaluate_join_record 中来判断条件是否成立, 如果不成立 更新统计信息
如果成立, 输出当前记录 选择的相关列
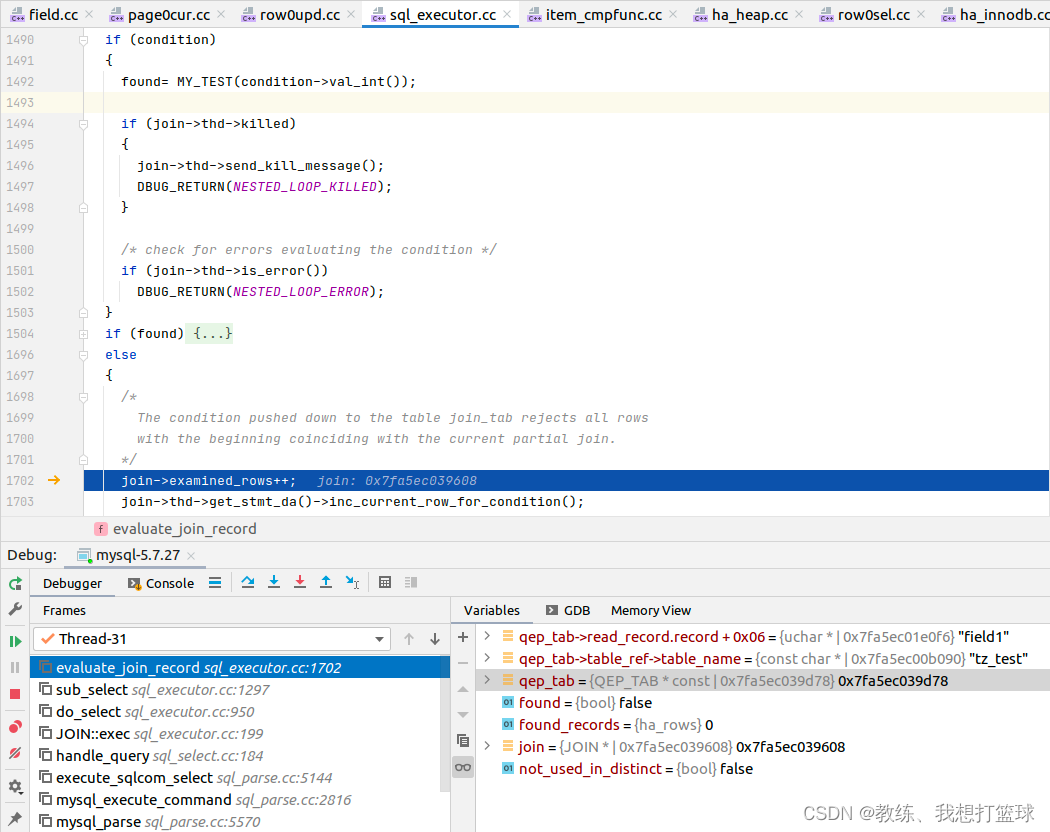
什么时候拆分 range, 什么时候 不拆分?
这里仅仅是 整理一个 模糊的规律, 因为 全表扫描的开销 取决于很多情况
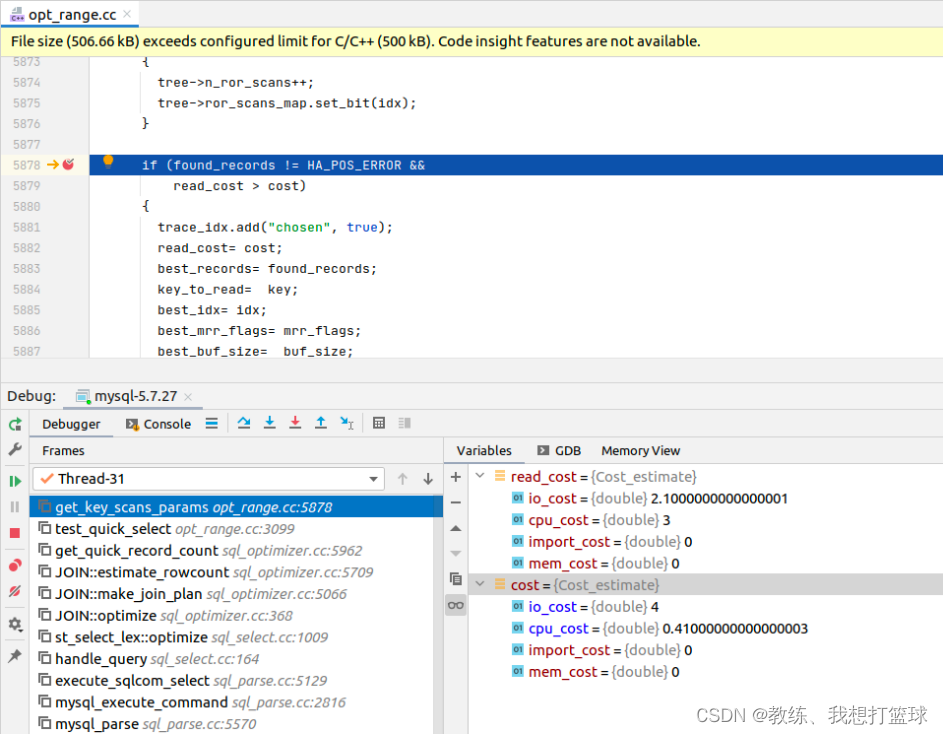
执行sql 如下 “explain select * from tz_test where field1 in ("field1", "field5");”
可以看到 全表扫描 的开销大概是在 5 左右
field1 索引扫描开销是 4, 大致的计算方式为扫描的记录的数量, 比如 ”field1”, ”field5” 需要扫描 “field1”, “field2”, “field5”, “field6,field5”
这里 field1 索引扫描开销较小, 因此选择的是 索引扫描
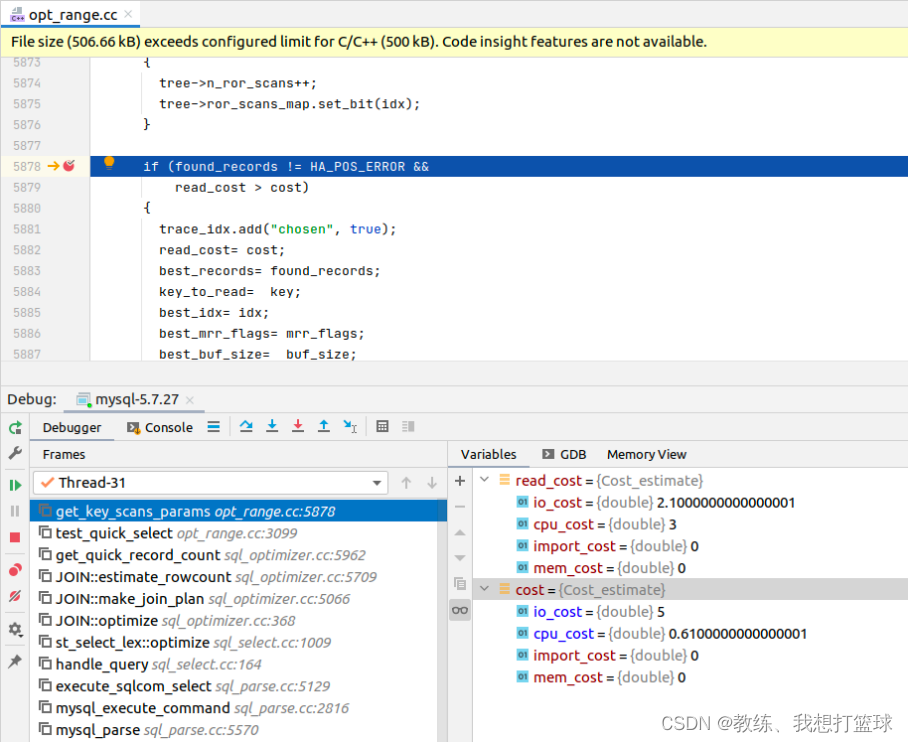
执行sql 如下 “explain select * from tz_test where field1 in ("field9", "field5");”
可以看到 全表扫描 的开销大概是在 5 左右
field1 索引扫描开销是 5, 大致的计算方式为扫描的记录的数量, 比如 ”field9”, ”field5” 需要扫描 “field5”, “field6,field5”, “field9”, “field9”, “supremum”
这里 全表索引扫描开销较小, 因此选择的是 全表扫描
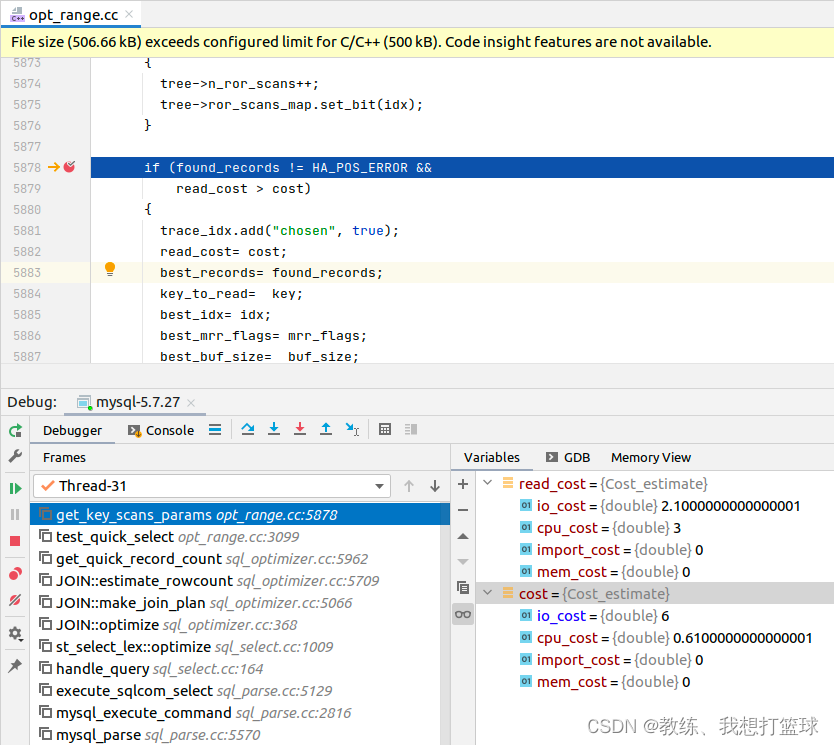
执行sql 如下 “explain select * from tz_test where field1 in ("field1", "field2", "field3");”
可以看到 全表扫描 的开销大概是在 5 左右
field1 索引扫描开销是 6, 大致的计算方式为扫描的记录的数量, 比如 ”field1”, ”field2”, “feidl3” 需要扫描 “field1”, “field2”, “field2”, “field3”, “field3”, “field4,field5”
这里 全表索引扫描开销较小, 因此选择的是 全表扫描
完