文章目录
- 1. vit
- 2. Swin-t
- 3. vit_3D
- 4. TimeSformer First🚀🚀
- 5. vivit
1. vit
详细解释
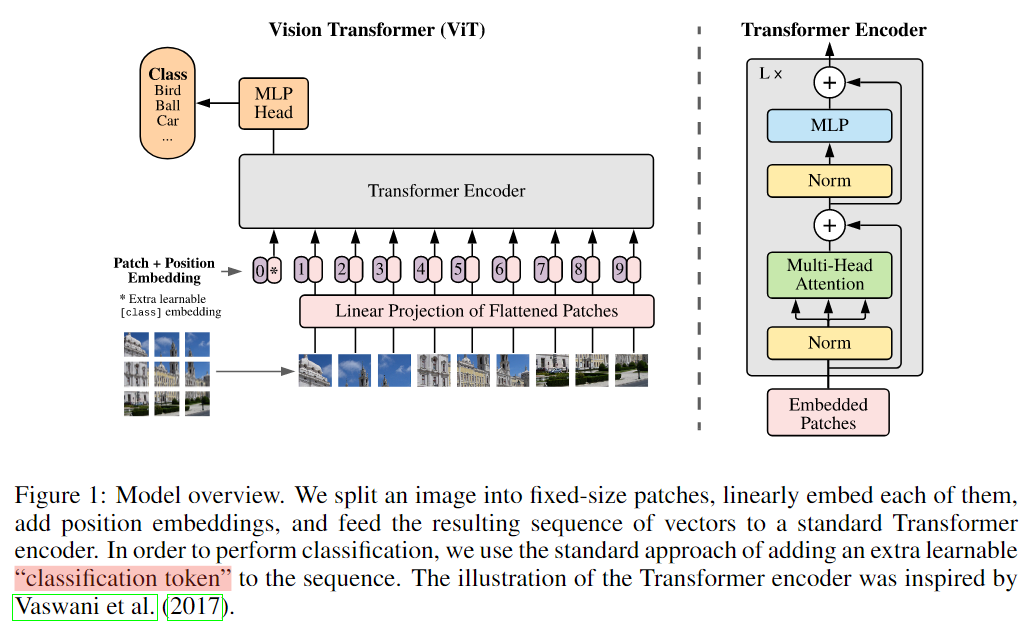
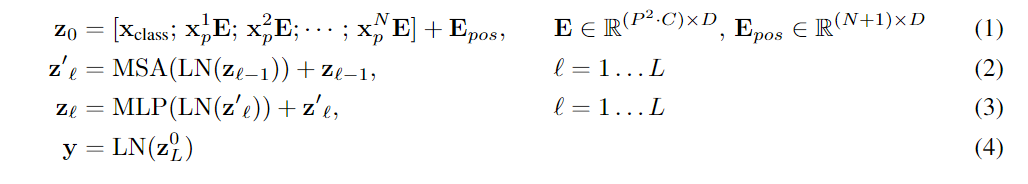

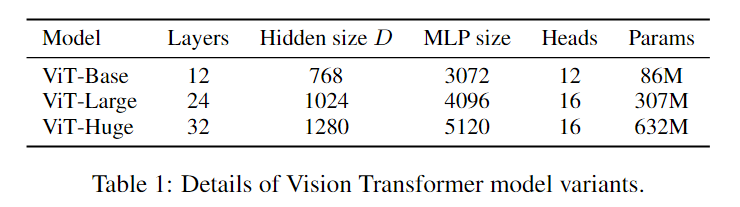
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Transformer中Multi-Head Attention的heads数。
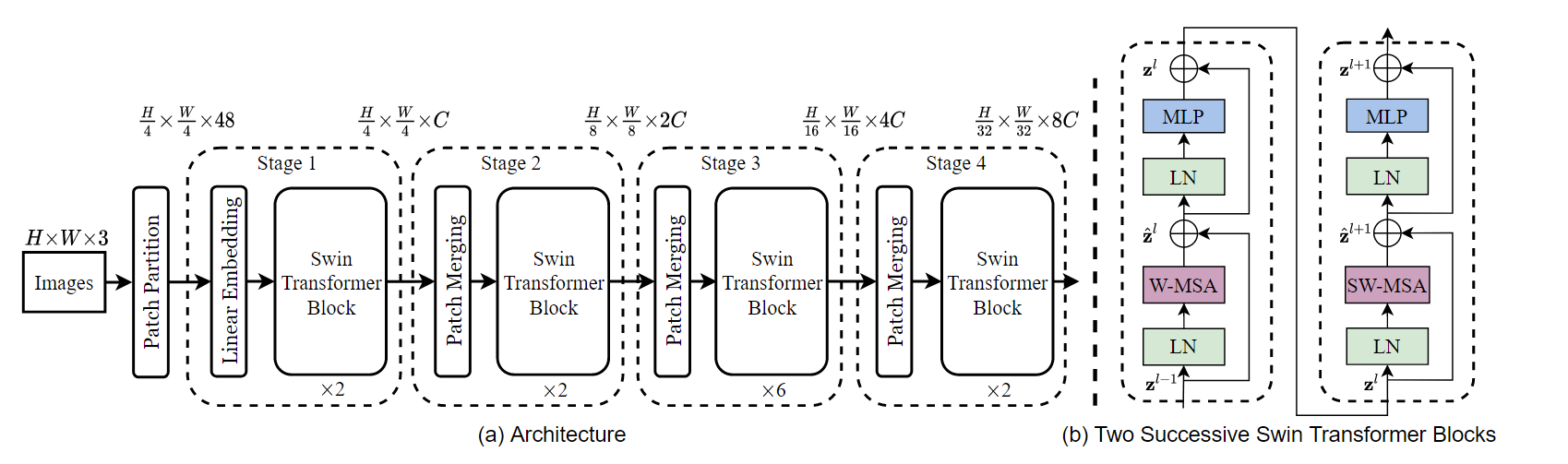
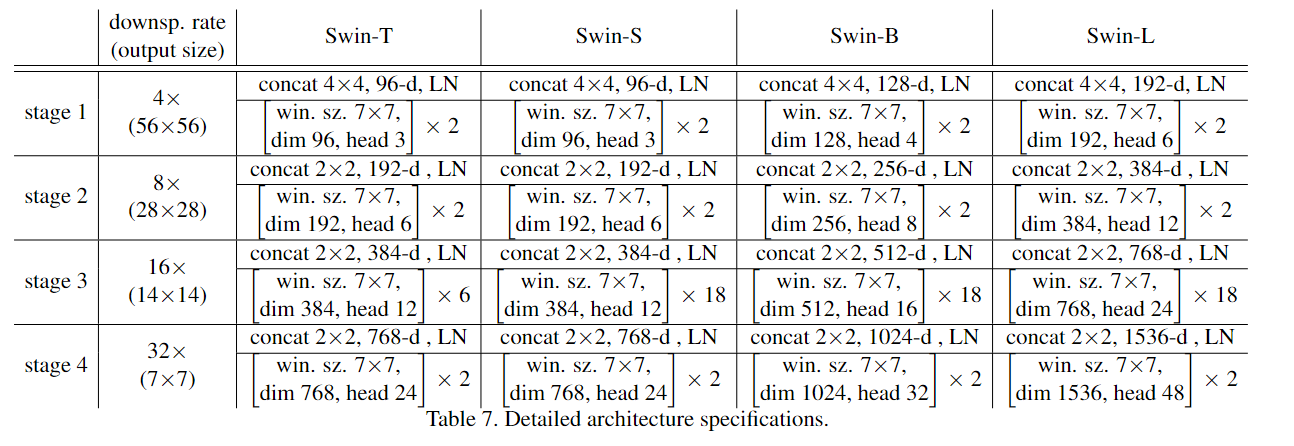
2. Swin-t
3. vit_3D
您将需要传递两个额外的超参数:
(1) 帧数frames 和(2) 沿帧维度的patch大小frame_patch_size
class ViT3D(nn.Module):
def __init__(self, *, image_size, image_patch_size, frames, frame_patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size) # 128 128
patch_height, patch_width = pair(image_patch_size) # 16 16
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
assert frames % frame_patch_size == 0, 'Frames must be divisible by frame patch size' # 16 2
num_patches = (image_height // patch_height) * (image_width // patch_width) * (frames // frame_patch_size) # 每一个frame块中有多少块patch
patch_dim = channels * patch_height * patch_width * frame_patch_size # 3*16*16*2=1536
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (f pf) (h p1) (w p2) -> b (f h w) (p1 p2 pf c)', p1 = patch_height, p2 = patch_width, pf = frame_patch_size),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim), # -->1024 token dim(Hidden Size)
nn.LayerNorm(dim),
)
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
只有在num_patches和patch_embedding部分,多了一些关于frame的操作。将视频输入数据经过patch_embedding转化为token后,就没什么区别了。(包括后面加【cls】和position embedding)
4. TimeSformer First🚀🚀
第一篇使用纯Transformer结构在视频识别上的文章。
初探Video Transformer(一):抛弃CNN的纯Transformer视频理解框架—TimeSformer
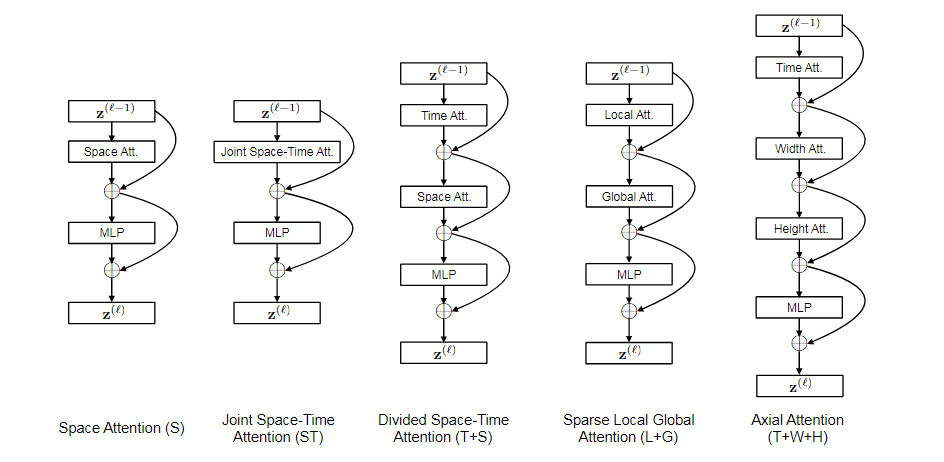

5种方法的可视化:

self-attention和rnn计算复杂度的对比
自注意力的计算复杂度和 输入token的数量平方 成正比。

5. vivit
初探Video Transformer(二):谷歌开源更全面、高效的无卷积视频分类模型ViViT
为了让模型表现力更强,ViViT讨论了两方面的设计和思考(TimeSformer只考虑了模型结构设计):
Embedding video clips 和 Transformer Models for Video

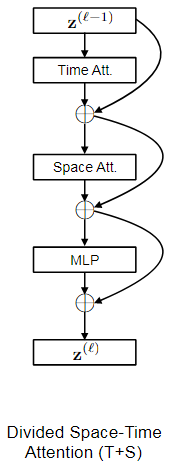
TimeSformer:通过reshape,可以分别对2D和时间维度分别进行embedding。
- Embedding video clips:

如何将输入的Video数据转化为tokens。(token_dim=N*d)



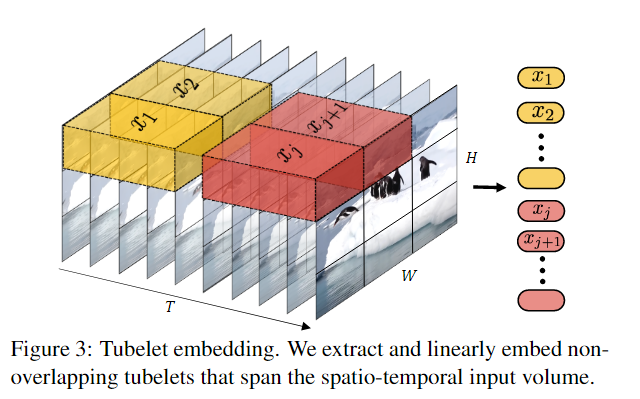
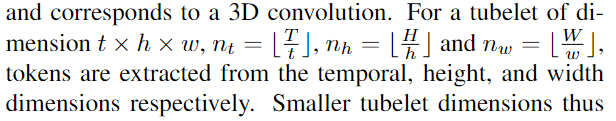
与"Uniform frame sampling"相比,这种方法融合了时空信息。
- Transformer Models for Video:

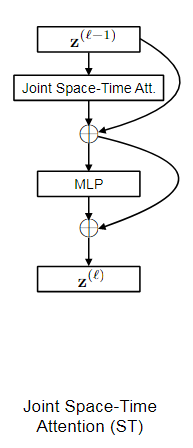
这种实现方法可以理解为vit-3D。和TimeSformer的joint attention相似。
- Model 2: Factorised encoder

- Model 3: Factorised self-attention

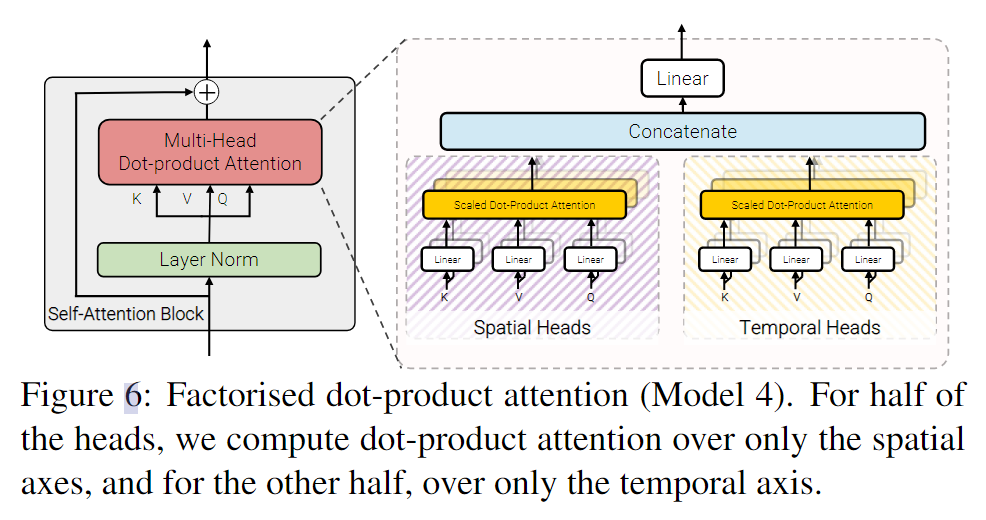
- Model 4: Factorised dot-product attention



-
Model-1
model1就是标准的VIT结构,除了patchembeeding以外没有任何的改变,直接看vit-3d代码就可以了。 -
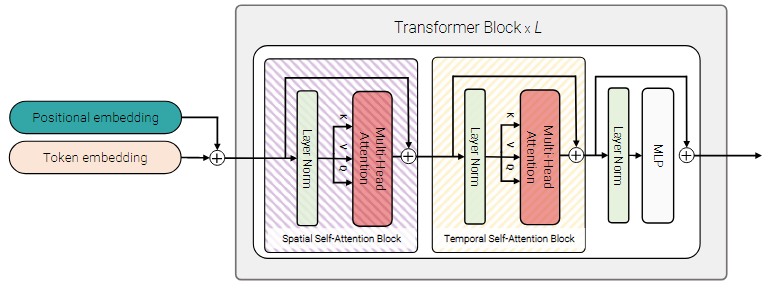
Model-2
第一个Transformer:先对同一帧下的token进行交互interaction,产生每个时间索引下的latent representation。
第二个Transformer:对time stepinx交互。相当于时间空间信息后融合。
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (f pf) (h p1) (w p2) -> b f (h w) (p1 p2 pf c)', p1 = patch_height, p2 = patch_width, pf = frame_patch_size),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim)
)
相比于VIT 3D的b c (f pf) (h p1) (w p2) -> b (f h w) (p1 p2 pf c),这里把时间维度单独抽出来。
在forward中:相比于之前的patch_embedding、cls_tokens 、pos_embedding。
def forward(self, video):
x = self.to_patch_embedding(video)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
model2中:
如果Transformer输入有【cls】,则分类。若无,则全局平均池化输出。
def forward(self, video):
x = self.to_patch_embedding(video) # b f (h w) (p1 p2 pf c)
b, f, n, _ = x.shape # n为一帧内有多少个patches,_为token—dim
x = x + self.pos_embedding[:, :f, :n] # 先pos_embedding
if exists(self.spatial_cls_token):
spatial_cls_tokens = repeat(self.spatial_cls_token, '1 1 d -> b f 1 d', b = b, f = f)
x = torch.cat((spatial_cls_tokens, x), dim = 2) # 后对spatial_cls_tokens 进行添加
x = self.dropout(x)
x = rearrange(x, 'b f n d -> (b f) n d') # 融合时间维度
# attend across space
x = self.spatial_transformer(x) # 进行空间的变换 输入输出维度不变(b f) n d
x = rearrange(x, '(b f) n d -> b f n d', b = b)
# excise out the spatial cls tokens or average pool for temporal attention
x = x[:, :, 0] if not self.global_average_pool else reduce(x, 'b f n d -> b f d', 'mean')# [4, 8, 1024] 提取第一个cls,当作当前帧所有token的全局表示
# append temporal CLS tokens
if exists(self.temporal_cls_token):
temporal_cls_tokens = repeat(self.temporal_cls_token, '1 1 d-> b 1 d', b = b)
x = torch.cat((temporal_cls_tokens, x), dim = 1)
# attend across time
x = self.temporal_transformer(x)
# excise out temporal cls token or average pool
x = x[:, 0] if not self.global_average_pool else reduce(x, 'b f d -> b d', 'mean') # [4, 1024] 提取第一个cls,当作跨帧所有token的全局表示
x = self.to_latent(x)
return self.mlp_head(x)
-
Model-3
model3的实现和TimeSformer的实现是一样的,去掉cls-token即可,可以参考TimeSformer的文章。 -
Model-4
model4的实现与model1不同之处在于,transformer是有两个不同维度的attention 来进行计算的。
代码以后填吧。
效果对比:

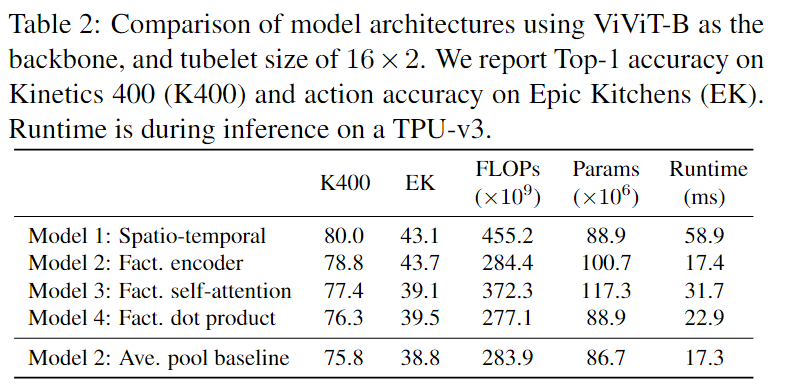
比较模型性能,这里Model2的temporal-transformer设置4层。model1的性能最好,但是FLOPs最大,运行时间最长。Model4没有额外的参数量,计算量比model1少很多,但是性能不高。Model3相比与其他的变体,需要更高的计算量和参数量。Model2表现最佳,精度尚可,计算量和运行时比较低。最后一行是单独做的实验,去掉了Model2的temporal transformer,直接在帧上做了pooling,EK上的精度下降很多,对于时序强的数据集需要用temporal transformer来做时序信息交互。