LLMs之RAG之IncarnaMind:IncarnaMind的简介(提高RAG召回率的两个优化技巧=滑块遍历反向查找+独立查询)、安装、使用方法之详细攻略
导读:在IncarnaMind项目中,提出了几个优化技巧,是非常值得我们在优化RAG系统的时候,进行思考和借鉴。
>> 文档分块能够提高相似度检索中的效率和准确性:可以通过小分块和大分块的结合来优化检索效果。分块大小需要权衡,分块不宜太大,否则会影响检索效果;分块也不宜太小,以免检索结果不完整。
>> 分块技巧—滑块遍历和反向查找(用小分块保证尽可能找到更多的相关内容,用大分块保证内容完整性):在相似度检索时,可以使用滑块遍历结果,根据小块的信息反向查找大块内容,以便提交给语言模型作为上下文。比如Langchain中ParentDocumentRetriever(父文档检索器)就采用了这一思路。
>> 用LLM将用户的提问转换成独立查询:当用户提问后,重新提炼问题并拆分成多个独立查询。通过过滤掉无用信息,使得查询更准确,进而提升用户体验和检索结果的质量。
目录
相关文章
LLMs之RAG:知识检索增强生成方法(搭建本地知识库、利用外挂信息库增强LLMs自身能力的一种方法,外部知识检索+LLMs生成回复=知识问答任务)的简介、实现方法(LangChain/Loc……等)、案例应用之详细攻略
IncarnaMind的简介
1、版本更新
2、应对的挑战及其提出的解决方案
(1)、流程图—高级架构
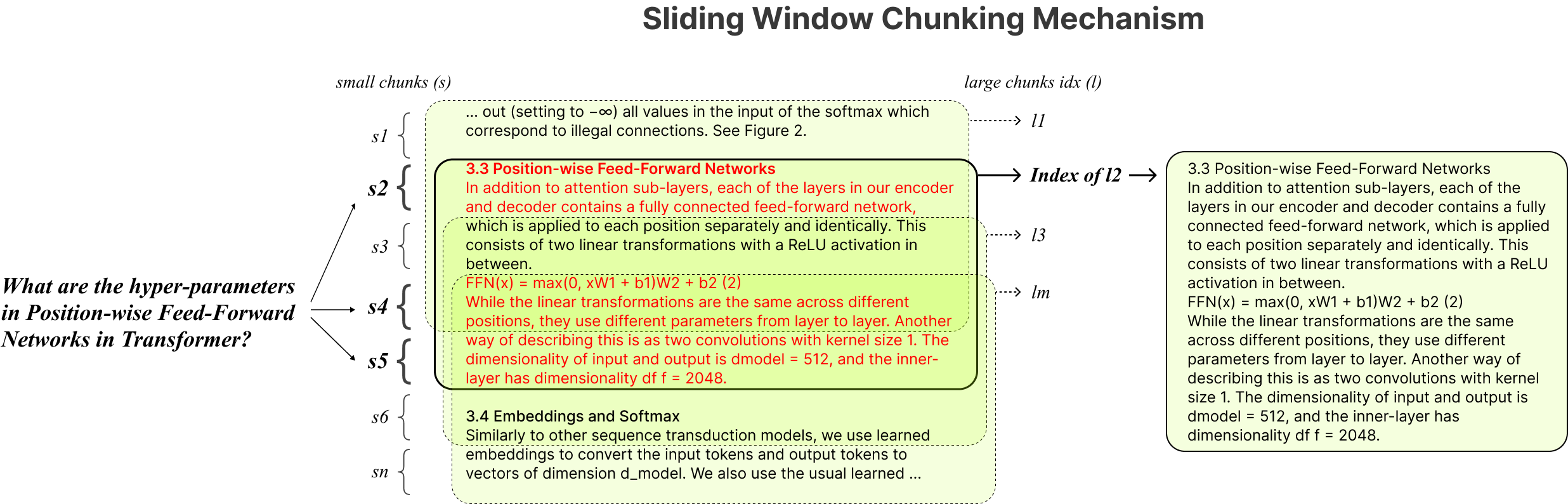
(2)、流程图—滑块窗口分块
3、不同模型的性能对比表
IncarnaMind的安装
1、环境配置以及闭源模型的密钥
2、安装
IncarnaMind的使用方法
1、基础用法
相关文章
LLMs之RAG:知识检索增强生成方法(搭建本地知识库、利用外挂信息库增强LLMs自身能力的一种方法,外部知识检索+LLMs生成回复=知识问答任务)的简介、实现方法(LangChain/Loc……等)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130215772
IncarnaMind的简介
IncarnaMind允许你使用大型语言模型(LLMs)如GPT与你的个人文件(PDF,TXT)进行聊天。尽管OpenAI最近推出了GPT模型的微调API,但它不允许base版本的预训练模型学习新数据,而且响应可能容易受到事实幻觉的影响。利用我们的滑块窗口分块机制和集合检索器,可以有效地查询地面真实文档中的精细和粗粒度信息,以增强LLMs。
GitHub地址:https://github.com/junruxiong/IncarnaMind
1、版本更新
| 开源和本地LLMs支持 | 开源和本地LLMs支持 推荐模型:我们主要使用Llama2系列模型进行测试,并建议使用llama2-70b-chat(完整或GGUF版本)以获得最佳性能。随时尝试其他LLMs。 系统要求:运行GGUF量化版本需要超过35GB的GPU RAM。 |
| 备用开源LLMs选项 | 备用开源LLMs选项 内存不足:如果受到GPU RAM的限制,请考虑使用Together.ai API。它支持llama2-70b-chat和大多数其他开源LLMs。此外,您可以获得25美元的免费使用额度。 即将推出:将来将发布更小型和经济实惠的微调模型。 |
| 注意事项 | 如何使用GGUF模型:有关获取和使用量化GGUF LLM的说明(类似于GGML),请参考此视频(从10:45到12:30)。 |
| 即将推出的功能 | 前端UI界面 经过微调的小型开源LLMs OCR支持 异步优化 支持更多文档格式。 |
视频地址:https://user-images.githubusercontent.com/44308338/268073295-89d479fb-de90-4f7c-b166-e54f7bc7344c.mp4
2、应对的挑战及其提出的解决方案
| 固定分块:传统的RAG工具依赖于固定的分块大小,限制了它们在处理不同数据复杂性和上下文方面的适应能力。 | 自适应分块:我们的滑块窗口分块技术根据数据复杂性和上下文动态调整窗口大小和位置,以实现RAG的细粒度和粗粒度数据访问平衡。 |
| 精度与语义:当前的检索方法通常要么侧重于语义理解,要么侧重于精确检索,但很少两者兼顾。 | |
| 单文档限制:许多解决方案一次只能查询一个文档,限制了多文档信息检索 | 多文档会话问答:支持跨多个文档同时进行简单和多跳查询,打破了单文档限制。 文件兼容性:支持PDF和TXT文件格式。 |
| 稳定性:IncarnaMind与OpenAI GPT、Anthropic Claude、Llama2和其他开源LLMs兼容,确保稳定的解析。 | LLM模型兼容性:支持OpenAI GPT、Anthropic Claude、Llama2和其他开源LLMs。 |
(1)、流程图—高级架构

(2)、流程图—滑块窗口分块
3、不同模型的性能对比表
| Metrics | GPT-4 | GPT-3.5 | Claude 2.0 | Llama2-70b | Llama2-70b-gguf | Llama2-70b-api |
|---|---|---|---|---|---|---|
| Reasoning | High | Medium | High | Medium | Medium | Medium |
| Speed | Medium | High | Medium | Very Low | Low | Medium |
| GPU RAM | N/A | N/A | N/A | Very High | High | N/A |
| Safety | Low | Low | Low | High | High | Low |
IncarnaMind的安装
1、环境配置以及闭源模型的密钥
| 环境配置 | 3.8 ≤ Python < 3.11与Conda |
| 密钥 | 一个/所有OpenAI API密钥,Anthropic Claude API密钥,Together.ai API密钥或HuggingFace Meta Llama模型的令牌 |
2、安装
1.1. 克隆存储库
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMind
1.2. 设置
创建Conda虚拟环境:
conda create -n IncarnaMind python=3.10
激活:
conda activate IncarnaMind
安装所有要求:
pip install -r requirements.txt
单独安装llama-cpp,如果您要运行量化本地LLMs:
>> 对于NVIDIA GPU支持,请使用cuBLAS
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dir
>> 对于Apple Metal(M1/M2)支持,请使用
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dir
在configparser.ini文件中设置您的一个/所有API密钥:
[tokens]
OPENAI_API_KEY = (替代)
ANTHROPIC_API_KEY = (替代)
TOGETHER_API_KEY = (替代)IncarnaMind的使用方法
1、基础用法
| 上传和处理您的文件 | 第一步,上传和处理您的文件 |
| 运行 | 第二步,运行 |
| 聊天 | 第三步, 聊天和提问任何问题 Human: |