1 概述
hugetlb机制是一种使用大页的方法,与THP(transparent huge page)是两种完全不同的机制,它需要:
- 管理员通过系统接口reserve一定量的大页,
- 用户通过hugetlbfs申请使用大页,
核心组件如下图:
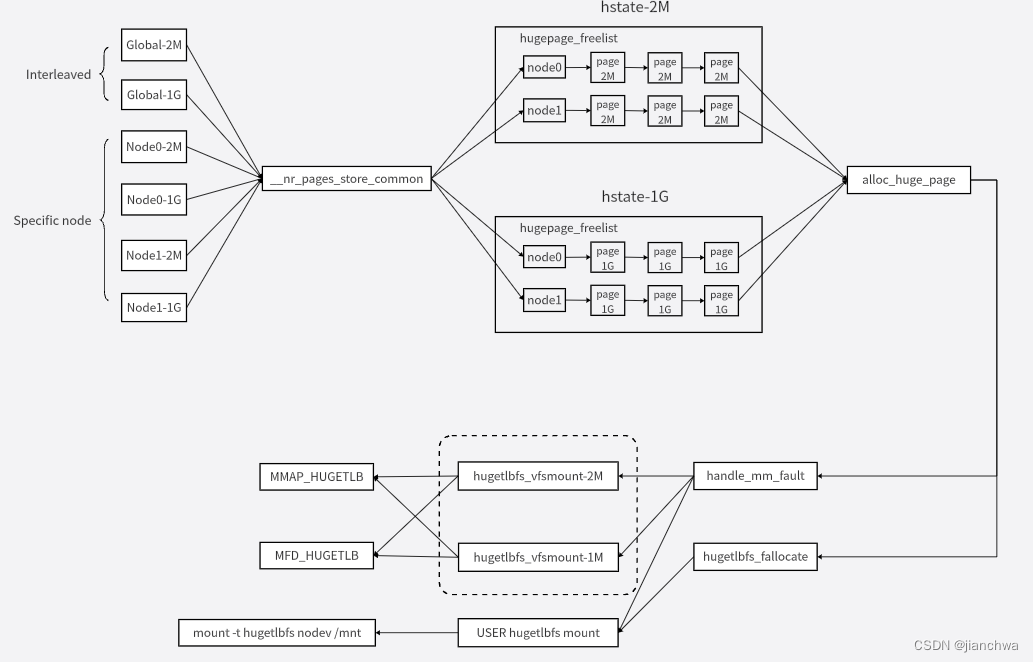
围绕着保存大页的核心数据结构hstate,
- 不同的系统接口,通过__nr_pages_store_common()将申请大页,并存入hstate;
- 不同的hugetlbfs挂载,通过alloc_huge_page()从hstate中申请大页使用;
下面,我们分别详解这些组件。
2 hstate
如上图中,hstate用于保存huge page,
关于hstate,参考以下代码:
struct hstate hstates[HUGE_MAX_HSTATE];
gigantic_pages_init()
---
/* With compaction or CMA we can allocate gigantic pages at runtime */
if (boot_cpu_has(X86_FEATURE_GBPAGES))
hugetlb_add_hstate(PUD_SHIFT - PAGE_SHIFT);
---
hugetlb_init()
---
hugetlb_add_hstate(HUGETLB_PAGE_ORDER);
if (!parsed_default_hugepagesz) {
...
default_hstate_idx = hstate_index(size_to_hstate(HPAGE_SIZE));
...
}
---
#define HPAGE_SHIFT PMD_SHIFT
#define HUGETLB_PAGE_ORDER (HPAGE_SHIFT - PAGE_SHIFT)
default_hugepagesz_setup()
---
...
default_hstate_idx = hstate_index(size_to_hstate(size));
...
---
__setup("default_hugepagesz=", default_hugepagesz_setup);其中有以下几个关键点:
- x86_64架构存在两个hstate,2M和1G
- 系统中存在一个default hstate,默认是2M的,可以通过kernel commandline设置;
我们在/proc/meminfoh中看到的:
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
HugePages开头的这几个都是default hstate的数据,换句话说,是2M的;1G的hugetlbs数据并不会体现在其中,参考代码:
hugetlb_report_meminfo()
---
for_each_hstate(h) {
unsigned long count = h->nr_huge_pages;
total += huge_page_size(h) * count;
if (h == &default_hstate)
seq_printf(m,
"HugePages_Total: %5lu\n"
"HugePages_Free: %5lu\n"
"HugePages_Rsvd: %5lu\n"
"HugePages_Surp: %5lu\n"
"Hugepagesize: %8lu kB\n",
count,
h->free_huge_pages,
h->resv_huge_pages,
h->surplus_huge_pages,
huge_page_size(h) / SZ_1K);
}
seq_printf(m, "Hugetlb: %8lu kB\n", total / SZ_1K);
---这我们再贴一段hstate处理hugepage的代码:
dequeue_huge_page_nodemask()
-> dequeue_huge_page_node_exact()
---
list_move(&page->lru, &h->hugepage_activelist);
set_page_refcounted(page);
ClearHPageFreed(page);
h->free_huge_pages--;
h->free_huge_pages_node[nid]--;
---
非常简单,链表维护,减少计数。
3 nr_hugepages
hugetlb需要系统管理员将一定量的内存reserve给hugetlb,可以通过以下途径:
- /proc/sys/vm/nr_hugepages,参考代码hugetlb_sysctl_handler_common(),它会向default_hstate注入大页,也就是2M;
- /sys/kernel/mm/hugepages/hugepages-size/nr_hugepages,这里可以指定size向2M或者1G的hstate注入大页,node策略为interleaved,
-
/sys/devices/system/node/node_id/hugepages/hugepages-size/nr_hugepages,通过该接口,不仅可以指定size,还可以指定node;
参考代码:
// /sys/kernel/mm/hugepages
hugetlb_sysfs_init()
---
hugepages_kobj = kobject_create_and_add("hugepages", mm_kobj);
...
for_each_hstate(h) {
err = hugetlb_sysfs_add_hstate(h, hugepages_kobj,
hstate_kobjs, &hstate_attr_group);
...
}
---
hugetlb_register_node()
---
struct node_hstate *nhs = &node_hstates[node->dev.id];
...
nhs->hugepages_kobj = kobject_create_and_add("hugepages",
&node->dev.kobj);
...
for_each_hstate(h) {
err = hugetlb_sysfs_add_hstate(h, nhs->hugepages_kobj,
nhs->hstate_kobjs,
&per_node_hstate_attr_group);
...
}
---
nr_hugepages_store_common()
---
h = kobj_to_hstate(kobj, &nid);
return __nr_hugepages_store_common(obey_mempolicy, h, nid, count, len);
---
static struct hstate *kobj_to_hstate(struct kobject *kobj, int *nidp)
{
int i;
for (i = 0; i < HUGE_MAX_HSTATE; i++)
if (hstate_kobjs[i] == kobj) {
if (nidp)
*nidp = NUMA_NO_NODE;
return &hstates[i];
}
return kobj_to_node_hstate(kobj, nidp);
}
另外,hugetlb还有overcommit功能,参考Redhat官方给出的解释:
/proc/sys/vm/nr_overcommit_hugepages
Defines the maximum number of additional huge pages that can be created and used by the system through overcommitting memory. Writing any non-zero value into this file indicates that the system obtains that number of huge pages from the kernel's normal page pool if the persistent huge page pool is exhausted. As these surplus huge pages become unused, they are then freed and returned to the kernel's normal page pool.
不过,在实践中,我们通常不会使用这个功能,hugetlb reserve的内存量都是经过预先计算的预留的;overcommit虽然提供了一定的灵活性,但是增加了不确定性。
4 hugetlbfs
hugetlb中的所有大页,都需要通过hugetlbfs以文件的形式呈现出来,供用户读写;接下来,我们先看下hugetlbfs的文件的使用方法。
const struct file_operations hugetlbfs_file_operations = {
.read_iter = hugetlbfs_read_iter,
.mmap = hugetlbfs_file_mmap,
.fsync = noop_fsync,
.get_unmapped_area = hugetlb_get_unmapped_area,
.llseek = default_llseek,
.fallocate = hugetlbfs_fallocate,
};hugetlbfs的文件并没有write_iter方法,如果我们用write系统调用操作该文件,会报错-EINVAL,具体原因可以索引代码中的FMODE_CAN_WRITE的由来;不过,hugetlbfs中的文件可以通过read系统调用读。fallocate回调存在意味着,我们可以预先通过fallocate给文件分配大页。另外,从hugetlb这个名字中我们就可以知道,它主要跟mmap有关,我们看下关键代码实现:
handle_mm_fault()
-> hugetlb_fault()
-> hugetlb_no_page()
-> alloc_huge_page()
hugetlbfs_fallocate()
-> alloc_huge_page()所以,hugetlbfs的大页是从mmap后的pagefault分配或者fallocate提前分配好的;
关于hugetlbfs的大页的分配,还需要知道reserve的概念;
hugetlbfs_file_mmap()
-> hugetlb_reserve_pages()
-> hugetlb_acct_memory()
-> gather_surplus_pages()
---
needed = (h->resv_huge_pages + delta) - h->free_huge_pages;
if (needed <= 0) {
h->resv_huge_pages += delta;
return 0;
}
---
alloc_huge_page()
-> dequeue_huge_page_vma()
---
if (page && !avoid_reserve && vma_has_reserves(vma, chg)) {
SetHPageRestoreReserve(page);
h->resv_huge_pages--;
}
---
//如果是fallocate路径,avoid_reserve就是truehugetlb_acct_memory()用于执行reserve,但是并不会真的分配;
这里并不是文件系统的delay allocation功能,大页的累计有明确的数量和对齐要求;reserve只是为了符合mmap的语义,即mmap时不会分配内存,page fault才分配;
hugetlbfs的mount参数中有一个min_size,可以直接在mount的时候reserve大页,如下:
hugepage_new_subpool()
---
spool->max_hpages = max_hpages;
spool->hstate = h;
spool->min_hpages = min_hpages;
if (min_hpages != -1 && hugetlb_acct_memory(h, min_hpages)) {
kfree(spool);
return NULL;
}
spool->rsv_hpages = min_hpages;
---而在实践中,这也没有必要;与overcommit类似,hugetlb最关键的特性就是确定性,它能确保用户可以使用到huge page,所以,资源都是提供计算预留好的,甚至包括,哪个进程能用多少等,所以,做这种mount reserve没有意义。
hugetlbfs除了用户通过mount命令挂载的,系统还给每个hstate一个默认挂载;
init_hugetlbfs_fs()
---
/* default hstate mount is required */
mnt = mount_one_hugetlbfs(&default_hstate);
...
hugetlbfs_vfsmount[default_hstate_idx] = mnt;
/* other hstates are optional */
i = 0;
for_each_hstate(h) {
if (i == default_hstate_idx) {
i++;
continue;
}
mnt = mount_one_hugetlbfs(h);
if (IS_ERR(mnt))
hugetlbfs_vfsmount[i] = NULL;
else
hugetlbfs_vfsmount[i] = mnt;
i++;
}
--
hugetlb_file_setup()
---
hstate_idx = get_hstate_idx(page_size_log);
...
mnt = hugetlbfs_vfsmount[hstate_idx];
...
inode = hugetlbfs_get_inode(mnt->mnt_sb, NULL, S_IFREG | S_IRWXUGO, 0);
...
---
ksys_mmap_pgoff()
---
if (!(flags & MAP_ANONYMOUS)) {
...
} else if (flags & MAP_HUGETLB) {
...
hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
...
len = ALIGN(len, huge_page_size(hs));
...
file = hugetlb_file_setup(HUGETLB_ANON_FILE, len,
VM_NORESERVE,
&ucounts, HUGETLB_ANONHUGE_INODE,
(flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
...
}
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
---
memfd_create()
---
...
if (flags & MFD_HUGETLB) {
...
file = hugetlb_file_setup(name, 0, VM_NORESERVE, &ucounts,
HUGETLB_ANONHUGE_INODE,
(flags >> MFD_HUGE_SHIFT) &
MFD_HUGE_MASK);
}
...
fd_install(fd, file);
---默认hugetlbfs挂载主要用于:
- memfd,MEMFD_HUGETLB,直接从hugetlb中申请大页,创建匿名mem文件;
- mmap,MMAP_HUGETLB,直接总hugetlb中申请大页,mmap到程序中;
这种方法虽然增加了灵活性,但是,还是之前强调的hugetlbfs是为了大页的确定性而存在的。