一、实验数据
数据集:“加油站数据.xls”
数据集介绍:该表记录了用户在11月和12月一天24小时内的加油信息,包括:持卡人标识(cardholder)、卡号(cardno)、加油站网点号(nodeno)、加油时间(opetime)、加油升数(liter)、金额(amount)
二、实验任务
a. 按照加油时间顺序对表0中的数据进行排序;
b. 统计加油站的站点数;统计用户总数(相同卡号按照同一人计算);统计17:30~18:30期间加油的人数和平均加油量,以及该时间段的加油总量在一天中的占比;
c. 按照月份可视化展示用户卡号为“1000113200000151566”的加油量;分析用户“1000113200000151566”常去的加油站点和通常的加油时间;根据加油时间、加油量、加油站点等因素分析该用户2007年是否有行为异常的时间,并进行解释说明。
d. 分析国庆节是否可以拉动加油站的经济增长(提示:可以跟整体和当月加油量的均值和方差进行对比);
e. 某用户周六9:00~19:00时间自由,你推荐他什么时间去哪个加油站加油,为什么;
f. 分析2007年期间,加油站点“32000966”的汽油价格波动情况;
三、前期工作
数据预处理
数据整合
import pandas as pd
# 读取整个Excel文件
xls = pd.ExcelFile('D:/MecLearning/加油站数据.xls')
# 创建一个空的DataFrame,用于存储所有表页的内容
combined_data = pd.DataFrame()
# 遍历Excel文件的每个表页,并将其内容合并到combined_data中
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name)
combined_data = pd.concat([combined_data, df], ignore_index=True)
# 将合并后的数据写入一个新的Excel文件
combined_data.to_excel('D:/MecLearning/合并后的数据.xlsx', index=False)
print("数据已整合并写入新的Excel文件 '合并后的数据.xlsx'")![]() 时间列分割
时间列分割
import pandas as pd
# 读取原始Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')
# 将opetime列分割成年月日和时间两列
df['Date'] = df['opetime'].str.split().str[0] # 提取年月日部分
df['Time'] = df['opetime'].str.split().str[1] # 提取时间部分
# 将修改后的DataFrame保存到原始文件中
df.to_excel('D:/MecLearning/合并后的数据.xlsx', index=False)
print("修改后的Date和Time列已保存到原始文件中")![]()

正式解题
a.按照加油时间顺序对数据进行排序:
import pandas as pd
# 读取Excel文件
df = pd.read_excel('D:/MecLearning/加油站数据.xls')
# 按照加油时间排序
df.sort_values(by='opetime', inplace=True)
# 打印排序后的数据
print(df)
b.统计加油站的站点数,统计用户总数,统计17:30~18:30期间加油的人数和平均加油量,以及该时间段的加油总量在一天中的占比:
# 统计加油站站点数
station_count = df['nodeno'].nunique()
# 统计用户总数
user_count = df['cardno'].nunique()
# 过滤出17:30~18:30期间的数据
filtered_data = df[(df['opetime'] >= '17:30:00') & (df['opetime'] <= '18:30:00')]
# 统计该时间段加油的人数和平均加油量
people_count = filtered_data['cardholder'].nunique()
average_liter = filtered_data['liter'].mean()
# 计算该时间段的加油总量占比
total_liter = filtered_data['liter'].sum()
total_day_liter = df['liter'].sum()
percentage = (total_liter / total_day_liter) * 100
print(f"加油站站点数:{station_count}")
print(f"用户总数:{user_count}")
print(f"17:30~18:30期间加油的人数:{people_count}")
print(f"平均加油量:{average_liter:.2f}升")
print(f"该时间段的加油总量占比:{percentage:.2f}%")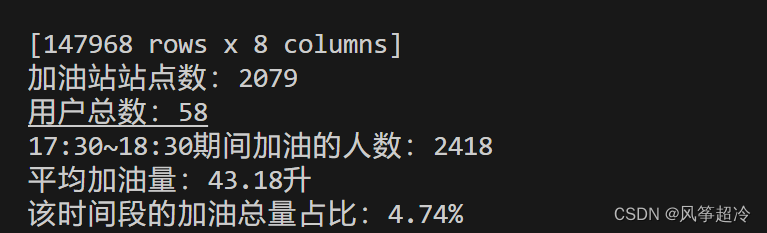
c.可视化展示用户卡号为“1000113200000151566”的加油量,分析用户常去的加油站点和通常的加油时间,并分析是否有异常时间段:
import pandas as pd
import matplotlib.pyplot as plt
import warnings
# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')
# 按照加油时间排序
df.sort_values(by='opetime', inplace=True)
# 过滤出指定用户的数据,并明确创建一个副本
user_data = df[df['cardno'] == 1000113200000160000].copy()
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 查找支持的中文字体
font_path = fm.findSystemFonts(fontpaths=None, fontext="ttf")
for font in font_path:
if "SimHei" in font:
plt.rcParams['font.sans-serif'] = [fm.FontProperties(fname=font).get_name()]
plt.rcParams['axes.unicode_minus'] = False
break
# 绘图代码
# 检查用户数据是否为空
if not user_data.empty:
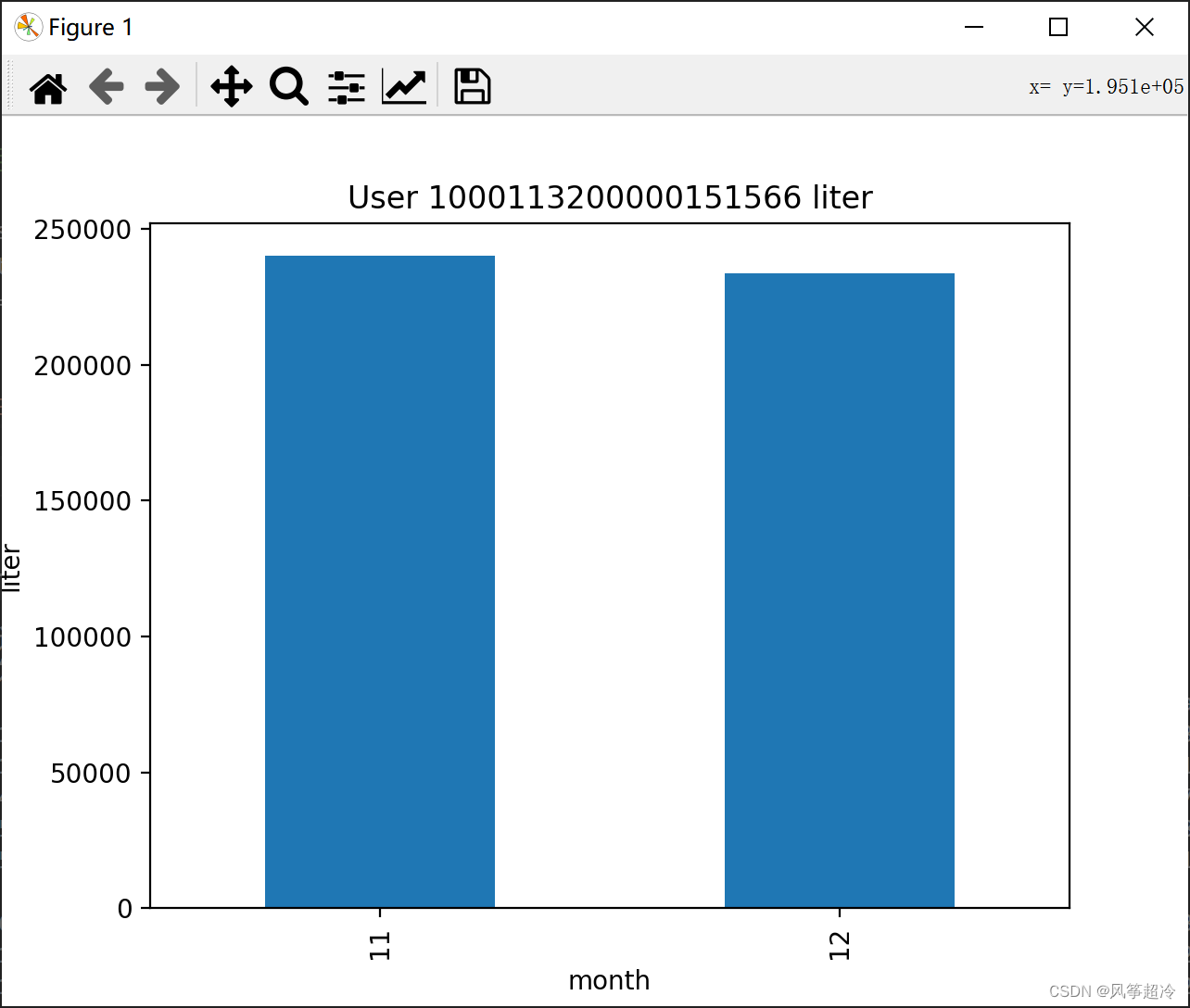
# a. 可视化用户加油量按月份
user_data['opetime'] = pd.to_datetime(user_data['opetime']) # 转换为日期时间类型
user_data['month'] = user_data['opetime'].dt.month # 提取月份
monthly_data = user_data.groupby('month')['liter'].sum() # 按月份统计加油量
monthly_data.plot(kind='bar')
plt.xlabel('month')
plt.ylabel('liter')
plt.title('User 1000113200000151566 liter')
plt.show()
# b. 分析用户常去的加油站点和通常的加油时间
frequent_station = user_data['nodeno'].mode().values[0]
frequent_time = user_data['opetime'].mode().values[0]
print(f"常去的加油站点:{frequent_station}")
print(f"通常的加油时间:{frequent_time}")
# c. 根据因素分析异常时间段
# 这部分需要进一步的数据分析和领域知识,以确定异常时间段
# 查找超出正常范围的加油量
mean_liter = user_data['liter'].mean()
std_liter = user_data['liter'].std()
threshold = mean_liter + 2 * std_liter # 将2倍标准差作为异常阈值
abnormal_periods = user_data[user_data['liter'] > threshold]
if not abnormal_periods.empty:
print("发现异常时间段:")
print(abnormal_periods)
else:
print("未找到用户1000113200000151566的加油记录")
d. 分析国庆节是否可以拉动加油站的经济增长,可以比较国庆节期间的加油量与整体和当月加油量的均值和方差:
import pandas as pd
import matplotlib.pyplot as plt
import warnings
# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')
# 假设国庆节日期范围为 '2007-10-01' 到 '2007-10-07'
national_day_data = df[(df['Date'] >= '2007-11-01') & (df['Date'] <= '2007-11-07')]
# 计算国庆节期间的加油量均值和方差
national_day_mean = national_day_data['liter'].mean()
national_day_var = national_day_data['liter'].var()
# 计算整体加油量均值和方差
overall_mean = df['liter'].mean()
overall_var = df['liter'].var()
# 计算当月加油量均值和方差
current_month_data = df[df['Date'].str.startswith('2007-11')]
current_month_mean = current_month_data['liter'].mean()
current_month_var = current_month_data['liter'].var()
# 打印比较结果
print(f"国庆节期间的加油量均值:{national_day_mean:.2f}升")
print(f"国庆节期间的加油量方差:{national_day_var:.2f}")
print(f"整体加油量均值:{overall_mean:.2f}升")
print(f"整体加油量方差:{overall_var:.2f}")
print(f"当月加油量均值:{current_month_mean:.2f}升")
print(f"当月加油量方差:{current_month_var:.2f}")
e. 推荐某用户周六9:00~19:00时间自由的加油时间和加油站点:
# 过滤出周六的数据
saturday_data = df[df['opetime'].dt.weekday == 5]
# 过滤出9:00~19:00的数据
saturday_data = saturday_data[(saturday_data['opetime'] >= '09:00:00') & (saturday_data['opetime'] <= '19:00:00')]
# 找出用户最常去的加油站点
frequent_station = saturday_data['nodeno'].mode().values[0]
# 找出平均加油量最高的时间段
best_time = saturday_data.groupby('opetime')['liter'].mean().idxmax()
print(f"推荐加油时间:{best_time}")
print(f"推荐加油站点:{frequent_station}")
f. 分析加油站点“32000966”的汽油价格波动情况:
计算price
import pandas as pd
import matplotlib.pyplot as plt
import warnings
# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据.xlsx')
# 检查是否包含 'amount' 和 'liter' 列
if 'amount' in df.columns and 'liter' in df.columns:
# 新增 'price' 列
df['price'] = df['amount'] / df['liter']
# 保存带有 'price' 列的新数据框到Excel文件
df.to_excel('D:/MecLearning/合并后的数据_with_price.xlsx', index=False)
else:
print("数据中缺少 'amount' 或 'liter' 列。")分析加油站点“32000966”的汽油价格波动
import pandas as pd
import matplotlib.pyplot as plt
import warnings
# 忽略特定警告
warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
# 读取Excel文件
df = pd.read_excel('D:/MecLearning/合并后的数据_with_price.xlsx')
# 假设数据集包含汽油价格字段为'price'
station_data = df[df['nodeno'] == '32000966']
station_data['Date'] = pd.to_datetime(station_data['Date']) # 转换为日期时间类型
station_data.sort_values(by='Date', inplace=True) # 按照加油时间排序
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# 设置日期时间刻度格式
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=1)) # 设置刻度间隔为一个月
# 绘制汽油价格的折线图
plt.plot(station_data['Date'], station_data['price'])
plt.xlabel('日期')
plt.ylabel('汽油价格')
plt.title('2007年加油站点32000966汽油价格波动情况')
plt.xticks(rotation=45) # 旋转x轴标签,以防止重叠
plt.grid() # 添加网格线
plt.show()