提示:Ambari-2.7.4和HDP-3.1.4安装
Hadoop集群安装目录
- 一、所需机器
- 二、系统环境配置
- 2.1准备
- 2.2配置5台主机的SSH免密登录(`所有机器` )
- 2.3同步时钟,开启NTP服务(`所有机器`)
- 2.4每台节点里配置FQDN,如下以主节点(master.hadoop)为例(`所有机器`)
- 2.5 修改文件打开限制(`所有机器`)
- 2.6关闭防火墙,关闭SELinux(`所有机器`)
- 2.7修改配置文件后重启所有五台机器
- 三、安装ambari,使用ambari安装hadoop集群
- 3.1制作本地源
- 3.2安装Mysql 5.7.27数据库
- 3.3安装JDK1.8(`所有机器`)
- 3.4安装配置Ambari
一、所需机器
部署5台Centos 7.6虚拟机
注意:安装的centos系统必须选择英文版本,最小化安装
二、系统环境配置
2.1准备
(1)修改本机名(所有机器)
- 第一种
[root@localhost ~]# vi /etc/hostname
主节点:master (192.168.31.11)
从节点:slave1 (192.168.31.12)
从节点:slave2 (192.168.31.13)
从节点:slave2 (192.168.31.14)
从节点:slave2 (192.168.31.15)
执行reboot,让主机名生效
reboot
- 第二种
#1.使用`hostnamectl`命令更新主机名:
sudo hostnamectl set-hostname <new_hostname>
#将`<new_hostname>`替换为您想要设置的新主机名。
#2.重新启动系统:
sudo reboot
#重新启动系统会使新的主机名生效。
#3.确认主机名已经修改:
hostname
#执行`hostname`命令,确认输出的主机名是否是您设置的新主机名。
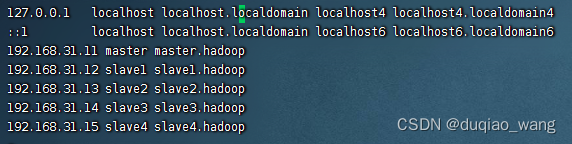
(2)修改5台机器hosts(所有机器)
ambari在安装时需要配置全域名,所以需要检查
为了减轻DNS的负担, 建议在节点里用 Name Service Caching Daemon (NSCD)
vi /etc/hosts
192.168.31.11 master master.hadoop
192.168.31.12 slave1 slave1.hadoop
192.168.31.13 slave2 slave2.hadoop
192.168.31.14 slave3 slave3.hadoop
192.168.31.15 slave4 slave4.hadoop
2.2配置5台主机的SSH免密登录(所有机器 )
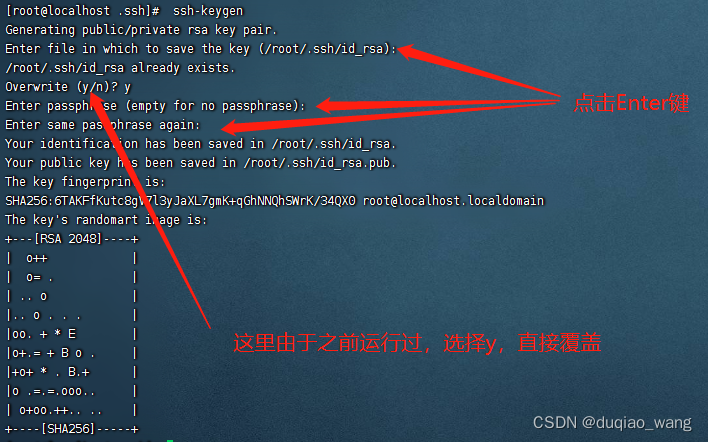
- 主节点(master.hadoop)里root用户登录执行命令(
注释:主节点创建密钥)
[root@master ~]# ssh-keygen
[root@master ~]# cd ~/.ssh/
[root@master ~]# cat id_rsa.pub >> authorized_keys
[root@master ~]# chmod 700 ~/.ssh
[root@master ~]# chmod 600 ~/.ssh/authorized_keys
在从节点(slave1.hadoop,slave2.hadoop,slave3.hadoop,slave4.hadoop)里root用户登录执行命令(注释:从节点上新建.ssh文件夹,用来接收主节点分发过来的密钥)
[root@slave1 ~]# mkdir ~/.ssh/
- 分发主节点里配置好的authorized_keys到各从节点
[root@master ~]#
scp /root/.ssh/authorized_keys root@192.168.31.11:/root/.ssh/authorized_keys
[root@master ~]#
scp /root/.ssh/authorized_keys root@192.168.31.12:/root/.ssh/authorized_keys
[root@master ~]#
scp /root/.ssh/authorized_keys root@192.168.31.13:/root/.ssh/authorized_keys
[root@master ~]#
scp /root/.ssh/authorized_keys root@192.168.31.14:/root/.ssh/authorized_keys
[root@master ~]#
scp /root/.ssh/authorized_keys root@192.168.31.15:/root/.ssh/authorized_keys

(注释:第一次分发密钥,需要输入从节点root账户的密码)
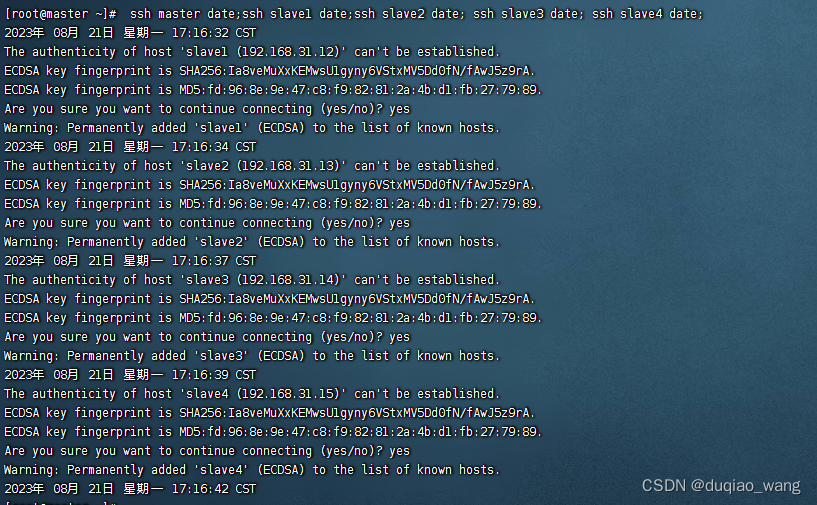
- 在主节点上测试是否实现了无密码登录
[root@master ~]# ssh master date;ssh slave1 date;ssh slave2 date; ssh slave3 date; ssh slave4 date;
- 将
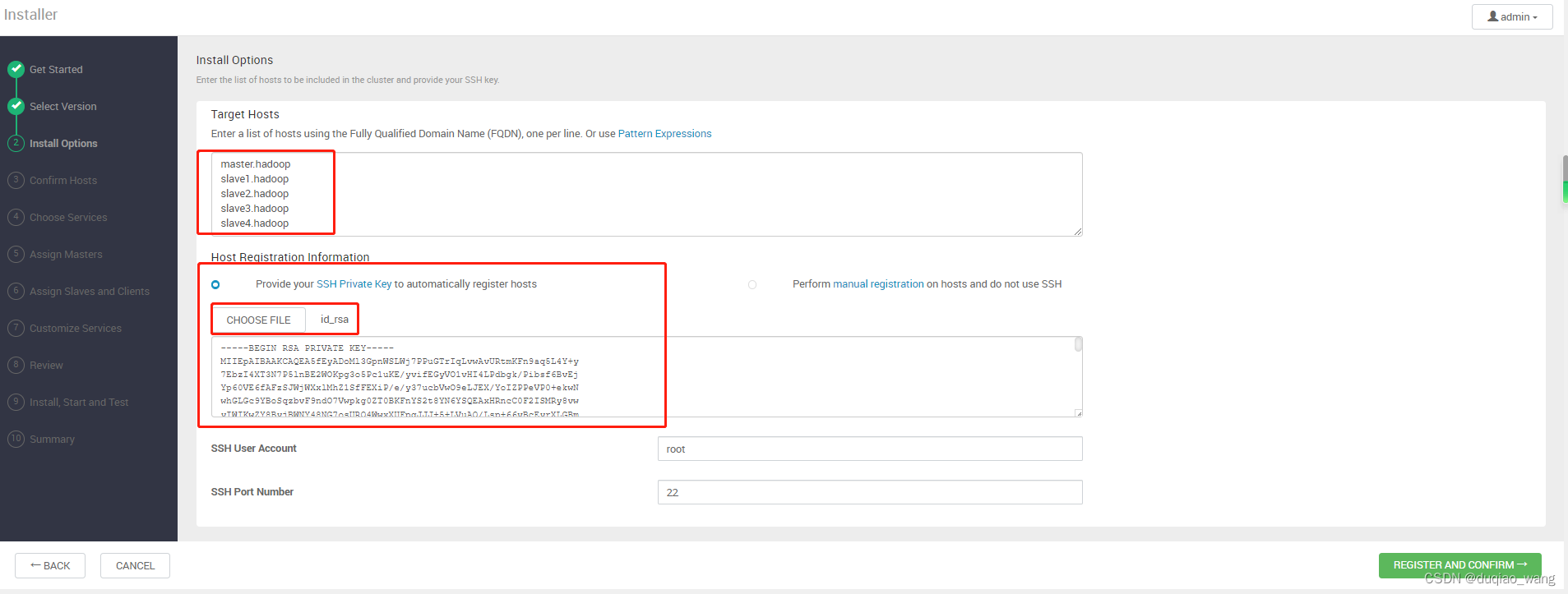
主节点上创建的秘钥拷贝出来,因为后面ambari安装的时候需要上传这个秘钥。创建秘钥是在隐藏文件夹/root/.ssh/下面的,所以需要先把秘钥拷贝到可见区域,然后拷贝到本地电脑上。
[root@ master ~]# cd /root/.ssh/
[root@ master ~]# cp id_rsa /root/
[root@ master ~]# ls /root/
2.3同步时钟,开启NTP服务(所有机器)
[root@localhost ~]# yum -y install ntp
[root@localhost ~]# systemctl is-enabled ntpd
[root@localhost ~]# systemctl enable ntpd.service
[root@localhost ~]# systemctl start ntpd.service
2.4每台节点里配置FQDN,如下以主节点(master.hadoop)为例(所有机器)
[root@localhost ~]# vi /etc/sysconfig/network
#master
NETWORKING=yes
HOSTNAME= master.hadoop

其他几台,操作同master
# slave1
NETWORKING=yes
HOSTNAME= slave1.hadoop
# slave2
NETWORKING=yes
HOSTNAME= slave2.hadoop
# slave3
NETWORKING=yes
HOSTNAME= slave3.hadoop
# slave4
NETWORKING=yes
HOSTNAME= slave4.hadoop
2.5 修改文件打开限制(所有机器)
[root@localhost ~]# vi /etc/security/limits.conf
# End of file
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072

2.6关闭防火墙,关闭SELinux(所有机器)
- 关闭防火墙,所有节点都要设置
[root@localhost ~]# systemctl status firewalld
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
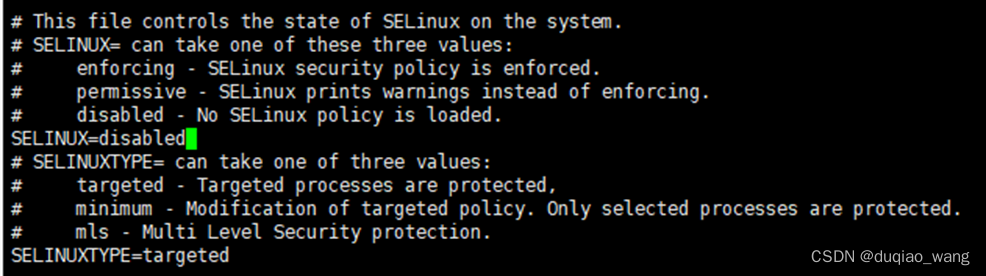
- 关闭SELinux,所有节点都要设置
查看SELinux状态:
[root@localhost ~]# sestatus
如果SELinuxstatus参数为enabled即为开启状态
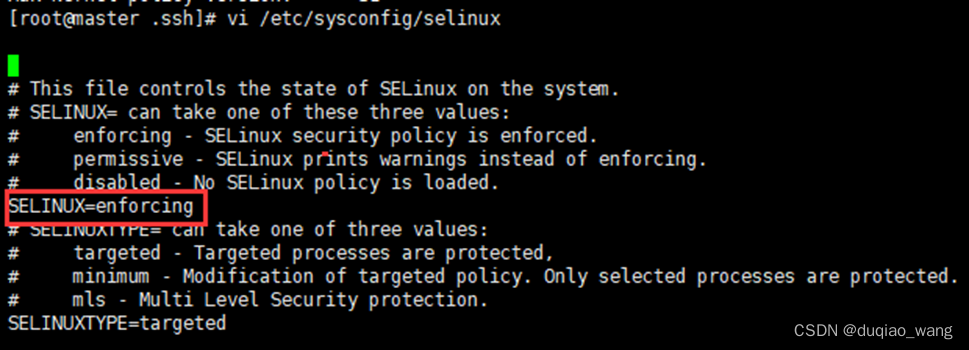
修改为:SELINUX=disabled
2.7修改配置文件后重启所有五台机器
[root@localhost ~]# reboot
三、安装ambari,使用ambari安装hadoop集群
3.1制作本地源
ps:制作本地源只需在主节点(master.hadoop)上进行即可
#安装HTTP服务器,允许http服务通过防火墙(永久)
[root@localhost ~]# yum -y install httpd
#添加Apache 服务到系统层使其随系统自动启动
[root@localhost ~]# systemctl start httpd.service
[root@localhost ~]# systemctl enable httpd.service
#安装本地源制作相关工具
[root@localhost ~]# yum -y install yum-utils createrepo yum-plugin-priorities
[root@localhost ~]# createrepo ./
- 在httpd网站根目录,默认是即/var/www/html/,创建目录ambari, 并且将下载的压缩包解压到/var/www/html/ambari目录
[root@localhost ~]# cd /var/www/html/
[root@localhost ~]# mkdir ambari
[root@localhost ~]# cd /var/www/html/ambari/
[root@localhost ~]# tar -zxvf ambari-2.7.4.0-centos7.tar.gz
[root@localhost ~]# tar -zxvf HDP-3.1.4.0-centos7-rpm.tar.gz
[root@localhost ~]# tar -zxvf HDP-UTILS-1.1.0.22-centos7.tar.gz
- 验证httd网站是否可用,可以使用links 命令或者浏览器直接访问下面的地址:
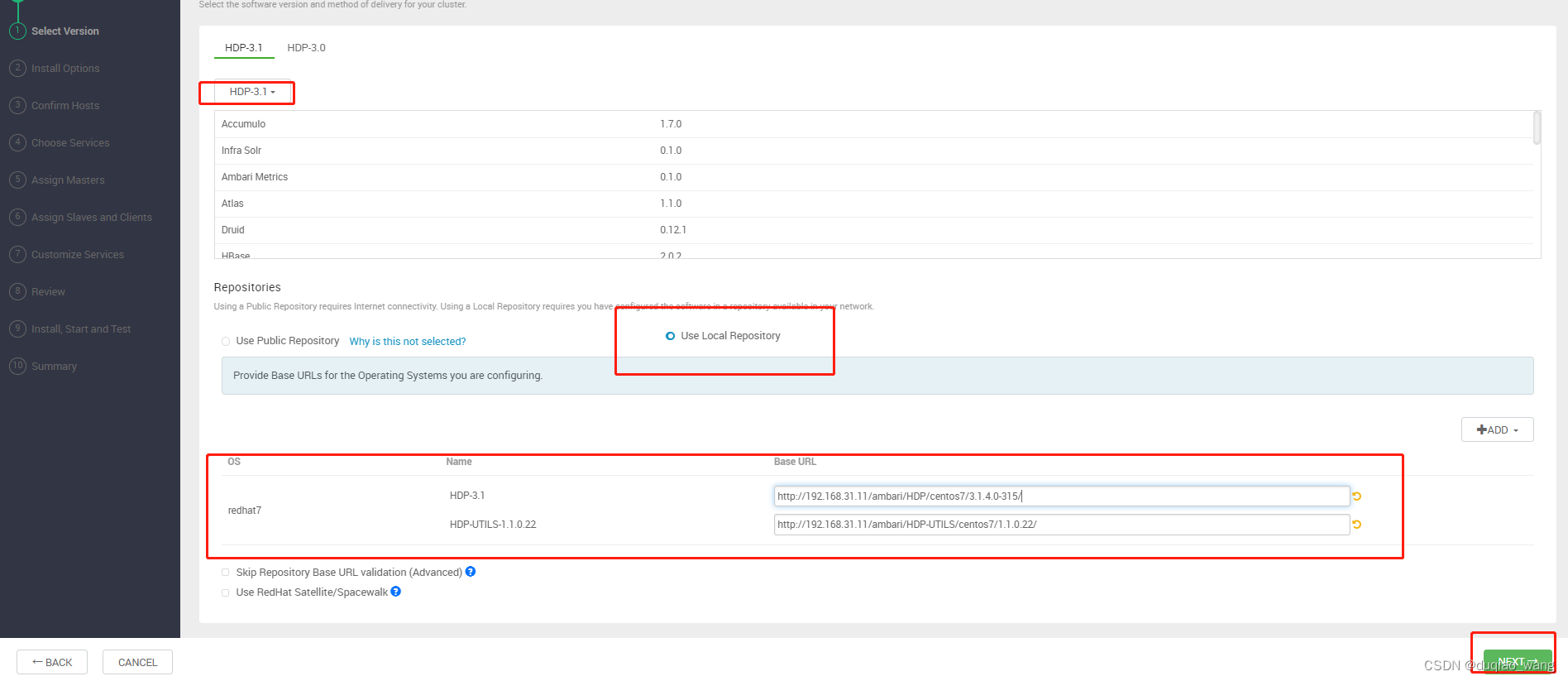
http://192.168.31.11/ambari/ - 配置ambari、HDP、HDP-UTILS的本地源
# 配置ambari源
vi /etc/yum.repos.d/ambari.repo
#内容如下
[ambari]
name=ambari
baseurl=http://192.168.31.11/ambari/ambari/centos7/2.7.4.0-118/
gpgcheck=0
# 配置hdp和hdp-utils源
vi /etc/yum.repos.d/hdp.repo
# 内容如下
[HDP]
name=HDP
baseurl=http://192.168.31.11/ambari/HDP/centos7/3.1.4.0-315/
gpgcheck=0
[HDP-UTILS]
name=HDP_UTILS
baseurl=http://192.168.31.11/ambari/HDP-UTILS/centos7/1.1.0.22/
gpgcheck=0
- 分发到其他机器
cd /etc/yum.repos.d
scp ambari.repo slave1:/etc/yum.repos.d/
scp ambari.repo slave2:/etc/yum.repos.d/
scp ambari.repo slave3:/etc/yum.repos.d/
scp ambari.repo slave4:/etc/yum.repos.d/
scp hdp.repo slave1:/etc/yum.repos.d/
scp hdp.repo slave2:/etc/yum.repos.d/
scp hdp.repo slave3:/etc/yum.repos.d/
scp hdp.repo slave4:/etc/yum.repos.d/
- 上面就创建好了主机上的文件,然后每台机器yum配置
[root@localhost ~]# yum clean all
[root@localhost ~]# yum makecache
[root@localhost ~]# yum repolist
3.2安装Mysql 5.7.27数据库
3.3安装JDK1.8(所有机器)
- 安装解压版JDK,jdk-8u212-linux-x64.tar.gz
- 再执行下面命令:
[root@localhost ~]# mkdir /opt/java
#将jdk-8u91-linux-x64.tar.gz文件放到/opt/java下
[root@localhost ~]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/java/
[root@localhost ~]# vi /etc/profile
# ---Set Java Environment---
JAVA_HOME=/opt/java/jdk1.8.0_212
JRE_HOME=/opt/java/jdk1.8.0_212/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
# ---Set Java Environment---
[root@localhost ~]# source /etc/profile
3.4安装配置Ambari
注意:在主节点(master.hadoop)上完成以下操作
- 1.安装ambari-server
[root@localhost ~]# yum -y install ambari-server
- 2.配置MySQL
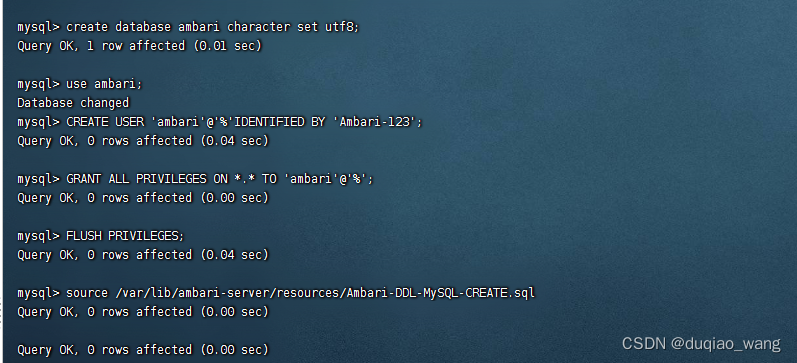
-(1)登录主节点(master.hadoop)上的MySQL
mysql -uroot -pMysql-502
create database ambari character set utf8;
use ambari;
CREATE USER 'ambari'@'%'IDENTIFIED BY 'Ambari-123';
GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'%';
FLUSH PRIVILEGES;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
(2)如果需要安装hive就执行,不装hive不管
登录从节点(slave1.hadoop)上的MySQL
[root@localhost ~]# mysql -uroot -pMysql-502
#因为要安装Hive,再创建Hive数据库和用户:
create database hive character set utf8;
use hive;
CREATE USER 'hive'@'%'IDENTIFIED BY 'Hive-123';
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%';
FLUSH PRIVILEGES;
(3)切换到主节点(master.hadoop)上操作,实现ambari-server与mysql的连接
[root@localhost ~]# cp /usr/share/java/mysql-connector-java.jar /var/lib/ambari-server/resources/mysql-jdbc-driver.jar
[root@localhost ~]# ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar

(4)初始化ambari配置
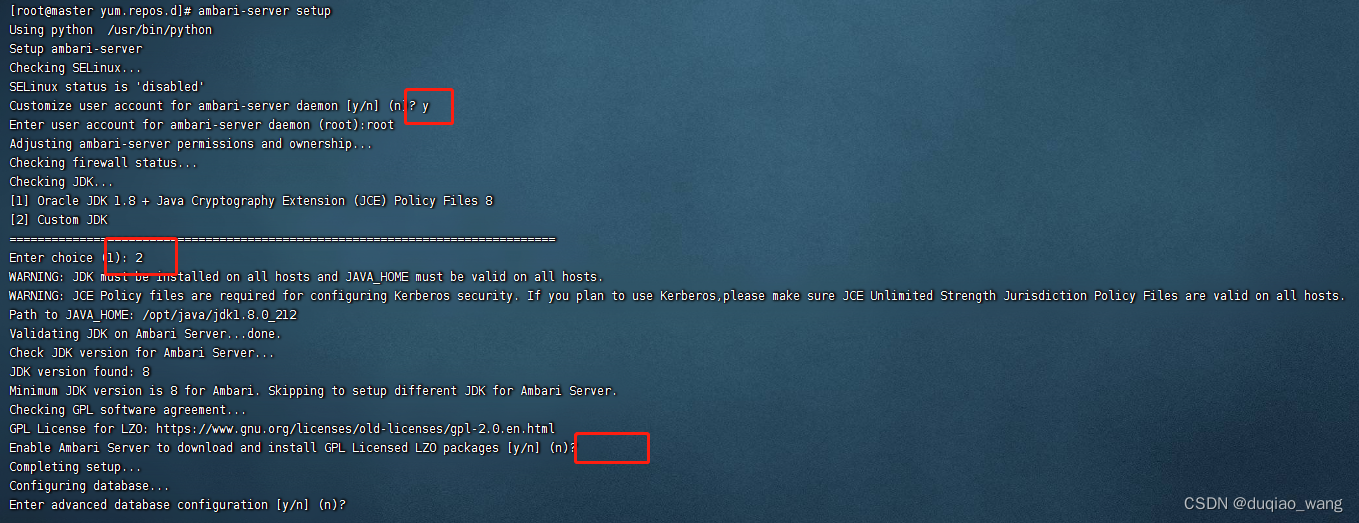
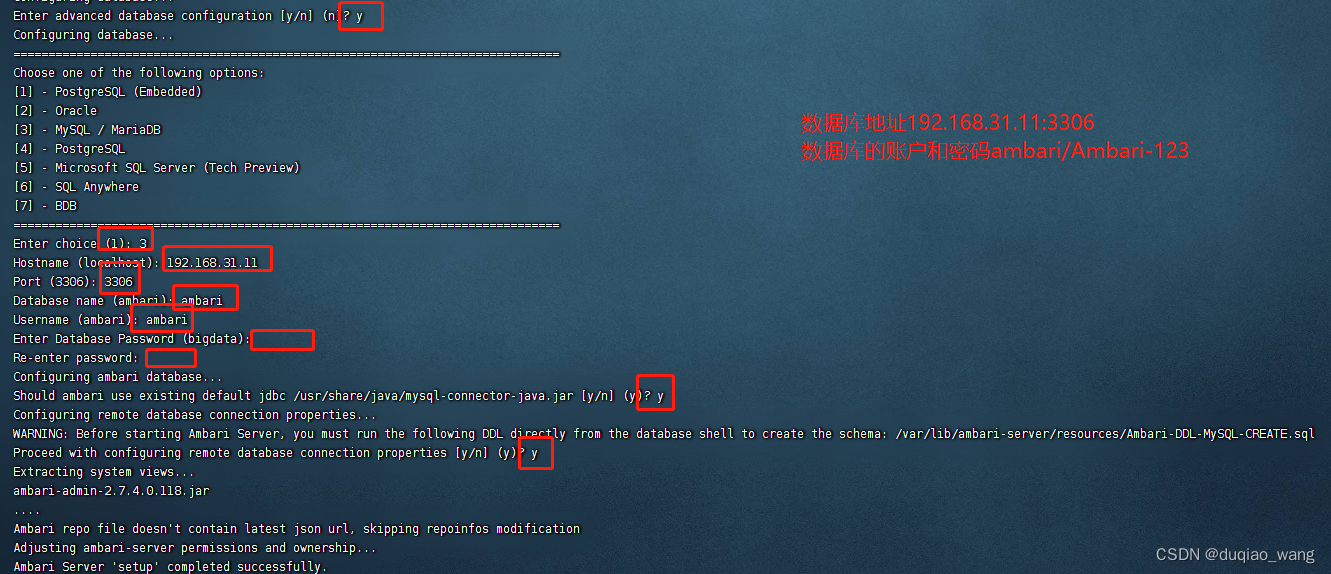
[root@localhost ~]# ambari-server setup
选择注意: ambari-server用户是root
JDK路径是自定义路径 /opt/java/jdk1.8.0_212
数据库地址192.168.31.121:306
数据库的账户和密码ambari/Ambari-123
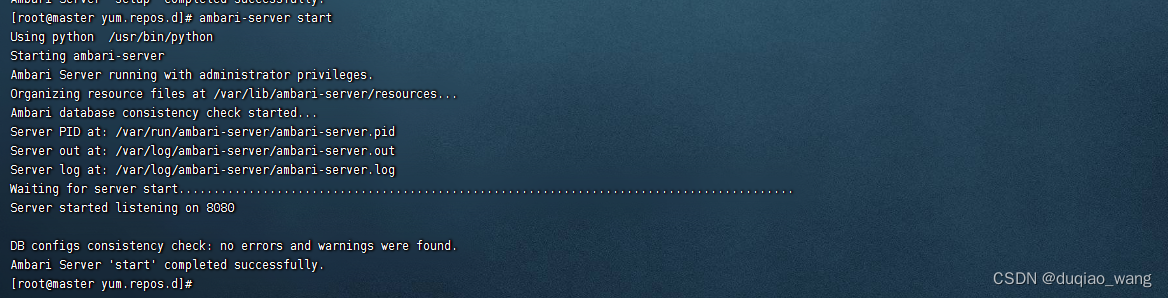
(5)执行启动命令,启动Ambari服务
(6)所有机器安装ambari-agent
[root@localhost ~]# yum -y install ambari-agent
(7)成功启动后在浏览器输入Ambari地址:
http://192.168.31.11:8080/
出现登录界面,默认管理员账户登录,账户:admin 密码:admin
(8)Ambari配置安装Hadoop集群
-
a
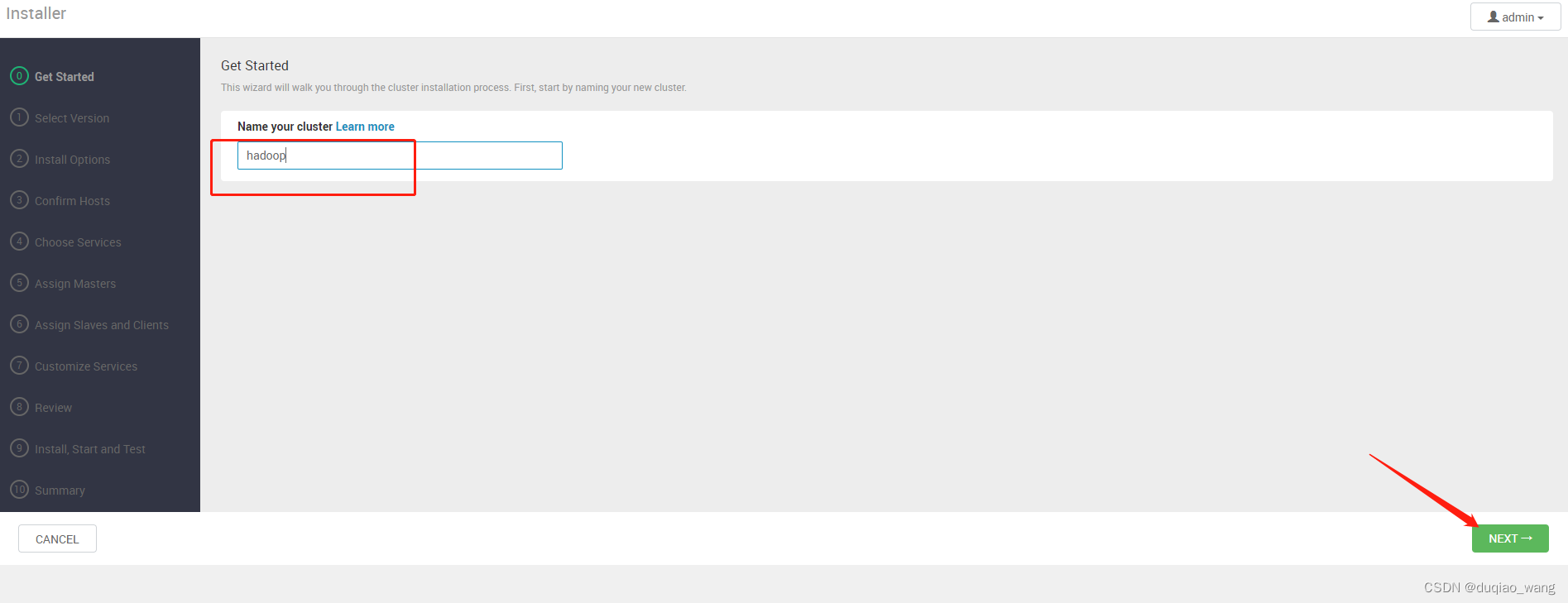
-
b
-
c
-
d
机架:
master.hadoop
slave1.hadoop
slave2.hadoop
slave3.hadoop
slave4.hadoop
-
e
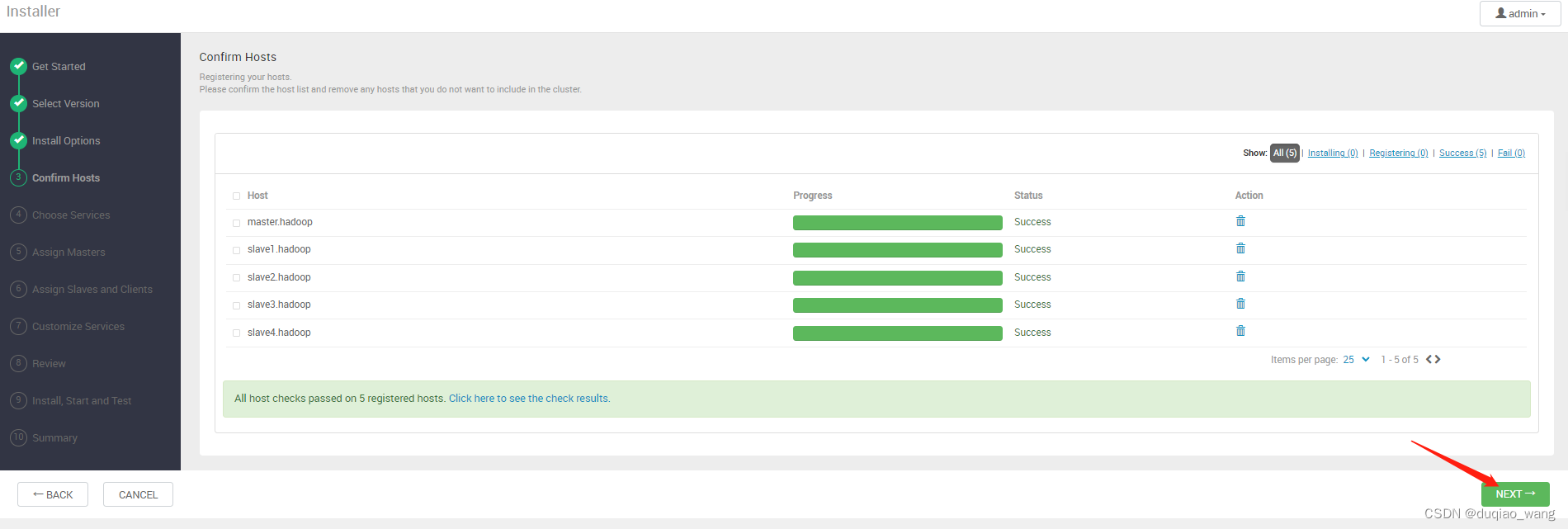
-
f 安装HDFS
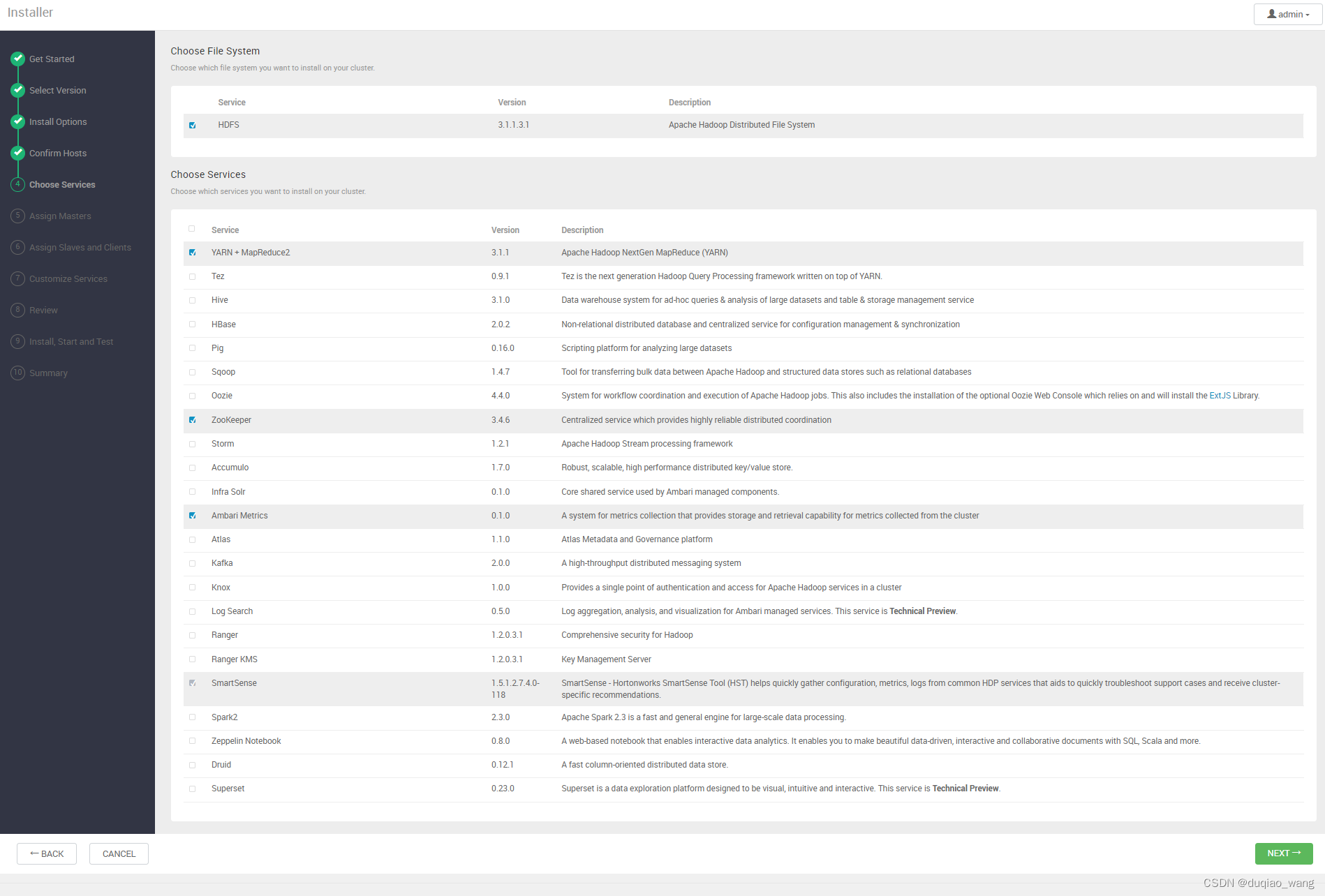
-
g
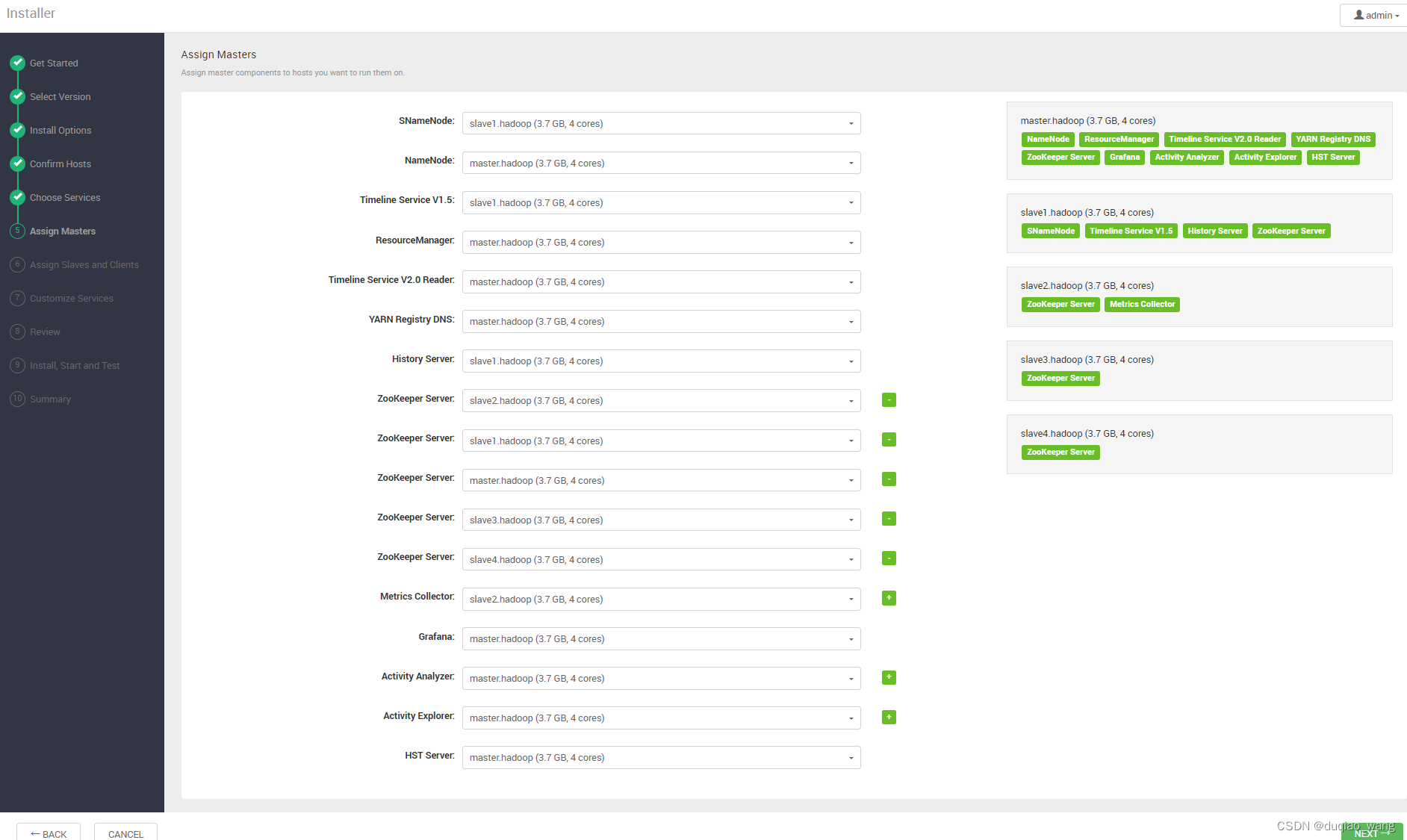
-
h
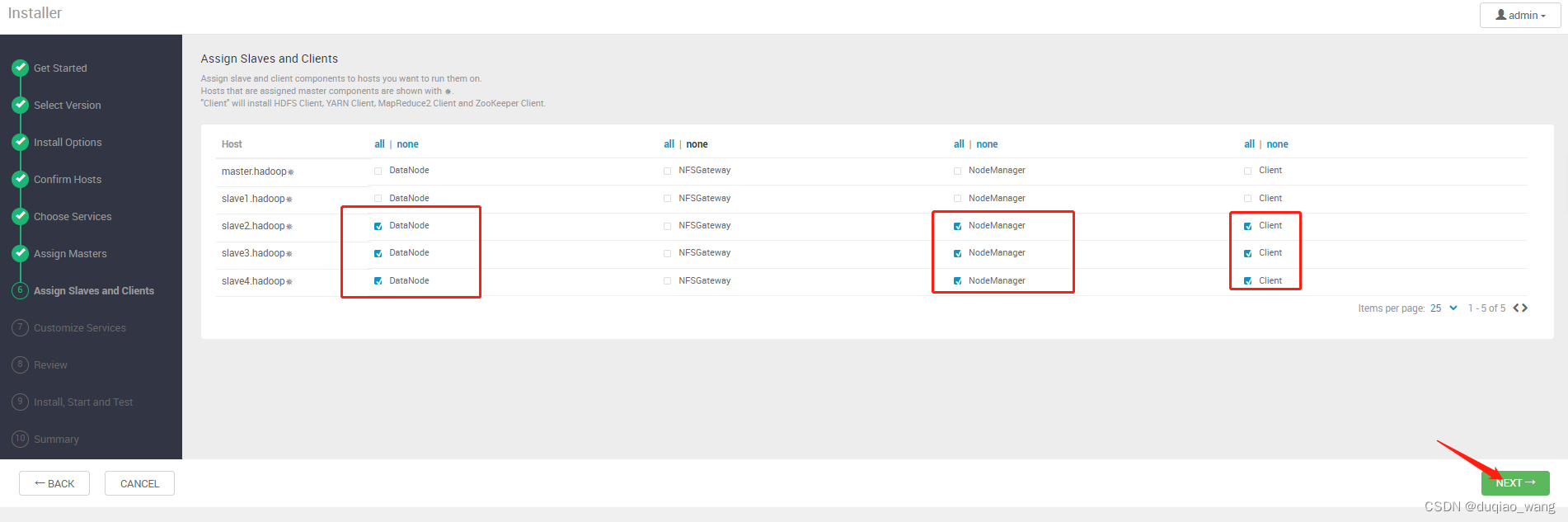
-
i
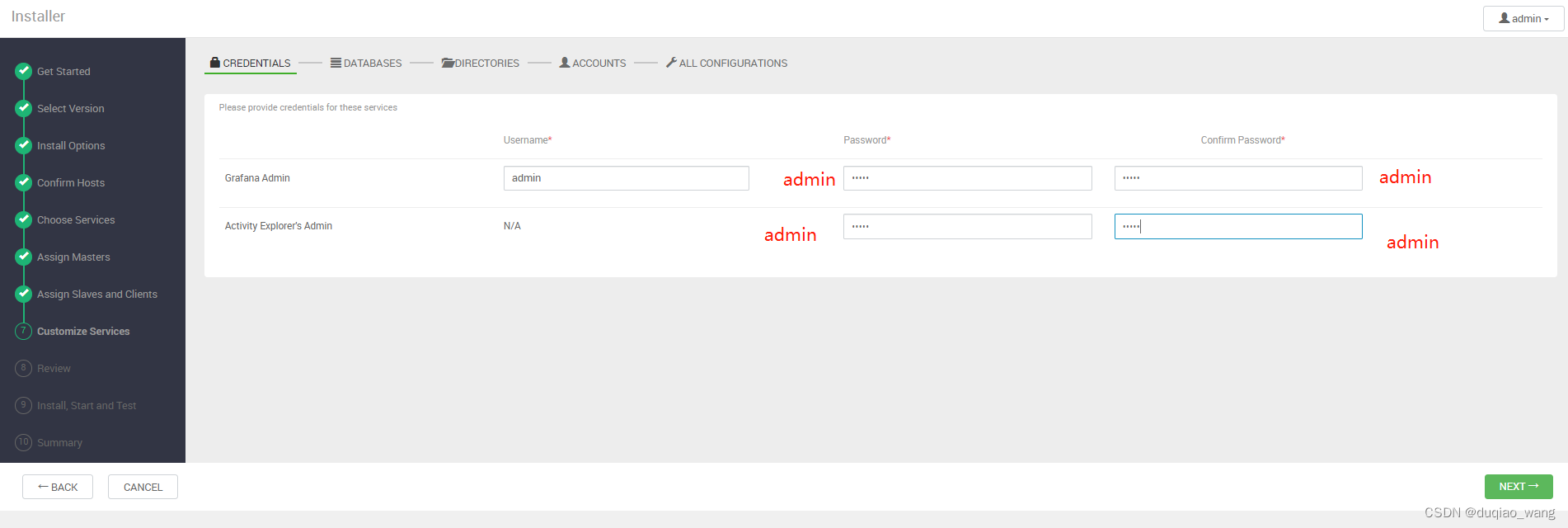
-
j
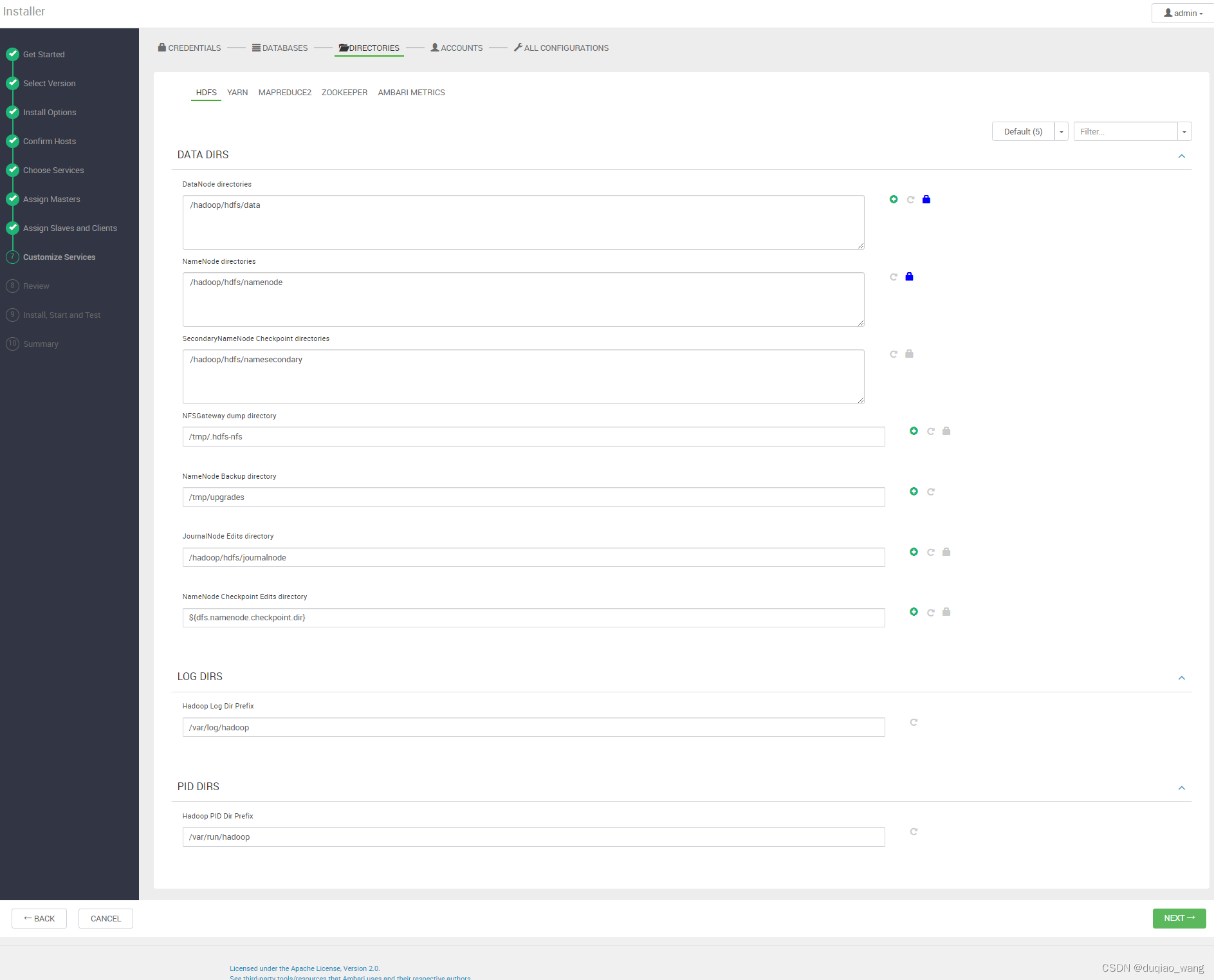
-
k
-
l
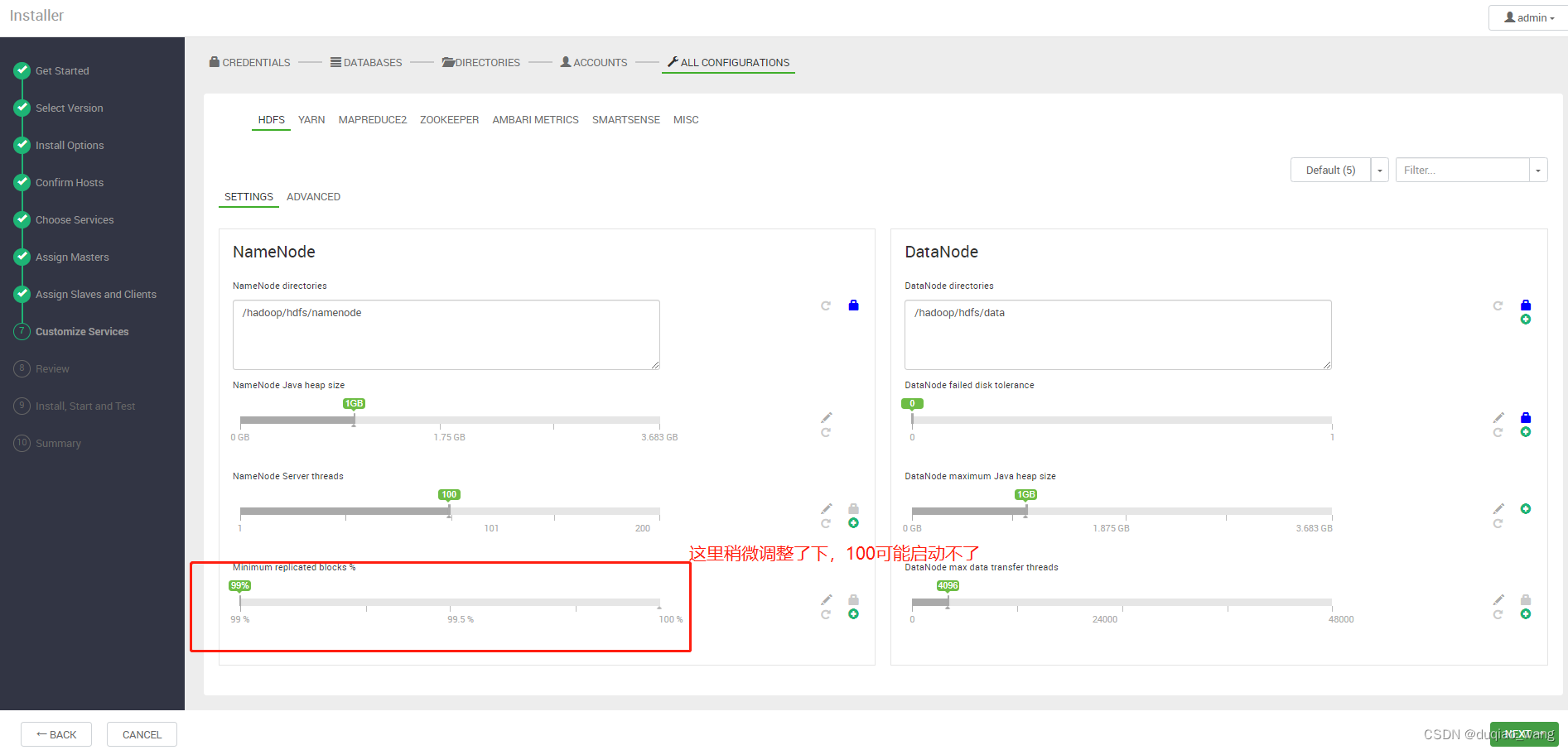
-
m
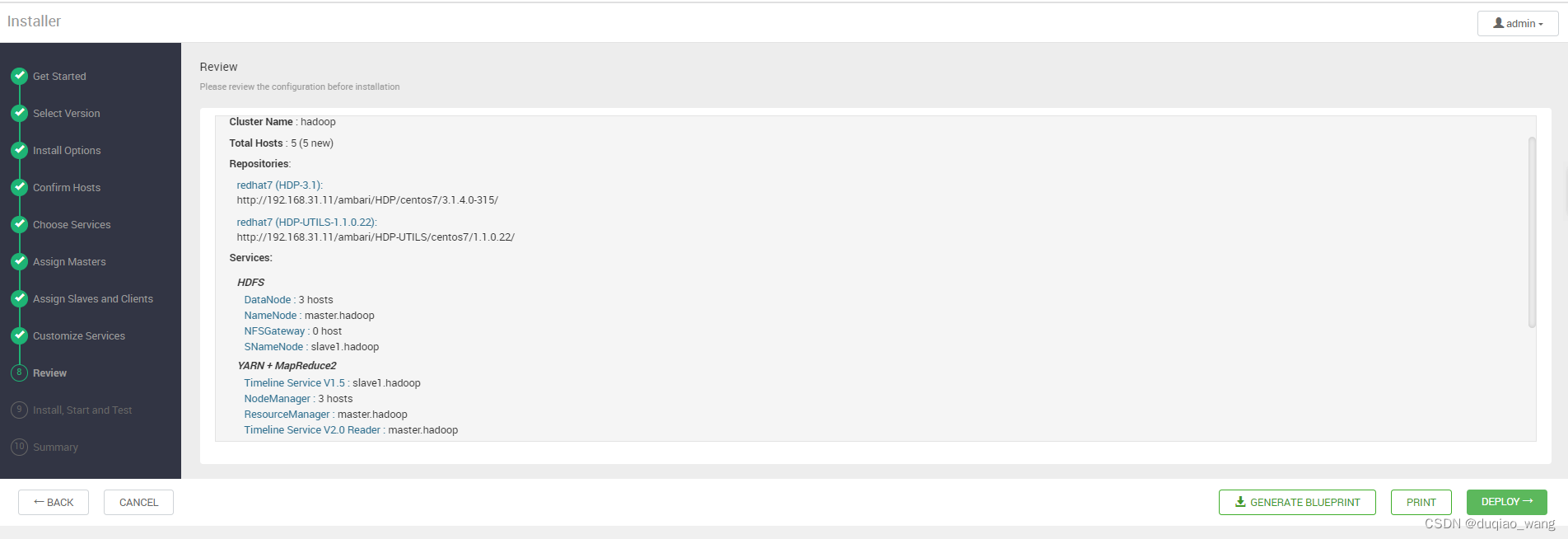
-
n
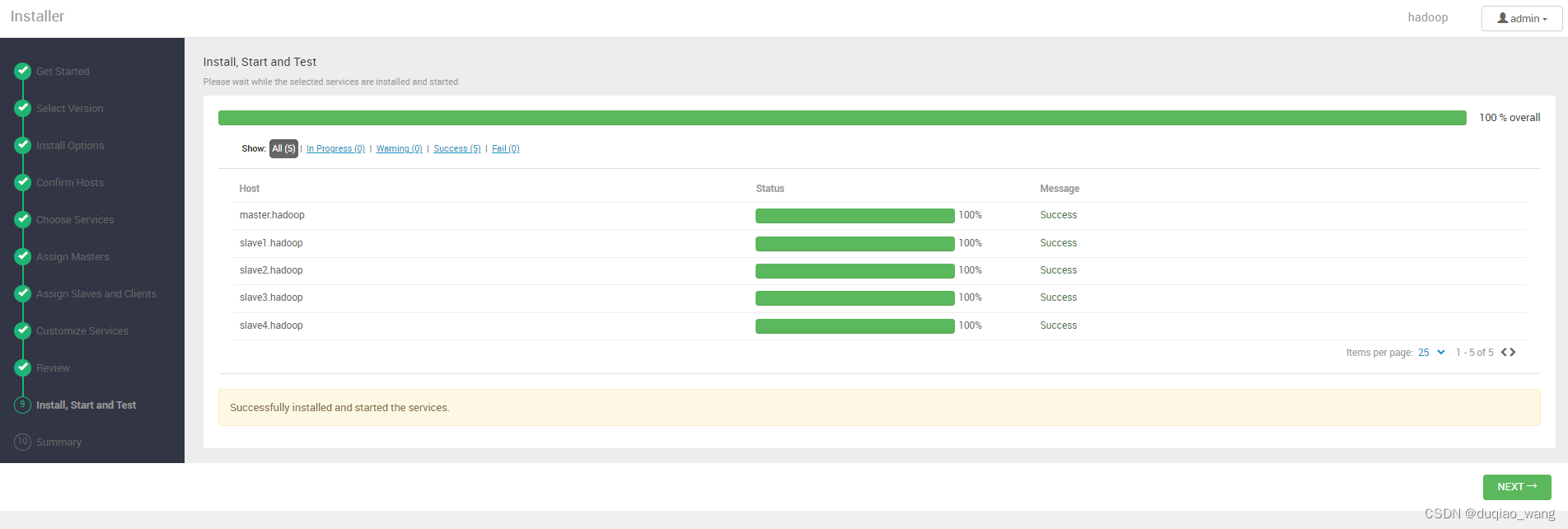
-
o

-
p 完成安装
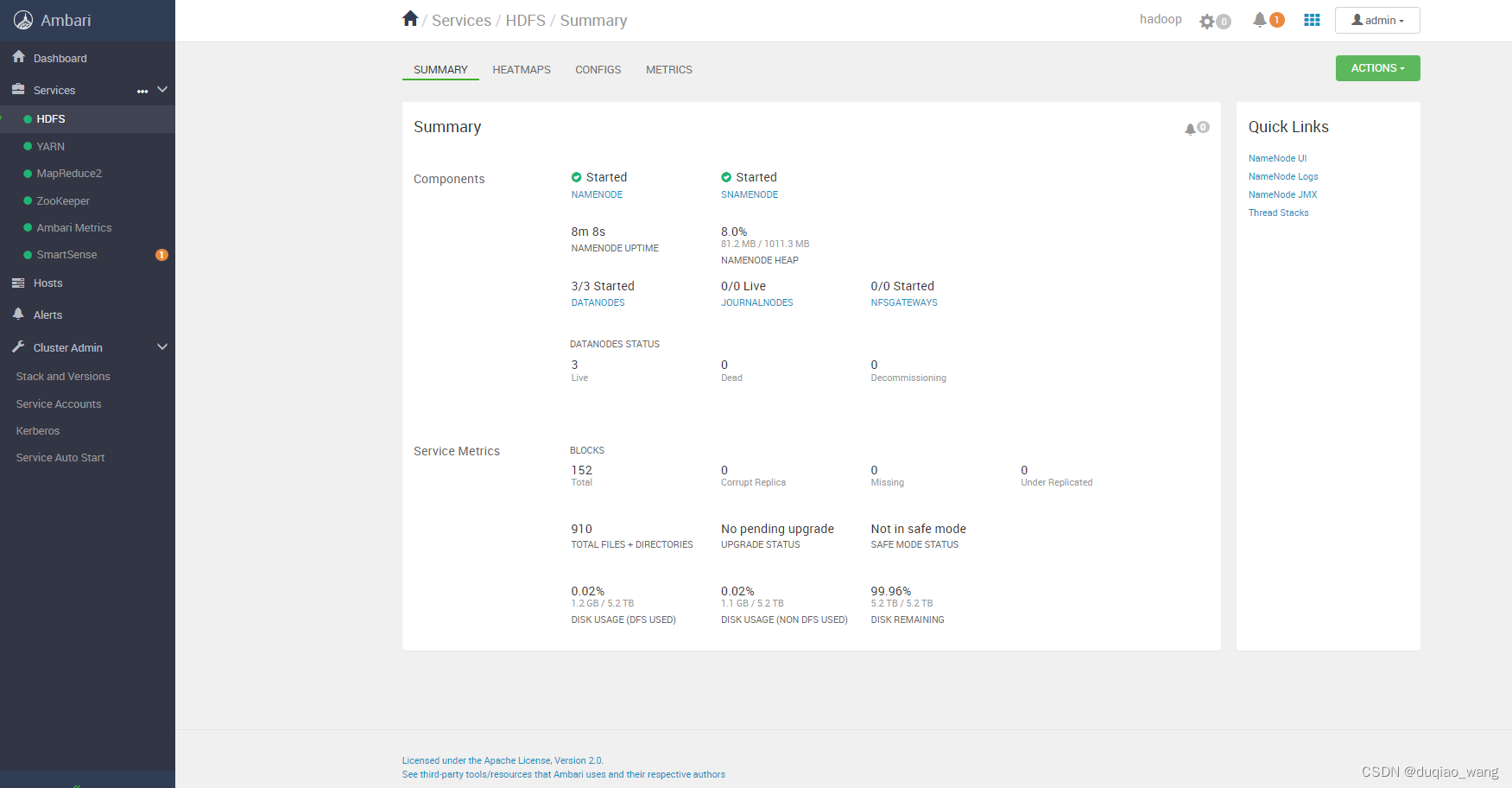
-
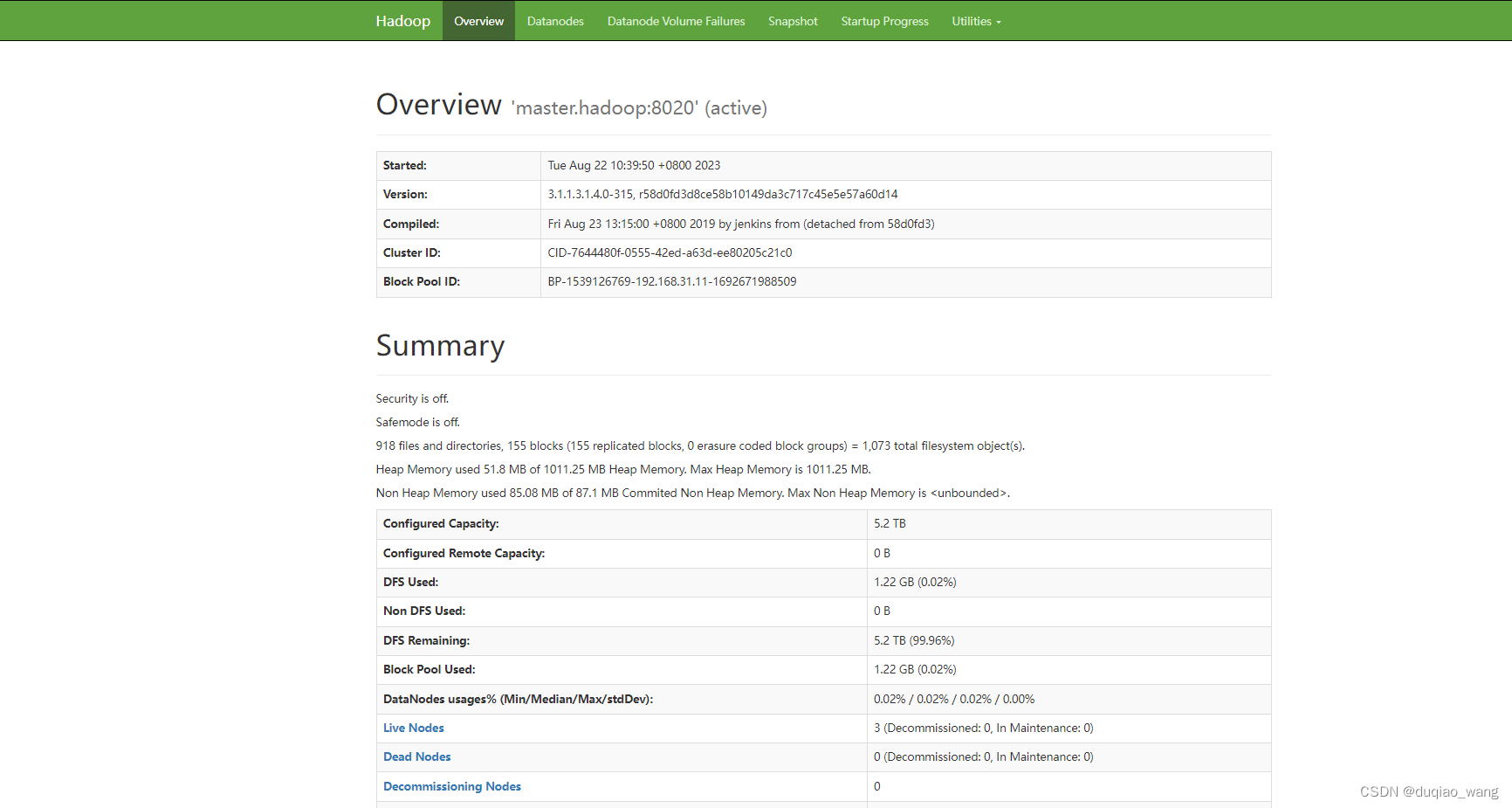
q HDFS访问页面
http://192.168.31.11:50070/dfshealth.html#tab-overview
(9)修改配置
- a 修改DataNode文件夹权限
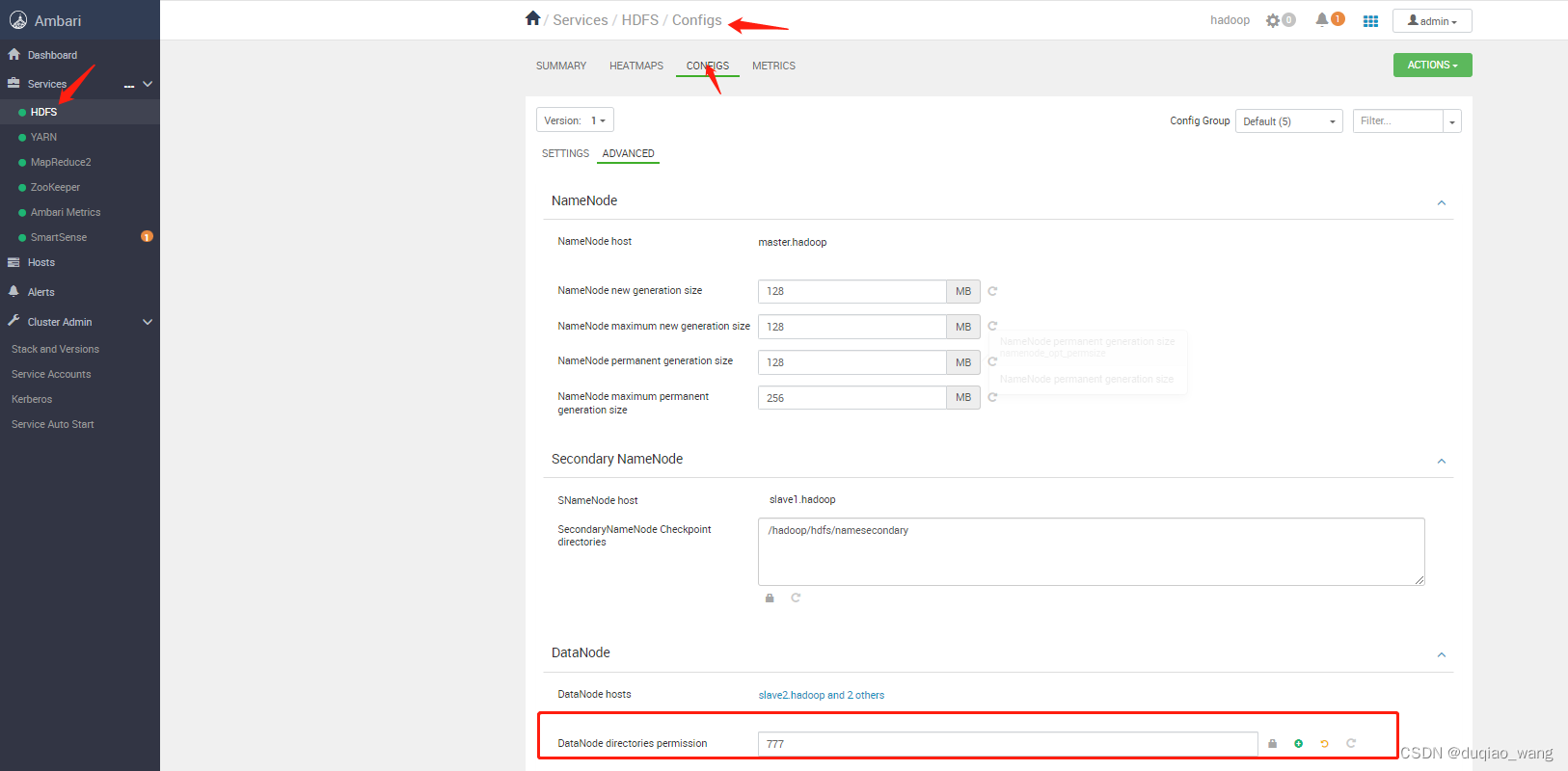
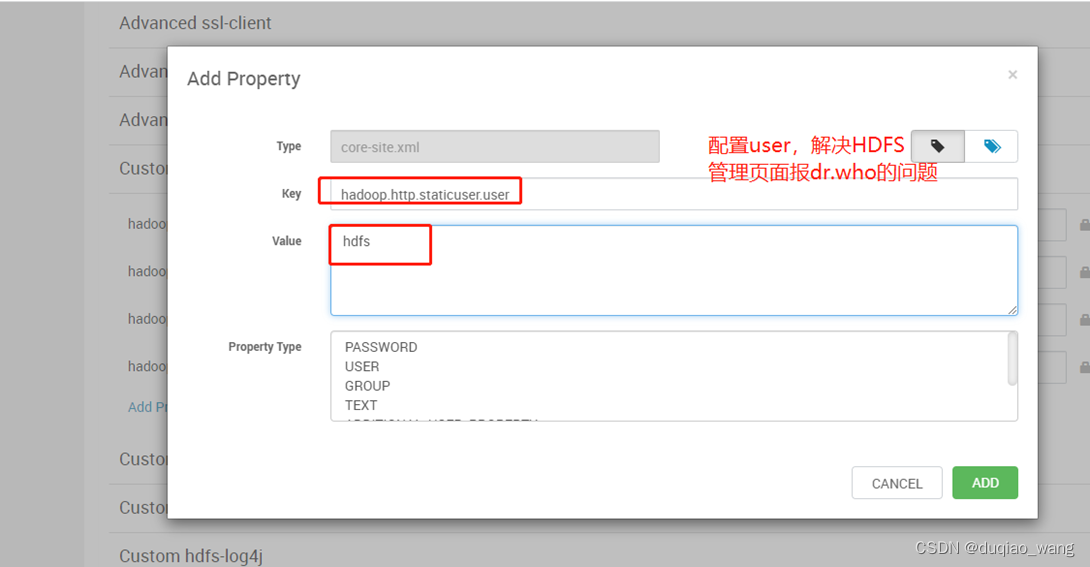
- b 修改Custom core-site.xml,配置staticuser.user
hadoop.http.staticuser.user
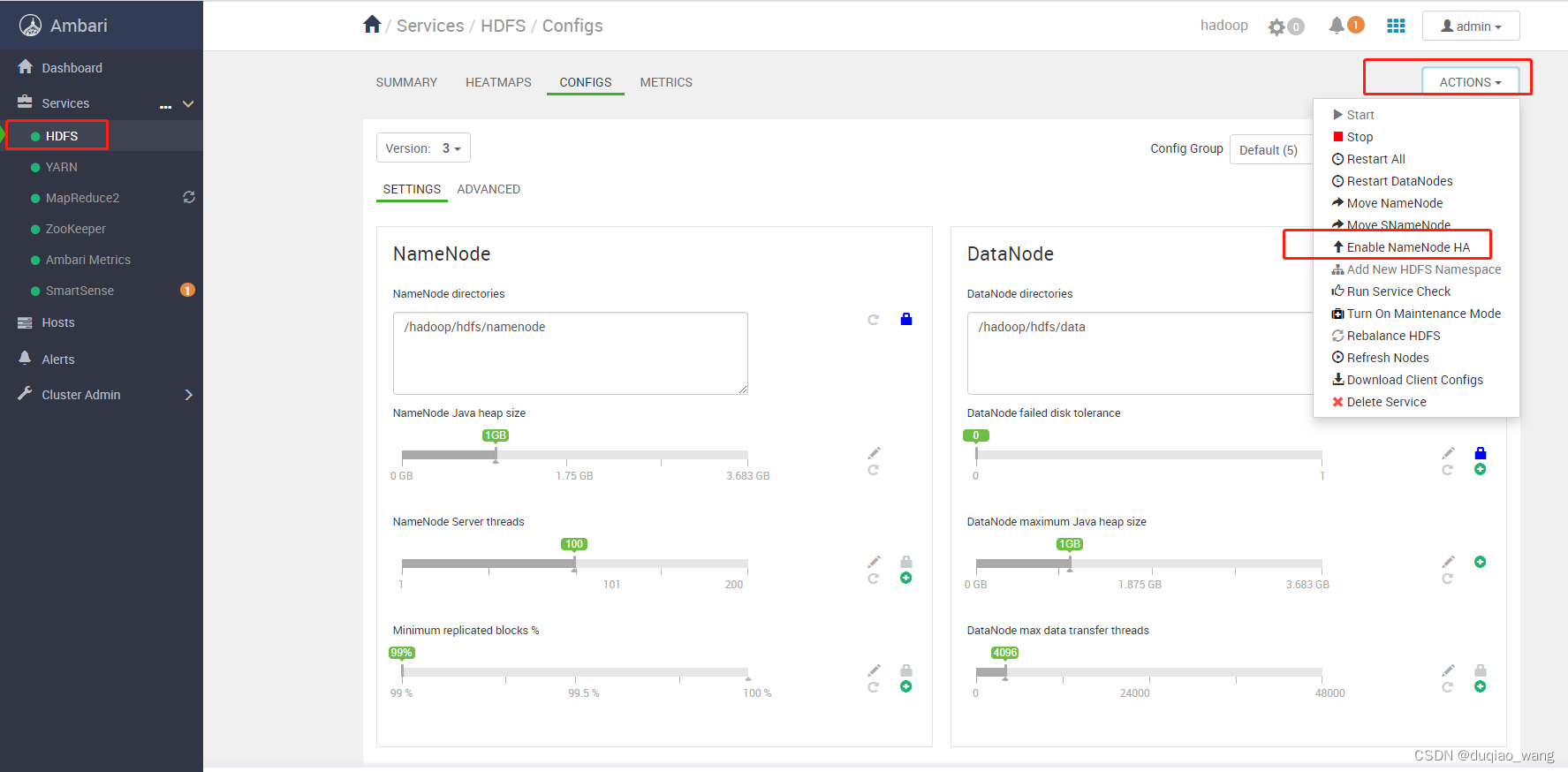
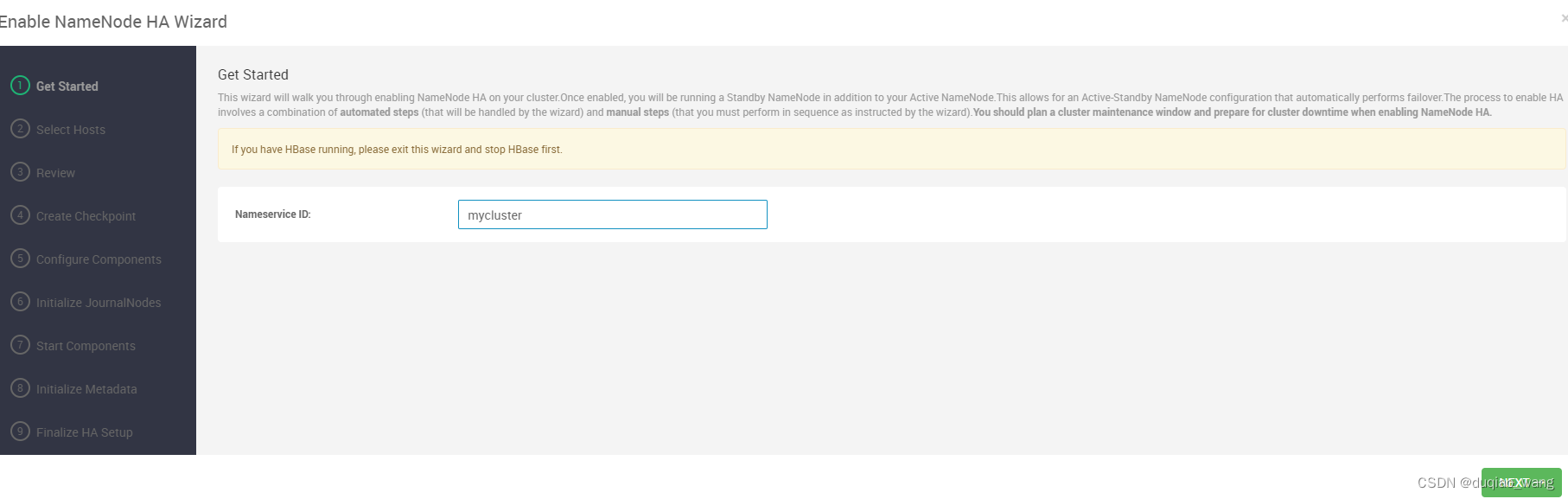
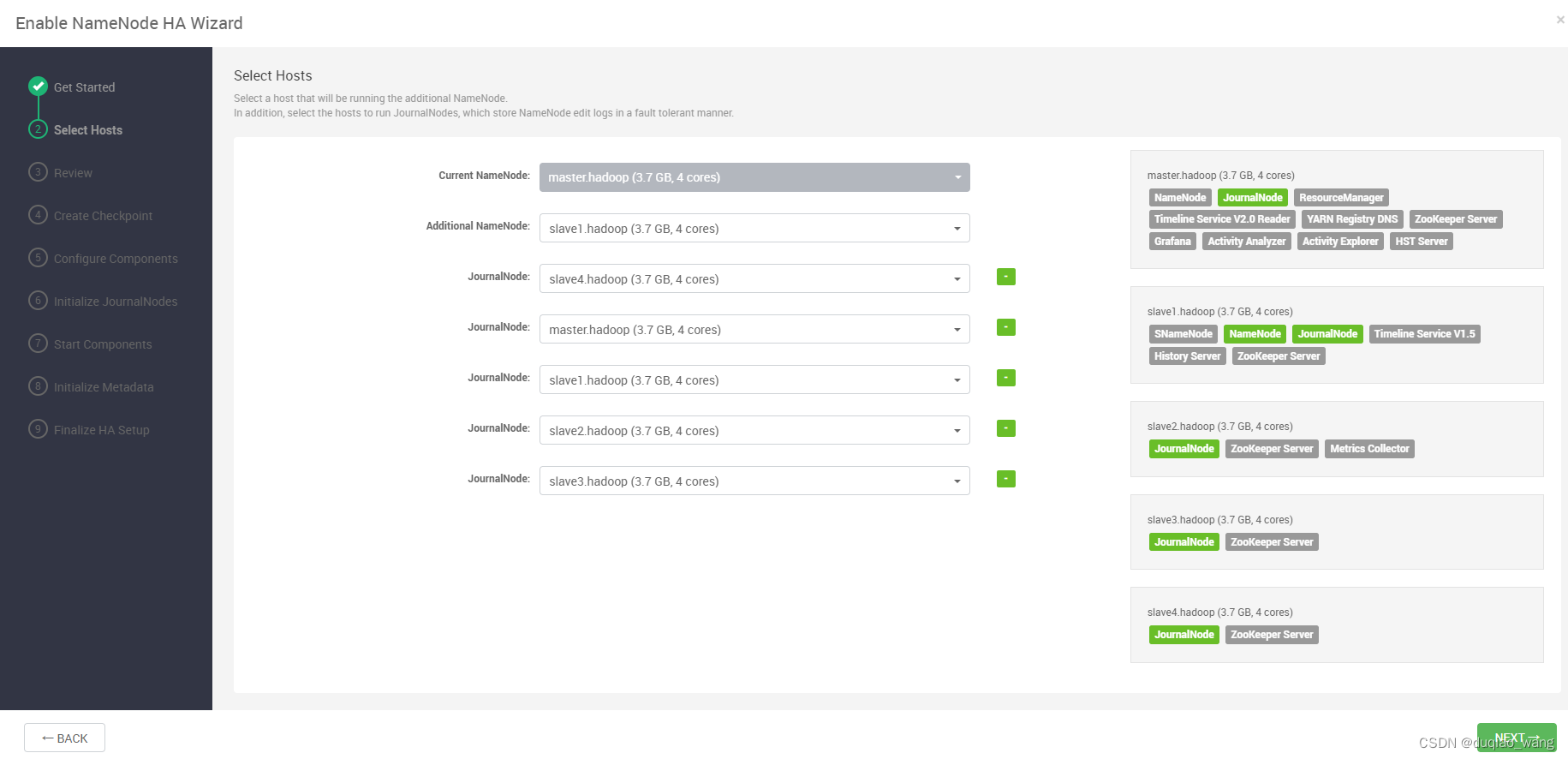
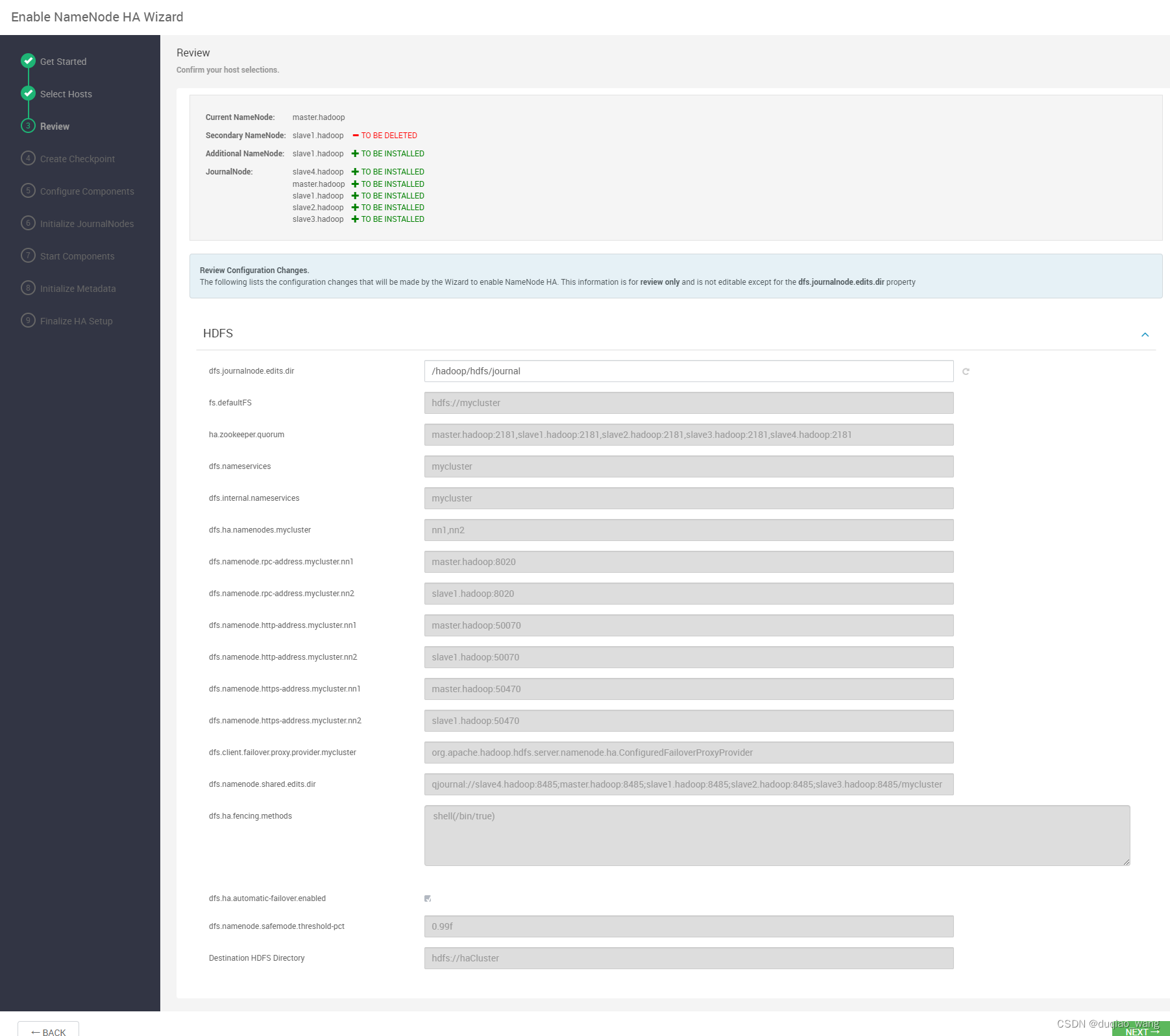
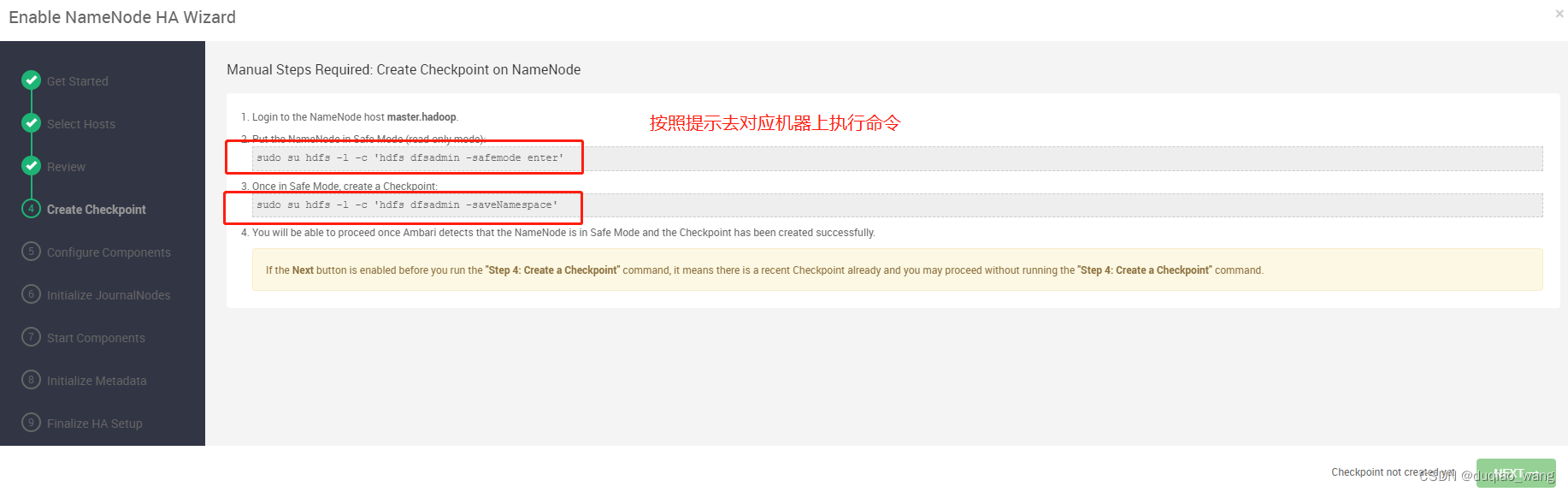
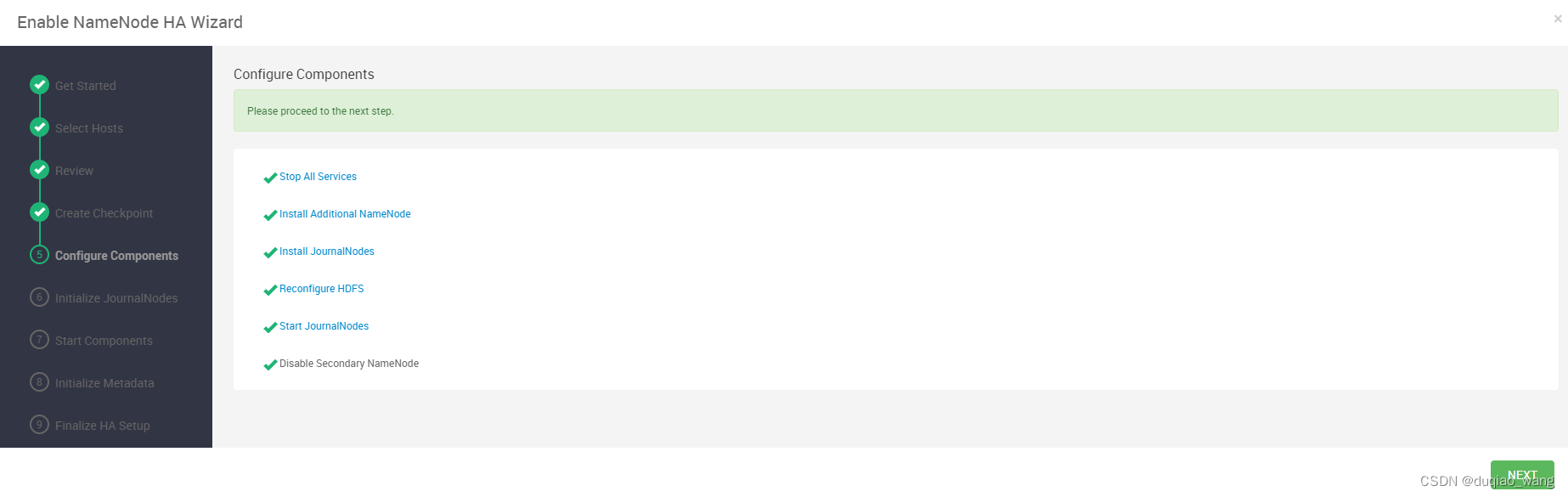
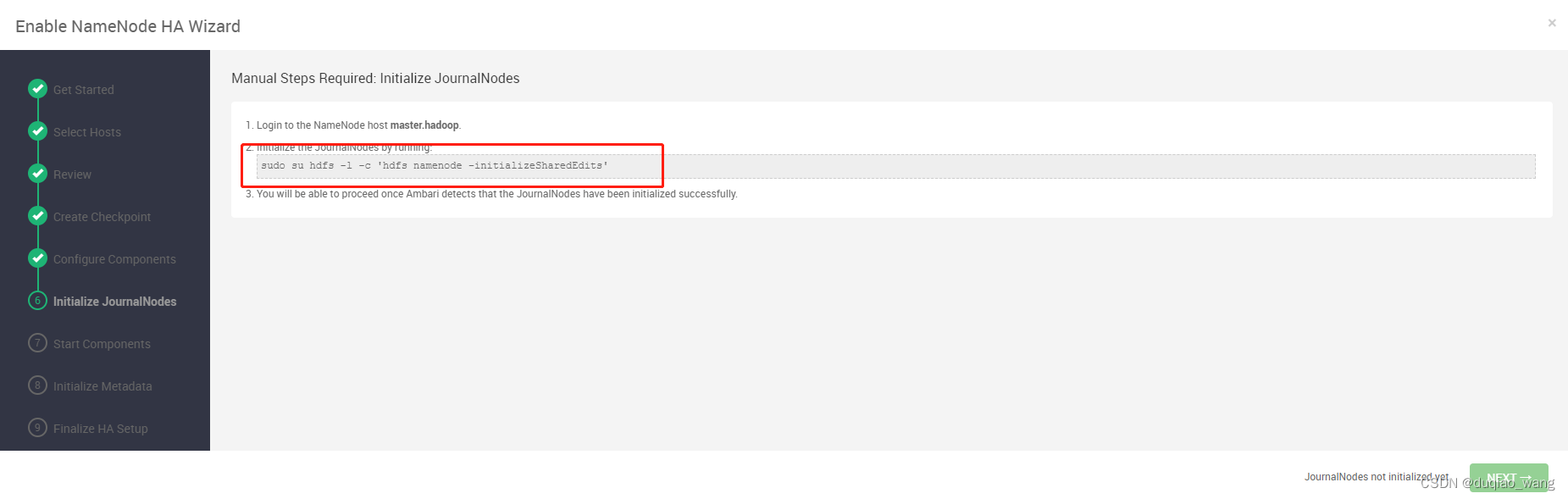
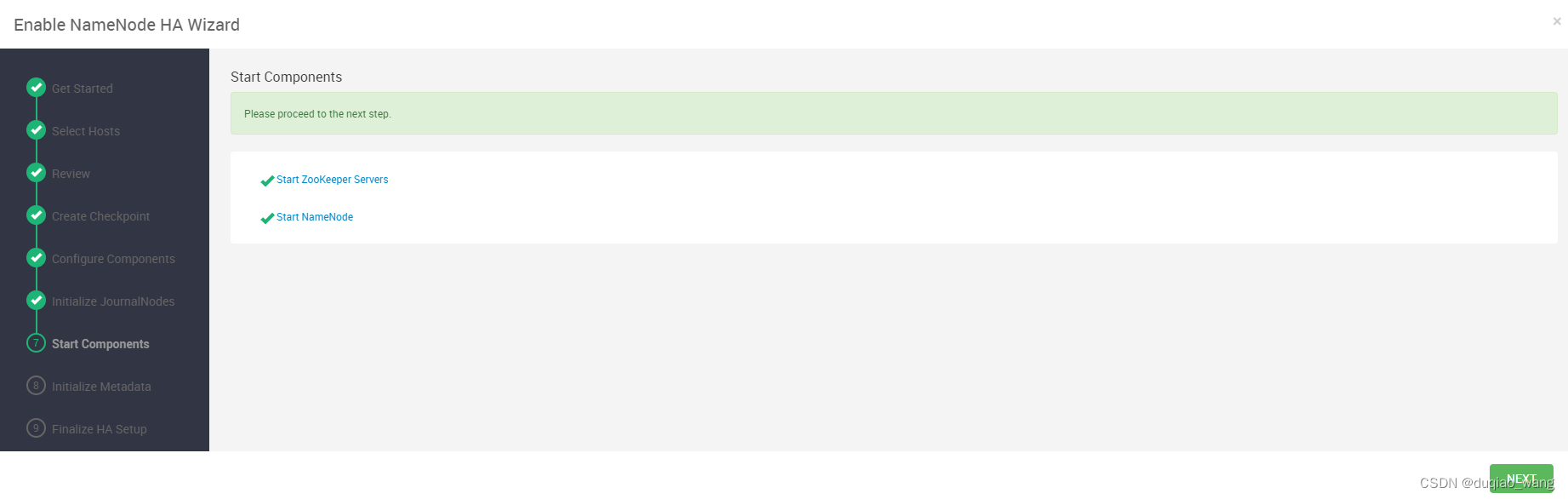
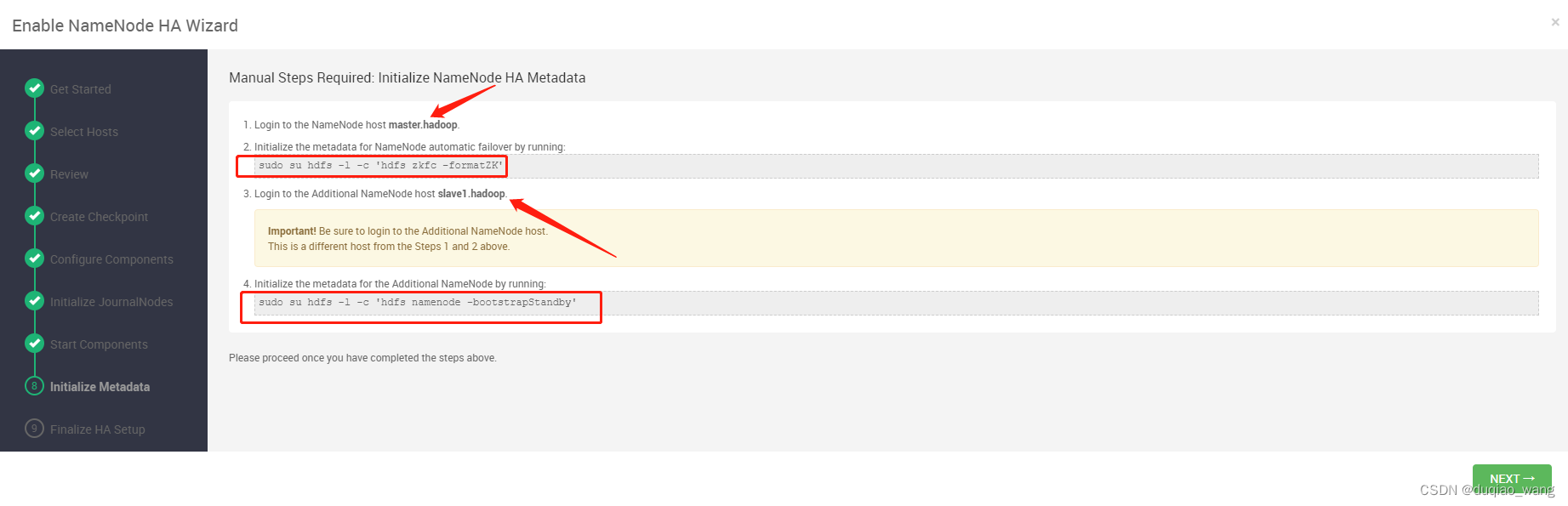
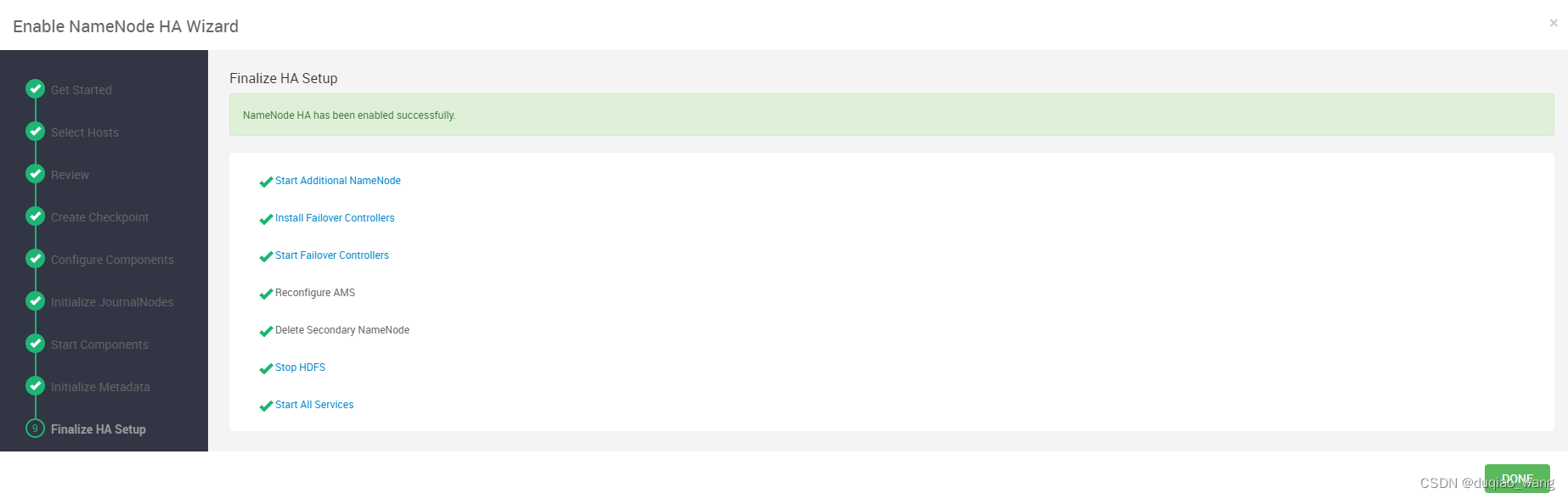
- c 配置NameNode HA高可用