本机运行代码
package com.example.hadoop.api.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
/**
* Text:指的是StringWritable
* (LongWritable , Text) map端的输入:这俩参数永远不变,Text:文本数据,LongWritable:偏移量(数据分割时的偏移量)
*
* (Text, IntWritable) map端的输出:根据需求一直处于变化中
*/
public static class MapTask extends Mapper<LongWritable,Text, Text, IntWritable>{
/**
* 每次读取一行数据,该方法就执行一次
* 样例数据
* hadoop,hadoop,spark,spark,spark,
* hive,hadoop,spark,spark,spark,
* spark,hadoop,hive,spark,spark,
* @param key 偏移量
* @param value 文本数据
* @param context 输出数据(hadoop,1) (spark,1)
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(",");
for (String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
/**
* reduce map的输出就是reduce的输入
*/
public static class ReduceTask extends Reducer<Text,IntWritable,Text,IntWritable>{
/**
* 每操作一次key,方法就执行一遍
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0 ;
for(IntWritable value:values){
count++;
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//本地测试模式,job对象提交任务
Job job = Job.getInstance();
//提交我们的俩内部类
job.setMapperClass(MapTask.class);
job.setReducerClass(ReduceTask.class);
//提交输出参数的类型,注意只要输出参数类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("mr/wordcount.txt"));
FileOutputFormat.setOutputPath(job,new Path("mr/outwordCount"));
Boolean b = job.waitForCompletion(true);
System.out.println(b?"成功":"失败请找bug");
}
}
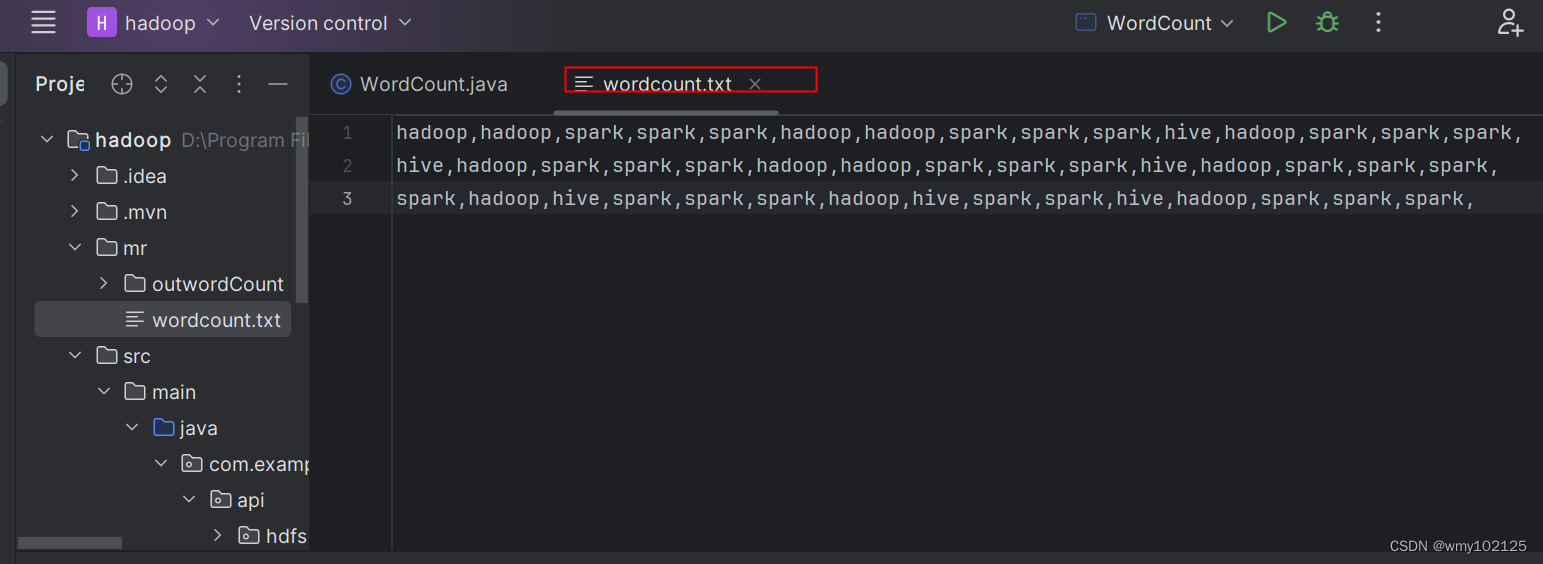
本机idea运行后发现报错
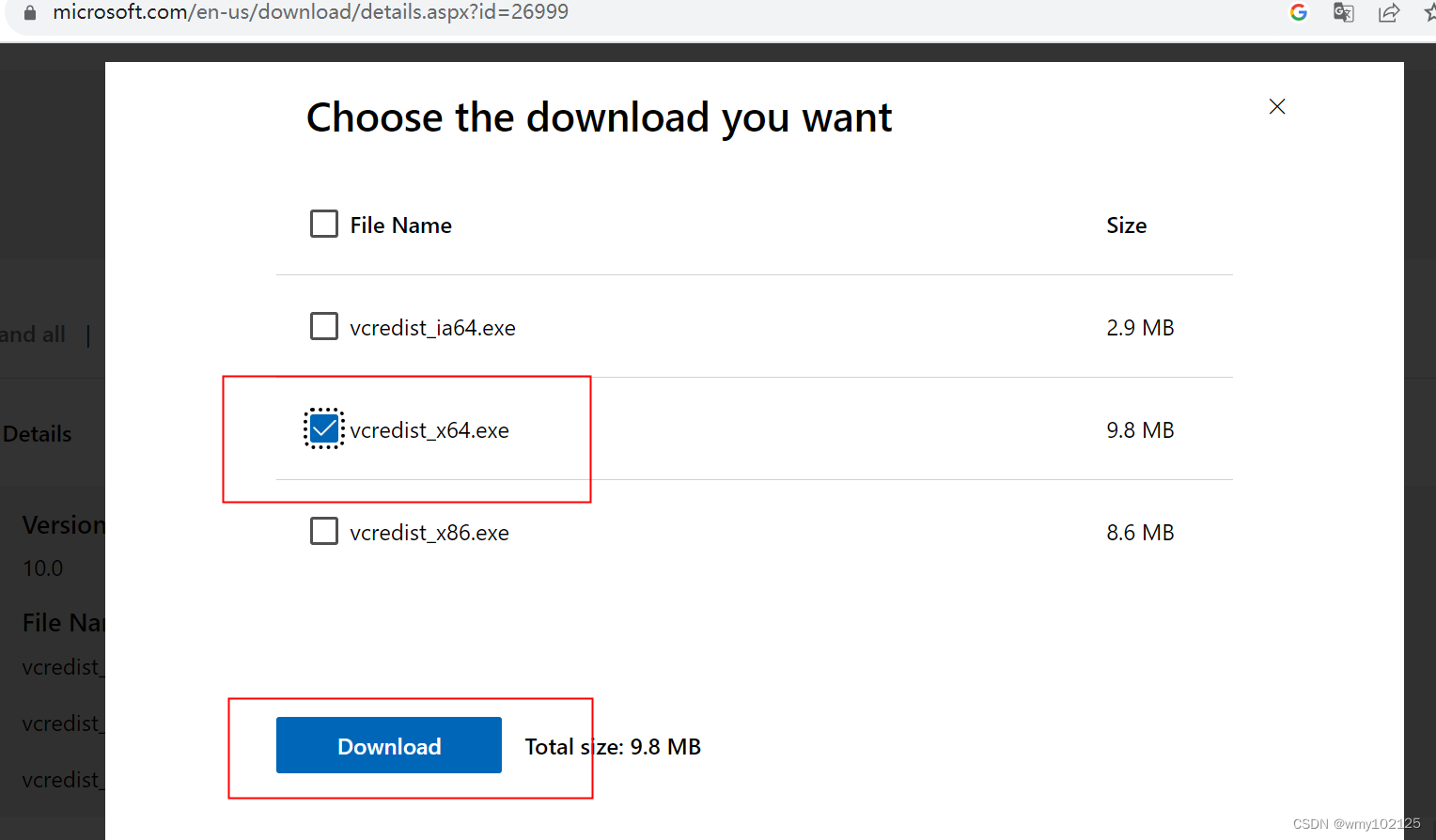
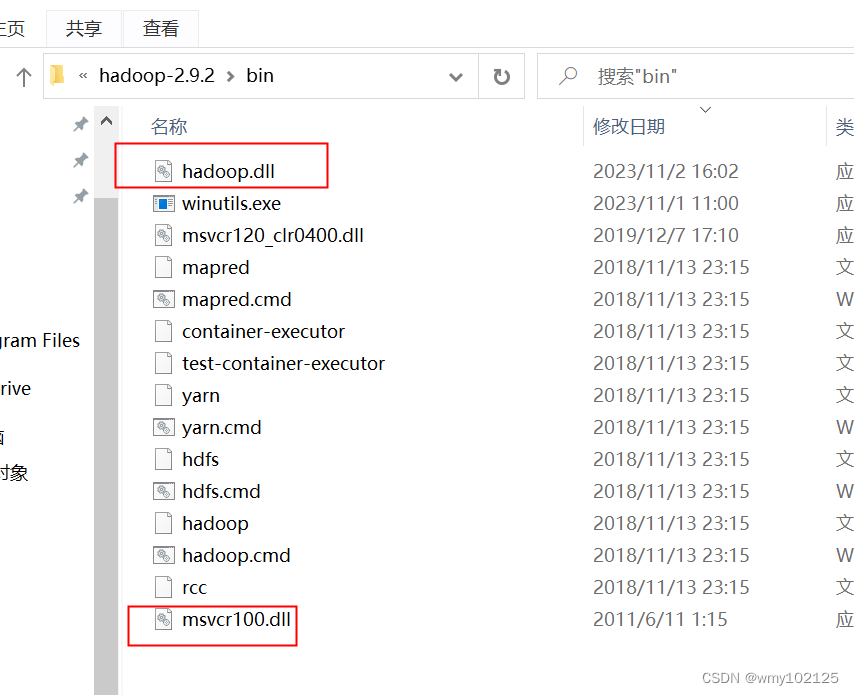
点击本机D:\hadoop-2.9.2\bin目录下winutils.exe报错msvcr100.dll找不到,说明缺少C++的运行环境,msvcr100.dll对应的是2010C++的运行环境,我的电脑是X64的,选择自己电脑的版本下载后直接安装即可
https://www.microsoft.com/en-us/download/details.aspx?id=26999
安装完成,保险起见可以将C:\Windows\System32\msvcr100.dll复制一份到hadoop的安装目录bin下D:\hadoop-2.9.2\bin
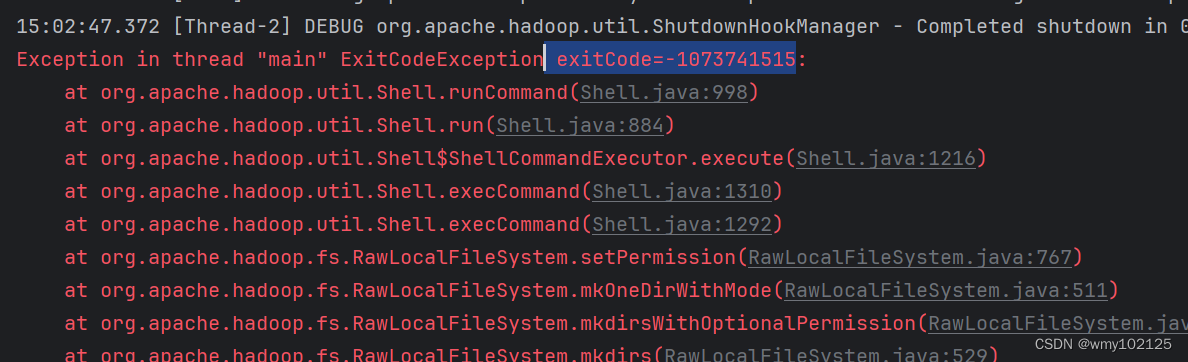
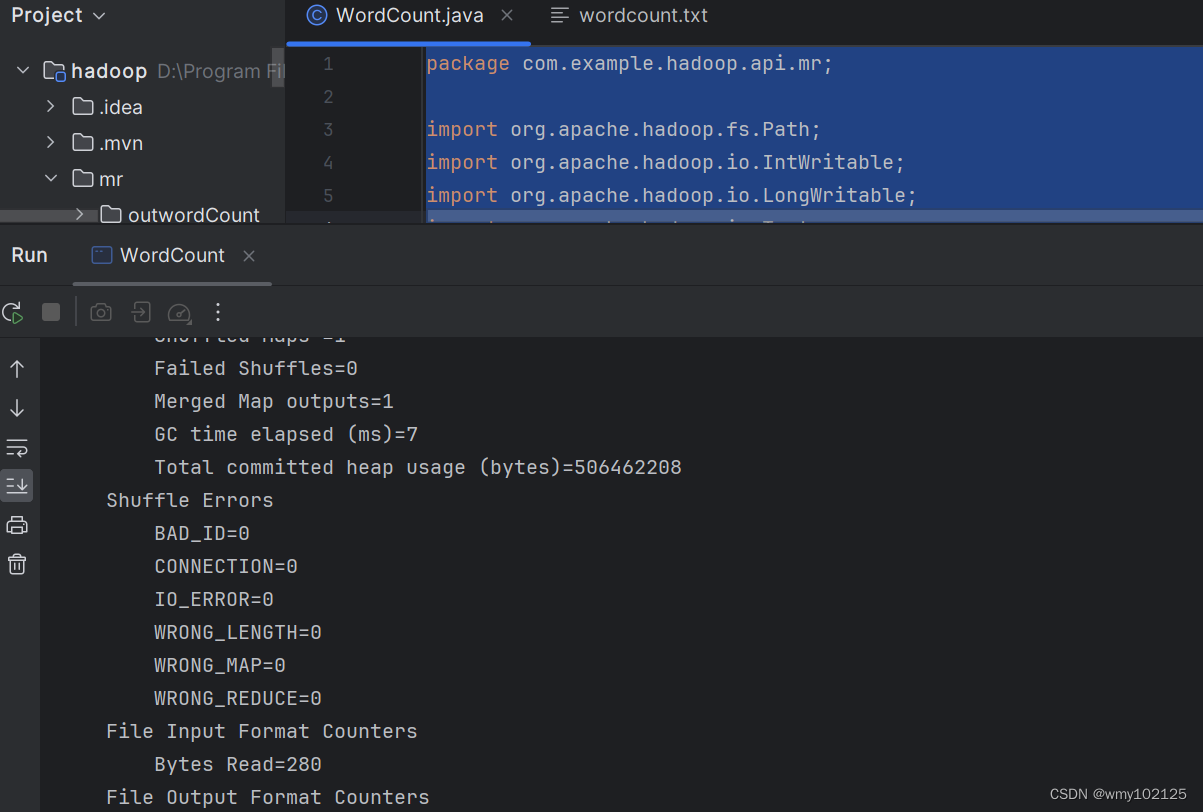
再次运行WordCount.java main方法,报错如下
现在又缺少hadoop.dll文件,所以单独下载下这个文件
https://github.com/steveloughran/winutils
选择一个和自己版本相近的,下载下来之后,copy到hadoop安装目录下
重启电脑,运行成功
运行后的统计结果


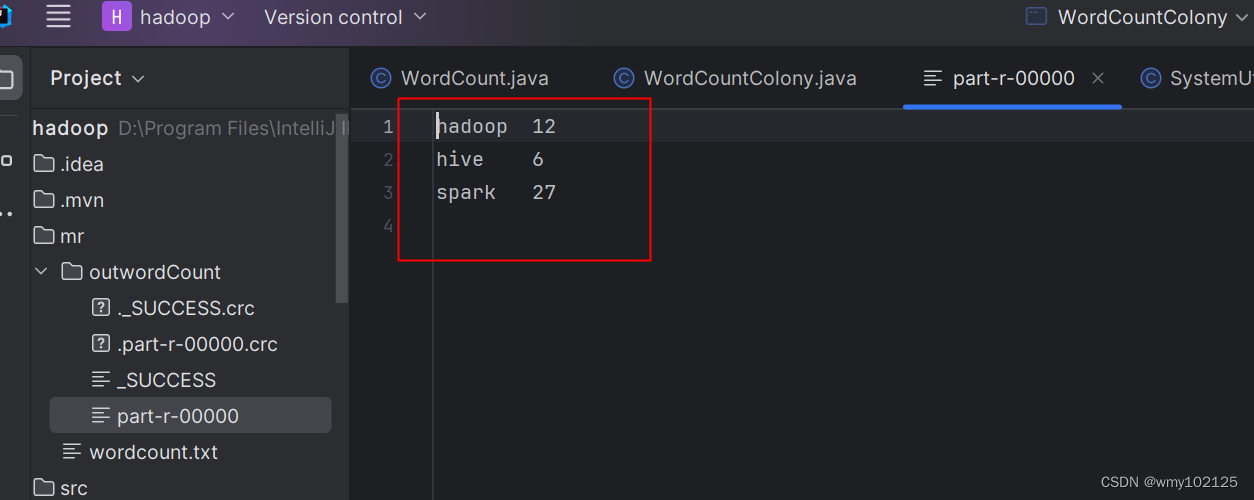
集群代码
package com.example.hadoop.api.mr;
import com.example.hadoop.util.SystemUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
/**
* @author wangmeiyan
* @Date 2023/11/02 17:10:00
* 集群mapReduce
*/
public class WordCountColony {
/**
* Text:指的是StringWritable
* (LongWritable , Text) map端的输入:这俩参数永远不变,Text:文本数据,LongWritable:偏移量(数据分割时的偏移量)
*
* (Text, IntWritable) map端的输出:根据需求一直处于变化中
*/
public static class MapTask extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* 每次读取一行数据,该方法就执行一次
* 样例数据
* hadoop,hadoop,spark,spark,spark,
* hive,hadoop,spark,spark,spark,
* spark,hadoop,hive,spark,spark,
*
* @param key 偏移量
* @param value 文本数据
* @param context 输出数据(hadoop,1) (spark,1)
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(",");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
/**
* reduce map的输出就是reduce的输入
*/
public static class ReduceTask extends Reducer<Text,IntWritable,Text,IntWritable> {
/**
* 每操作一次key,方法就执行一遍
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0 ;
for(IntWritable value:values){
count++;
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//集群测试模式,job对象提交任务
Configuration configuration = new Configuration();
String hdfsUrl = SystemUtil.getProperties().getProperty("spring.hdfs.url");
configuration.set("fs.defaultFS",hdfsUrl);
Job job = Job.getInstance(configuration);
//提交我们的俩内部类
job.setMapperClass(WordCount.MapTask.class);
job.setReducerClass(WordCount.ReduceTask.class);
//提交输出参数的类型,注意只要输出参数类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(SystemUtil.getProperties().getProperty("spring.hdfs.input")));
//如果文件已经存在就删除
Path output = new Path(SystemUtil.getProperties().getProperty("spring.hdfs.output"));
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(output)){
fileSystem.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
Boolean b = job.waitForCompletion(true);
System.out.println(b?"成功":"失败请找bug");
}
}
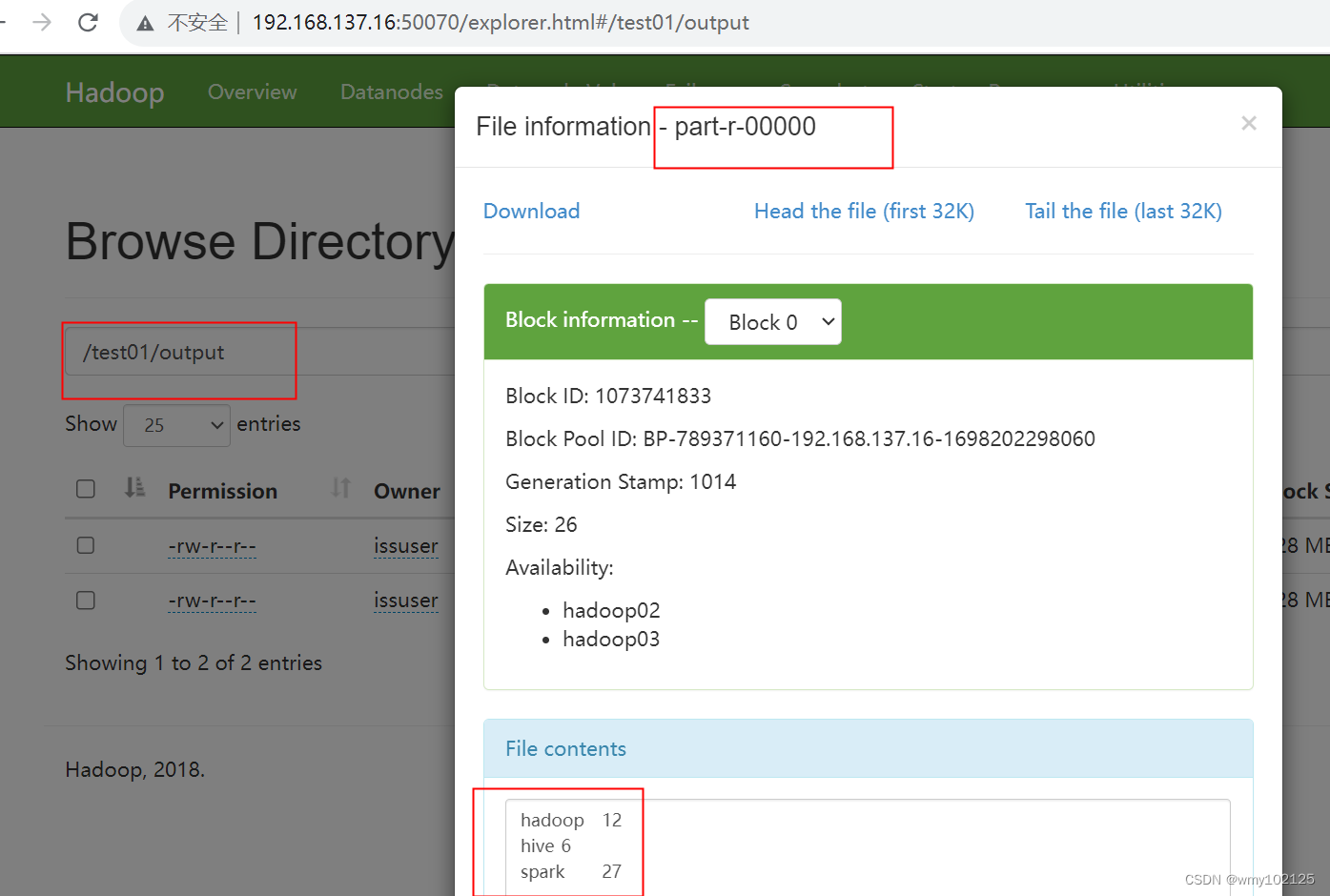
hadoop页面上准备好目录和待统计的文件
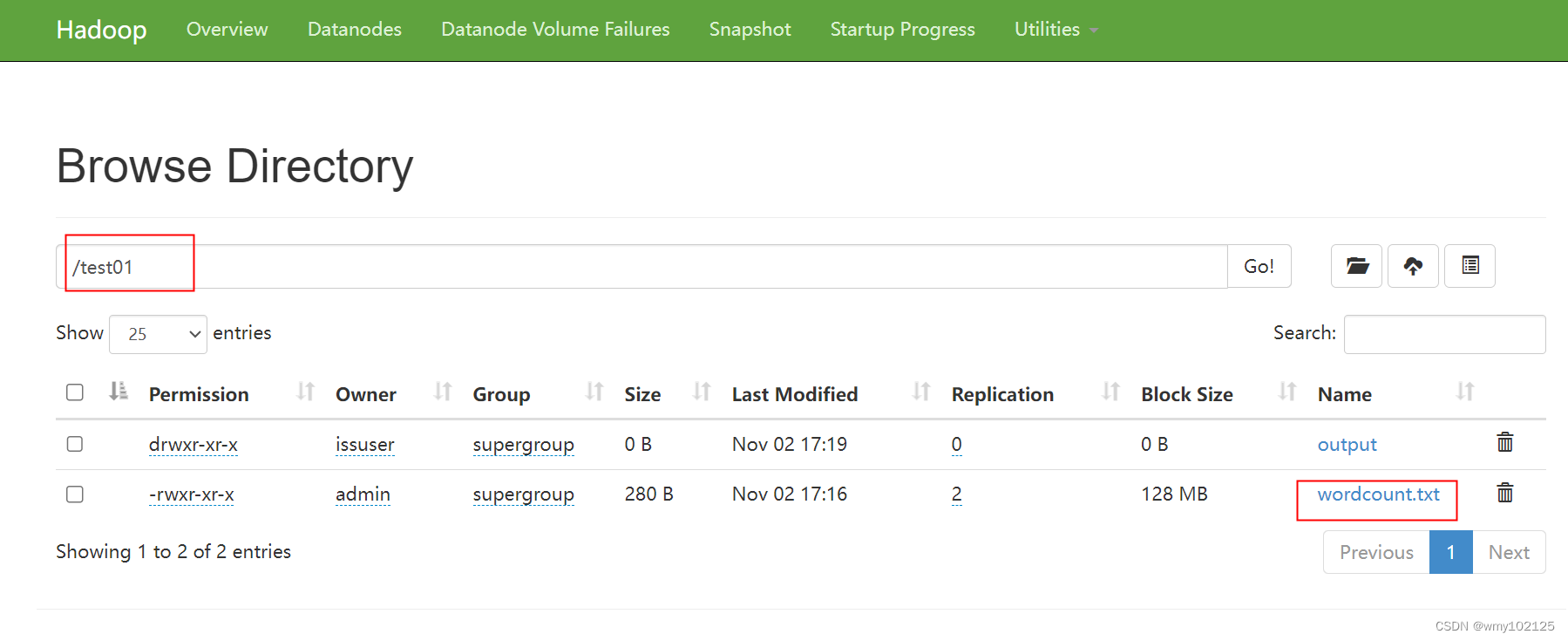
直接运行代码,查看统计结果