目录
1、为什么需要将Process Explorer/Process Hacker与Windbg结合起来分析高CPU占用问题?
1.1、使用Windbg分析时为什么还要使用Process Explorer/Process Hacker呢?
1.2、使用Process Explorer/Process Hacker分析时为什么还要使用Windbg呢?
2、先用Process Explorer/Process Hacker找到占用高CPU的线程id,然后到Windbg中找到对应的线程
2.1、在Process Explorer/Process Hacker找到占用高CPU的线程
2.2、到Windbg中找到高CPU占用的线程,切换到该线程中
3、分析占用高CPU线程的代码
3.1、找到pdb文件,查看详细的函数调用堆栈
3.2、分析占用高CPU线程的代码
4、在Windbg中查看变量的值,定位线程中发生死循环的原因
4.1、进一步分析代码
4.2、在Windbg中查看m_DataList列表中的元素,找出了引发问题的原因
5、最后
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html开源组件及数据库技术(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/category_11931267.html开源组件及数据库技术(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_12458859.html 本文还是以最近项目中遇到的那个问题实例为例,详细来讲述如何使用Windbg去排查线程中发生死循环的问题。
https://blog.csdn.net/chenlycly/category_12458859.html 本文还是以最近项目中遇到的那个问题实例为例,详细来讲述如何使用Windbg去排查线程中发生死循环的问题。
1、为什么需要将Process Explorer/Process Hacker与Windbg结合起来分析高CPU占用问题?
通过上一篇文章《使用Process Explorer/Process Hacker和Windbg初步定位软件高CPU占用问题》比较得知,在分析高CPU占用问题时,使用Process Hacker查看线程的函数调用堆栈时多次Refresh堆栈都能正常显示,而Process Explorer在多次Refresh时显示的堆栈会不太准确,所以后面需要去查看线程的函数调用堆栈时建议使用Process Hacker。在分析Process Explorer/Process Hacker工具分析程序高CPU占用问题时,可能还需要使用Windbg调试器。
1.1、使用Windbg分析时为什么还要使用Process Explorer/Process Hacker呢?
在Windbg中我们可以使用!runaway命令查看各个线程占用的CPU时间片时长统计,如下所示:
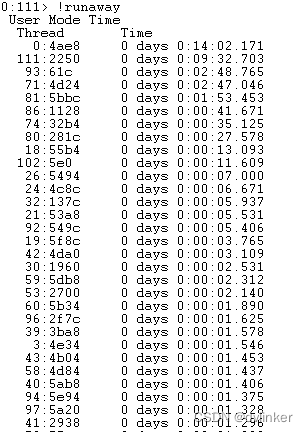
但占用CPU时间片多的线程不一定就是当前CPU占用高的线程,主要有以下几个原因:
1)程序一般都有个主线程,主线程一直在运行,占用的CPU时间片肯定很多,可能会排在首位;
2)当前高CPU占用的线程,可能是某个时刻才创建启动的,其占用的CPU时间片相对于其他很早就启动的线程,可能不是比较少。
所以,我们还要借助Process Explorer/Process Hacker查看当前占用高CPU的那个线程,然后通过线程id到Windbg中找到对应的线程号(数字编号),然后使用~ns命令切换到高CPU占用的线程(~ns命令中的n就是线程数字编号),然后就可以查看线程的函数调用堆栈,进行进一步分析了。
1.2、使用Process Explorer/Process Hacker分析时为什么还要使用Windbg呢?
我们使用Process Explorer/Process Hacker找到占用CPU高的线程,然后双击即可以查看该线程的函数调用堆栈,这两个工具也支持加载pdb符号库文件,在加载pdb文件后也可以在函数调用堆栈中显示具体的函数名(pdb文件放在exe主程序的目录中)。
但Process Explorer/Process Hacker仅仅是能看到函数调用堆栈,但有时我们需要查看相关变量的值去辅助分析线程的上下文代码,去排查CPU占用高的原因。变量的值可能是排查问题的关键线索。而在Windbg中不仅可以看到准确无误的、最精准的函数调用堆栈(在加载到系统库pdb文件时还能显示系统库内部的函数名),还能查看到函数调用堆栈中相关变量的值(比如函数中局部变量的值、相关C++类对象的成员变量的值等),如下所示:

因为当前问题是高CPU占用,没有发生异常崩溃,所以不会有dump文件生成。这就需要Windbg的动态调试了,即直接将Windbg附加到目标进程上和目标进程一起跑,在Windbg中中断一下(点击Windbg菜单栏中的Debug -> Break,Windbg就会中断下来),就可以使用kn命令查看中断时的函数调用堆栈了。
2、先用Process Explorer/Process Hacker找到占用高CPU的线程id,然后到Windbg中找到对应的线程
首先到Windows任务管理器中找到占用高CPU的程序,接着打开Process Explorer/Process Hacker工具找到目标程序,查看程序进程中占用高CPU的线程,然后将Windbg附加到目标程序进程上,跳转到占用高CPU的线程上,查看函数调用堆栈进行分析。
2.1、在Process Explorer/Process Hacker找到占用高CPU的线程
打开任务管理器看到目标程序占用了最高比例的CPU,如下所示:(此处注意一下,因为之前排查项目问题时没有截图,此处以演示程序的截图为例,不要与本案例中的项目问题对号入座)
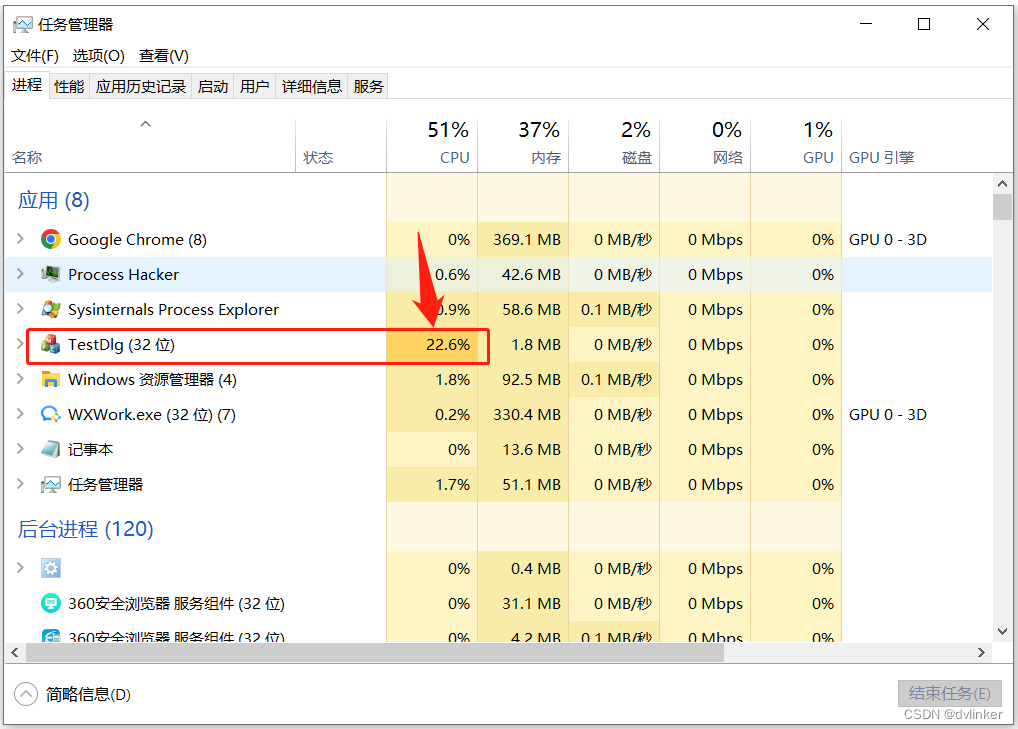
于是打开Process Explorer,找到目标程序进程,双击打开进程的属性页面,然后点击Treads标签(Tab)页,就能看到进程的线程列表页面,如下:(此处注意一下,因为之前排查项目问题时没有截图,此处以演示程序的截图为例,不要与本案例中的项目问题对号入座)
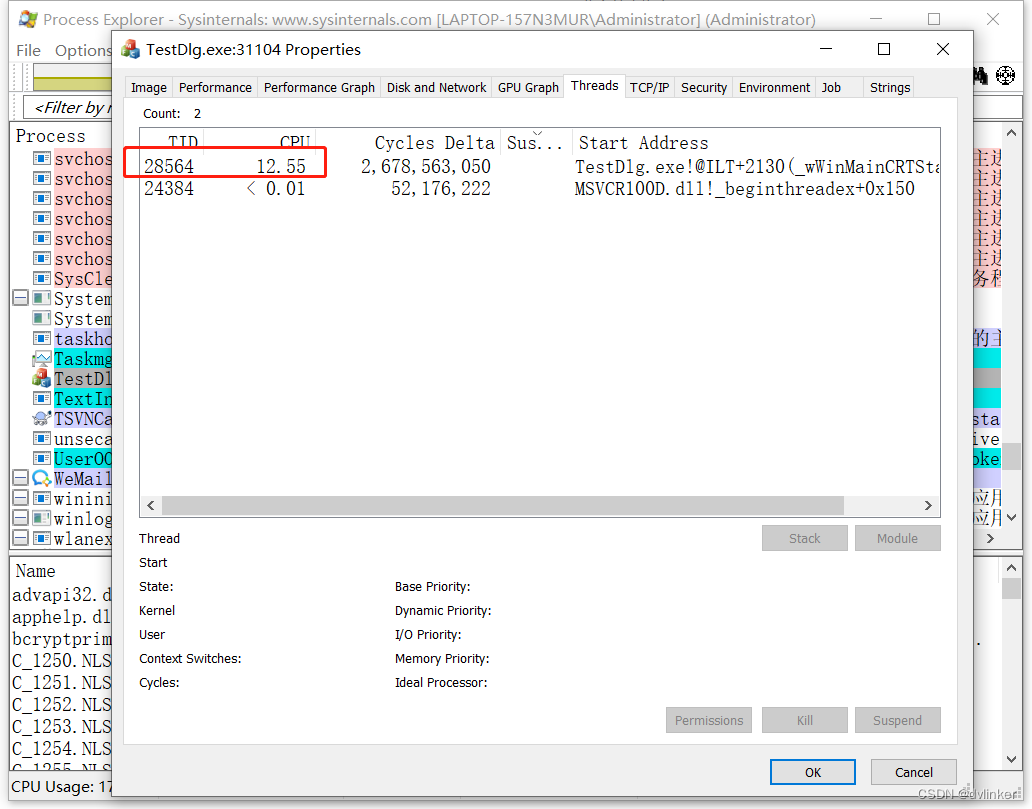
这样我们就可以就知道占用高CPU的线程id。
2.2、到Windbg中找到高CPU占用的线程,切换到该线程中
然后我们启动Windbg,将Windbg附加到目标程序进程上,然后输入!runaway命令将进程中所有线程占用的CPU时间片都打印出来,如下所示:(从此处开始的截图,都是项目中的真实截图,主要截取的是Windbg中的图)
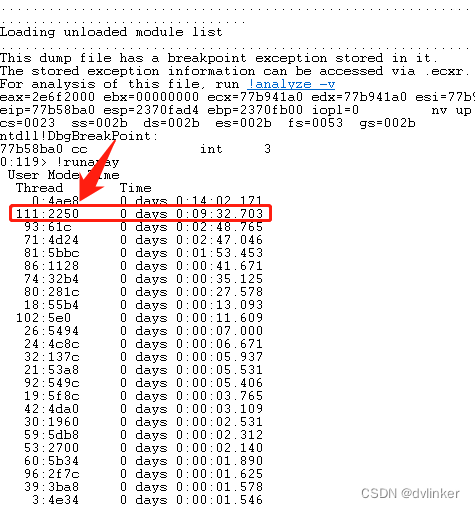
!runaway命令打印出来的是进程中所有线程的用户态CPU时间片时间统计,我们的业务代码主要运行在用户态,所以只要看用户态的统计即可。
由Process Explorer中显示的线程id,到图上中找到占用CPU高的线程:
111:2250 0 days 0:09:32.703
其中111是Windbg中的线程序号,2250就是线程id,注意该线程id是16进制的,而Process Explorer中显示的线程id是10进制的8784,把这个值拷贝到系统自带的计算器中:
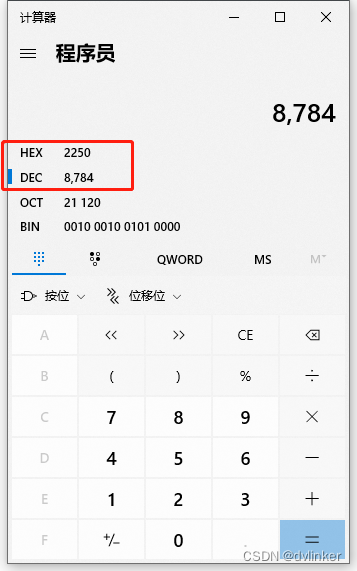
查看对应的16进制值为2250,然后到Windbg中找到对应的线程。
在Windbg中确定占用高CPU的线程后,就使用~115s命令(其中115就是Windbg中显示的线程序号,不是线程id)切换到目标线程中,然后使用kn命令就可以查看函数调用堆栈,进行后续分析了。
关于何时使用Windbg进行静态分析,何时使用Windbg进行动态调试,可以参见我之前写的文章:
何时使用Windbg静态分析?何时使用Windbg动态调试?![]() https://blog.csdn.net/chenlycly/article/details/131806819 关于使用Windbg静态分析dump文件的详细步骤,可以参见我之前写的文章:
https://blog.csdn.net/chenlycly/article/details/131806819 关于使用Windbg静态分析dump文件的详细步骤,可以参见我之前写的文章:
使用Windbg静态分析dump文件的一般步骤及要点详解![]() https://blog.csdn.net/chenlycly/article/details/130873143 关于使用Windbg进行动态调试的详细步骤,可以参见我之前写的文章:
https://blog.csdn.net/chenlycly/article/details/130873143 关于使用Windbg进行动态调试的详细步骤,可以参见我之前写的文章:
使用Windbg动态调试目标进程的一般步骤及要点详解![]() https://blog.csdn.net/chenlycly/article/details/131029795
https://blog.csdn.net/chenlycly/article/details/131029795
3、分析占用高CPU线程的代码
因为需要将Windbg中的函数调用堆栈对照C++源码分析,一时半会分析不出来,所以不能一直占用同事的电脑,于是在动态调试的Windbg中使用命令:
.dump /ma D:\1230.dmp
手动导出当前进程的全dump文件。全dump文件保存了进程中的所有内存信息,可以查看到所有变量的值。之前我们讲过生成dump文件的三种方法,以及minidump和全dump文件的区别,可以参见我之前写的文章:
dump文件类型与dump文件生成方法详解![]() https://blog.csdn.net/chenlycly/article/details/127991002
https://blog.csdn.net/chenlycly/article/details/127991002
3.1、找到pdb文件,查看详细的函数调用堆栈
取来dump文件用Windbg打开,使用~111s命令切换到目标线程中,然后输入kn命令查看函数调用堆栈:
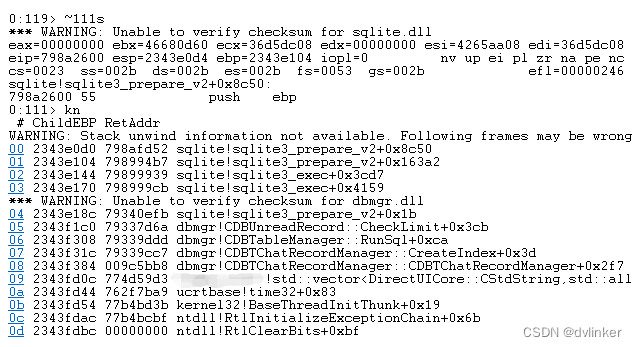
因为没有加载pdb符号库文件,堆栈中看不到具体的函数名,分析问题很不方便。为了查看函数调用堆栈中的具体的函数名以及后续要查看变量的值(需要用到pdb符号文件中的变量符号才能识别),我们需要查看一下相关exe和dll模块的时间戳,去找对应的pdb文件。
根据堆栈中涉及到的模块名称,使用lm vm 模块名*命令查看模块的生成时间戳,如下所示:
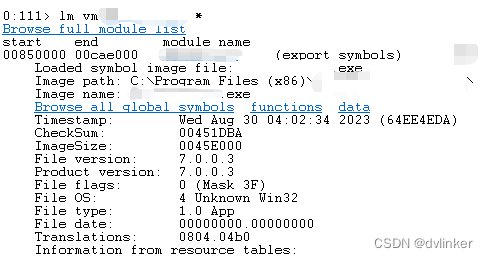
根据模块的生成时间,到文件服务器上找到对应时间点的pdb文件,然后将pdb文件拷贝到本机上来,然后将pdb路径设置到Windbg中,然后使用~111s切换到目标线程中,使用kn命令就可以查看到详细的函数调用堆栈了,如下所示:
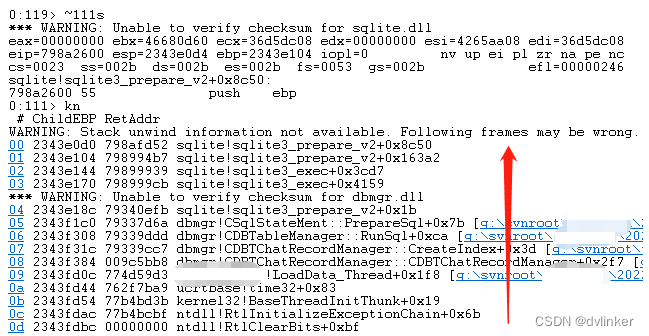
这样在函数调用堆栈中可以看到具体的函数名和行号了,就方便分析了。至于如何将pdb路径设置到Windbg中,我们之前已经多次讲过,此处就不再赘述了。关于pdb符号库文件的说明,以及如何在Windbg中设置pdb文件的路径,请查看我之前写的文章:
pdb符号文件详解![]() https://blog.csdn.net/chenlycly/article/details/125508858 此外,此处的pdb文件从何而来呢?我们有一套自动化代码编译系统(主要通过脚本去控制),如果项目代码有修改,会在第二天凌晨(比如凌晨2点)自动编译代码并生成二进制文件和安装包,然后通过脚本会将编译生成的二进制文件、对应的pdb文件以及安装包,拷贝到文件服务器上保存下来,不同时间点用不同的文件夹命名,如下所示:
https://blog.csdn.net/chenlycly/article/details/125508858 此外,此处的pdb文件从何而来呢?我们有一套自动化代码编译系统(主要通过脚本去控制),如果项目代码有修改,会在第二天凌晨(比如凌晨2点)自动编译代码并生成二进制文件和安装包,然后通过脚本会将编译生成的二进制文件、对应的pdb文件以及安装包,拷贝到文件服务器上保存下来,不同时间点用不同的文件夹命名,如下所示:
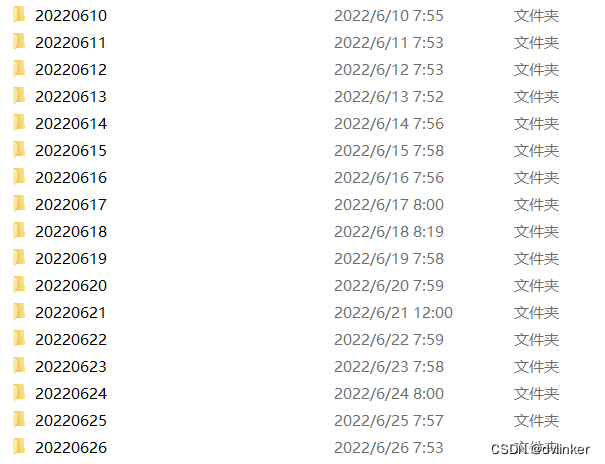
这样我们事后在需要的时候,就可以到文件服务器上找到对应时间点的pdb文件了。以前我们讲的历史版本比对法,也是依赖这种自动化编译系统,每天都会自动编译版本,生成安装包,这样可以使用二分法安装不同时间点的版本去比较了。如果没有这样的自动化编译系统,历史版本比对法颗粒度会比较粗(时间跨度比较大),就很难精准的定位问题了。
3.2、分析占用高CPU线程的代码
根据Windbg中显示的详细函数调用堆栈,到C++源码中找到对应的线程代码处,如下所示:
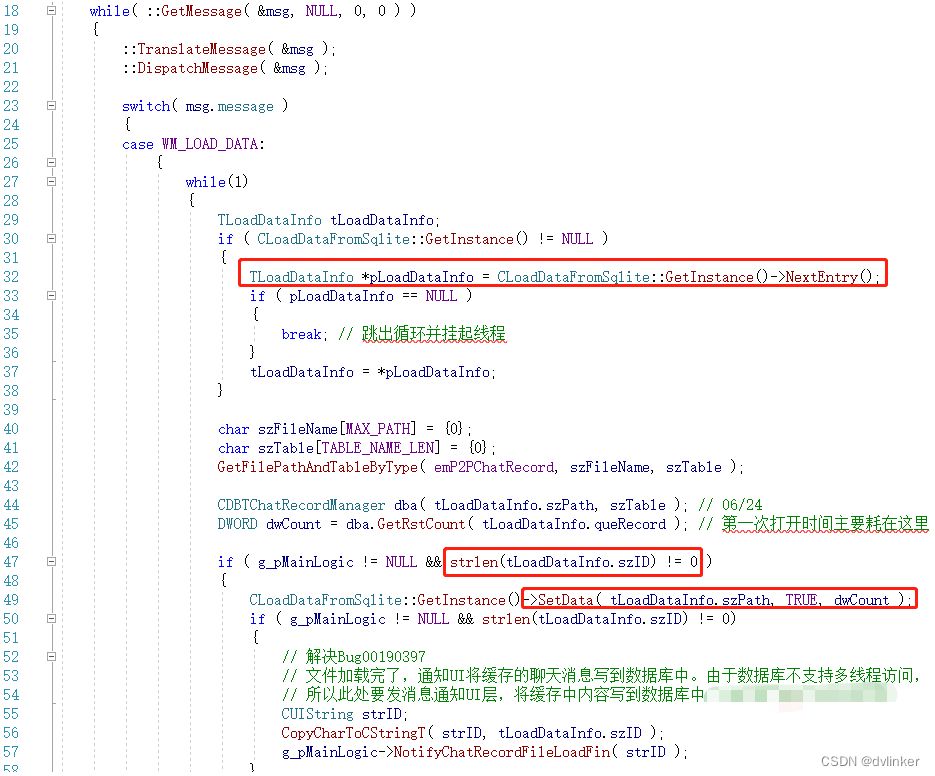
在这段代码中,有个while循环,大概率是这个循环中发生死循环了!这是别的同事好几年前写的代码,同时已经离职,将相关代码上下文读了几遍才大概搞清楚这块代码的意图。我们暂且不要去看这段代码的是否严谨以及代码指令,我们一起去看看问题可能是出在哪里了。
这段代码中调用CLoadDataFromSqlite::GetInstance()->NextEntry接口去遍历CLoadDataFromSqlite类中的列表:
std::deque<TLoadDataInfo*> m_DataList;
这个While循环就是为了遍历这个列表,当遍历完这个列表后,CLoadDataFromSqlite::GetInstance()->NextEntry接口就会返回NULL,这样就会退出While循环了。看了代码上下文,可能是这个CLoadDataFromSqlite::GetInstance()->NextEntry接口及上下文写的有问题,可能接口始终不返回NULL,导致While出现了死循环。于是进一步分析这块代码的上下文。
于是查看CLoadDataFromSqlite::GetInstance()->NextEntry接口的实现源码:

这个接口中会根据数据库文件对象的优先级,多次调用依次返回还没有加载的数据库文件对象。
回到线程主代码处,会去加载读CLoadDataFromSqlite::GetInstance()->NextEntry接口返回的数据库文件对象,读完后会调用CLoadDataFromSqlite::GetInstance()->SetData接口将数据库文件对象设置为已加载。但调用CLoadDataFromSqlite::GetInstance()->SetData接口的条件是tLoadDataInfo.szID字段不为空,难道存放数据库文件信息的列表CLoadDataFromSqlite::m_DataList中有的数据库文件对象信息中的szID为空?导致多次调用CLoadDataFromSqlite::GetInstance()->NextEntry接口返回的是同一个对象,造成了死循环?
当前是用Windbg事后分析dump文件,并是在动态调试,如果是动态调试,可以直接在Windbg中使用bp命令设置断点,进行断点调试去验证这个假设。
这个地方需要强调一点,线程主体框架代码中的循环,会一直运行,看上去像是“死循环”,但与代码片的循环(短暂的循环)中因为代码有缺陷导致的死循环,是完全不同的概念,处置方式也不同的。不能让线程函数中的主体循环一直不停歇的运行,否则会导致高CPU占用,需要添加Sleep去解决。对于代码片中的循环遍历时发生的死循环,是代码的bug,不能使用Sleep去规避,应该查出引发死循环的根本原因并加以解决。
4、在Windbg中查看变量的值,定位线程中发生死循环的原因
4.1、进一步分析代码
调用CLoadDataFromSqlite::GetInstance()->SetData接口将CLoadDataFromSqlite::m_DataList列表中对应的数据库文件设置为已加载,循环调用CLoadDataFromSqlite::GetInstance()->NextEntry接口返回的是CLoadDataFromSqlite::m_DataList列表中未加载的数据库文件对象,如果列表中的数据库文件都加载过了,则CLoadDataFromSqlite::GetInstance()->NextEntry接口会返回为空,就会执行break操作,退出当前的while循环,就不会有死循环。而调用CLoadDataFromSqlite::GetInstance()->SetData接口的条件是tLoadDataInfo.szID字段不为空,难道存放数据库文件的CLoadDataFromSqlite::m_DataList列表中有元素的szID字段为空,导致对应的数据库对象元素始终是未加载状态,导致调用CLoadDataFromSqlite::GetInstance()->NextEntry接口返回的始终是同一个元素,导致始终跳不出while循环,进而产生了死循环。
由于无法确定问题,最开始想添加打印,在代码上下文的怀疑点中添加打印日志,尝试通过打印去分析一下。但这个问题不是必现的,运行添加打印的版本可能就复现不了了,而且该问题是出在大领导的PC上,也不好让领导帮忙复现,还是要基于现有信息想办法,尽量定位问题。
我们当前使用的dump文件是从动态调试的Windbg中使用命令导出的,是全dump文件,可以查看到所有变量在内存中的值,既然我们怀疑CLoadDataFromSqlite::m_DataList列表中的元素有问题,那能不能尝试在Windbg中查看该列表中的元素值呢?
4.2、在Windbg中查看m_DataList列表中的元素,找出了引发问题的原因
之前我们多次讲过,在Windbg中可以查看函数调用堆栈中的函数中的变量值(可以查看函数中局部变量的值,也可以查看相关类对象中成员变量的值),有时这些变量值可能是分析问题的关键线索。之前写过几篇实际项目问题的排查案例,可以参看:
通过查看Windbg中变量值去定位C++软件异常问题![]() https://blog.csdn.net/chenlycly/article/details/125731044通过查看Windbg中变量值去定位C++软件异常的又一典型案例分享
https://blog.csdn.net/chenlycly/article/details/125731044通过查看Windbg中变量值去定位C++软件异常的又一典型案例分享![]() https://blog.csdn.net/chenlycly/article/details/125793532 对于当前的这个问题,这个CLoadDataFromSqlite::m_DataList列表不是函数调用堆栈中某个函数的局部变量,也不是函数所在类对象的成员变量,而是一个单实例类CLoadDataFromSqlite的成员变量,即CLoadDataFromSqlite单实例对象的成员变量,这个CLoadDataFromSqlite单实例对象是静态变量,类似于全局变量,我们该如何在Windbg中查看CLoadDataFromSqlite::m_DataList这个列表的内存呢?
https://blog.csdn.net/chenlycly/article/details/125793532 对于当前的这个问题,这个CLoadDataFromSqlite::m_DataList列表不是函数调用堆栈中某个函数的局部变量,也不是函数所在类对象的成员变量,而是一个单实例类CLoadDataFromSqlite的成员变量,即CLoadDataFromSqlite单实例对象的成员变量,这个CLoadDataFromSqlite单实例对象是静态变量,类似于全局变量,我们该如何在Windbg中查看CLoadDataFromSqlite::m_DataList这个列表的内存呢?
Windbg中有个x命令,可以搜索按变量符号搜索到变量的内存信息,于是尝试使用如下的命令:
x xxxxdll!CLoadDataFromSqlite::m_DataList
在该命令中xxxxdll是变量所在的模块名,是不带后缀名的。结果这个命令搜不到任何内容,CLoadDataFromSqlite::m_DataList是依附在单实例对象CLoadDataFromSqlite::s_pInstance中的,它不是独立存在的,应该要通过对象去查找,于是尝试:
x xxxxdll!CLoadDataFromSqlite::s_pInstance
果然找到了,如下所示:
![]()
显示的是CLoadDataFromSqlite::s_pInstance静态变量的首地址,点击超链接即可展开该对象的内存分布,如下所示:
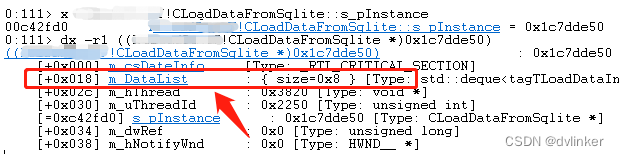
可以看到我们想看的m_DataList列表,点击其超链,就能展开该列表,然后点击序号,就能依次查看列表中的每个元素了:
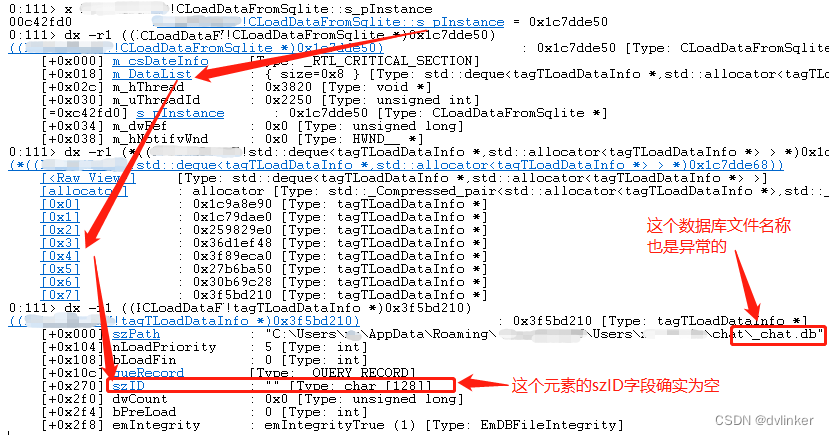
果然看到最后一个数据库文件元素的szID字段是空的,并且数据库文件名称也是有问题的。应该是相关代码的逻辑有问题,向m_DataList列表中加入了一个无效元素,导致了线程发生了死循环。
后面针对上述问题,详细查看了代码的上下文,将问题解决掉了。正是在Windbg中查看相关变量的值,帮我们快速找到引发问题的原因,有效地提高了排查问题的效率。
5、最后
在本问题案例中,先是使用Process Explorer或者Process Hacker找到占用高CPU的线程,通过线程id到Windbg中找到对应的线程,然后切换到对应的线程中查看函数调用堆栈。然后根据函数调用堆栈去分析C++源码,最后通过在Windbg中查看相关变量的值找出引发问题的原因。这个问题排查难度并不大,但很有代表性,主要是给大家提供排查问题的思路和方法,有一定的参考价值,希望能给大家提供一定的借鉴或参考!