论文:https://arxiv.org/abs/1904.02689
代码:https://github.com/dbolya/yolact
0、摘要
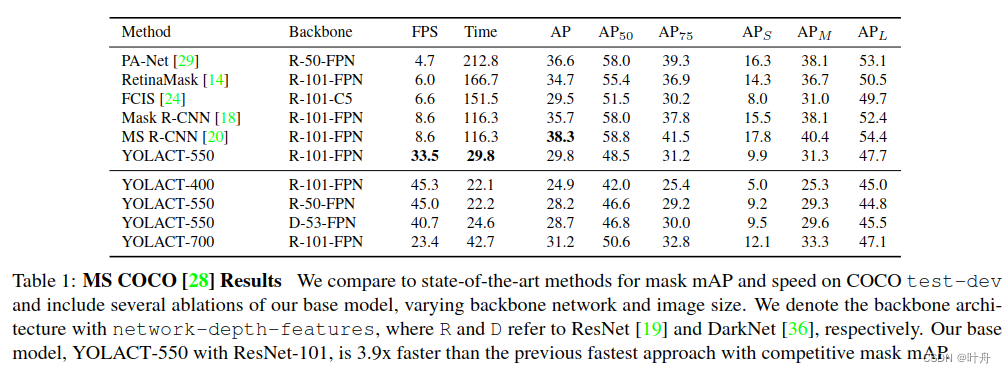
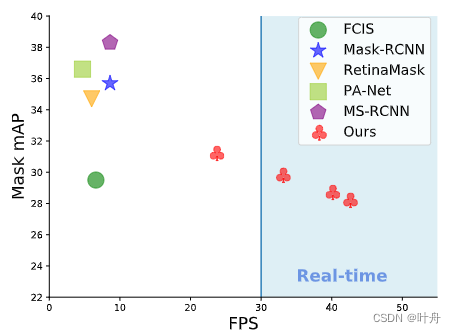
提出了一个简单、全卷积的实时实例分割模型,在COCO上实现29.8的mAP,在单张Titan XP显卡上实现33.5FPS,这速度显著超越了此前的所有SOTA。此外,只需一张显卡即可训练达到这种效果。作者将实例分割分为两个并行的子任务:一个分支生成一系列原型mask,也即prototype;另一个分支做目标检测同时对每个实例预测mask系数。如此,就可以利用prototype和mask系数信息,通过线性组合生成实例mask。这个过程不依赖于repooling,所以可以生成高质量mask,且表现出无消耗的时间稳定性。进一步的,作者还发现尽管使用的是全卷积,但prototype仍能够以平移不变的方式学习到实例的定位信息。最后,还提出了 Fast NMS,它是标准 NMS 的快速版,仅具有边际性能损失。
1、动机
"Boxes are stupid anyway though, I'm probably a true believer in masks except I can't get YOLO to learn them." —— Joseph Redmon, YOLOv3
可以看出,YOLACT是替Joseph Redmon圆梦的【此处应该有个狗头】~
言归正传,此前的流行实例分割都是在目标检测的基础上增加mask分支,如Mask-RCNN、FCIS,他们主要关注性能而非速度。于是,为了填补这块空白,作者想做出一个类似SSD和YOLO级别的实例分割。
在目标检测领域,SSD和YOLO通过移除像Faster RCNN那样的第二个阶段,并通过一些手段做弥补,可以达到不错的效果。然而实例分割领域却不能简单地如法炮制。此前流行的两阶段的实例分割通常都依赖于repool操作(如ROI Pooling、ROI Align)来做特征定位,然后将这些定位的特征送到mask预测分支,这种操作非常heavy且由于其串行特性而难以加速,再加上大量的后处理,故而难以实时。
基于这些问题,作者提出了YOLACT,其丢弃了显式的定位步骤,取而代之的是在prototype中隐式学习实例的定位。在这种方式下,网络可自行学习到实例mask的定位,使得在视觉上、空间上、语义上相似的实例在prototype上能够区分开来,也即网络学习到了将相似的实例区分开的能力。
2、方法
2.1. 网络结构
整体网络架构如图2所示:

网络结构简单描述一下:
- 输入图像,送入backbone,进行特征提取;
- backbone出来的feature map,P3~P7部分利用FPN进行特征融合,送入检测分支,生成cls、bbox、mask coff; P3部分则送入mask分支,通过一个FCN生成一组prototypes;
- 对NMS之后剩下的实例,利用mask coefficients和prototypes线性组合生成最终的分割mask;
网络包含了几个要点:
- 1)网络是在one-stage网络中添加mask分支来实现实时实例分割的,但这种方式不同于Mask-RCNN在Faster-RCNN基础上做的那样,YOLOACT没有显式定位操作,而是通过prototype来隐式学习;
- 2)网络的两个分支:
- a. 目标检测分支:除了包含目标检测的常规内容(边框、置信度、类别等),还增加了mask系数;
- b. prototype分支:固定通道数的一组prototype,原图尺度、不依赖于实例类别;其通过分布式表达各个实例的特征,在预测时也会利用所有prototype对每个种类别的实例做分割;
- 3)将实例mask的预测内容分解到两个分支是因为:可以利用擅长生成语义向量的FC层生成mask系数,利用擅长产生空间相关mask的卷积层来生成prototype,这样可以实现并行计算,从而保持一阶段且快速的特点。
2.2. 关于prototype
本工作最重要的工作是在实例分割中引入了prototype。
prototypes是一组通过FCN生成的固定通道数的feature map,protonet网络结构见图3:

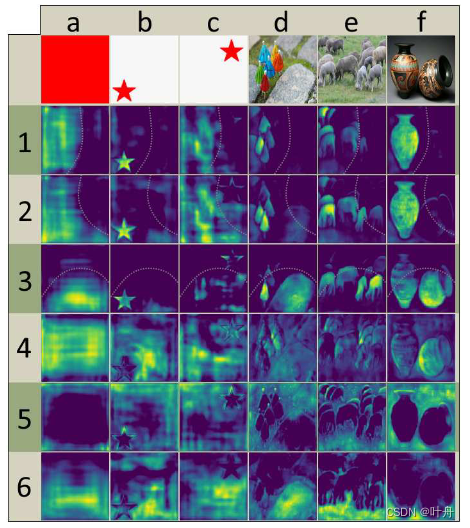
prototypes的通道数与类别数无关,对每个类别,都会通过所有prototype跨类别组合来做分割。YOLACT中的prototype学习到的是一种分布式表示,每一个实例的分割mask都是多个prototype的组合,也即prototype是跨类别共享的。
这种分布式的特征表示,使得每个prototype负责不同的特征:有的负责在空间上划分图像,有的负责定位实例,有的负责编码位置敏感的方向图(类似于FCIS中硬编码位置敏感的模块),而大部分prototype都是这些信息的组合表示。这种特性如图5所示:
3、实验结果