《Pytorch新手入门》第二节-动手搭建神经网络
- 一、神经网络介绍
- 二、使用torch.nn搭建神经网络
- 2.1 定义网络
- 2.2 torch.autograd.Variable
- 2.3 损失函数与反向传播
- 2.4 优化器torch.optim
- 三、实战-实现图像分类(CIFAR-10数据集)
- 3.1 CIFAR-10数据集加载与预处理
- 3.2 定义网络结构
- 3.3 定义损失函数和优化器
- 3.4 训练网络
- 3.5 测试
- 四、总结(附完整代码)
参考《深度学习框架PyTorch:入门与实践_陈云(著)》
代码链接:https://github.com/chenyuntc/pytorch-book
一、神经网络介绍
神经网络是机器学习中的一种模型,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。

感知机模型相当于神经网络的基本单元,只包含一个神经元
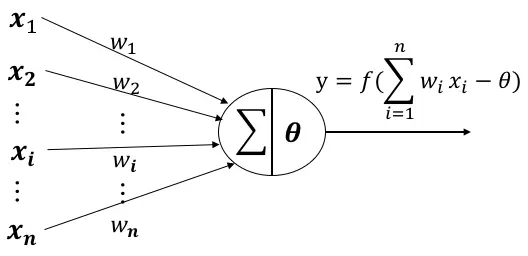
一个神经元有n个输入,每一个输入对应一个权值w,神经元内会对输入与权重做乘法后求和,求和的结果与偏置做差,最终将结果放入激活函数中,由激活函数给出最后的输出,输出往往是二进制的,0 状态代表抑制,1 状态代表激活。
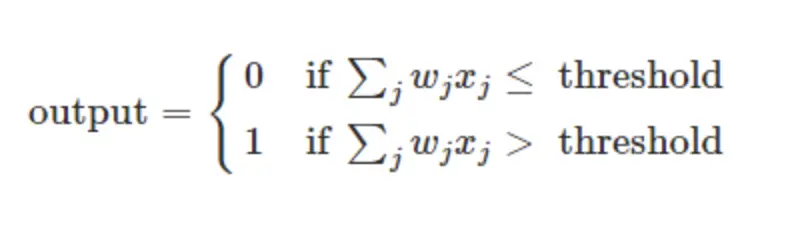
但是对于只有输入层与输出层的感知机模型,只能对线性数据进行划分,对于如下图的异或模型,是无法准确划分的。

但如果是两层网络(这里的两层指的是隐层与输出层,因为只有这两层中的节点是有激活函数的),在隐层有两个节点,那么此时就可以得到两条线性函数,再在输出节点汇总之后,将会得到由两条直线围成的一个面,这时就可以成功的将异或问题解决。


随着网络深度的增加,每一层节点个数的增加,都可以加强网络的表达能力,网络的复杂度越高,其表示能力就越强,也就可以表达更复杂的模型,这就是多层感知机。而对网络的学习其实主要是对网络中各个节点之间的连接权值和阈值的学习,即寻找最优的连接权值和阈值从而使得该模型可以达到最优(一般是局部最优),更新权重的过程分为两个阶段:输入信号的前向传播和误差的反向传播,即BP神经网络。

一个神经网络包括输入层、隐含层(中间层)和输出层。输入层神经元个数与输入数据的维数相同,输出层神经元个数与需要拟合的数据个数相同,隐含层神经元个数与层数就需要设计者自己根据一些规则和目标来设定。在深度学习出现之前,隐含层的层数通常为一层,即通常使用的神经网络是3层网络。
BP神经网络采用的是全连接网络,当神经元个数或隐藏层增加时,参数量会变得非常庞大,导致训练时间过长,网络麻痹,局部最小等问题,因此没办法将网络设计的很深,这也在很大程度上限制了BP神经网络的应用,无法解决复杂问题,直到出现了卷积神经网络。
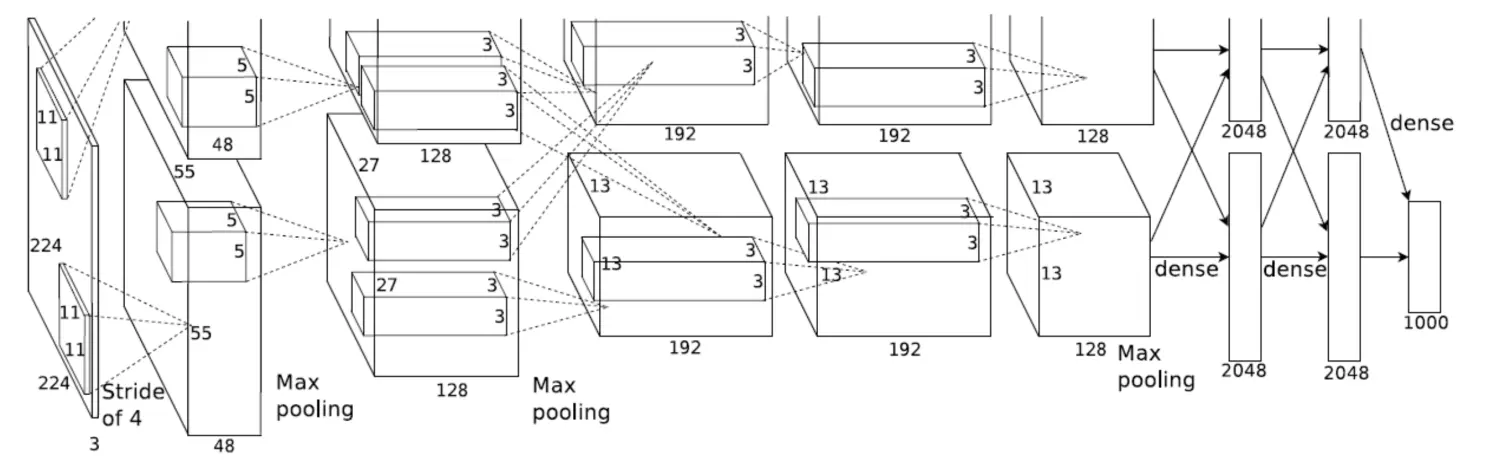
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
最简单的卷积神经网络由三部分构成。第一部分是输入层。第二部分由n个卷积层和池化层的组合组成。第三部分由一个全连结的多层感知机分类器构成。如上图的ALexNet。
二、使用torch.nn搭建神经网络
torch.nn 是专门为神经网络设计的模块化接口。nn.Module 是 nn 中最重要的类,可以把它看作一个网络的封装,包含网络各层定义及forward方法,调用forward(input)方法,可返回前向传播的结果。我们以最早的卷积神经网络LeNet 为例,来看看如何用.Module实现。
以LeNet为例:

2.1 定义网络
定义网络时,需要继承nn.Module,并实现它的 forward 方法,把网络中具有可学习参数的层放在构造函数__init__()中。如果某一层(如ReLU)不具有可学习的参数,则既可以放在构造函数中,也可以不放。
import torch as t
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__()
# 第一个参数1表示输入图片为单通道,第二个参数6表示输出通道数
# 第三个参数5表示卷积核为5*5
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 前向传播
def forward(self, x):
# 一般步骤:卷积——》激活——》池化
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
# 将输出的多维度的tensor展平成一维,然后输入分类器
# -1是自适应分配,指在不知道函数有多少列的情况下,根据原tensor数据自动分配列数
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
if __name__=="__main__":
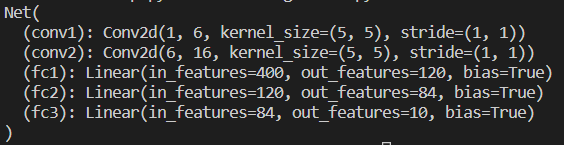
net = Net()
print(net)
只要在nnModule的子类中定义了 forward 函数,backward 函数就会被自动实现(利用Autograd自动微分)。在forward 函数中可使用任何 Variable 支持的函数,还可以使用iffor循环、print、log等Python语法,写法和标准的Python写法一致。
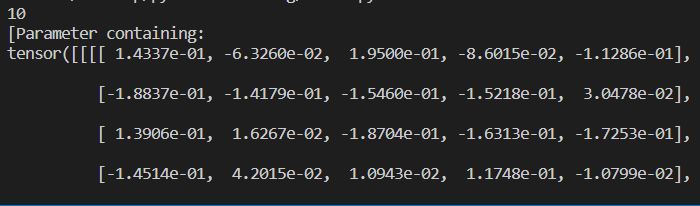
网络的可学习参数通过net.parameters()返回,net.named_parameters可同时返回可学习的参数及名称。
params = list(net.parameters())
print(len(params))
print(params)
(所有参数进行了随机初始化)
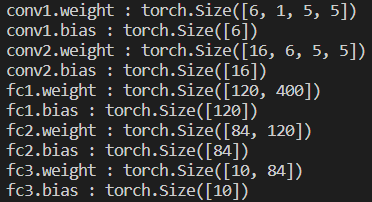
for name, param in net.named_parameters():
print(name, ":", param.size())
2.2 torch.autograd.Variable
forward 函数的输人和输出都是 Variable,只有 Variable 才具有自动求导功能,Tensor是没有的,所以在输人时,需要把Tensor封装成Variable。
autograd.Variable是Autograd 中的核心类,它简单封装了Tensor,并支持几乎所有Tensor的操作。
Tensor在被封装为 Variable之后,可以调用它的backward实现反向传播,自动计算所有梯度。Variable 的数据结构如图所示。(torch.autograd自动微分模块将在后续详细讲解)
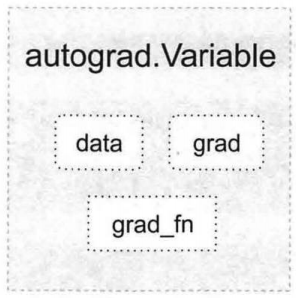
Variable主要包含三个属性。
data:保存Variable所包含的Tensor。
grad:保存data对应的梯度,grad也是个 Variable,而不是Tensor,它和data的形状一样。
grad_fn:指向一个Function对象,这个Function用来反向传播计算输人的梯度
from torch.autograd import Variable
input = Variable(t.randn(1, 1, 32, 32))
out = net(input)
print(out.size())
print(out)
'''
torch.Size([1, 10])
tensor([[ 0.0865, 0.0695, -0.0310, 0.0339, -0.0652, -0.1096, 0.0837, 0.0969,
-0.1431, -0.0609]], grad_fn=<AddmmBackward>)
'''
需要注意的是,torch.nn只支持mini-batches,不支持一次只输入一个样本,即一次必须是一个batch。如果只想输人一个样本,则用input.unsqueeze(0)将 batch size设为1。例如nn.Conv2d 输入必须是4维的,形如 nSamplesnChannelsHeightWidth,可将nSamples设为1,即1nChannelsHeightWidth。
2.3 损失函数与反向传播
nn实现了神经网络中大多数的损失函数,如nn.MSELoss 用来计算均方误差,nn.CrossEntropyLoss 用来计算交叉简损失。
target = Variable(t.arange(0, 10)).float()
criterion = nn.MSELoss()
loss = criterion(out, target)
print(loss)
'''
tensor(28.4748, grad_fn=<MseLossBackward>)
'''
对loss进行反向传播溯源(使用grad_fn属性)
首先通过前面的网络可以看到它的计算图如下
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
当我们使用loss.backward()时,该图会动态生成并自动微分,也会自动计算图中参数(Parameter)的导数。
但是要注意grad在反向传播过程中是累加的 (accumulated ),这意味着每次运行反向传播,梯度都会累加之前的梯度,所以反向传播之前需把梯度清零。
# 调用loss.backward(),观察调用之前和调用之后的grad
# 把net中所有可学习的参数的梯度清零
net.zero_grad()
print("反向传播之前conv1.bias的梯度")
print(net.conv1.bias.grad)
loss.backward()
print("反向传播之后conv1.bias的梯度")
print(net.conv1.bias.grad)
'''
反向传播之前conv1.bias的梯度
None
反向传播之后conv1.bias的梯度
tensor([ 0.0024, -0.0718, 0.0162, -0.0442, -0.0605, -0.0177])
'''
2.4 优化器torch.optim
在反向传播计算完所有参数的梯度后,还需要使用优化方法更新网络的权重和参数。例如,随机梯度下降法(SGD)的更新策略如下:
weight = weight - learning_rate * gradient
print(x[:, 1])
'''
tensor([0.0000e+00, 1.0516e-35, 0.0000e+00, 1.0515e-35, 0.0000e+00])
'''
手动实现:
learning_rate = 0.01
for p in net.parameters():
p.data.sub_(p.grad.data * learning_rate)
权重更新完成后,就会进入到下一轮的训练,循环进行,直到达到训练轮次或者满足停止训练条件。
torch.optim中实现了深度学习中绝大多数的优化方法,例如 RMSProp、AdamtorchSGD等,更便于使用,因此通常并不需要手动写上述代码。
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr = 0.01)
# 在训练过程中,先梯度清零
# 和net.zero_grad()效果一样
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
三、实战-实现图像分类(CIFAR-10数据集)
实现步骤:
- 使用torchvision加载并预处理CIFAR-10数据集
- 定义网络结构
- 定义损失函数和优化器
- 训练网络并更新网络参数
- 测试网络
3.1 CIFAR-10数据集加载与预处理
CIFAR-10是一个常用的彩色图片数据集,它有 10个类别:airplane、automobilebird、cat、deer、dog、frog、horse、ship 和 truck。每张图片都是3x 32x32,也即3通道彩色图片,分辨率为32x32。
在深度学习中数据加载及预处理是非常复杂烦琐的,但PyTorch 提供了一些可极大简化和加快数据处理流程的工具。同时,对于常用的数据集,PyTorch 也提供了封装好的接口供用户快速调用,这些数据集主要保存在 torchvision 中。
torchvision实现了常用的图像数据加载功能,例如Imagenet、CIFAR10、MNIST等,以及常用的数据转换操作,这极大地方便了数据加载。
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
# 可以把Tensor转成Image,方便可视化
show = ToPILImage()
# 定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转为tensor
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)), # 归一化
])
# 加载数据集
# 训练集
trainset = tv.datasets.CIFAR10(
root = './data/',
train=True,
download=True,
transform=transform
)
trainloader = t.utils.data.DataLoader(
trainset,
batch_size=4,
shuffle=True,
num_workers=2
)
# 测试集
testset = tv.datasets.CIFAR10(
root = './data/',
train=True,
download=False,
transform=transform
)
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=2
)
第一次运行程序torchvision会自动下载CIFAR-10数据集,有100多MB,需花费一定的时间(可能一次下载不会成功,可以多试几次),如果已经下载有CIFAR-10,可通过root参数指定。


classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog',
'frog', 'horse', 'ship', 'truck')
(data, label) = trainset[100]
print(classes[label])
show((data+1)/2).resize((100, 100))
Dataset对象是一个数据集,可以按下标访问,返回形如(data,label)的数据。

Dataloader 是一个可迭代的对象,它将dataset 返回的每一条数据样本拼接成一个batch,并提供多线程加速优化和数据打乱等操作。当程序对dataset 的所有数据遍历完遍之后,对Dataloader 也完成了一次迭代。
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(" ".join('%ls' % classes[labels[j]] for j in range(4)))
show(tv.utils.make_grid((images+1)/2)).resize((400, 100))

3.2 定义网络结构
使用2.1小节中的LeNet网络,将self.conv1中第一个参数修改为3,因为CIFAR-10是3通道彩色图。
class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__()
# 第一个参数1表示输入图片为单通道,第二个参数6表示输出通道数
# 第三个参数5表示卷积核为5*5
self.conv1 = nn.Conv2d(3, 6, 5) # 将单通道改为3通道
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 前向传播
def forward(self, x):
# 一般步骤:卷积——》激活——》池化
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
# 将输出的多维度的tensor展平成一维,然后输入分类器
# -1是自适应分配,指在不知道函数有多少列的情况下,根据原tensor数据自动分配列数
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
3.3 定义损失函数和优化器
损失函数采用交叉熵损失,优化器采用随机梯度下降,学习率为0.001。
from torch import optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
3.4 训练网络
所有网络的训练流程都是类似的,循环执行如下流程:
- 输入数据
- 前向传播得到输出
- 计算误差
- 误差反向传播
- 更新参数
# 训练20个epoch
for epoch in range(20):
running_loss = 0.0
for i, data in enumerate(trainloader):
# 输入数据
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = net(inputs)
# 求误差
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 打印log信息
# 在pytorch0.4版本之后,Variable和Tensor进行了合并。loss.data直接输出tensor值,不输出tensor的梯度信息,所以不用加[0]
running_loss += loss.data
# 每2000个batch打印一次训练状态
if i%2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/2000))
running_loss = 0.0
print('Finishing Training')
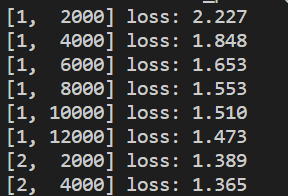
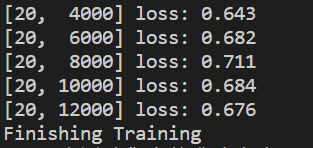
可以看到loss在不断下降,如果想更直观地观察变化曲线,可以将数据可视化,比如使用Tensorboard。
如果想要在GPU上训练,需要将网络和数据集转移到GPU上
if t.cuda.is_available():
net.cuda()
images = images.cuda()
labels = labels.cuda()
output = net(Variable(images))
loss = criterion(output, Variable(labels))
如果发现在GPU上训练的速度并没比在 CPU 上提速很多,实际是因为网络比较小,GPU没有完全发挥自己的真正实力。
3.5 测试
在整个测试集的效果
correct = 0
total = 0
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = t.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('{}张测试集中的准确率为{} %'.format(total, 100*correct.item()//total))

可以看到,在使用LeNet网络训练20轮后,其准确率为60%,训练的准确率远比随机猜测(准确率为 10%)好,证明网络确实学到了东西。
四、总结(附完整代码)
通过这一节的学习,我们体会了神经网络构建、训练、测试的完整流程,后续章节将会深入和详细地讲解其中包含的具体知识。
完整代码(做了一些小修改):
import torch as t
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch import optim
import torchvision as tv
import torchvision.transforms as transforms
# 类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog',
'frog', 'horse', 'ship', 'truck')
#定义网络结构
class Net(nn.Module):
def __init__(self, in_channel, out_channel):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__()
# 第一个参数1表示输入图片为单通道,第二个参数6表示输出通道数
# 第三个参数5表示卷积核为5*5
self.conv1 = nn.Conv2d(in_channel, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, out_channel)
# 前向传播
def forward(self, x):
# 一般步骤:卷积——》激活——》池化
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
# 将输出的多维度的tensor展平成一维,然后输入分类器
# -1是自适应分配,指在不知道函数有多少列的情况下,根据原tensor数据自动分配列数
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 训练
def train(net, epoch):
# 定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转为tensor
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)), # 归一化
])
# 加载数据集
# 训练集
trainset = tv.datasets.CIFAR10(
root = './data/',
train=True,
download=False,
transform=transform
)
trainloader = t.utils.data.DataLoader(
trainset,
batch_size=4,
shuffle=True,
num_workers=0
)
# 测试集
testset = tv.datasets.CIFAR10(
root = './data/',
train=False,
download=False,
transform=transform
)
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=0
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(epoch):
running_loss = 0.0
for i, data in enumerate(trainloader):
# 输入数据
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = net(inputs)
# 求误差
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 打印log信息
running_loss += loss.data
# 每2000个batch打印一次训练状态
if i%2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/2000))
running_loss = 0.0
print('Finishing Training')
# 在测试集上的效果
correct = 0
total = 0
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = t.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('{}张测试集中的准确率为{} %'.format(total, 100*correct.item()//total))
if __name__=="__main__":
net = Net(3, 10)
train(net, 2)