目录
- 一、高性能应用服务HAI产品 + Stable Diffusion Webui部署思路
- 二、一键启动Stable Diffusion WebUI 推理
- 三、使用 HAI JupyterLab连接 进行 StableDiffusion API 的部署
- 四、使用本地IDE实现私服Web端一键文生图
- 五、使用腾讯云Cloud Studio 快速云上开发
- 六、高性能应用服务HAI使用感受
- 最后
 本次有幸受邀作为新品先锋体验官参加了【腾讯云HAI域探秘】活动,沉浸式体验高性能应用服务HAI产品 + Stable Diffusion WebUI部署。
本次有幸受邀作为新品先锋体验官参加了【腾讯云HAI域探秘】活动,沉浸式体验高性能应用服务HAI产品 + Stable Diffusion WebUI部署。
一、高性能应用服务HAI产品 + Stable Diffusion Webui部署思路
腾讯云高性能应用服务(Hyper Application Inventor, HAI),是一款面向AI、科学计算的GPU应用服务产品,为开发者量身打造的澎湃算力平台。基于腾讯云GPU云服务器底层算力,提供即插即用的高性能云服务,无需复杂配置,便可享受即开即用的GPU云服务体验。我们的实验思路主要如下:
- 体验高性能应用服务HAI启动 StableDiffusionWebUI 进行文生图模型推理;
- 使用高性能应用服务HA的JupyterLab连接进行 StableDiffusion API 的部署;
- 使用本地IDE调用 StableDiffusion API 的前端Web页面,实现私服一键文生图;
- 使用腾讯Cloud Studio 快速开发调用 StableDiffusion API 的前端Web页面;

二、一键启动Stable Diffusion WebUI 推理
打开高性能应用服务HAI,申请到体验资格后,在控制台点击新建,选择AI模型,选择Stable Diffusion,地域任意选择,算力方案选择基础型,然后为实例取个名称如:stable_diffusion_test,硬盘默认50GB,点击购买。
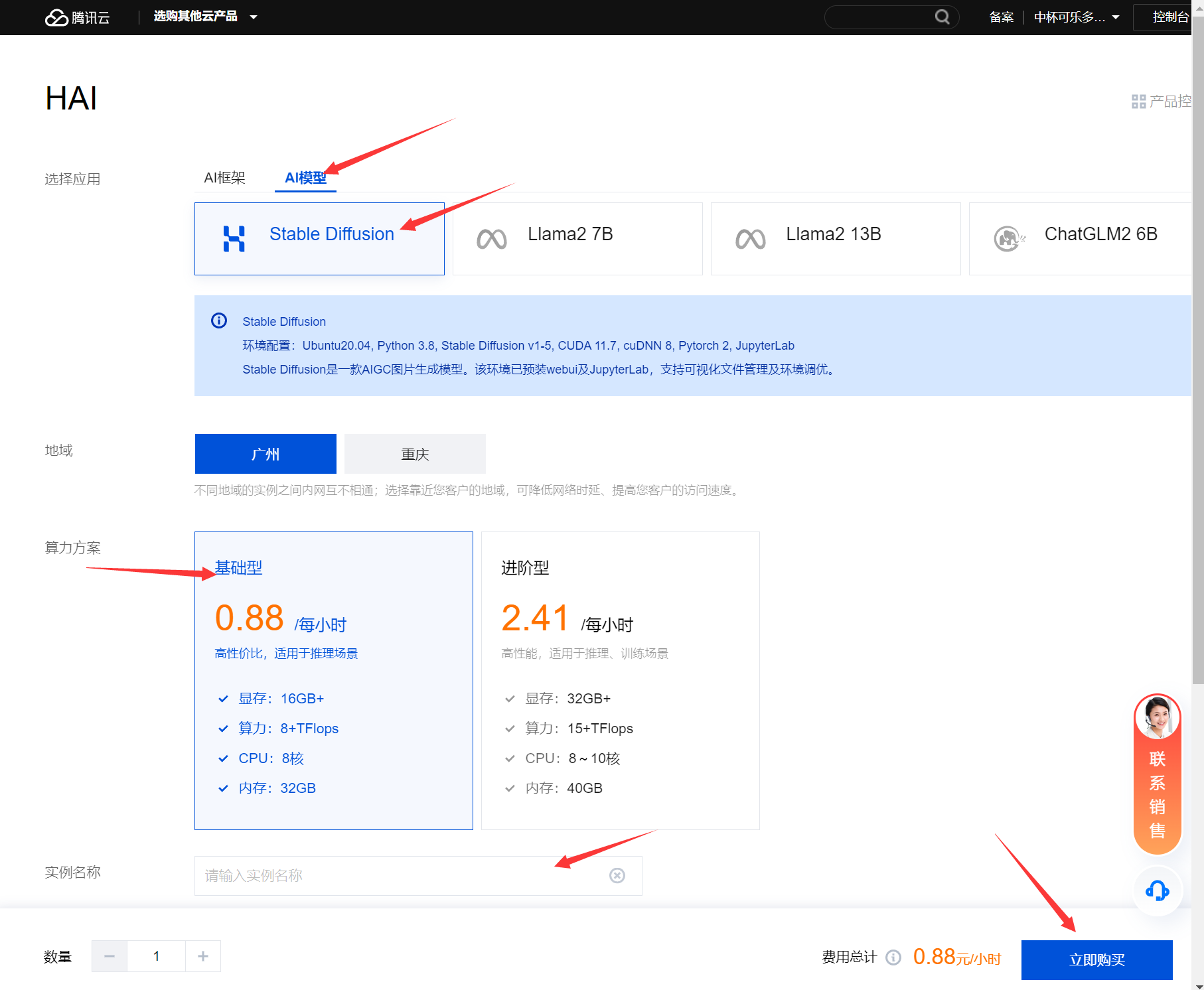
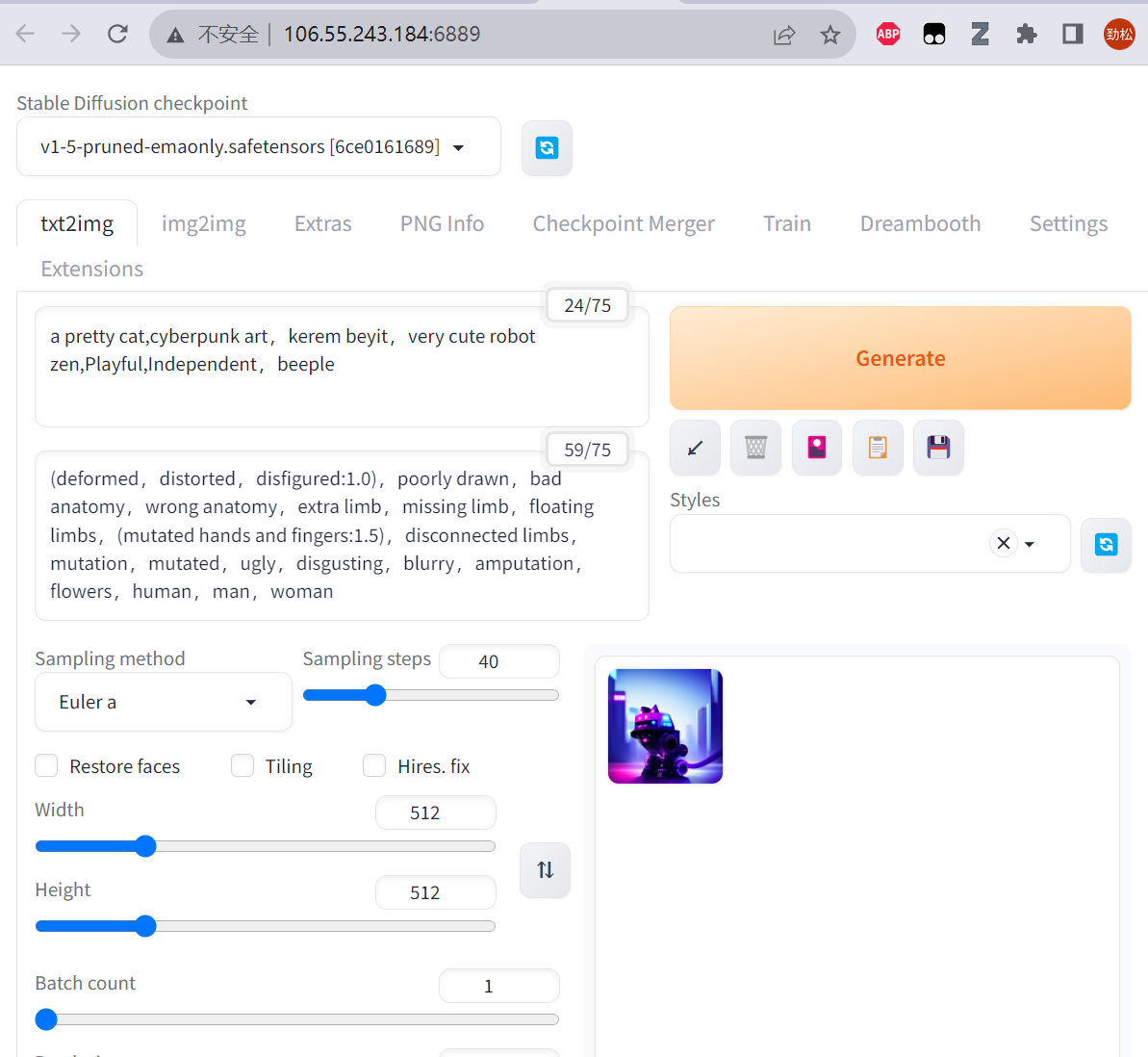
等待创建完成后,点击算力连接,点击stable_diffusion_webui,一键启动推理
进入页面后,我们就可以开始使用 高性能应用服务HAI 部署的StableDiffusionWebUI 快速进行AI绘画了,整个的ui界面包括了
- 模型选择: 模型对于 SD 绘图来说非常重要,不同的模型类型、质量会很大程度的决定最终的出图效果(系统默认配置了基础模型,也可以更换)
- Prompt区: 如果你使用过 ChatGPT 你应该知道 Prompt 是什么。说的直白点就是你想让 SD 帮忙生成什么样的图,反向 Prompt 就是你不想让 SD 出生的图里有这些东西。后续课程也会详细的讲解如何更好的编写 Prompt
- 功能栏: 包括了常见的 文生图、图生图、模型获取、模型训练等功能。不同的功能页面也不同,这一节课,我们先针对最长使用的 文生图 模块页面来讲解
- 采样区: 采用什么样的绘画方式算法,以及“画多少笔” 来绘图。一定程度上决定出图的质量
- 调参区: 设置分辨率、每次出图的批次、出图抽象性(和 prompt 关联性的程度)
- 脚本区: 通过配置脚本可以提高效率;比如批量出图、多参数的出图效果比较
经常使用的功能如下:
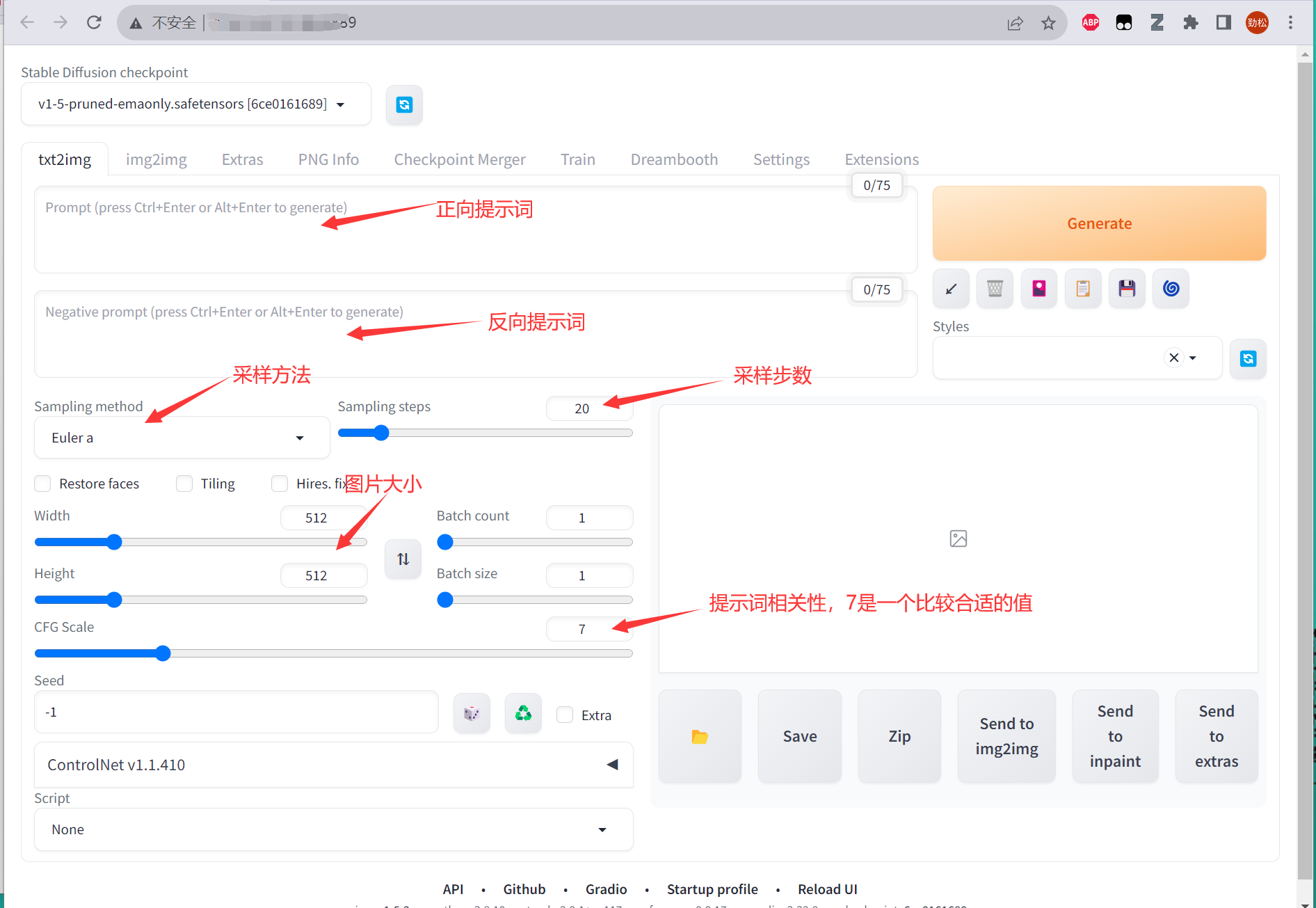
这里推荐几个小技巧:
- 正向提示词(Prompt)和反向越多,AI 绘图结果会更加精准。另外,目前中文提示词的效果不好,还得使用英文提示词;
- 采样方式推荐使用Euler a、DDIM、DPM ++ 2M Karras这三个;
- 采样步骤建议在20~40之间,步数越高也就意味着耗费的资源会越多,对机器的配置会更高,且步数不是越高越好;
- 分辨率推荐使用512×512,在 SD 的最初模型 SD 1.5 训练的图片的分辨率大部分都是 512×512,所以在出图的时候,这个分辨率的效果也是最好的;
- 若是想明确某主体,应当使其生成步骤向前,生成步骤数加大,词缀排序向前,权重提高。画面质量 → 主要元素 → 细节;若是想明确风格,则风格词缀应当优于内容词缀,画面质量 → 风格 → 元素 → 细节。
三、使用 HAI JupyterLab连接 进行 StableDiffusion API 的部署
点击Jupyter_Lab连接,进入JupyterLab
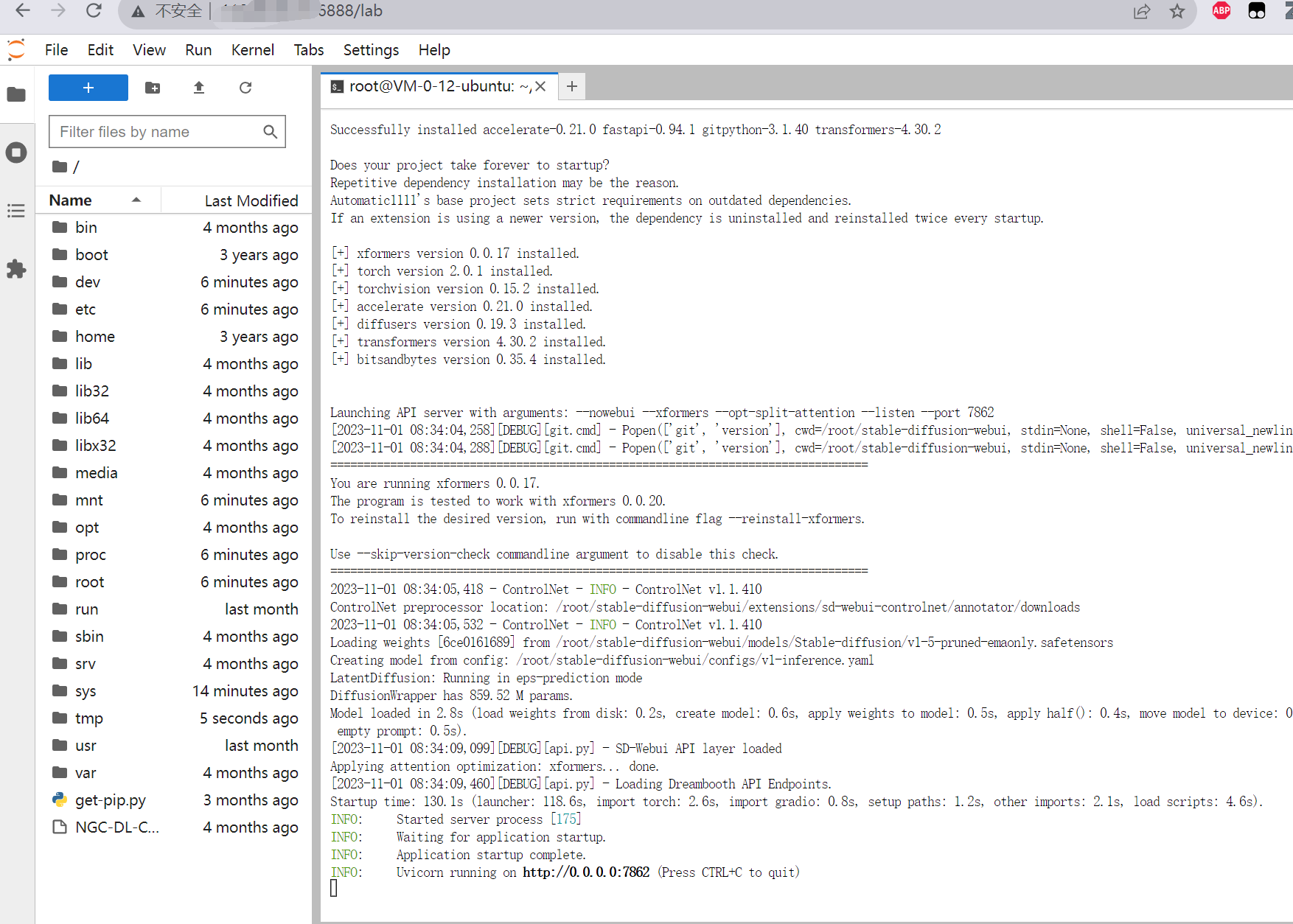
新建一个终端,cd进入/root/stable-diffusion-webui目录,然后以API 模式启动运行launch.py文件,并监听7862端口,命令如下:
cd /root/stable-diffusion-webui
python launch.py --nowebui --xformers --opt-split-attention --listen --port 7862
启动成功后,如图所示:
为了使外部网络能够顺利地访问该服务器提供的API服务,我们还需要给 高性能应用服务HAI 配置端口规则,点击服务器的图标进入配置项:
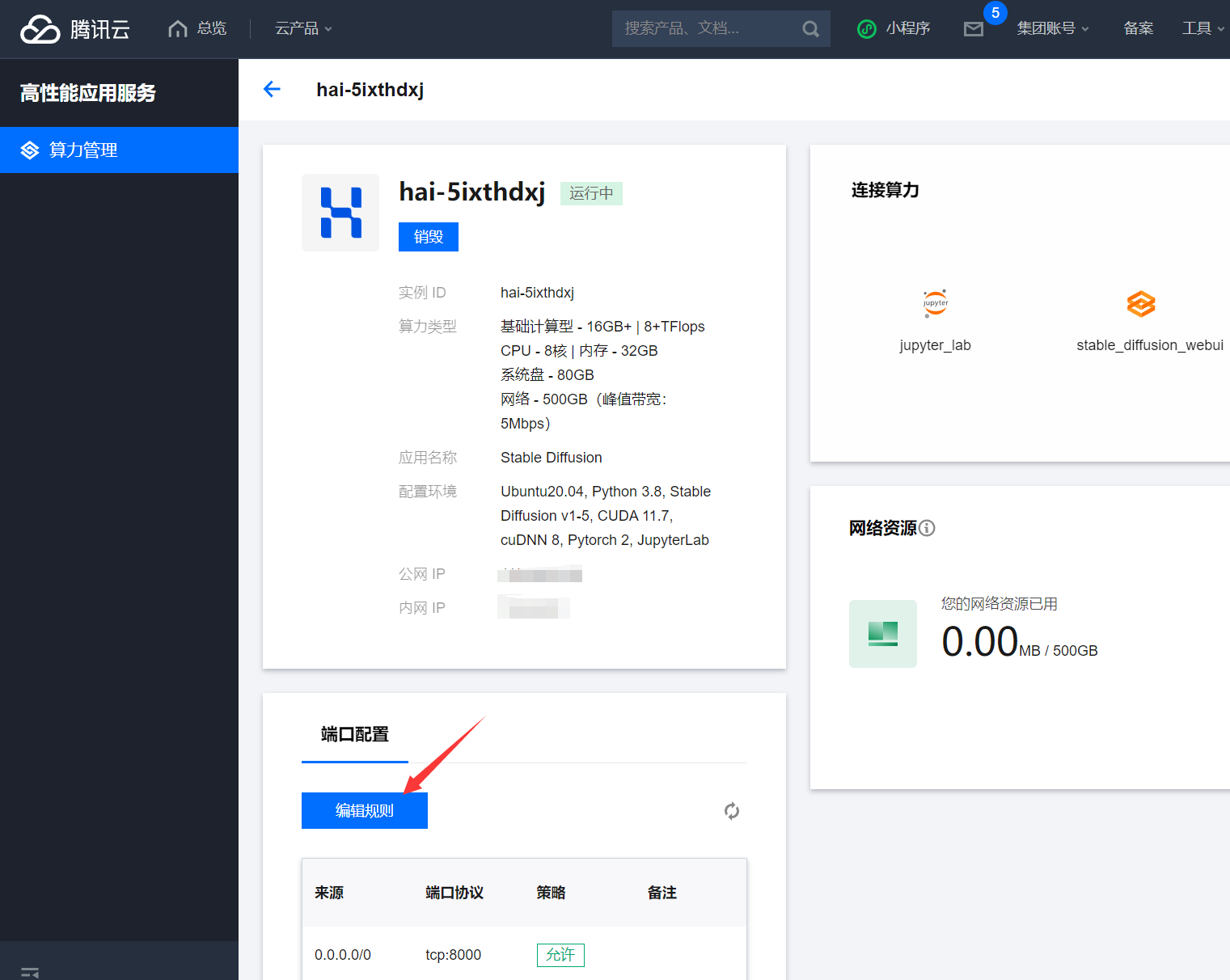
添加入站规则,配置来源0.0.0.0/0 ,协议端口:TCP:7862 (根据您配置的端口填写),如下:
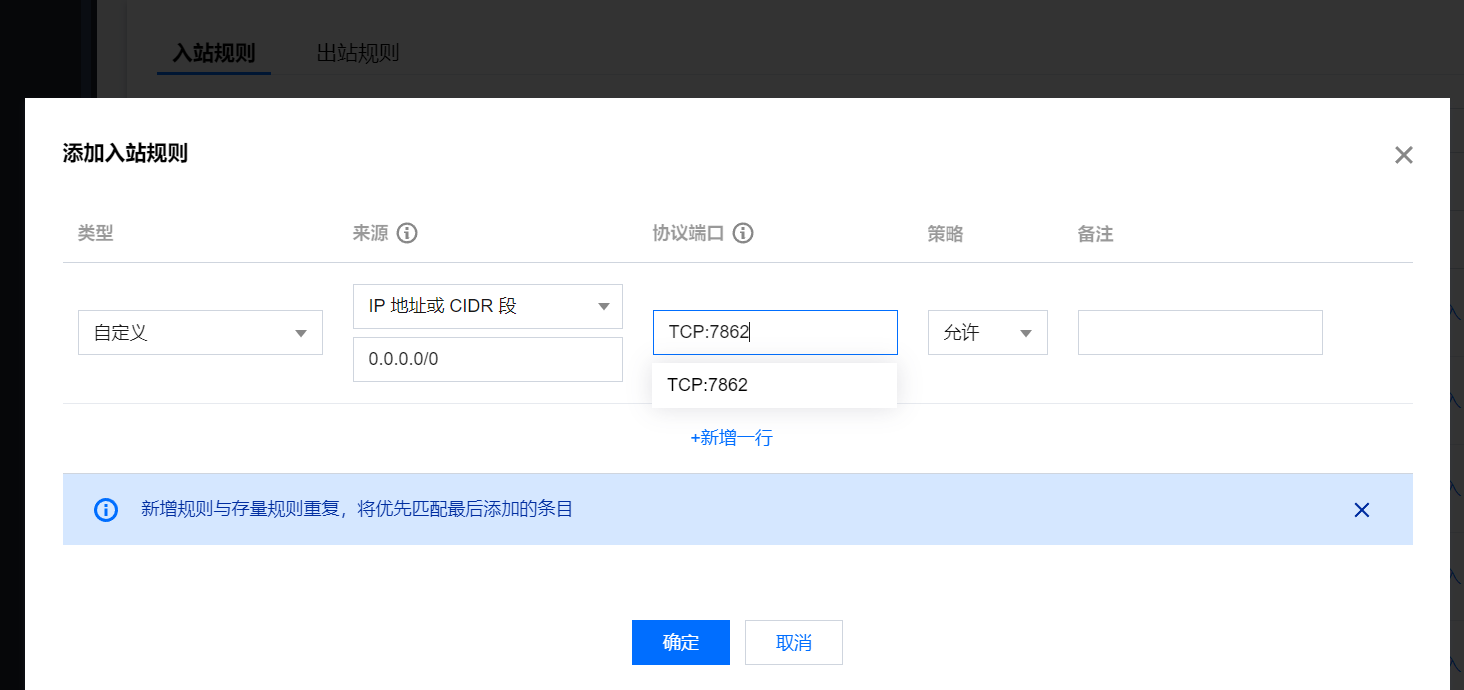
配置完成后输入 服务器IP地址:端口号/docs 可查看相关的 API 接口 swagger 使用指南,这里不再展开
这里我们可以使用Postman测试结构是否部署成功,打开Postman,新建一个Post请求,url为http://服务器IP地址:端口号/sdapi/v1/txt2img,然后body改为JSON格式,并输入相关请求参数,如下:
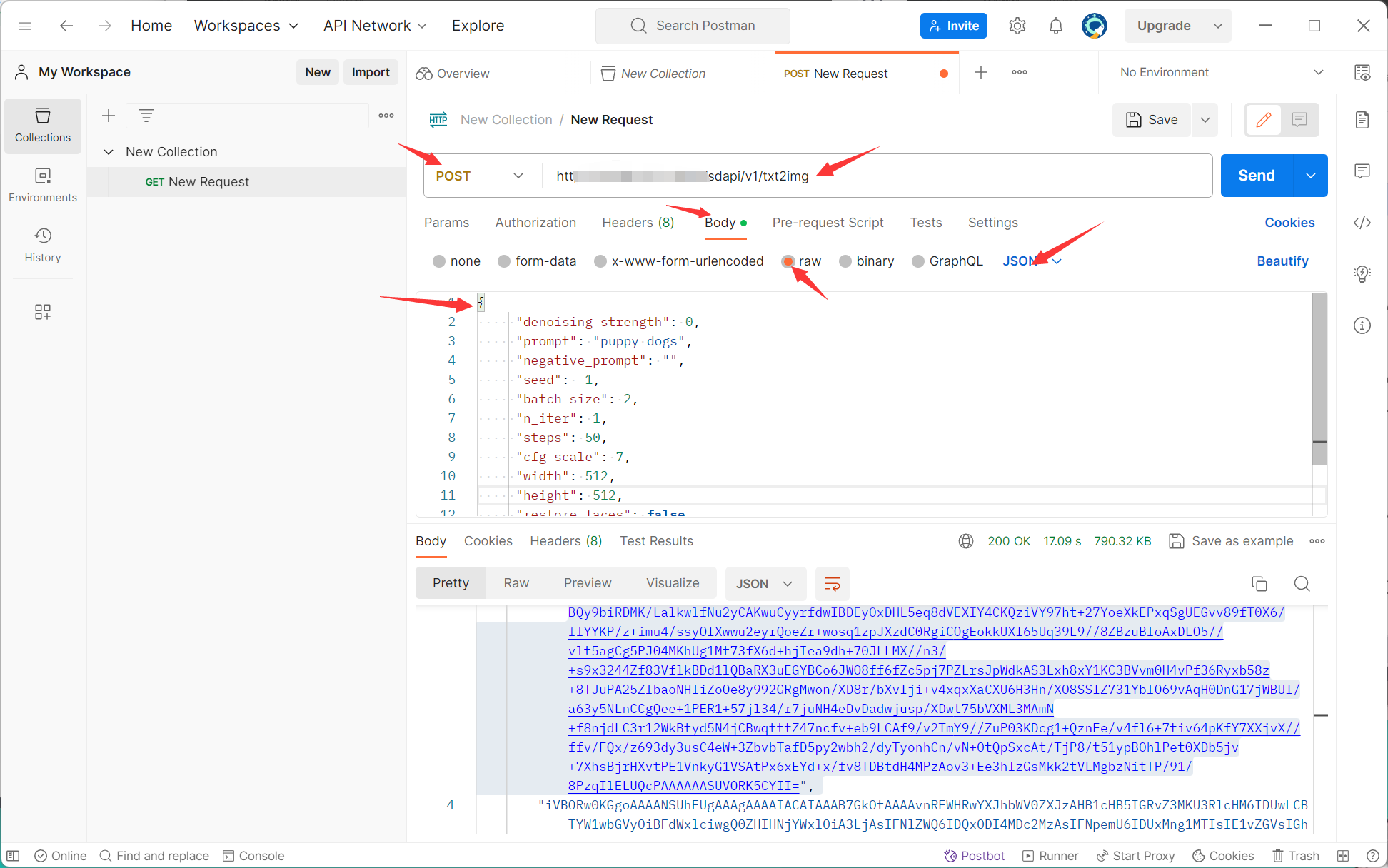
简单的请求参数如下:
{
"denoising_strength": 0,
"prompt": "puppy dogs",
"negative_prompt": "",
"seed": -1,
"batch_size": 2,
"n_iter": 1,
"steps": 50,
"cfg_scale": 7,
"width": 512,
"height": 512,
"restore_faces": false,
"tiling": false,
"sampler_index": "Euler"
}
其中,prompt为提示词,negative_prompt为反向提示词,seed为种子,随机数,batch_size为每次张数,n_iter为生成批次,steps为生成步数,cfg_scale为关键词相关性,width为宽度,height为高度,restore_faces为脸部修复,tiling为可平铺,sampler_index为采样方法。
点击Send后,HAI服务器接受请求并进行推理,推理后会将图以base64的方法发过来,返回的格式如下:
{
"images": [...],// 这里是一个base64格式的字符串数组,根据你请求的图片数量而定
"parameters": { ... },//此处为你输入的body
"info": "{...}"// 返回的图片的信息
}
四、使用本地IDE实现私服Web端一键文生图
既然Postman测试成功,那么我们可以为其写一个Web前端页面,本次项目使用到的技术栈为Vue3+TS+Vite+Ant-Design+Axios,项目已经上传至CSDN,链接如下:https://download.csdn.net/download/air__Heaven/88492769
下载后,解压并打开终端,输入npm i安装依赖,然后打开vite.config.ts,将sdapi和controlnet的api改为HAI服务器的地址和端口:
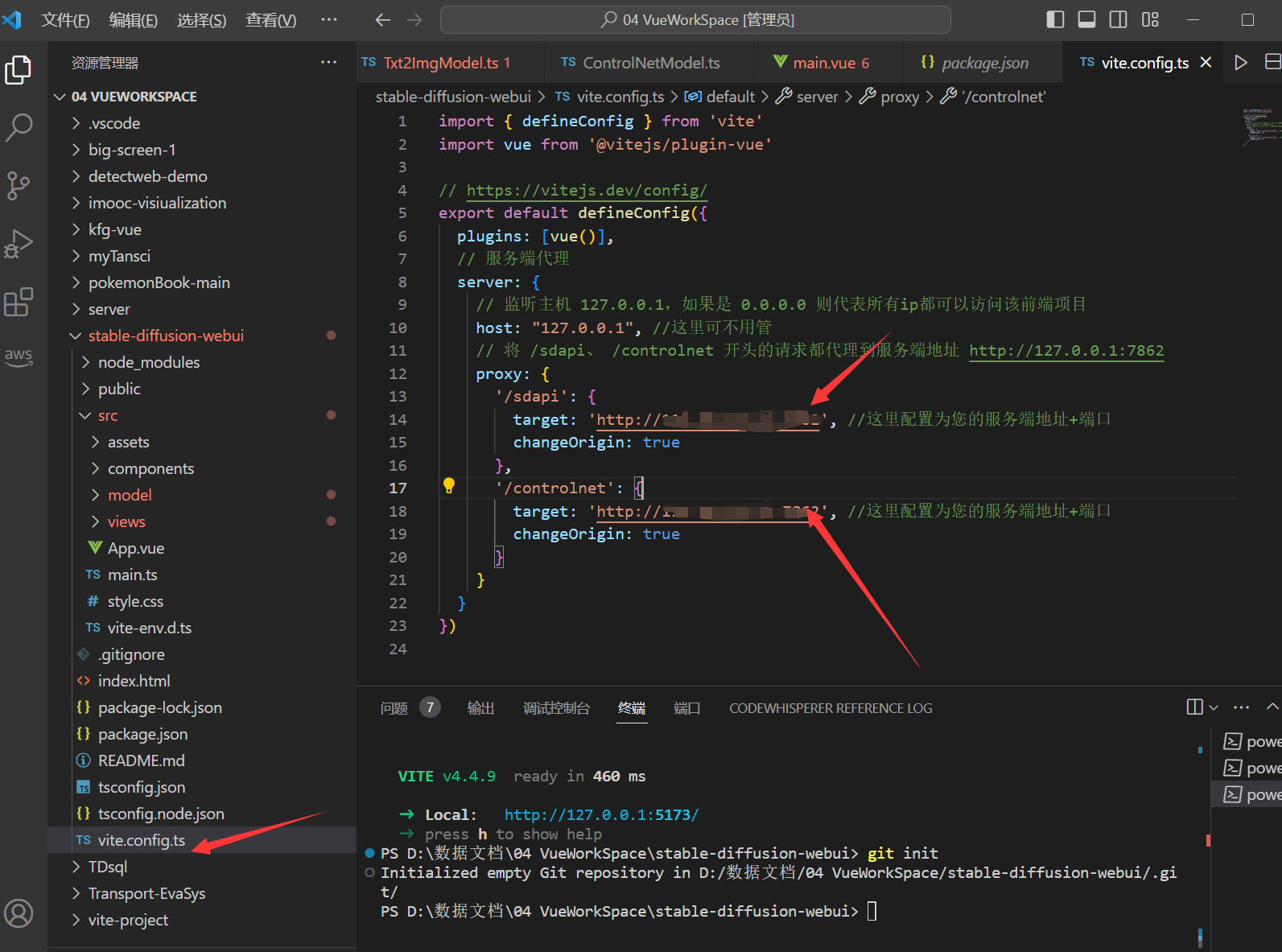
然后输入npm run dev运行项目,就可以愉快的开始玩耍了!
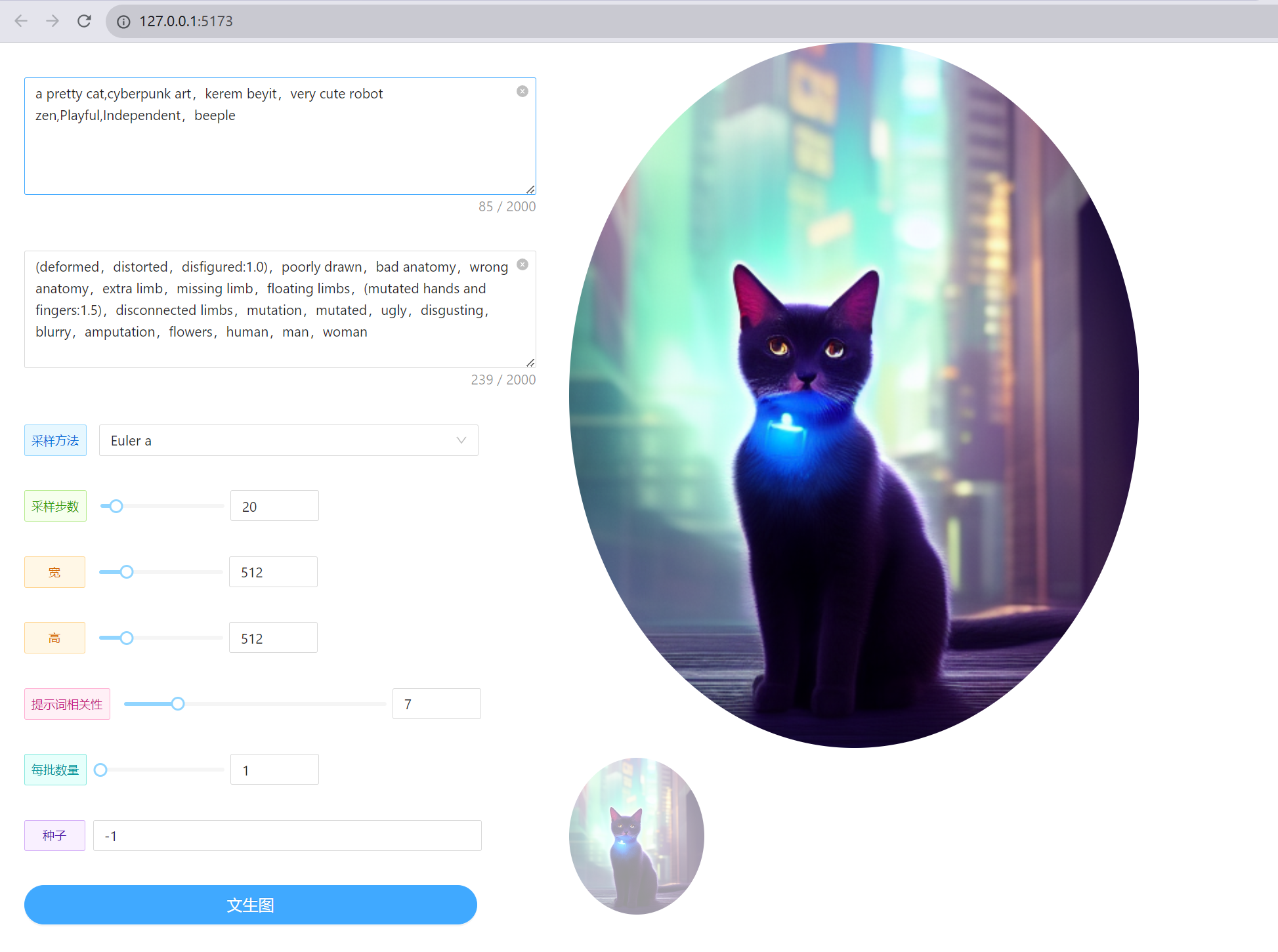
其中main.vue中的核心代码如下:
// 定义文生图请求函数
async function txt2Img() {
// 每次请求之前清空浏览器的 localStorage 中的缓存
txt2imgReqStorage.value = null
txt2imgResultStorage.value = null
// 清空轮播图
txt2img_imgs.value = []
// 如果启用了 ControleNet 则将 ControlNet 相关组件中的参数填充到 文生图请求参数中
if (controlNetEnable.value === true) {
console.log(imgFileList.value)
if (imgFileList.value?.length === 0) {
message.error("ControlNet已启用,请上传图片")
return
}
if (controlNet_payload.value.module === '') {
message.error("ControlNet已启用,请选择预处理器")
return
}
if (controlNet_payload.value.model === '') {
message.error("ControlNet已启用,请选择模型")
return
}
imgFileList.value?.forEach((value, index) => {
if (index === 0) {
controlNet_payload.value.input_image = value.thumbUrl || ''
}
})
txt2img_payload.value.alwayson_scripts = {
controlnet: {
args: [controlNet_payload.value]
}
}
} else {
txt2img_payload.value.alwayson_scripts = {}
}
// 打印请求参数
console.log("文生图请求参数:", txt2img_payload.value)
// 将请求参数保存在浏览器的 localStorage 中
txt2imgReqStorage.value = txt2img_payload.value;
//开始请求
message.loading('正在请求...', 10)
// 文生图api调用
const resp = await axios.post('/sdapi/v1/txt2img', txt2img_payload.value)
// 打印请求结果
console.log("文生图响应结果:", resp)
if (resp.data) {
message.success('请求成功!')
// 提取请求结果中的图片
txt2imgRes.value = resp.data
// 定义一个临时数组,该数组将赋值给 txt2imgResultStorage
let tempArr = ref<string[]>([])
txt2imgRes.value?.images.forEach((value: string, index: number) => {
txt2img_imgs.value.push('data:image/png;base64,' + value)
// 临时数组中只存放2张图片,防止赋值给 txt2imgResultStorage 后超过5M(localStorage最大支持5M),抛出异常
if (index < 2) {
tempArr.value.push('data:image/png;base64,' + value)
}
})
//将提取的请求结果中的图片保存在浏览器的 localStorage 中,如果叠加显示每次生成的图片,请把以下三行代码的注释去掉即可
// if (tempArr.value.length > 0) {
// txt2imgResultStorage.value = tempArr.value
// }
} else {
message.error('请求失败!')
}
}
// 获取文生图的采样方法
async function txt2ImgSampler() {
const resp = await axios.get("/sdapi/v1/samplers")
console.log("采样方法:", resp)
txt2ImgSamplerRes.value = resp.data
txt2ImgSamplerRes.value?.forEach((sampler: Txt2ImgSamplers) => {
txt2ImgSamplerOptions.value?.push({
value: sampler.name,
label: sampler.name
})
})
}
// 获取 ControlNet 的 Preprocessor 的值
async function controlNetPreProcessors() {
const resp = await axios.get('/controlnet/module_list')
console.log("ControlNet-Preprocessor:", resp)
controlNetModuleRes.value = resp.data
controlNetModuleRes.value?.module_list.forEach((module: string) => {
controleNetModuleSelect.value?.push({ value: module, label: module })
})
}
// 获取 ControlNet 的 Model 的值
async function controlNetModels() {
const resp = await axios.get('/controlnet/model_list')
console.log("ControlNet-Model:", resp)
controlNetModelRes.value = resp.data
controlNetModelRes.value?.model_list.forEach((model: string) => {
controleNetModelSelect.value?.push({ value: model, label: model })
})
}
// 该函数将在页面每次加载后进行调用
onMounted(() => {
// 页面加载后获取保存在浏览器的 localStorage 中的数据去填充组件的输入
if (Object.keys(txt2imgReqStorage.value).length !== 0) {
txt2img_payload.value = txt2imgReqStorage.value
}
if (txt2imgResultStorage.value.length > 0) {
txt2img_imgs.value = txt2imgResultStorage.value
}
// 调用获取文生图采样方法的函数
txt2ImgSampler()
// 调用获取 ControlNet 的 Preprocessor 的函数
controlNetPreProcessors()
// 调用获取 ControlNet 的 Model 的函数
controlNetModels()
})
其中定义一个名为txt2Img的异步函数,用于处理文生图请求。函数根据是否启用了ControlNet,将ControlNet相关组件中的参数填充到文生图请求参数中。最后,打印请求参数并将其保存在浏览器的localStorage中,然后开始发送请求。
定义一个名为txt2ImgSampler的异步函数,用于获取文生图的采样方法。该函数通过调用API接口获取采样方法数据,并将其存储在txt2ImgSamplerRes变量中。
定义了两个异步函数controlNetPreProcessors和controlNetModels,分别用于获取ControlNet的预处理器和模型的值。这两个函数都通过调用API接口获取相应的数据,并将其存储在相应的变量中。
在页面加载后,调用onMounted函数。在该函数中,首先从浏览器的localStorage中获取保存的数据并填充到组件的输入中。然后依次调用txt2ImgSampler、controlNetPreProcessors和controlNetModels函数,以获取采样方法、预处理器和模型的值。
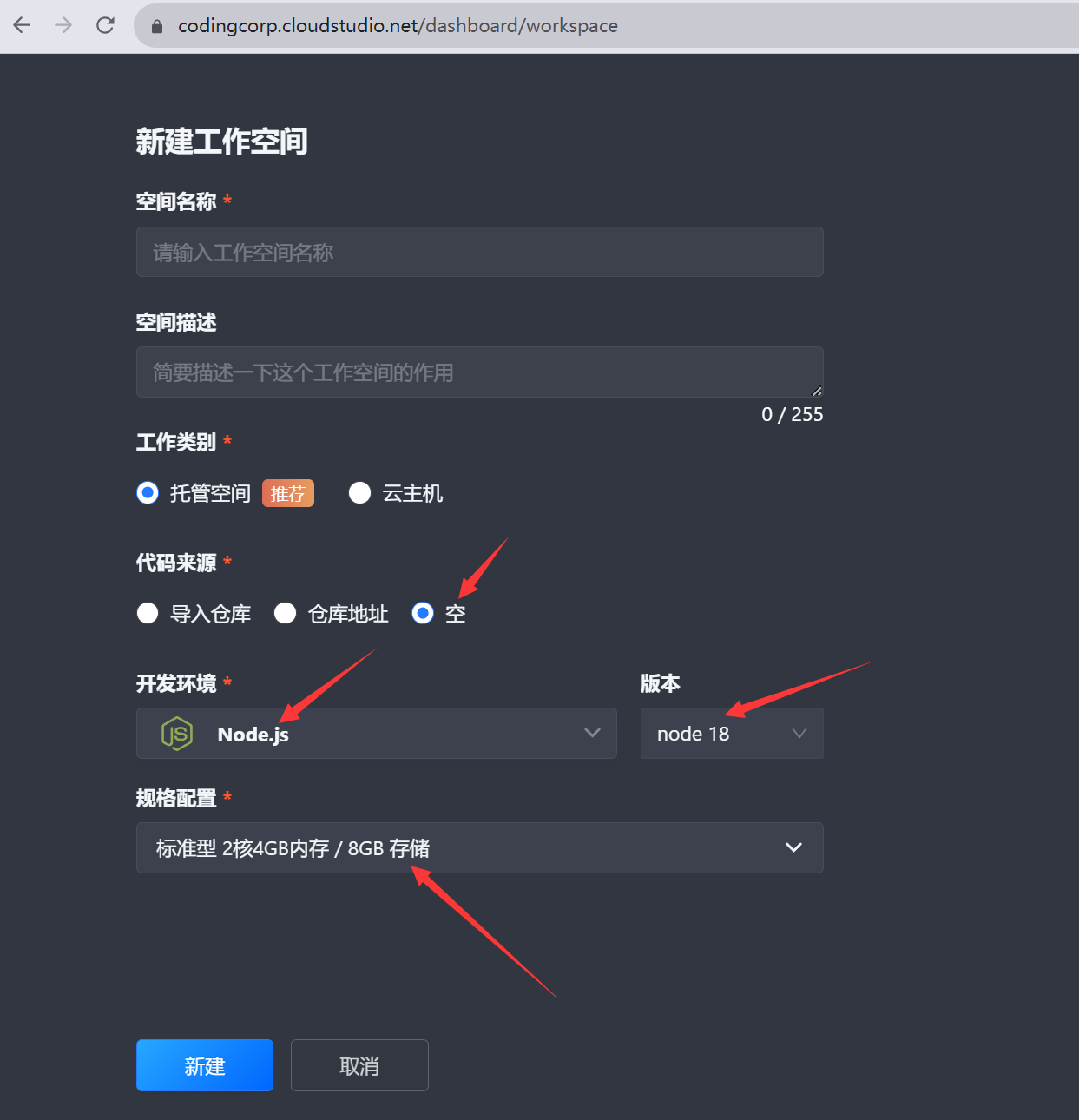
五、使用腾讯云Cloud Studio 快速云上开发
如果本地没有安装VSCode,也可以使用目前比较火的云IDE,选择打开腾讯云Cloud Studio,选择开发空间的手动创建并立即创建,自定义模板配置如下:
同样,将之前下载的压缩包上传到Cloud Studio开发空间的工作目录中,打开终端,输入解压命令unzip sd_api.zip,解压完成后,后面的步骤与第四章基本相同,即在终端窗口输入命令cd进入文件夹,然后输入npm install安装依赖包,等待依赖完成安装后就可以输入npm run dev启动Web项目了。
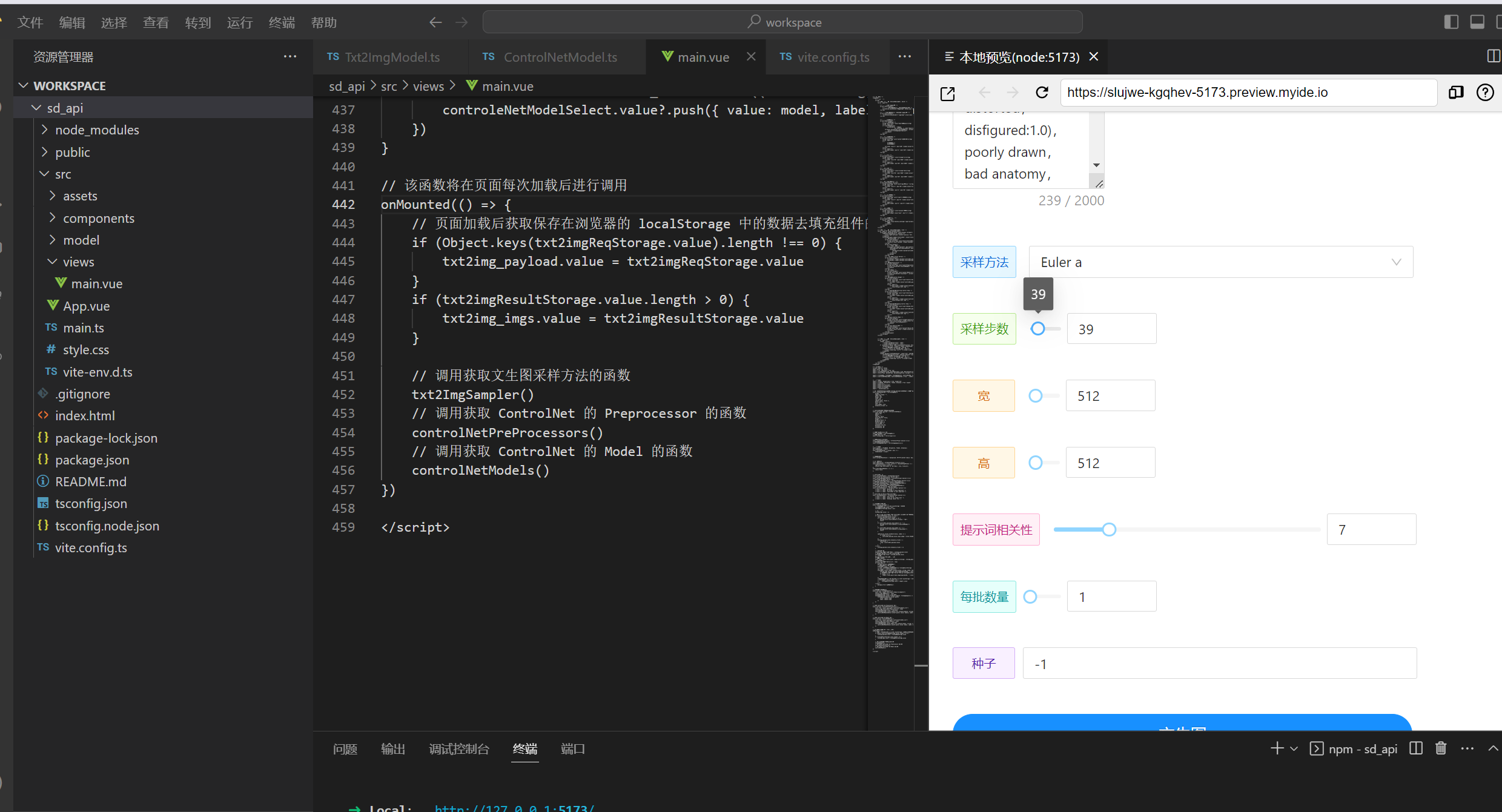
最后别忘了销毁HAI服务器和暂停腾讯云Cloud Studio使用空间。
六、高性能应用服务HAI使用感受
整体流程体验下来,HAI作为一款面向AI和科学计算的GPU应用服务产品,具有高性能计算能力、即插即用的云服务、灵活的配置选项、广泛的软件支持和安全保障等优点,是开发者进行复杂科学计算和AI模型训练的理想选择。
- 高性能计算能力:HAI基于腾讯云GPU云服务器底层算力,提供高性能计算能力,能够满足复杂科学计算和AI模型训练的需求。
- 即插即用的云服务: HAI提供即插即用的高性能云服务,无需复杂配置,开发者可以快速启动和部署GPU计算任务。
- 灵活的配置选项:HAI提供灵活的配置选项,用户可以根据自己的需求和预算选择不同的GPU实例类型和配置项等。
- 丰富的软件支持:HAI为客户提供了广泛的软件支持,包括流行的GPU应用程序和开发框架,如TensorFlow, PyTorch等,可以方便用户进行AI模型的训练和部署。
- 安全保障:腾讯云拥有高水准的安全防护机制和服务,保障用户的数据和计算任务的安全可靠。

【腾讯云HAI域探秘】活动目前正在进行中,本次活动是由腾讯云和CSDN联合推出的开发者技术实践活动,活动将通过技术交流直播、动手实验、有奖征文等形式,带您深入沉浸式体验腾讯云高性能应用服务HAI。在本次活动中,只要完成各个环节任务,不仅可以参与AIGC创作抽奖、优秀博文的评选,还可以获取相应的积分,参加最终的积分排行榜,获取丰厚的活动礼品。

最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 个人主页:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
另外,我们已经建立了微信T2I学习交流群,如果你也是T2I方面的爱好者或研究者可以私信我加入。