上一节我讲了冒泡排序、插入排序、选择排序这三种排序算法,它们的时间复杂度都是O(n2),比较高,适合小规模数据的排序。这里会介绍两种时间复杂度为O(nlogn)的排序算法,归并排序和快速排序。这两种排序算法适合大规模的数据排序,比上一节讲的那三种排序算法要更常用。
归并排序和快速排序都用到了分治思想,非常巧妙。乃至于,我们可以借鉴这个思想,来解决非排序的问题,比如:如何在O(n)的时间复杂度内查找一个无序数组中的第K大元素? 这就要用到我们今天要讲的内容。
归并排序的原理
我们先来看归并排序(Merge Sort)。
归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
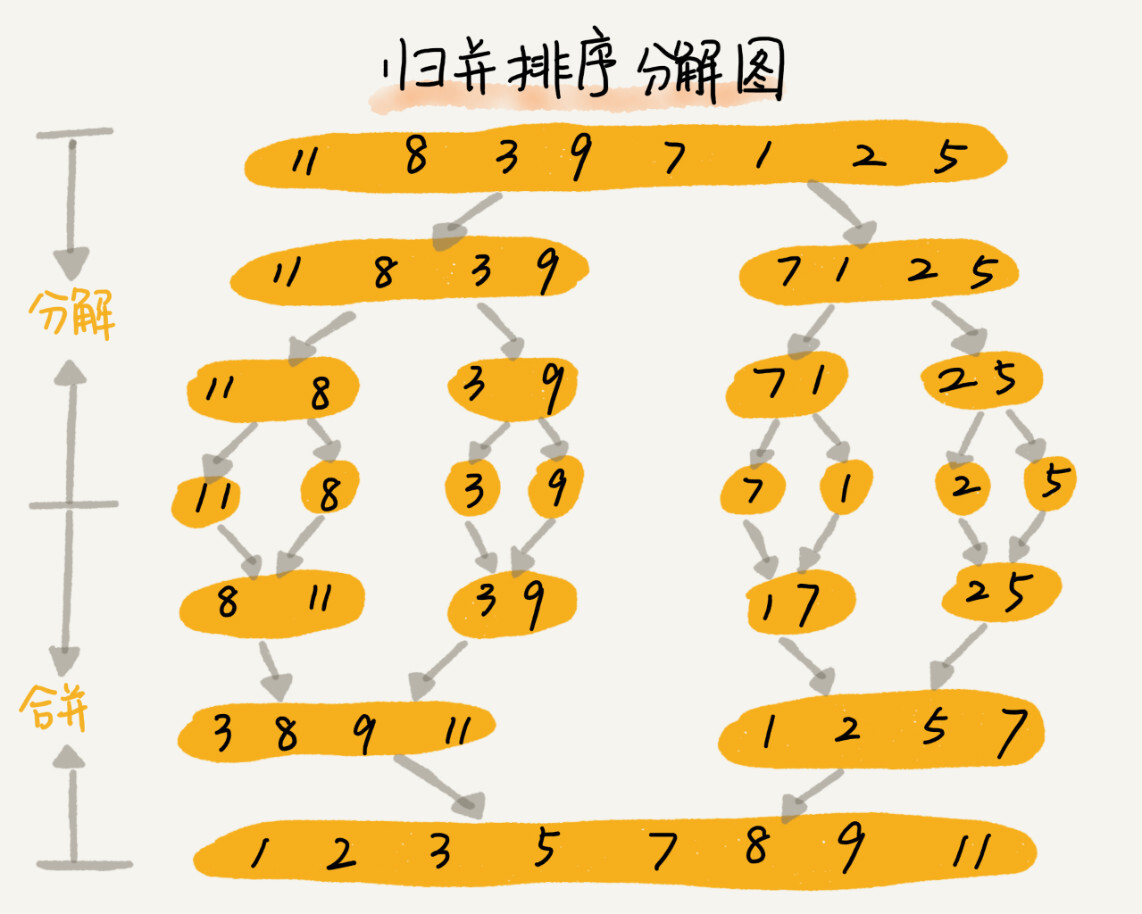
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
从我刚才的描述,你有没有感觉到,分治思想跟我们前面讲的递归思想很像。是的,分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。分治算法的思想我后面会有专门的一节来讲,现在不展开讨论,我们今天的重点还是排序算法。
前面我通过举例让你对归并有了一个感性的认识,又告诉你,归并排序用的是分治思想,可以用递归来实现。我们现在就来看看如何用递归代码来实现归并排序。
写递归代码的技巧就是,分析得出递推公式,然后找到终止条件,最后将递推公式翻译成递归代码。所以,要想写出归并排序的代码,我们先写出归并排序的递推公式。
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解
我来解释一下这个递推公式。
merge_sort(p…r)表示,给下标从p到r之间的数组排序。我们将这个排序问题转化为了两个子问题,merge_sort(p…q)和merge_sort(q+1…r),其中下标q等于p和r的中间位置,也就是(p+r)/2。当下标从p到q和从q+1到r这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从p到r之间的数据就也排好序了。
有了递推公式,转化成代码就简单多了。为了阅读方便,我这里只给出伪代码,你可以翻译成你熟悉的编程语言。
// 归并排序算法, A是数组,n表示数组大小
merge_sort(A, n) {
merge_sort_c(A, 0, n-1)
}
// 递归调用函数
merge_sort_c(A, p, r) {
// 递归终止条件
if p >= r then return
// 取p到r之间的中间位置q
q = (p+r) / 2
// 分治递归
merge_sort_c(A, p, q)
merge_sort_c(A, q+1, r)
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}
你可能已经发现了,merge(A[p...r], A[p...q], A[q+1...r])这个函数的作用就是,将已经有序的A[p...q]和A[q+1....r]合并成一个有序的数组,并且放入A[p....r]。那这个过程具体该如何做呢?
如图所示,我们申请一个临时数组tmp,大小与A[p...r]相同。我们用两个游标i和j,分别指向A[p...q]和A[q+1...r]的第一个元素。比较这两个元素A[i]和A[j],如果A[i]<=A[j],我们就把A[i]放入到临时数组tmp,并且i后移一位,否则将A[j]放入到数组tmp,j后移一位。
继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组tmp中的数据拷贝到原数组A[p...r]中。