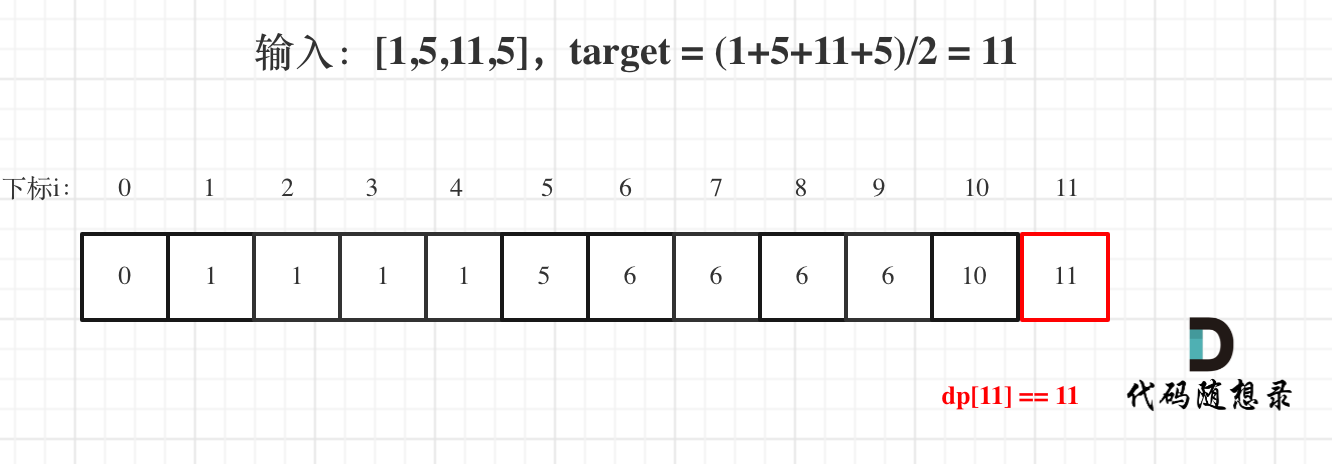
前两节中,着重分析了几种常用排序算法的原理、时间复杂度、空间复杂度、稳定性等。这节,将讲三种时间复杂度是O(n)的排序算法:桶排序、计数排序、基数排序。因为这些排序算法的时间复杂度是线性的,所以我们把这类排序算法叫作线性排序(Linear sort)。之所以能做到线性的时间复杂度,主要原因是,这三个算法是非基于比较的排序算法,都不涉及元素之间的比较操作。
这几种排序算法理解起来都不难,时间、空间复杂度分析起来也很简单,但是对要排序的数据要求很苛刻,所以我们今天的学习重点是掌握这些排序算法的适用场景。
按照惯例,我先给你出一道思考题:如何根据年龄给100万用户排序? 你可能会说,我用上一节课讲的归并、快排就可以搞定啊!是的,它们也可以完成功能,但是时间复杂度最低也是O(nlogn)。有没有更快的排序方法呢?让我们一起进入今天的内容!
桶排序(Bucket sort)
首先,我们来看桶排序。桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

桶排序的时间复杂度为什么是O(n)呢?我们一块儿来分析一下。
如果要排序的数据有n个,我们把它们均匀地划分到m个桶内,每个桶里就有k=n/m个元素。每个桶内部使用快速排序,时间复杂度为O(k * logk)。m个桶排序的时间复杂度就是O(m * k * logk),因为k=n/m,所以整个桶排序的时间复杂度就是O(n*log(n/m))。当桶的个数m接近数据个数n时,log(n/m)就是一个非常小的常量,这个时候桶排序的时间复杂度接近O(n)。
桶排序看起来很优秀,那它是不是可以替代我们之前讲的排序算法呢?
答案当然是否定的。为了让你轻松理解桶排序的核心思想,我刚才做了很多假设。实际上,桶排序对要排序数据的要求是非常苛刻的。
首先,要排序的数据需要很容易就能划分成m个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为O(nlogn)的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
比如说我们有10GB的订单数据,我们希望按订单金额(假设金额都是正整数)进行排序,但是我们的内存有限,只有几百MB,没办法一次性把10GB的数据都加载到内存中。这个时候该怎么办呢?