A Spatial–Spectral Dual-Optimization Model-Driven Deep Network for Hyperspectral and Multispectral Image Fusion
(一种用于高光谱与多光谱图像融合的空间-光谱双优化模型驱动深度网络)
深度学习,特别是卷积神经网络(CNN),在多光谱(MS)和高光谱(HS)图像融合(MS/HS融合)任务中显示出非常有前途的结果。大多数现有的CNN方法都是基于“黑盒”模型,这些模型不是专门为MS/HS融合设计的,这在很大程度上忽略了观察到的HS和MS图像所明显拥有的先验信息,并且缺乏清晰的可解释性,从而留下了进一步改进的空间。在本文中,我们提出了一种可解释的网络,称为空间-光谱双重优化模型驱动的深度网络( S 2 S^{2} S2DMDN),它将MS/HS融合的内在生成机制嵌入到网络中。该算法有两个主要特点:1)将输入MS和HS图像明显具有的空间先验和光谱先验在网络架构中进行显式编码; 2)将迭代的空间-光谱双重优化算法展开为模型驱动的深度网络。该方法的优点是网络具有良好的可解释性和泛化能力,融合后的图像语义更丰富,空间精度更高。
INTRODUCTION
超光谱(HS)传感器可以在数百个连续光谱带中捕获同一场景的图像。因此,HS图像已广泛用于许多应用中,包括分类和变化检测。然而,由于光学成像系统的限制,空间和光谱分辨率之间存在不可避免的折衷。虽然HS传感器捕获了丰富的光谱信息,但HS图像的空间分辨率远低于多光谱(MS)图像。HS图像空间分辨率的不足限制了其应用领域。在图像增强中,通常考虑利用附加的异质图像生成高分辨率图像。特别地,如图1所示,将低分辨率HS(LR-HS)图像与高分辨率MS(HR-MS)图像融合以重建高分辨率HS(HR-HS)图像,称为MS/HS融合,近年来获得了很多关注以提高应用质量。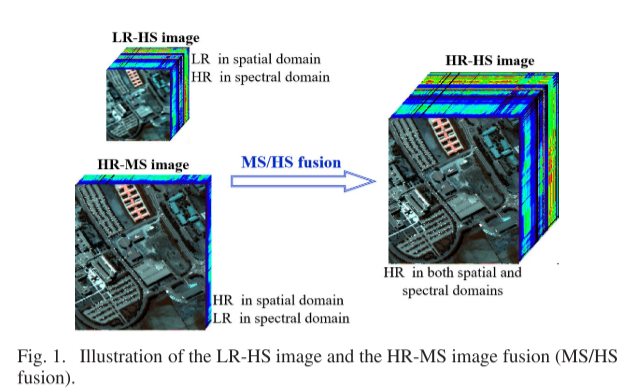
目前,各种MS/HS融合方法已被提出,并取得了显着的性能。基于模型的方法将MS/HS融合问题表示为一个不适定的逆问题,该逆问题基于线性观测模型在先验约束下最小化目标函数。由于基于模型的方法的性能取决于手动预先指定的先验项,这些方法通常实现有限的性能。在过去的几年里,基于深度学习的方法已经被引入来解决各种计算机视觉任务,包括MS/HS融合。由于深度学习的强大学习能力,学习从输入HR-MS和LR-HS图像到目标HR-HS图像的映射的基于学习的方法比基于模型的方法获得更好的空间-光谱质量。然而,大多数基于深度学习的方法不是专门为MS/HS融合设计的,并且缺乏对MS/HS融合任务的特定可解释性(即,黑盒子设计)。这些黑盒深度学习模型由工具包中的现有组件组成,缺乏透明度。它们也忽略了HS和MS图像的观测模型和先验知识,无法直观地观察网络的内部结构,导致无法直观地分析MS/HS融合的实现机制,泛化能力有限。
为了解决这个问题,我们提出了一种新的空间-光谱双重优化模型驱动的深度网络(
S
2
S^{2}
S2DMDN)用于MS/HS融合。提出的S2 DMDN具有透明的设计,并以可解释的方式解决了MS/HS融合问题。详细地说,我们首先将观测模型转换为空间-光谱双重优化问题,其中假设目标HR-HS图像,其可以通过增强上采样的LR-HS图像的空间信息和校正HR-MS图像的光谱信息来近似。采用半二次分裂half-quadratic splitting法,给出了将每个优化函数转化为两个子问题的迭代算法。然后,我们构建了一个包括光谱信息和空间细节增强分支的两分支前馈网络,来展示所提出的双重优化迭代算法。每个分支包含去噪模块和重构模块,以模拟迭代算法的流程。通过端到端的训练,得到两个分支结果的加权和,以生成高空间和高光谱保真度的目标HR-HS图像。
贡献
1)提出了一种基于深度学习和基于模型的MS/HS融合方法,具有良好的可解释性和泛化能力。
2)基于观测模型以及HS和MS图像的空间和光谱先验约束,提出的空间-光谱双重优化策略将MS/HS融合转化为一个多任务问题,即融合图像的光谱分布应尽可能接近LR-HS图像,空间分布应尽可能与HR-MS图像一致,为MS/HS融合网络提供了可靠的数学理论指导。
3)我们构造了一个空间细节更新分支和一个光谱信息更新分支来展开所提出的空间-光谱双重优化算法。构造的空间细节更新分支由新的高低频独立(HLI)去噪模块和基于空间细节注入的重建模块组成,设计的光谱信息更新分支由HLI去噪模块和基于光谱校正的重建模块组成,可实现可设计、可解释、可预测的深度MS/HS融合学习。
RELATED WORK
Traditional Methods
HS全色锐化是MS/HS融合的一种特殊情况,已被广泛发展以借助于全色(PAN)图像的空间细节来生成HR-HS图像。分量替换(CS)和多分辨率分析(MRA)是两类具有代表性的方法。CS方法是指在合适的域中用PAN图像替换变换的HS图像的某些分量的方法,包括主成分分析(PCA),强度-色调-饱和度(IHS)变换,Gram-Schmidt(GS)和GS自适应(GSA)。MRA方法以多分辨率方式将PAN图像中缺失的空间细节注入到LR-HS图像中,典型的方法是基于平滑滤波器的强度调制(SFIM)、广义拉普拉斯金字塔(GLP)和加性小波亮度比例(AWLP)。研究的MS/HS融合任务是高度相关的HS泛锐化问题,因为HS 泛锐化问题可以被视为一个特殊的情况下,MS/HS融合。将HS泛锐化扩展到MS/HS融合问题的一种常用方法是将其视为多个泛锐化子问题,其中HS图像被划分为若干区域,MS图像的每个波段充当PAN图像的角色,与HS图像逐区域融合。然而,这些方法的性能需要改进,因为目标HS图像遭受严重的光谱失真。
基于模型的方法,包括贝叶斯,矩阵分解和张量分解方法,近年来在解决MS/HS融合问题方面受到了广泛关注。基于模型的方法将MS/HS融合任务视为优化问题,其中先验正则化项的选择对方法的性能至关重要。贝叶斯方法依赖于推断HR-HS图像与输入HR-MS和LR-HS图像的联合特征的合适的统计模型。在MS/HS融合任务中引入随机混合模型的贝叶斯方法后,人们开展了各种研究来挖掘更多的内在特征。矩阵分解方法学习信号子空间的字典,并利用优化工具来产生因子分解。耦合非负矩阵分解(CNMF)是矩阵分解的典型代表方法,交替分解HR-MS和LR-HS图像,以获得构建HR-HS图像的非负基。由于二阶矩阵分解破坏了HS图像的空间信息,基于高阶张量的方法引起了学者们的关注。Li等人提出了一种耦合稀疏张量因子分解(CSTF),它引入了张量因子分解,将问题重新表述为稀疏核心张量和字典的估计。Bu等人提出了一种新的图拉普拉斯引导的耦合张量分解模型,以利用HS图像融合的内在全局空间-光谱信息,其巧妙地保留了HS图像的内在空间-光谱信息。Xue等人提出了一种基于稀疏性的多层张量分解方法,用于低秩张量完备化,可以挖掘隐藏在张量中的隐含稀疏性属性。然而,基于模型的方法依赖于参数的选择,并且融合性能对所选择的参数敏感。此外,基于模型的方法具有高计算复杂度。
Deep Learning-Based Methods
近年来,深度学习,特别是卷积神经网络(CNN),在超分辨率(SR)、图像融合、图像去噪、分类等图像处理任务中表现出良好的性能。Gao等人提出了一种用于湿地分类的深度特征交互网络(DFINet),该网络设计了深度交叉注意模块,从HS和MS图像中提取自相关和互相关(CC),结合互补信息进行分类。Li等人提出了一种用于多源遥感数据联合分类的非对称特征融合网络(AsyFFNet)。在过去的几年里,已经开发了许多基于CNN的SR模型。Deng等人提出了超分辨率CNN(SRCNN),首次将其引入到图像恢复任务中。受此启发,许多不同的网络体系结构被用来解决MS/HS融合问题。全色锐化CNN(PNN)遵循SRCNN的基本思路,即将LR-MS图像与PAN图像作为输入进行堆叠。变体架构,如残差网络,生成对抗网络(GAN)和3-D CNN框架,也被开发来提高泛锐化的性能。这些变体架构也被开发用于改善MS/HS融合的性能。由于CNN强大的特征提取能力,基于CNN的方法可以更好地拟合HR-MS图像,LR-HS图像和HRHS图像之间的非线性关系,与传统方法相比,取得了很好的效果。然而,这些基于深度学习的方法有一个明显的缺点,即“黑盒”设计往往导致泛化能力差。此外,这些基于深度学习的方法忽略了观察到的HS和MS图像明显具有的先验知识,这导致泛化能力差。为了解决这个问题,Yang等人提出了一种深度先验正则化融合模型,该模型利用多尺度非局部注意力机制来利用HSI的自相似先验。Wei等人提出了一种递归残差结构,用于在深度展开网络中实现正则化约束。然而,他们设计了不同的结构来实现正则化约束,而没有进一步讨论MS/HS融合模型。Xie等人提出了一种基于HS图像的观测模型和低秩先验的新型HS/MS融合模型,并将所提出的模型展开为深度网络。本文基于观测模型的方法只考虑了HS图像的先验信息,而忽略了MS图像的先验信息,有进一步改进的空间。
PROPOSED MODEL-DRIVEN MS/HS FUSION ALGORITHM
Model Formulation
我们首先介绍了本文中使用的符号,然后再介绍所提出的方法。这篇文章,矩阵和向量分别用粗体字表示。符号X ∈
R
L
×
N
R^{L×N}
RL×N是指具有L个光谱带和每个带中的N个像素的HR-HS图像。Y ∈
R
l
×
N
R^{l×N}
Rl×N和Z ∈
R
L
×
n
R^{L×n}
RL×n分别表示观察到的HR-MS和LR-HS图像,其中l表示HR-MS图像中的谱带数量,n表示LR-HS图像的像素。在数学上,HR-MS图像是HR-HS图像的光谱下采样版本,并且LR-HS图像是HR-HS图像的空间模糊下采样版本。因此,HR-MS图像、LR-HS图像和HR-HS图像之间的线性关系可以通过以下观察模型来公式化
空间和光谱退化函数B和R在实际应用中可能不可用。因此,本文中不知道B和R。NM和NH分别是来自HR-MS和LR-HS传感器的噪声,其通常被假定为高斯噪声。
MS/HS融合的目标是在保持HR-MS图像的空间信息的同时,保留LR-HS的光谱信息。为了实现这一目标,我们在数学上将其表述为多任务问题,其中融合图像的光谱分布应尽可能与LR-HS图像的光谱分布一致,并且其空间分布应尽可能接近HRMS图像的空间分布。更具体地,我们假设可以通过将空间细节注入到上采样的LR-HS图像中或对HR-MS图像执行谱维SR来获得目标图像。一方面,我们将丢失的空间细节注入到空间上采样的HS图像中以获得目标HR-HS图像。另一方面,我们对HR-MS图像进行光谱SR和光谱校正,以获得目标HR-HS图像。
在本文中,令^Z表示在空间维度上需要估计的缺失的空间细节, ^Y表示在光谱维度上需要校正的光谱信息。因此,我们通过以下新设计的双重优化公式来解决这个多任务问题:
同时,引入残差学习优化目标函数也可以提高计算效率。通过(1)从观察到的HR-MS和LR-HS图像恢复所需的HR-HS是不适定的逆问题。一般来说,图像先验编码作为正则化可以提供高质量的解决方案。特别地,与传统的对HR-HS图像进行正则化的方法不同,我们在两个目标优化方程中对待估计的空间偏差和光谱偏差进行正则化。这是因为期望的HR-HS图像的空间细节主要来源于观测的HR-MS图像,并且期望的HR-HS图像的光谱信息应尽可能与LR-HS图像的光谱信息一致。因此,该设置有利于输入LR-HS图像的光谱信息和HR-MS中包含的空间细节的完全保留。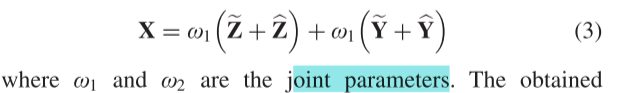
通过求解空间-光谱双重优化问题,得到的目标HR-HS图像在空间信息和光谱信息之间取得了平衡。
Model Optimization
我们采用半二次分裂法求解(2)。以求解(2)中的第一目标函数为例,引入辅助分裂变量U1,第一目标函数可写为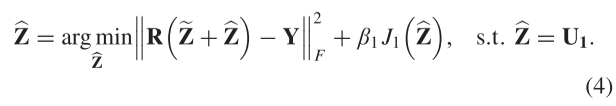
等式(4)是一个同等约束的优化问题,可以转化为以下的无约束优化问题:
 其中λ2是惩罚参数,U2是引入的辅助分裂变量,其可以由以下等式给出:
其中λ2是惩罚参数,U2是引入的辅助分裂变量,其可以由以下等式给出: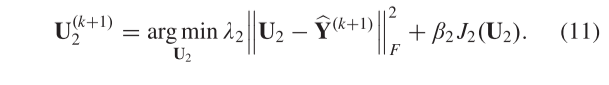
传统的基于模型的方法根据先验知识设计正则项,以获得高质量的解。他们的表现在很大程度上取决于先前的假设。然而,对于不同的HS图像,很难选择合适的先验。近年来,数据驱动的深度表示先验被证明具有自适应拟合先验的优势,并在各种计算机视觉任务中取得了巨大的成功。因此,本研究采用细胞神经网络从训练数据中学习先验知识来定义正则化项,从而解决反问题,而不是使用人工预先指定的先验知识。具体地说,我们通过将(9)和(10)的更新操作展开为卷积层,设计了用于MS/HS融合的可解释的CNN。与从人工预先指定的正则化项导出近邻运算的传统方法不同,该方法中的展开运算可以被实现为卷积层,并且可以从训练数据中端到端地隐式学习。
PROPOSED MODEL-DRIVEN CONVOLUTIONAL NETWORK

如算法1所示,提出了一种通用的MS/HS融合算法,该算法需要多次迭代才能收敛,计算量很大。为了解决这个问题,我们将算法1展开到一个称为
S
2
S^{2}
S2DMDN的深度网络中。根据第II-A节中的两个目标函数,
S
2
S^{2}
S2DMDN采用两个分支来同时更新光谱信息和空间细节。每个分支有K个阶段,展开阶段数与算法1中的迭代数相对应。两个分支的每次迭代的输出用于更新空间信息并校正前一次迭代的输出的光谱信息。采用参数可学习的联合判别策略生成目标HR-HS图像。该网络以端到端的方式进行训练,以便可以联合优化两个分支的参数。所提出的
S
2
S^{2}
S2DMDN的更多细节如下所示。
Spatial Detail Update
根据(7)和(9),用于更新LR-HS图像的空间上采样版本的空间信息的空间偏差Z可以通过交替求解关于^
Z
(
K
)
Z^{(K)}
Z(K)和
U
(
K
)
U^{(K)}
U(K)1的两个子问题来获得。
U
(
K
)
U^{(K)}
U(K)1的求解过程可以看作是一个去噪问题。这项研究开发了一种新的端到端金字塔去噪模块,它允许网络在两个独立的分支中处理高频和低频分量。好处是重建的结果在空间上更精确,在语义上也更丰富。针对^
Z
(
K
)
Z^{(K)}
Z(K)的求解问题,设计了基于细节注入的空间重建模块,所有操作均由卷积层实现。总体架构如图2(a)所示,它执行K次迭代。我们加强了每次迭代共享相同参数的网络,以减少过拟合的影响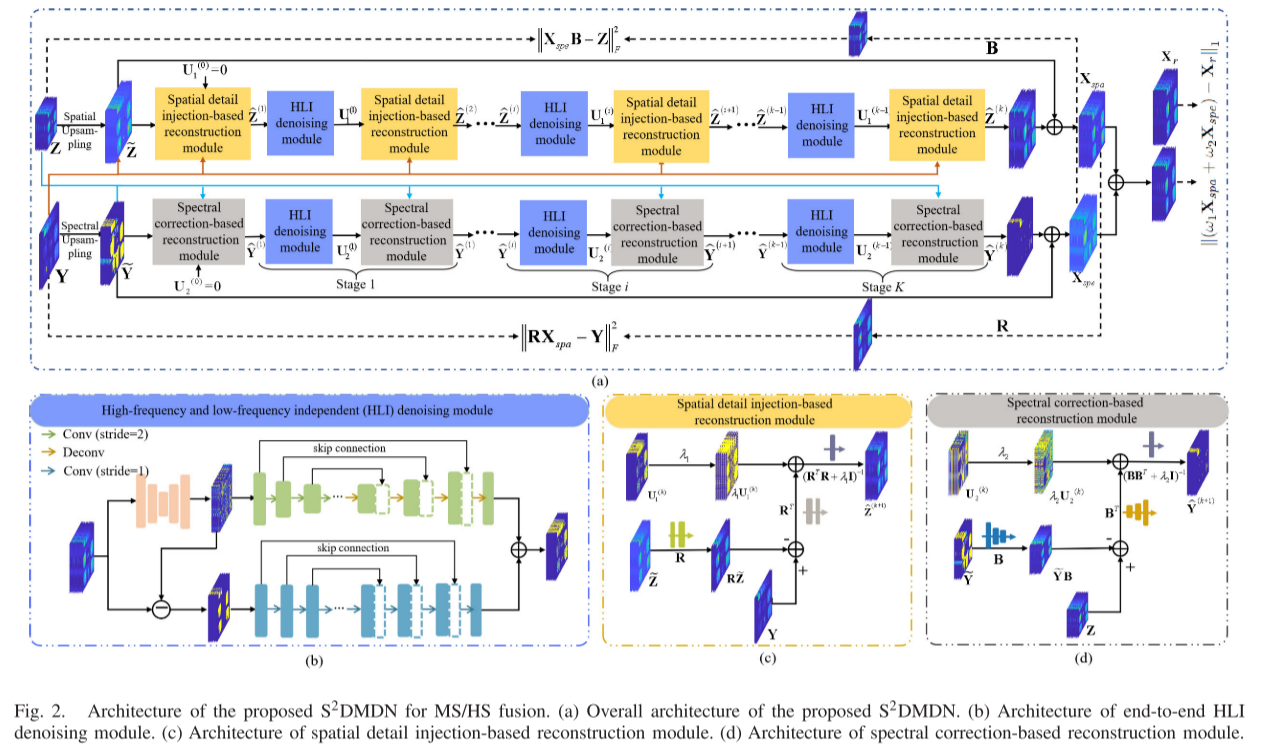
-
End-to-End HLI Denoising Module: 根据贝叶斯概率,(7)相当于通过高斯去噪器对图像^ Z ( K + 1 ) Z^{(K+1)} Z(K+1)进行去噪。传统的去噪方法,如全变分(TV),K-SVD和BM 3D,可能会产生伪影并过度平滑不规则结构。由此,深度学习编码器-解码器去噪网络(U-net)应运而生,其目的是从紧凑的特征中重构与原始输入一样接近的输出,已被广泛用作去噪模型。然而,编码器-解码器架构中包含的最大池化和上采样操作可能会导致图像边缘和纹理等低级信息的丢失,这些信息对去噪任务至关重要。为了解决这个问题,我们提出了一个端到端的HLI去噪模块,它将成熟的拉普拉斯金字塔理论引入神经网络。如图2(b)所示,在第k阶段,我们首先将输入图像^ Z ( K ) Z^{(K)} Z(K)分解为拉普拉斯金字塔,该拉普拉斯金字塔由高频和低频分量组成。然后,我们为每个组件独立地构建两个具有相似结构的U-Net,以预测相应的干净输出 U ( K ) U^{(K)} U(K)1。高频和低频分量被分开处理,以使输出在语义上更丰富,在空间上更精确。此外,每个U-Net都采用级联学习来减少参数。
具体地说,我们使用卷积和反卷积运算来实现拉普拉斯金字塔的生成过程。在给定输入Z(K)的情况下,采用步长为2的3×3卷积层来降低特征图的空间维度,然后利用反卷积层对尺度因子为2的紧致特征进行上采样,得到输入^ Z ( K ) Z^{(K)} Z(K)L的低频分量,输入^ Z ( K ) Z^{(K)} Z(K)H的高频分量由输入^ Z ( K ) Z^{(K)} Z(K)减去低频分量^ Z ( K ) Z^{(K)} Z(K)L得到。这个过程可以表示为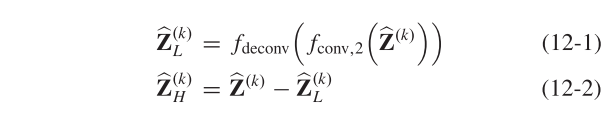
其中fdeconv(·)表示去卷积层,fconv,2(·)表示缩放因子为2的卷积层。在获得输入的高频和低频分量之后,利用U-Net同时产生无噪声的低频和高频分量。对于低频分量,编码器包含3 × 3卷积层,步幅设置为2以进行下采样。在解码器中,采用3 × 3的解卷积层来重构各个分量的高质量输入。在编码器中加入跳跃连接,将编码器中的低层特征传递到解码器中相应的尺度特征上,充分利用了各尺度特征的信息。用于高频分量的U-Net具有与用于低频分量的U-网络类似的架构,除了卷积层和去卷积层的步幅都被设置为1以保持特征的尺度恒定。然后,可以通过将无噪声的高频分量 U ( K ) U^{(K)} U(K)1H和低频分量 U ( K ) U^{(K)} U(K)1L相加来获得更新的中间结果 U ( K ) U^{(K)} U(K)1,其被表示为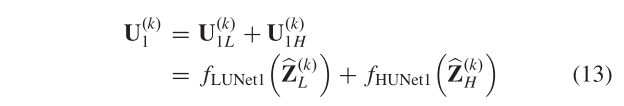
其中,fLUNet1(·)表示用于在空间细节更新中获得输入^ Z ( K ) Z^{(K)} Z(K)L的无噪声低频分量的U-Net,并且fLUNet1(·)的网络结构可以表示为
-
Spatial Detail Injection-Based Reconstruction Module:如(9)中所述,基于空间细节注入的重构模块将中间结果 U ( K ) U^{(K)} U(K)1作为输入,并计算更新的^ Z ( K + 1 ) Z^{(K+1)} Z(K+1)。基于空间细节注入的重建模块的架构在图2(c)中示出,其被设计为利用深度网络执行(9)。输入LR-HS图像Z首先经过双三次插值方法以生成具有与HR-MS图像相同尺度的空间上采样的HS图像~Z。然后,我们用一个1 × 1卷积层来近似R,它在频谱上下采样 ~Z以减少频谱维数。输入HR-MS图像Y从光谱下采样的 ~Z中减去,并且通过利用1 × 1卷积层进行光谱上采样来执行转置矩阵 R T R^{T} RT。然后将频谱上采样的结果与由可学习参数λ1加权的中间结果 U ( K ) U^{(K)} U(K)1相加。在网络中,计算( R T R^{T} RTR + λ1I)−1 ∈ R L × L R^{L×L} RL×L是困难的,它与谱退化矩阵R有关。因此,运算( R T R^{T} RTR + λ1I)−1 ∈ R L × L R^{L×L} RL×L被一个可学习的矩阵所取代,这可以通过1 × 1卷积层有效地实现。
在K次迭代之后,我们可以近似地生成在第K次迭代中更新的空间细节^ Z ( K ) Z^{(K)} Z(K)。空间细节增强分支Xspa的第k次迭代的输出可以通过将更新的空间细节注入上采样的LR-HS图像来获得,其被表示为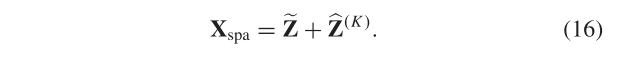
Spectral Information Update
类似于空间细节更新,迭代优化方程(10)和(11)被展开为一系列网络实现,包括HLI去噪模块和基于频谱校正的重建模块。展开阶段的总数等于算法1中的迭代的总数。在频谱更新过程中,HLI去噪模块还分别处理输入的高频分量和低频分量,并且基于频谱校正的重建模块使用展开深度网络来执行(10)中描述的计算过程。图2(a)示出了频谱信息更新分支的细节,并且网络的参数在K次迭代之间共享。
- HLI Denoising Module:HLI去噪模块首先将输入的^
Y
(
K
)
Y^{(K)}
Y(K)分解为低频分量和高频分量。具体地说,以^
Y
(
K
)
Y^{(K)}
Y(K)为输入,输入^
Y
(
K
)
Y^{(K)}
Y(K)L的低频分量可由3×3个步长为2的卷积层和反卷积层进行上采样得到。然后,通过从输入中去除低频分量来获得输入的高频分量^
Y
(
K
)
Y^{(K)}
Y(K)H。在光谱信息校正分支中,采用与空间细节增强分支去噪模块高度一致的结构来重构无噪声的高频和低频分量
U
(
K
)
U^{(K)}
U(K)2H和
U
(
K
)
U^{(K)}
U(K)2L,并通过融合
U
(
K
)
U^{(K)}
U(K)2H和
U
(
K
)
U^{(K)}
U(K)2L来更新中间结果
U
(
K
)
U^{(K)}
U(K)2。光谱信息更新分支中的HLI去噪模块的这个过程可以表示为

- Spectral Correction-Based Reconstruction Module:
为了产生更新的估计^ Y ( K + 1 ) Y^{(K+1)} Y(K+1),我们设计了一个基于深谱校正的重建网络来执行(10)中的运算。如图2(D)所示,基于频谱校正的重建模块以 U ( K ) U^{(K)} U(K)2、Y和Z为输入,并利用卷积层来近似^ Y ( K + 1 ) Y^{(K+1)} Y(K+1)。我们提出用1×1卷积层和两个3×3卷积层的近似B实现MS图像的光谱上采样,空间下采样的步长为2。在从LR-HS图像Z减去空间下采样的Y之后,由包含两个反卷积层的子网络执行表示空间上采样操作的转置矩阵BT。然后将结果与中间结果$U^{(K)}$2相加,中间结果$U^{(K)}$2由可学习参数λ2~加权。最后,通过使用1×1卷积层重建^ Y ( K + 1 ) Y^{(K+1)} Y(K+1)来执行(BBT+λ2I)-1层。
在第k次迭代中更新的频谱信息^ Y ( K ) Y^{(K)} Y(K)用于校正前一次第(k-1)次迭代的频谱信息。光谱校正分支Xspe中的第K次迭代的输出通过下式获得: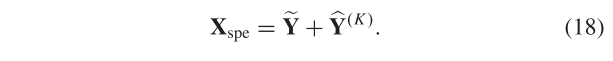
Spatial–Spectral Joint Loss Function
通常,MS/HS融合方法的性能受损失函数的影响很大。本文设计了一种空间-频谱联合损失函数,该函数既能减小融合后的HS图像与参考图像之间的差异,又能保证卷积层逼近有效的频谱和空间下采样矩阵。L2损失是基于深度学习的MS/HS融合任务中损失函数的主要选项。然而,L2损失函数优化的方法往往会丢失高频细节,导致感知效果不佳和纹理平滑。实验证明L1损失是一个更好的选择。L1损失可以更好地关注小错误,从而比L2损失实现进一步的改进。因此,我们通过计算(3)中所示的两个分支Xspa和Xspe的结果的加权和来获得重构HR-HS图像X,并且使重构HS图像和参考图像Xr之间的平均绝对误差(MAE)最小化。此外,为了更好地逼近(2)中的运算,我们进一步训练
S
2
S^{2}
S2 DMDN网络学习有效的空间退化矩阵B和光谱响应矩阵R,从而设计基于空间退化的损失和基于光谱退化的损失来约束公式(2)所示的空间-光谱双重优化模型。在μ1和μ2控制权衡的情况下,总空间-频谱联合损失函数被公式化为:





![[架构之路-251/创业之路-82]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 商业智能、决策支持系统、知识管理](https://img-blog.csdnimg.cn/5ea1150dabd8486295b0dd77167ed22e.png)