C++ 多线程之OpenMP并行编程使用详解
- 总结OpenMP使用详解
- 本文转载自:https://blog.csdn.net/AAAA202012/article/details/123665617?spm=1001.2014.3001.5506
1.总览
OpenMP(Open Multi-Processing)是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,通过线程实现并行化,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
OpenMP与Pthread有着许多本质不同:
- Pthread需要显式地明确每个线程的行为; OpenMP只需要简单的声明这块代码并行执行。
- 只要系统拥有Pthreads库,Pthreads程序就能够被任意的C编译器使用;除了拥有OpenMP还要求编译器支持某些操作。
- Pthreads提供了虚拟地编写任何可知线程行为的能力;OpenMP用于实现并行更加简单,但是很难对底层的线程交互进行编程。
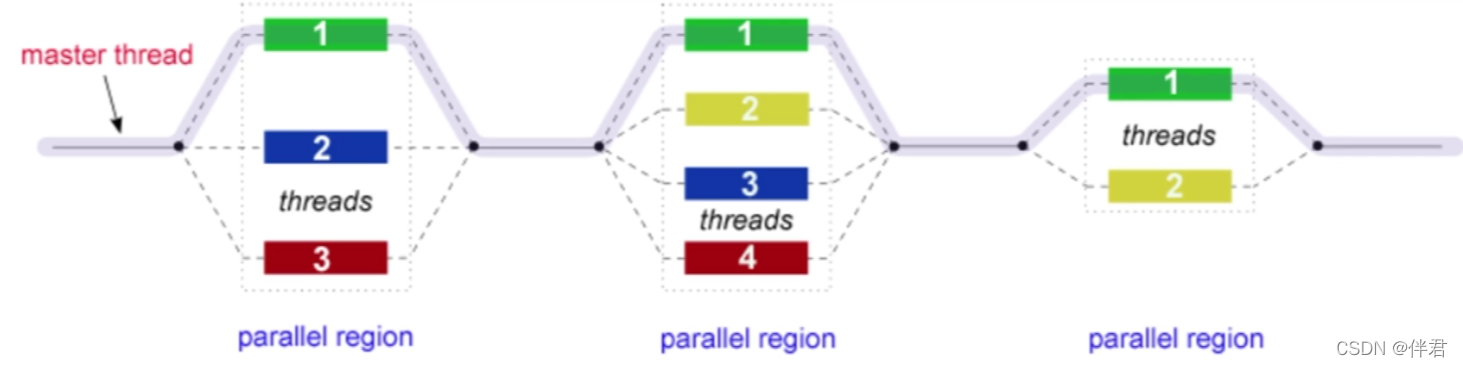
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
Fork(派生):主线程(master thread)创建一组并行化执行的线程;
Join(合并):当线程完成工作后,它们会进行同步与终止,只剩下master thread。
2.编译
使用gcc编译OpenMP程序,需要在后面包含-fopenmp选项;
在VS中启用OpenMP,在项目上右键 -> 属性 -> 配置属性 ->C/C++ -> 语言 -> OpenMP支持,选择“是”即可。
3.编译制导指令
编译制导指令以#pragma omp开始,后面根具体的功能指令,格式如:#pragma omp 指令[子句,[子句]…]。常用的功能指令如下:
- parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
- for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
- parallel for: parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
- sections:用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
- parallel sections:parallel和sections两个语句的结合,类似于parallel for;
- single:用在并行域内,表示一段只被单个线程执行的代码;
- critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
- flush:保证各个OpenMP线程的数据影像的一致性;
- barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
- atomic:用于指定一个数据操作需要原子性地完成;
- master:用于指定一段代码由主线程执行;
- threadprivate:用于指定一个或多个变量是线程专用;
相应的OpenMP子句为:
- private:指定一个或多个变量在每个线程中都有它自己的私有副本;
- firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
- lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
- reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
- nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
- num_threads:指定并行域内的线程的数目;
- schedule:指定for任务分担中的任务分配调度类型;
- shared:指定一个或多个变量为多个线程间的共享变量;
- ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
- copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
- copyin:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
- default:用来指定并行域内的变量的使用方式,缺省是shared。
>OpenMP parallel
parallel制导指令用来创建并行域,后边要跟一个大括号将要并行执行的代码放在一起
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
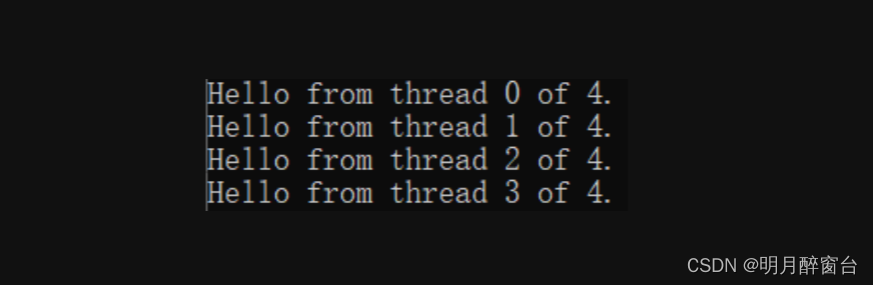
void hello(void) {
//返回线程号
int my_rank = omp_get_thread_num();
//返回当前并行区域中的线程数
int thread_count = omp_get_num_threads();
printf("Hello from thread %d of %d. \n", my_rank, thread_count);
}
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
//num_threads指定要用多少个线程来实现hello
#pragma omp parallel num_threads(thread_count)
{
hello();
}
return 0;
}
>OpenMP for
#pragma omp parallel for它告诉编译器,接下来的for循环,将会使用并行的方式执行,使用并行的时候需要满足以下四个需求:
- 在循环的迭代器必须是可计算的并且在执行前就需要确定迭代的次数;
- 在循环的代码块中不能包含break,return,exit;
- 在循环的代码块中不能使用goto跳出到循环外部;
- 迭代器只能够被for语句中的增量表达式所修改。
数据依赖性:在该循环中的计算依赖于一个或更多个先前的迭代结果。当存在这种状况时,需要格外注意,容易出现错误。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
double a[10], b[10];
for (int i = 0; i < 10; i++) {
a[i] = i;
b[i] = 10 - i;
}
double s[10];
#pragma omp parallel for num_threads(thread_count)
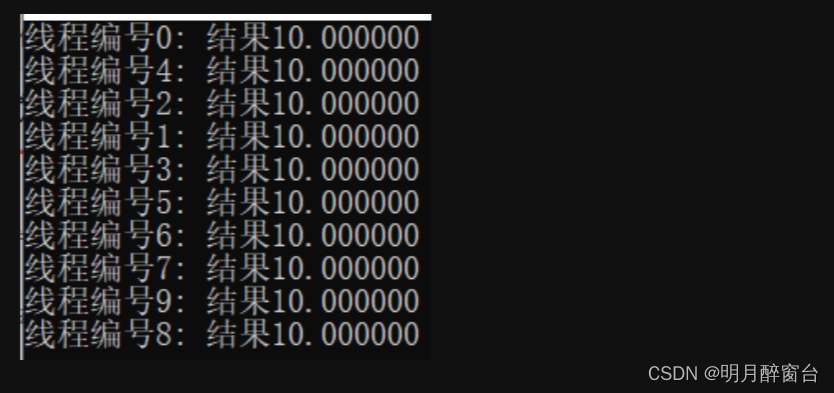
for (int i = 0; i < 10; i++){
s[i] = a[i] + b[i];
printf("线程编号%d: 结果%lf\n",omp_get_thread_num(), s[i]);
}
return 0;
}
>OpenMP private Variables
在OpenMP中,变量的作用域涉及在parallel块中能够访问该变量的线程集合。能够被线程组中所有线程访问的变量拥有共享作用域,而一个只能被单个线程访问的变量拥有私有作用域。
Private在#pragma中作为一个可选的,附加的选项,它能够直接的告诉编译器去使得共享变量作为每个线程中的私有变量。它的形式为 #pragma omp … private(< variable list >)
>>>private
关于private的信息:
- 每一个线程都是拥有独自的该变量的副本;
- 如果j被定义为私有变量,那么在for循环里面,所有的线程都不能访问其他j(尽管j是共享变量);
- 所有的线程都不会使用到先前的定义;
- 所有线程都不能给共享的j赋值;
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
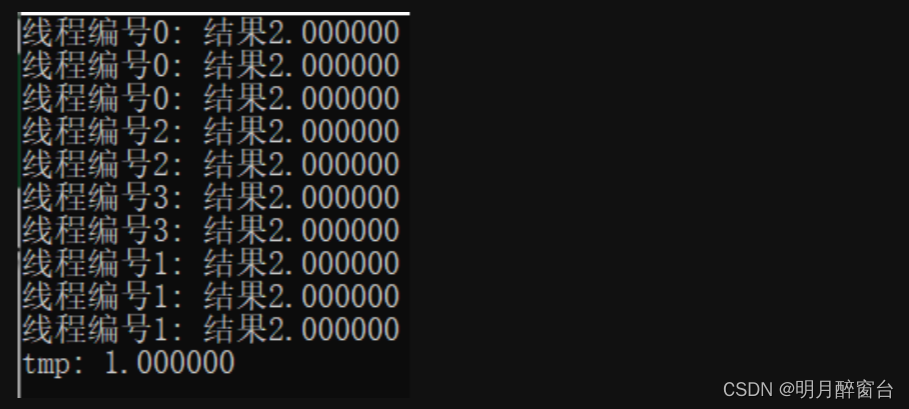
double tmp = 1.0f;
#pragma omp parallel for num_threads(thread_count) private(tmp)
for (int i = 0; i < 10; i++)
{
tmp = 2.0f;
printf("线程编号%d: 结果%lf\n", omp_get_thread_num(), tmp);
}
printf("tmp: %lf\n",tmp);
return 0;
}
>>>firstprivate
关于firstprivate的信息:
- firstprivate选项告诉编辑器私有变量在第一个循环会继承共享变量的值;
- 这个私有的变量只会在每个线程的第一个循环继承,而不会在每个循环中继承;
- 其使用方法于private几乎一致:#pragma omp parallel for firstprivate;
关于变量的拷贝:
- 如果数据是基础数据类型,如int,double等,会将数据进行直接拷贝;
- 如果变量是一个数组,它会拷贝一个对应的数据以及大小到私有内存中;
- 如果变量为指针,它会将变量指向的地址拷贝过去,指向相同地址;
- 如果变量是一个类的实例,它会调用对应的构造函数构造一个私有的变量。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
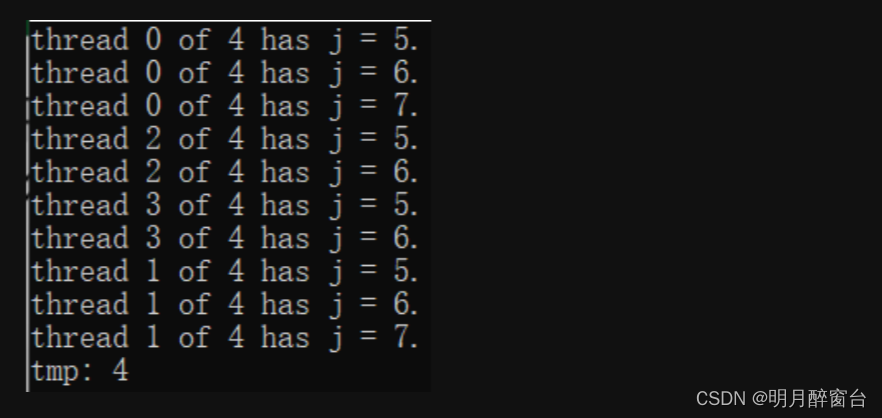
int thread_count = strtol(argv[1],NULL,10);
int j = 4;
#pragma omp parallel for num_threads(thread_count) firstprivate(j)
for (int i = 0; i < 10; i++)
{
j++;
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("thread %d of %d has j = %d.\n", my_rank,thread_count,j);
}
printf("tmp: %d\n",j);
return 0;
}
>>>lastprivate
关于lastprivate的信息:
- lastprivate选项告诉编辑器私有变量会在最后一个循环出去的时候,用私有变量的值替换掉我们共享变量的值;
- 当负责最后一个iteration的线程离开循环的时候,它会将该私有变量的值赋值给当前共享变量的值。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
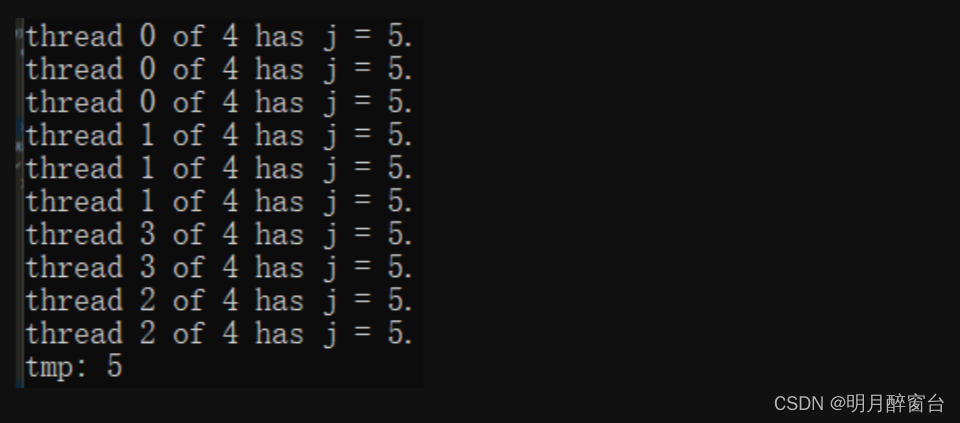
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
int j;
#pragma omp parallel for num_threads(thread_count) lastprivate(j)
for (int i = 0; i < 10; i++)
{
j = 4;
j++;
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("thread %d of %d has j = %d.\n", my_rank,thread_count,j);
}
printf("tmp: %d\n",j);
return 0;
}
>OpenMP section
sections在封闭代码的指定部分中,由线程组进行分配任务:
- 每个独立的section都需要在sections里面;
- 每个section可能执行不同的任务;
- 如果一个线程够快,该线程可能执行多个section。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
# pragma omp parallel num_threads(thread_count)
{
# pragma omp sections
{
# pragma omp section
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("thread %d of %d.\n", my_rank, thread_count);
}
# pragma omp section
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("thread %d of %d.\n", my_rank, thread_count);
}
# pragma omp section
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("thread %d of %d.\n", my_rank, thread_count);
}
# pragma omp section
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("thread %d of %d.\n", my_rank, thread_count);
}
}
}
return 0;
}

>>>reduction
reduction也是一种常见的子句,它为我们的parallel,for和sections提供了一个归并的功能:
- 它会提供一个私有的变量拷贝并且初始化该私有变量;
- 私有变量的初始化的值取决于选择的归并的操作符;
- 这些变量的拷贝会在本地线程中进行更新;
- 在最后的出口中,所有的变量拷贝将会通过操作符所定义的规则进行合并的计算,计算成一个共享变量;
- 使用方法如下:#pragma omp … reduction(op:list)。
reduction提供的操作符几乎都是符合结合律的二元操作符,本地变量的初始值如下所示:
| Operator | Initial Value |
|---|---|
| + | 0 |
| * | 1 |
| - | 0 |
| ^ | 0 |
| & | ~0 |
| 丨 | 0 |
| && | 1 |
| 丨丨 | 0 |
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
int j = 10;
printf("j = %d\n", j);
# pragma omp parallel num_threads(thread_count) reduction(+:j)
{
# pragma omp sections
{
# pragma omp section
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
j = j + 10;
printf("Hello from thread %d of %d in section 1 and j = %d.\n", my_rank, thread_count,j);
}
# pragma omp section
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
j = j + 20;
printf("Hello from thread %d of %d in section 2 and j = %d.\n", my_rank, thread_count, j);
}
}
}
printf("j = %d\n",j);
return 0;
}

>OpenMP single
single选项是在并行块里面使用的:
- 它告诉编译器接下来紧跟的下段代码将会只一个线程执行;
- 它可能会在处理多段线程不安全代码时非常有用;
- 在不使用no wait选项时,在线程组中不执行single的线程们将会等待single的结束
#pragma omp single nowait
{
nthreads = omp_get_num_threads();
printf("number of threads = %d\n",nthreads);
}
//与上面的代码大致等同
tid = omp_get_thread_num();
if(tid == 0){
nthreads = omp_get_num_threads();
printf("number of threads = %d\n",nthreads);
}
>OpenMP master
master选项是在并行块里面使用的:
- 它告诉编译器接下来紧跟的下段代码将会会由主线程执行;
- 它不会出现等待现象。
#pragma omp master
{
nthreads = omp_get_num_threads();
printf("number of threads = %d\n",nthreads);
}
//与上面的代码等同
tid = omp_get_thread_num();
if(tid == 0){
nthreads = omp_get_num_threads();
printf("number of threads = %d\n",nthreads);
}
>OpenMP barrier
在很多时候,需要线程之间团结协作完成某个任务,这就要求线程能够完成一致协调合作。OpenMP提供了多个操作,其中barrier和critical分别用于实现同步与互斥。
它是用于实现同步的一种手段,会在代码的某个点,令线程停下直到所有的线程都到达该地方。使用的语法如下:#pragma omp barrier。许多情况下,它已经能够自动的插入到工作区结尾,比如在for,single中,但是它能够被nowait禁用。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
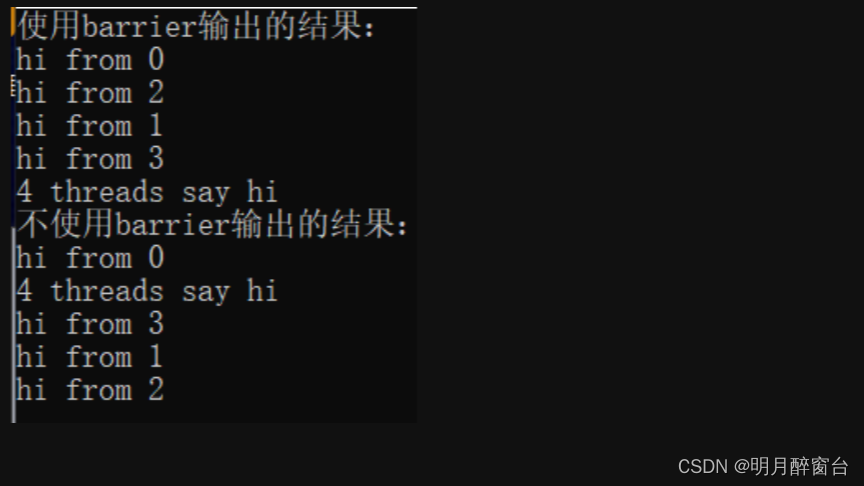
printf("使用barrier输出的结果:\n");
# pragma omp parallel num_threads(thread_count)
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("hi from %d\n", my_rank);
# pragma omp barrier
if (my_rank == 0) {
printf("%d threads say hi\n", thread_count);
}
}
printf("不使用barrier输出的结果:\n");
# pragma omp parallel num_threads(thread_count)
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
printf("hi from %d\n", my_rank);
//# pragma omp barrier
if (my_rank == 0) {
printf("%d threads say hi\n", thread_count);
}
}
return 0;
}
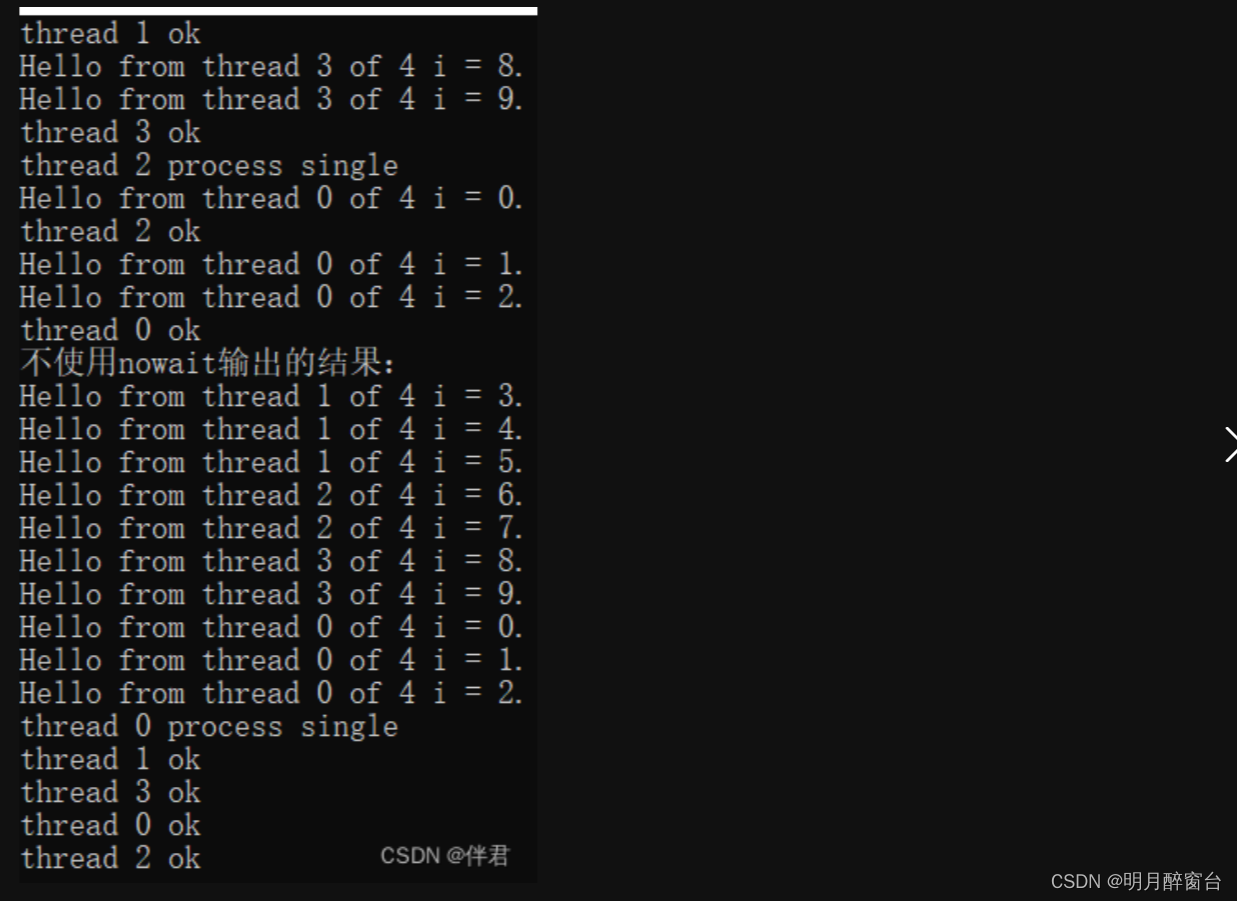
>>>nowait
nowait在OpenMP中,用于打断自动添加的barrier的类型,如parallel中的for以及single,用法如下:#pragma omp for nowait 、#pragma omp single nowait。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
#include<windows.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
printf("使用nowait输出的结果:\n");
# pragma omp parallel num_threads(thread_count)
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
# pragma omp for nowait
for (int i = 0; i < 10; i++) {
if (my_rank == 0)
Sleep(3000);
printf("Hello from thread %d of %d i = %d.\n", my_rank, thread_count, i);
}
# pragma omp single nowait
{
printf("thread %d process single\n", my_rank);
Sleep(3000);
}
printf("thread %d ok\n", my_rank);
}
printf("不使用nowait输出的结果:\n");
# pragma omp parallel num_threads(thread_count)
{
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
# pragma omp for
for (int i = 0; i < 10; i++) {
if (my_rank == 0)
Sleep(3000);
printf("Hello from thread %d of %d i = %d.\n", my_rank, thread_count, i);
}
# pragma omp single
printf("thread %d process single\n", my_rank);
Sleep(3000);
printf("thread %d ok\n", my_rank);
}
return 0;
}
>OpenMP critical
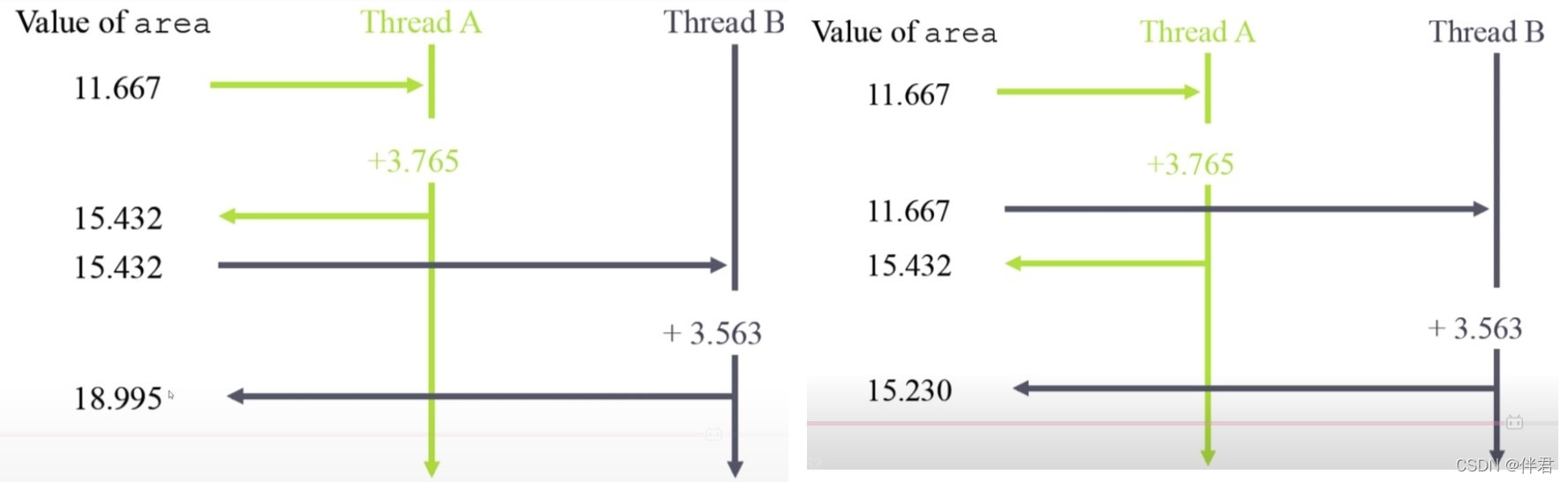
竞争现象可以由下图表示:
OpenMP提供了一个实现互斥的接口:critical,它告诉编译器解析来的一段代码在同一个时间段将会只由一个线程进行,使用方法如下:#pragma omp critical。好处是解决了竞争现象;坏处是使用critical会让程序执行减少并行化程序,而且必须要写代码的人手动判断哪些部分需要用critical。
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
int j = 0;
# pragma omp parallel for num_threads(thread_count) shared(j)
for (int i = 0; i < 10; i++) {
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
# pragma omp critical
{
j = j + 1;
printf("Hello from thread %d of %d i = %d,j = %d\n", my_rank, thread_count, i, j);
}
}
return 0;
}
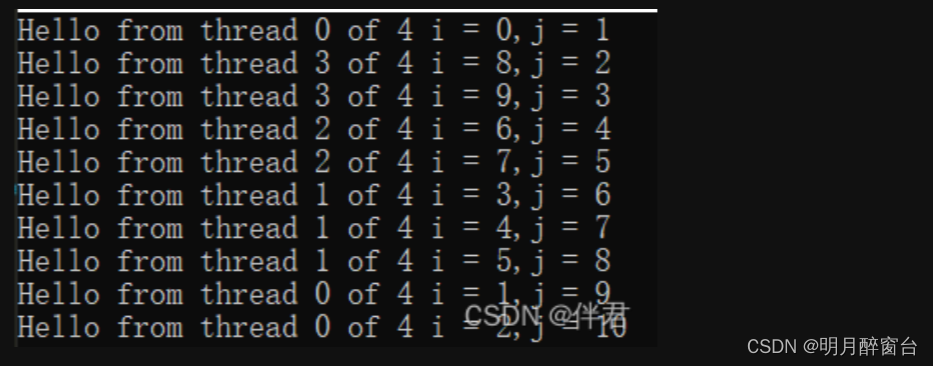
>OpenMP atomic
在特殊的情况下,除了使用critical指令控制临界区以外,我们还可以使用其他选项去保证内存的控制是原子的,OpenMP提供了一个选项:atomic(原子),它只在特殊的情况下使用:在自增或自减的情况下使用;在二元操作数的情况下使用。并且其只会应用于一条指令。使用方法如下:#pragma omp atomic。
critical与atomic的区别如下图所示:

>OpenMP schedule
循环调度的种类:
- 静态调度:在循环执行之前,就已经将循环任务分配好;
- 动态调度:在循环执行过程中,边执行边分配。
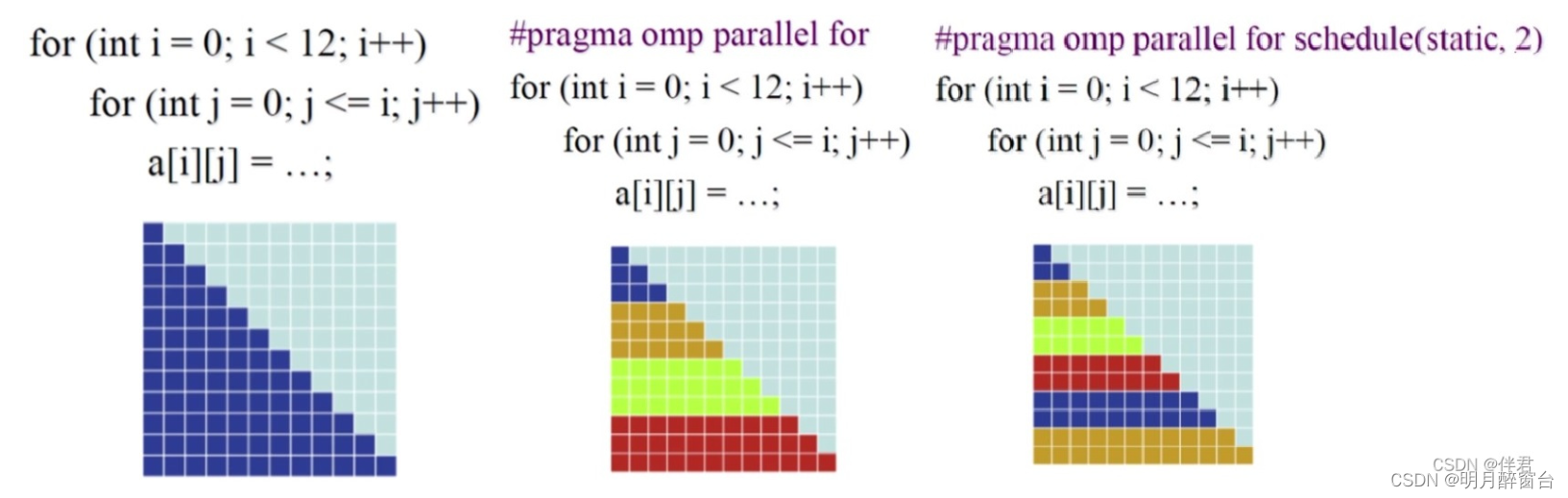
OpenMP提供了一个指令schedule,它能够将循环分配给每个线程,当采用不同的参数时,我们会使用不同的调度方式。它的使用方式如下:shedule(static[,chunk]),当采用static的参数时,chunk代表了每一块分块的大小,它会采取转轮制度,谁先获取块,谁就能获得整一块的内容。特点是低开销,但是可能会造成分配的不均衡。具体理解如下图所示:
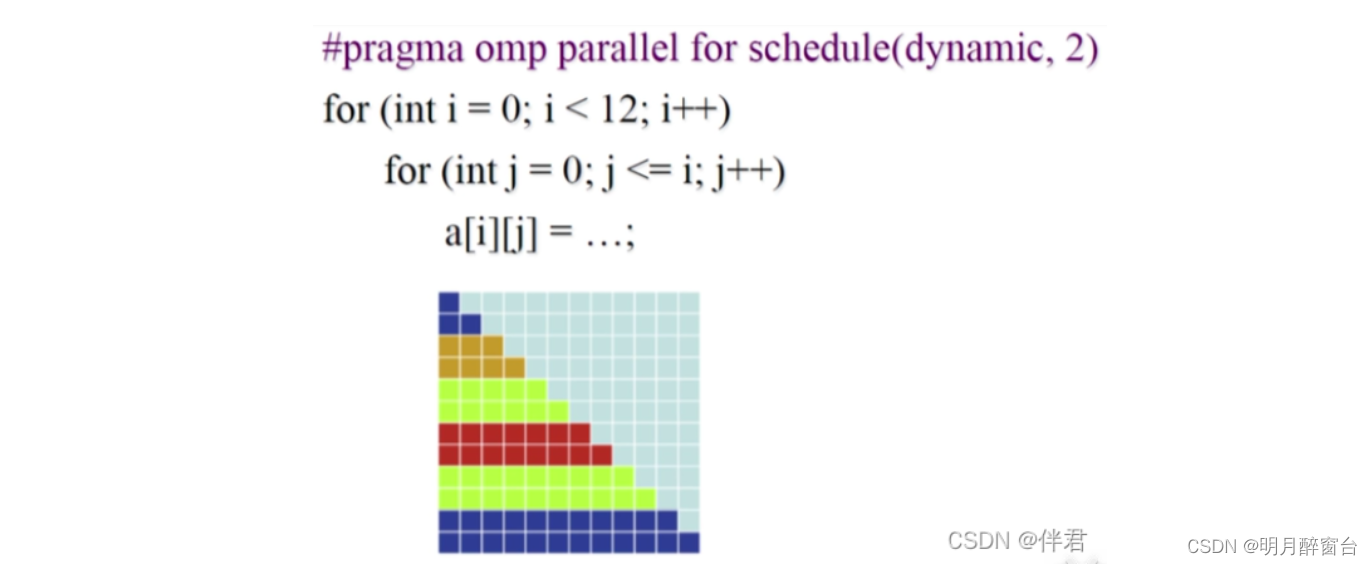
它的使用方式还有:shedule(dynamic[,chunk]),当采用dynamic的参数时,chunk代表了每一块分块的大小,每个线程执行完毕后,会自动获取下一个块,特点是高开销,但是能减少分配不均衡的情况。具体分配方式如下图所示:
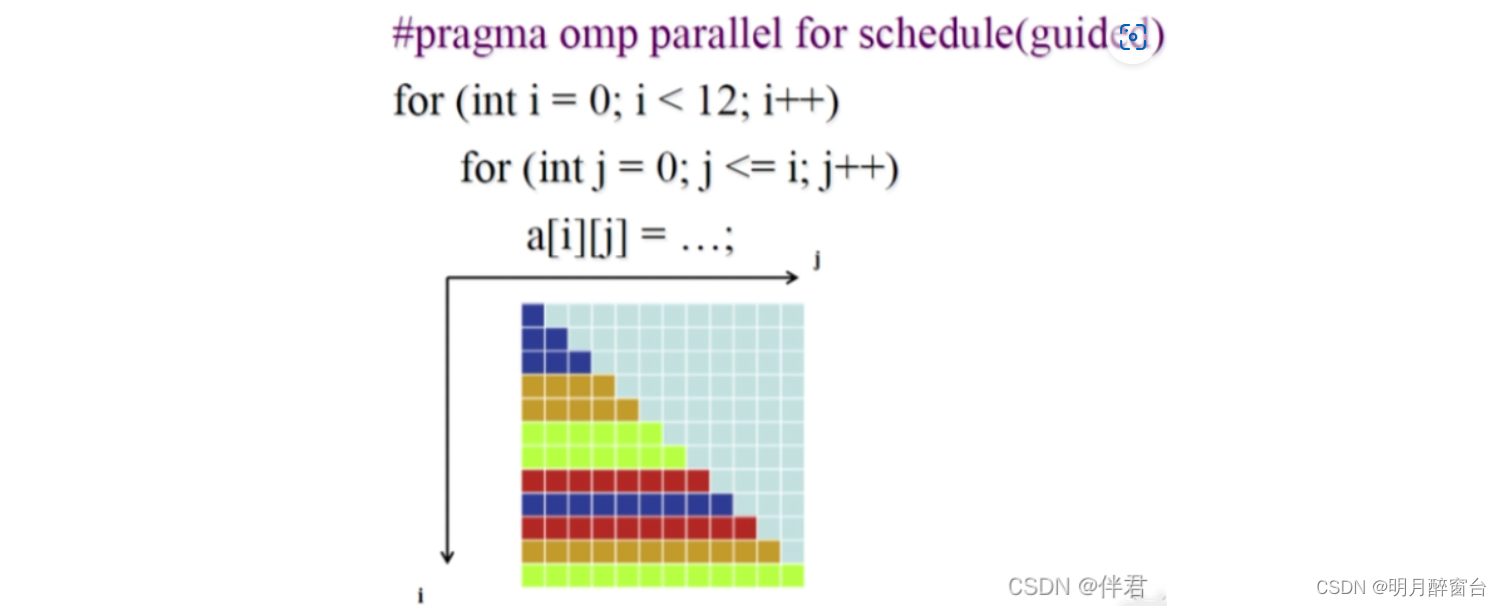
它的使用方式还有:shedule(guide[,chunk]),当采用guide的参数时,会按照一定的规则分配块,这是一种动态的分配,每一块的分配数量是在不断收缩的,但是最小不会小于chunk。最初的块会被定义成:循环数量/线程数。其余块的大小会被定义成:剩余循环数量/线程数。具体分配方式如下图所示:
#include<omp.h>
#include<windows.h>
#include<time.h>
void delay() {
int t = 50;
int my_rank = omp_get_thread_num();
t = t * (my_rank + 1);
Sleep(t);
}
int main(int argc, char** argv) {
int thread_count = strtol(argv[1],NULL,10);
int j = 0;
srand(time(NULL));
clock_t start, end;
start = clock();
# pragma omp parallel for num_threads(thread_count) schedule(static,2)
for (int i = 0; i < 100; i++) {
delay();
}
end = clock();
printf("first loop finish,time: %f\n", (double)end - start);
start = clock();
# pragma omp parallel for num_threads(thread_count) schedule(dynamic,2)
for (int i = 0; i < 100; i++) {
delay();
}
end = clock();
printf("second loop finish,time: %f\n", (double)end - start);
start = clock();
# pragma omp parallel for num_threads(thread_count) schedule(guided,2)
for (int i = 0; i < 100; i++) {
delay();
}
end = clock();
printf("third loop finish,time: %f\n", (double)end - start);
return 0;
}
4.环境变量
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用的环境变量如下:
- OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
- OMP_NUM_THREADS:用于设置并行域中的线程数;
- OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
- OMP_NESTED:指出是否可以并行嵌套。
5.API函数
| 函数名 | 函数作用 |
|---|---|
| omp_in_parallel | 判断当前是否在并行域中 |
| omp_get_thread_num | 返回线程号 |
| omp_set_num_threads | 设置后续并行域中的线程格式 |
| omp_get_num_threads | 返回当前并行区域中的线程数 |
| omp_get_max_threads | 获取并行域可用的最大线程数目 |
| omp_get_num_procs | 返回系统中处理器的个数 |
| omp_get_dynamic | 判断是否支持动态改变线程数目 |
| omp_set_dynamic | 启用或关闭线程数目的动态改变 |
| omp_get_nested | 判断系统是否支持并行嵌套 |
| omp_set_nested | 启用或关闭并行嵌套 |