本思路来自acwing算法提高课
题目描述

看本文需要准备的知识
1.dfs算法基本思想
2.对剪枝这个词有个简单的认识
迭代加深思想和此题分析
首先,什么是迭代加深呢?当一个问题的解有很大概率出现在递归树很浅的层,但是这个问题的解本身存在着很深的层,当这个很浅的层的对应分支在搜索顺序比较靠后的位置时,我们就会先搜索前几个很深的层,导致浪费大量时间,迭代加深就是为了解决这个问题(如下图所示)而存在的
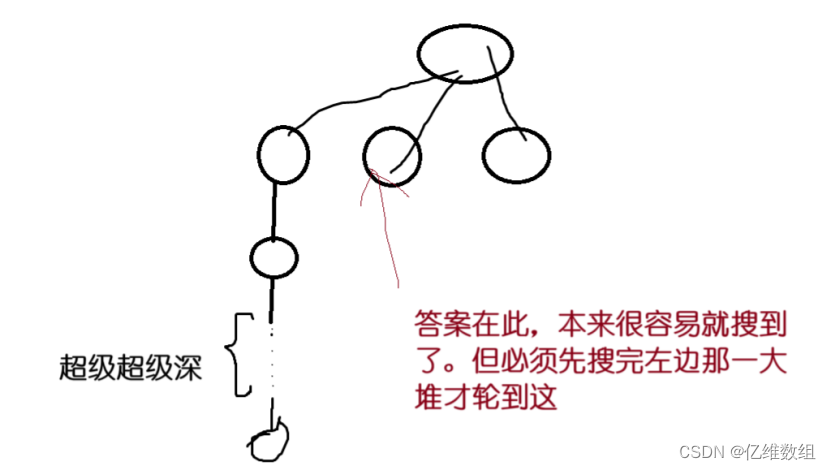
迭代加深具体思想非常简单,设置一个max_depth,每次搜索超过这个值直接return,如果搜完没搜到就逐步扩大max_depth
比如上面那个图,刚开始max_depth==1,对于左边那一堆,往下搜一个没搜到直接return,轮到第二个分支,往下搜一个,直接就找到答案了!如果答案在第二个分支的第二层,就会从最左边开始先往下搜两个没找到,就开始搜第二个分支往下看两个,就又找到了。
有人可能会问,这样反复搜之前搜过的部分,不会导致效率低吗?
举一个满二叉树的例子吧!
假设答案在第8层,在max_depth从1到8的过程中,会先搜索:
2^1+2^2+......+2^7<2^8
所以相对第8层而言,这个重复搜索不值一提
而对于这个题目,举一个例子:n=127时,可以是1,2,4,8,16,32,64,仅仅第7层就可以搜到,而如果按照正常搜索顺序去搜,举一个极端例子,可以这样:
1,2,填第三个时,可以填1+2=3,
1,2,3填第四个时,可以填1+3=4,
依次类推,甚至可以搜一百多层!!!相对于第7层而言,这做出了极大的优化!
最后我们可以发现,这有一种bfs的味道,感觉就像是迭代加深把dfs的优势和bfs做了融合一样
剪枝
本题可以做几个剪枝
1.优化搜索顺序,每层的搜索大的开始,这样分支数会减少
2.可行性剪枝,当某层上可能填入的数小于等于当前确定序列的最后一个数,或者大于n,那么就不选这个数
3.去掉冗余,比如1,2,3,4,该搜第五个数时,2+3=1+4所以如果1+4已经搜过就不用弄2+3了,故设立st数组,标记已经搜过的,下次再见时直接continue本次循环
本题感想
这道题目,对于st数组到底是每层初始化一次还是每棵递归树整体初始化一次这个问题,我思考了很长时间,虽然知道结果是前者,但始终找不到其中的原因,现在我想通了,找这个原因其实是没有必要的,而且是很难的,因为dfs层与层之间的调用会导致各种数组变量结果变化,我们寻找这种具体变化和影响是极其艰难的,所以我们需要做的事弄清st数组应该作用于什么地方就行了,本题st数组的目的就是仅仅为了排除二重循环的X[i]+X[j]相同的冗余问题,既然仅仅作用于二重循环,我们也仅仅需要在二重循环前面开一个st数组即可
代码
#include<iostream>
#include<cstring>
using namespace std;
const int N=110;
int path[N];
int n;
bool dfs(int u,int k)
{
if(u==k)return path[u-1]==n;
bool st[N];
memset(st,0,sizeof st);
for(int i=u-1;i>=0;i--)
{
for(int j=i;j>=0;j--)
{
int s=path[i]+path[j];
if(s>n||s<=path[u-1]||st[s])continue;
path[u]=s;
st[s]=true;
if(dfs(u+1,k))return true;
}
}
return false;
}
int main()
{
path[0]=1;
while(cin>>n,n)
{
int k=1;
while(!dfs(1,k))k++;
for(int i=0;i<k;i++)cout<<path[i]<<" ";
cout<<endl;
}
return 0;
}