在互联网时代之下,大数据对各行各业的发展有着重要的推动作用,而说到数据采集,必不可少的就是去使用爬虫工作。
一、什么是网络爬虫?
它是一种按照一定的规则自动游览、检索网页信息的程序或者脚本,通过自动请求目标网站,去采集所需要的数据&信息内容,比如文字信息、图片&视频等等;网络爬虫在许多领域有广泛的应用,例如搜索引擎的索引建立、数据挖掘、信息搜集和监测等。通过爬虫技术,可以自动化地从互联网上获取大量的数据,并为其他应用和分析提供支持
二、网络爬虫的工作原理
1、网络请求
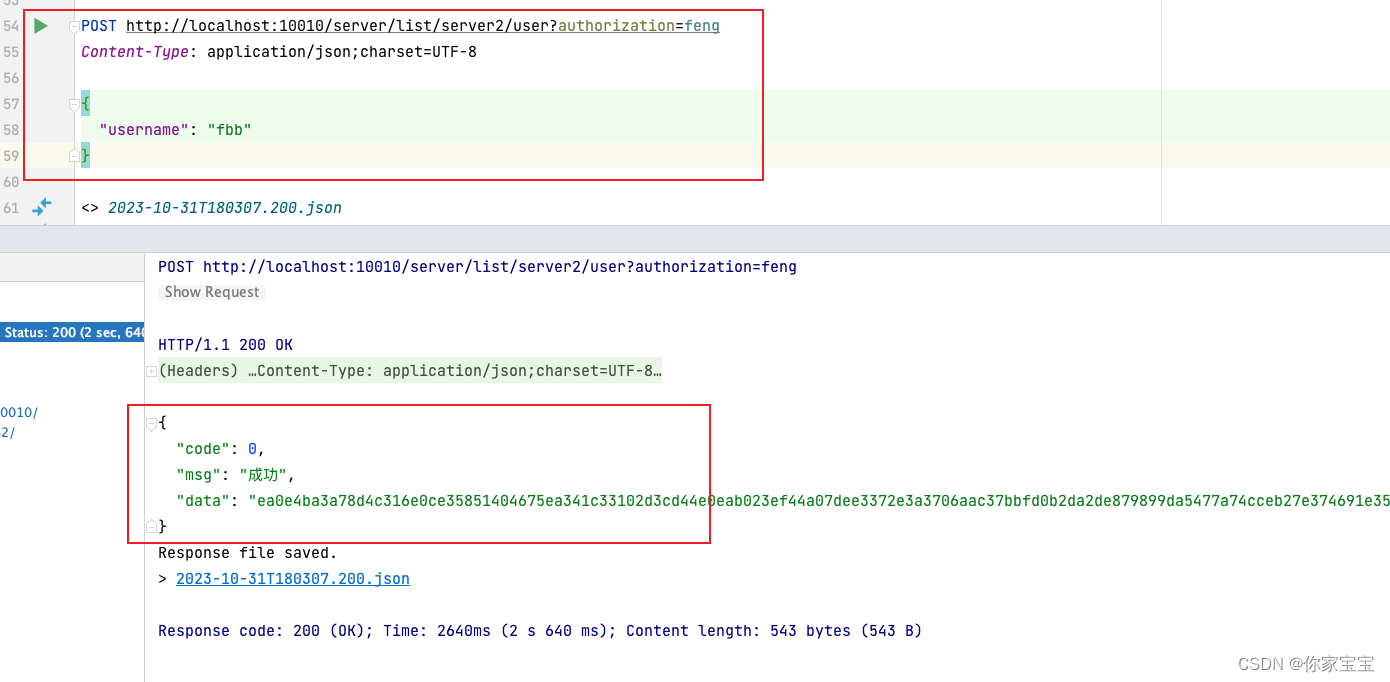
爬虫通过发送HTTP请求来获取网页内容。它可以模拟浏览器行为,发送GET或POST请求,并携带所需的参数和头部信息。
2、网页解析
爬虫会解析获取到的网页内容,提取出需要的数据。它可以使用HTML解析器来解析HTML标记语言,或使用其他技术(如XPath、正则表达式等)来提取特定的数据。
3、数据处理和存储
爬虫还可以对提取的数据进行处理和清洗,以便后续的分析和使用。它可以将数据保存到数据库、文本文件或其他数据存储介质中。
三、为什么网络爬虫需要使用动态代理IP
我们在做爬虫的工作的时候,经常会遇到的情况就是,刚开始正常工作抓取数据,很快就会出现“403”提示您的IP访问频率太高,这主要是网站做了反爬虫措施,同一个地址有限制访问次数就会直接拒绝服务。
动态代理的工作原理即在用大量不同地址的代理进行访问获取数。
四、怎么选择动态代理ip
1、服务商的代理ip池子要足够大
网络爬虫工作一般需要用到大量的动态IP,以保证爬虫工作的正常运行和获取数据量足够,池子越大,能获得的信息就越多。IPFoxy代理池子共有4000w个代理IP
2、高匿代理IP
为了保证爬虫能安全的访问目标网站,不被禁封和限制访问,代理IP需要模拟真实用户的IP地址,进行爬虫工作,需要匿名性够高的代理进行访问
3、高速稳定的代理IP
一方面IP的带宽和速度决定了是否能秒速响应网站的请求,另一方面,爬虫需要长时间且不间断的访问,所以IP的稳定性也是至关重要的。IPFoxy动态代理经测试稳定性可达99%。
五、如何获取代理ip
购买了IPFoxy动态代理包后,要怎么获取想要的代理ip:
1->按照需要选择地区,比如美国
2->根据本地网络选择路线优化,比如本地网络是香港,则选择亚太地区
3->根据需要选择socks5\http协议
4->输入要生成的代理数量,1~1000
5->前面四步设置好后点击批量生成按钮(按照需要选择要生成的格式)
6->点击批量复制或者导出到文本